







使用默认的语言库识别
只能使用多字体训练
1.安装Tesseract
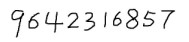
3. 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
tesseract.exe number.jpg result -l eng其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
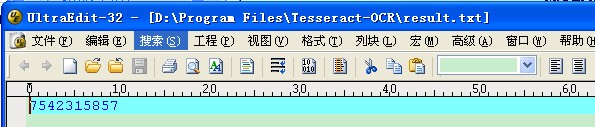
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
训练样本
1.下载工具jTessBoxEditor. http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
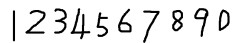
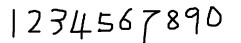
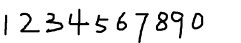
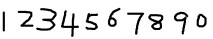
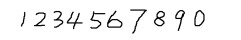
- tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
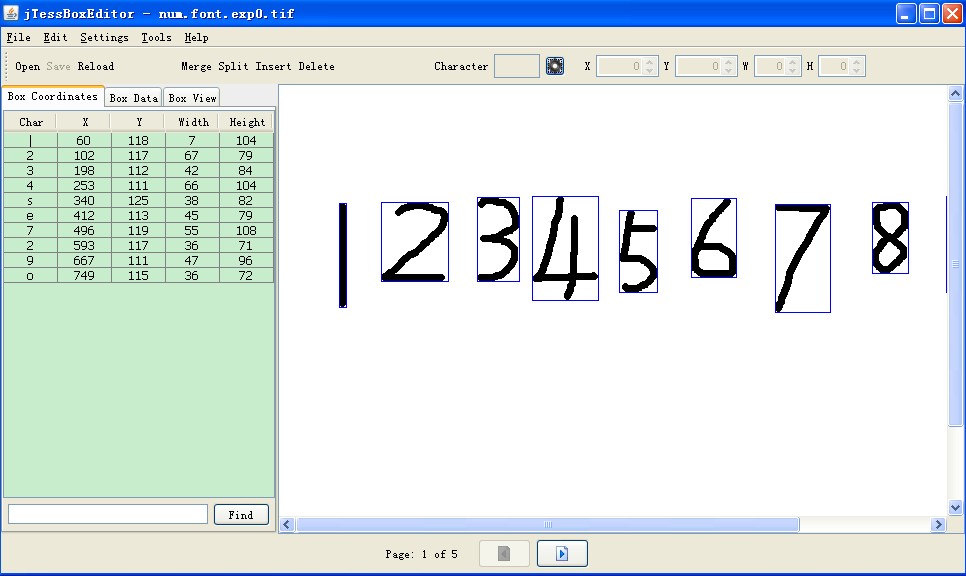
5.文字校正。运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
font_properties不含有BOM头,文件内容格式如下:
- <fontname> <italic> <bold> <fixed> <serif> <fraktur>
<fontname> <italic> <bold> <fixed> <serif> <fraktur>其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
- font 0 0 0 0 0
font 0 0 0 0 0- rem 执行改批处理前先要目录下创建font_properties文件
- echo Run Tesseract for Training..
- tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
- echo Compute the Character Set..
- unicharset_extractor.exe num.font.exp0.box
- mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
- echo Clustering..
- cntraining.exe num.font.exp0.tr
- echo Rename Files..
- rename normproto num.normproto
- rename inttemp num.inttemp
- rename pffmtable num.pffmtable
- rename shapetable num.shapetable
- echo Create Tessdata..
- combine_tessdata.exe num.
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.将批处理通过命令行执行。执行后的结果如下:
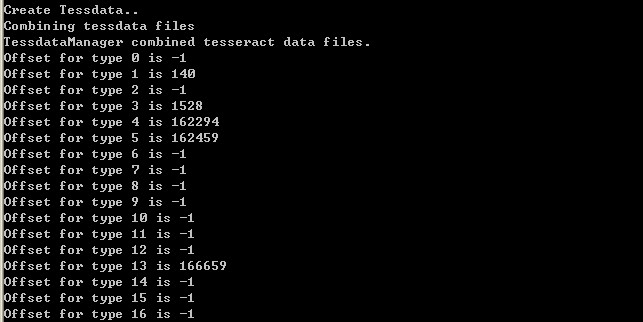
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
使用训练后的语言库识别
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng 2、 tesseract.exe number.jpg result -l num
3、对单个字符的操作 tesseract input.jpg out -psm 10 (对单个或多个识别)
4、tesseract.exe number.jpg result -l num -psm 10 对单多字体都有效
tesseract.exe number.jpg result -l eng识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。

使用开发库开发应用
C:\Program Files\Tesseract-OCR>tesseract -help
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
Tesseract can be given a page mode parameter (-psm) which can have the following values:
0= Orientation and script detection (OSD) only.1= Automatic page segmentation with OSD.2= Automatic page segmentation, but no OSD, or OCR3= Fully automatic page segmentation, but no OSD. (Default)4= Assume a single column of text of variable sizes.5= Assume a single uniform block of vertically aligned text.6= Assume a single uniform block of text.7= Treat the image as a single text line.8= Treat the image as a single word.9= Treat the image as a single word in a circle.10= Treat the image as a single character.
Example:
tesseract image.tif image.txt -l eng -psm 0However, I am not sure that it is possible to use the layout analysis in standalone mode.
#include "stdafx.h"
#include "tesseract-3.02.02-win32\include\tesseract\baseapi.h"
#include "tesseract-3.02.02-win32\include\tesseract\strngs.h"
#ifdef DEBUG
#pragma comment(lib,"libtesseract302-static.lib")
#else
#pragma comment(lib,"libtesseract302-static-debug.lib")
#endif
int _tmain(int argc, _TCHAR* argv[])
{
const char * image = "H3.jpg";
tesseract::TessBaseAPI api;
api.Init(NULL, "eng");
api.SetVariable( "tessedit_char_whitelist", "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" );
api.SetPageSegMode(tesseract::PSM_SINGLE_LINE);
STRING text_out;
if (!api.ProcessPages(image, NULL, 0, &text_out))
{
return 0;
}
printf(text_out.string());
return 0;
}
开发帮助:http://tesseract-ocr.repairfaq.org/














 8347
8347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









