







作者博客地址:http://www.yooongchun.cn/
Python爬虫抓取去哪儿网景点信息告诉你国庆那儿最堵
摘要:本文主要介绍了使用Python抓取去哪儿网站的景点信息并使用BeautifulSoup解析内容获取景点名称、票销售量、景点星级、热度等数据,然后使用xlrd、xlwt、xlutils等库来处理Excel,写入到Excel中,最后使用matplotlib可视化数据,并用百度的heatmap.js来生成热力图。
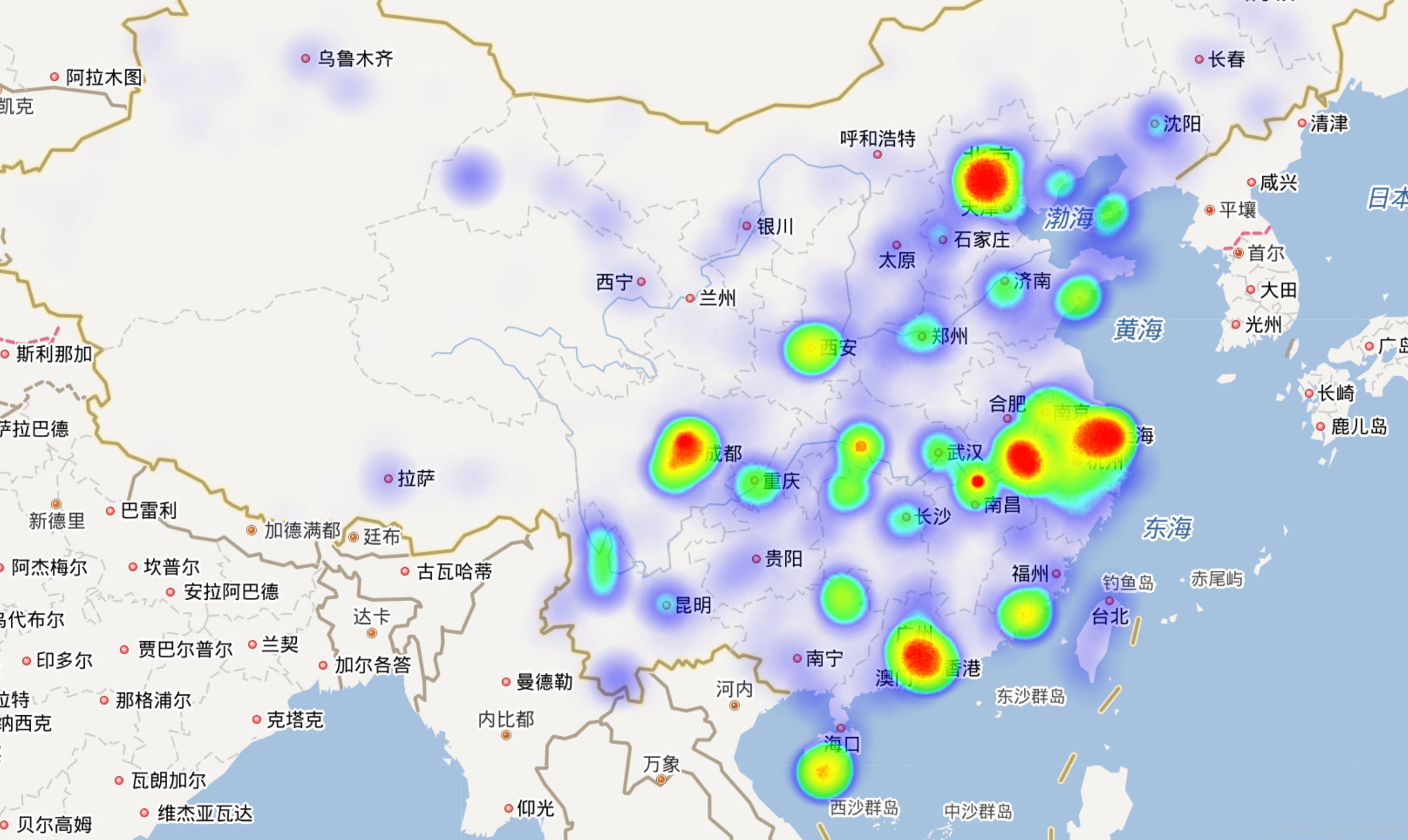
首先,上张效果图:
下面就详细来介绍如何一步步实现。
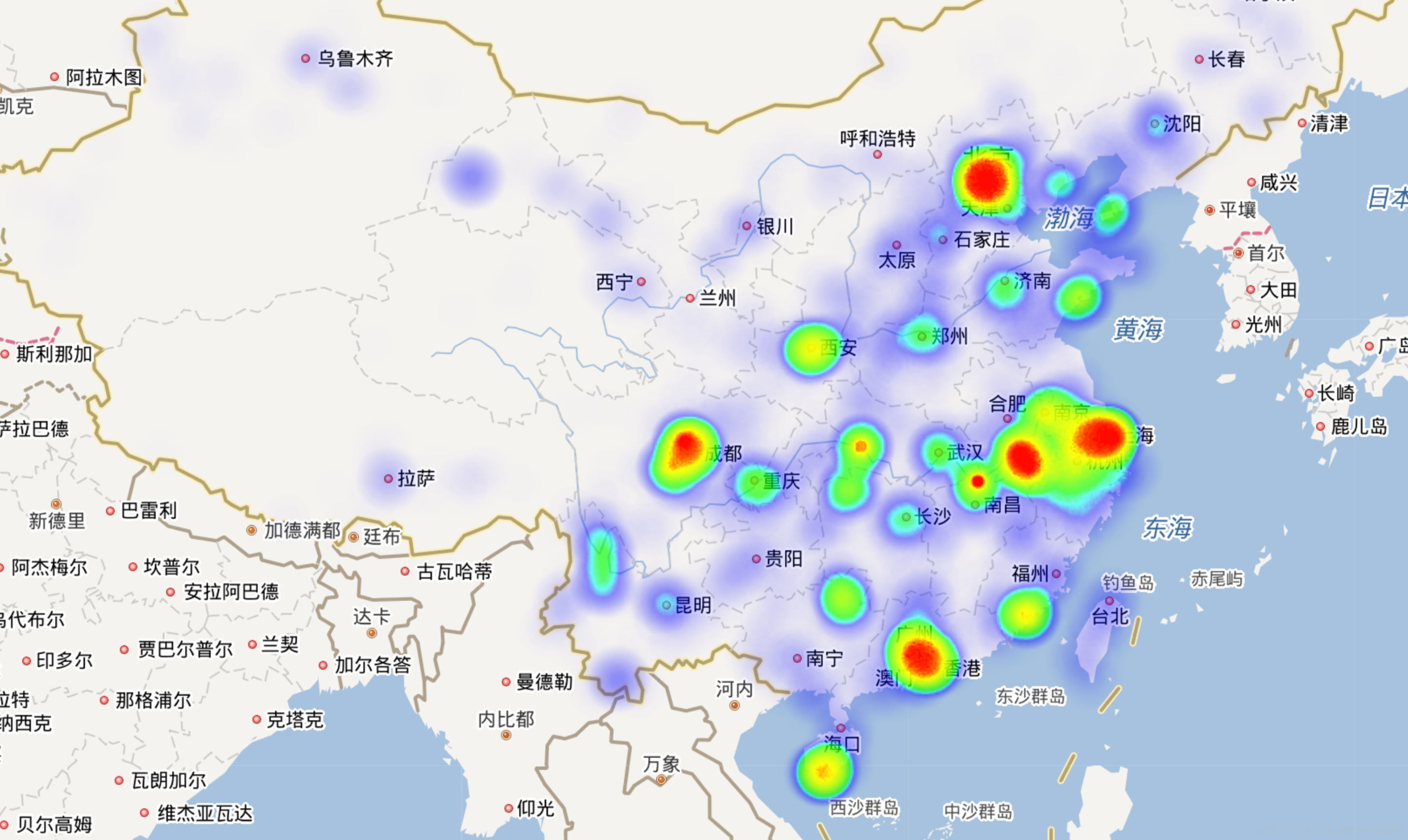
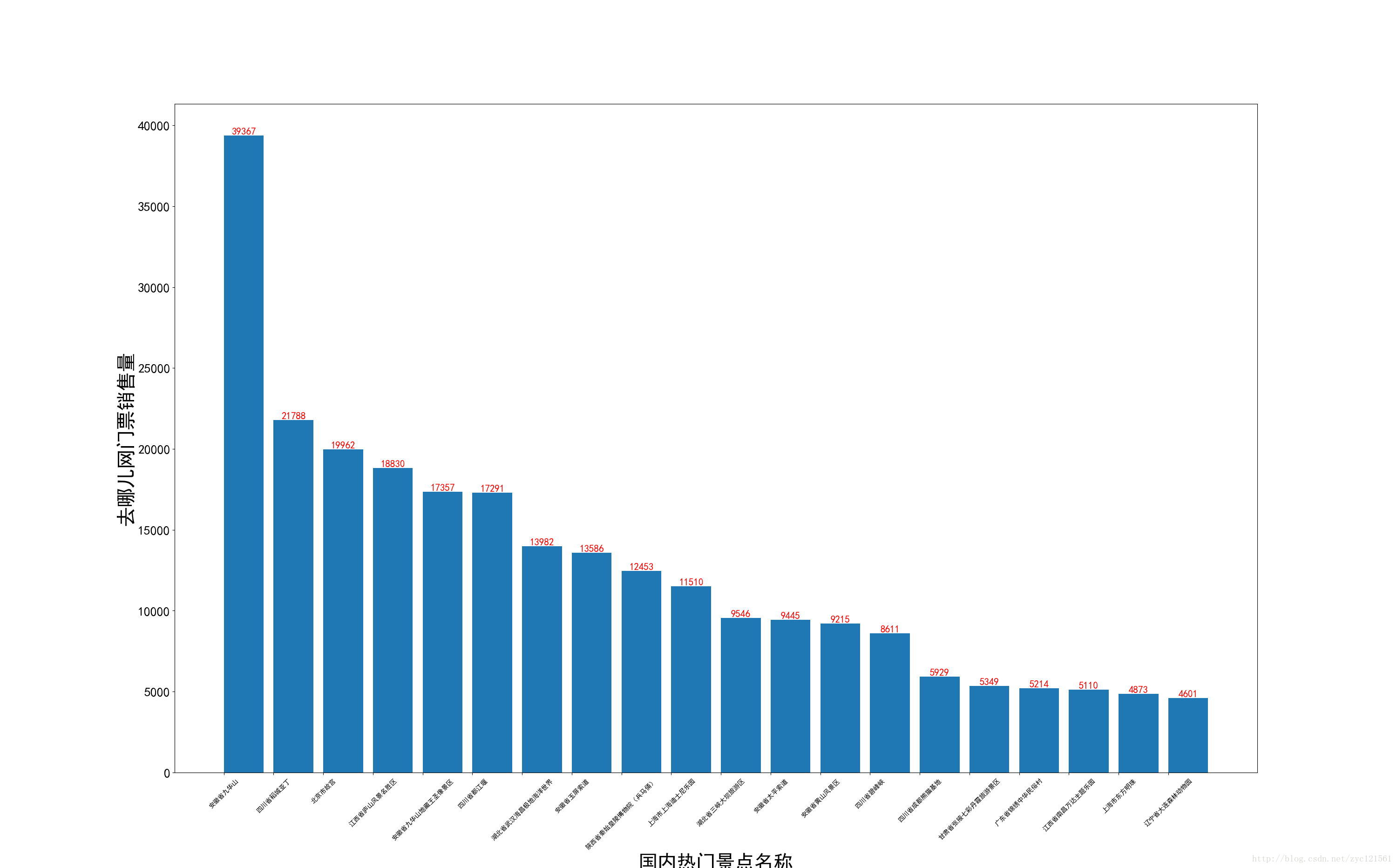
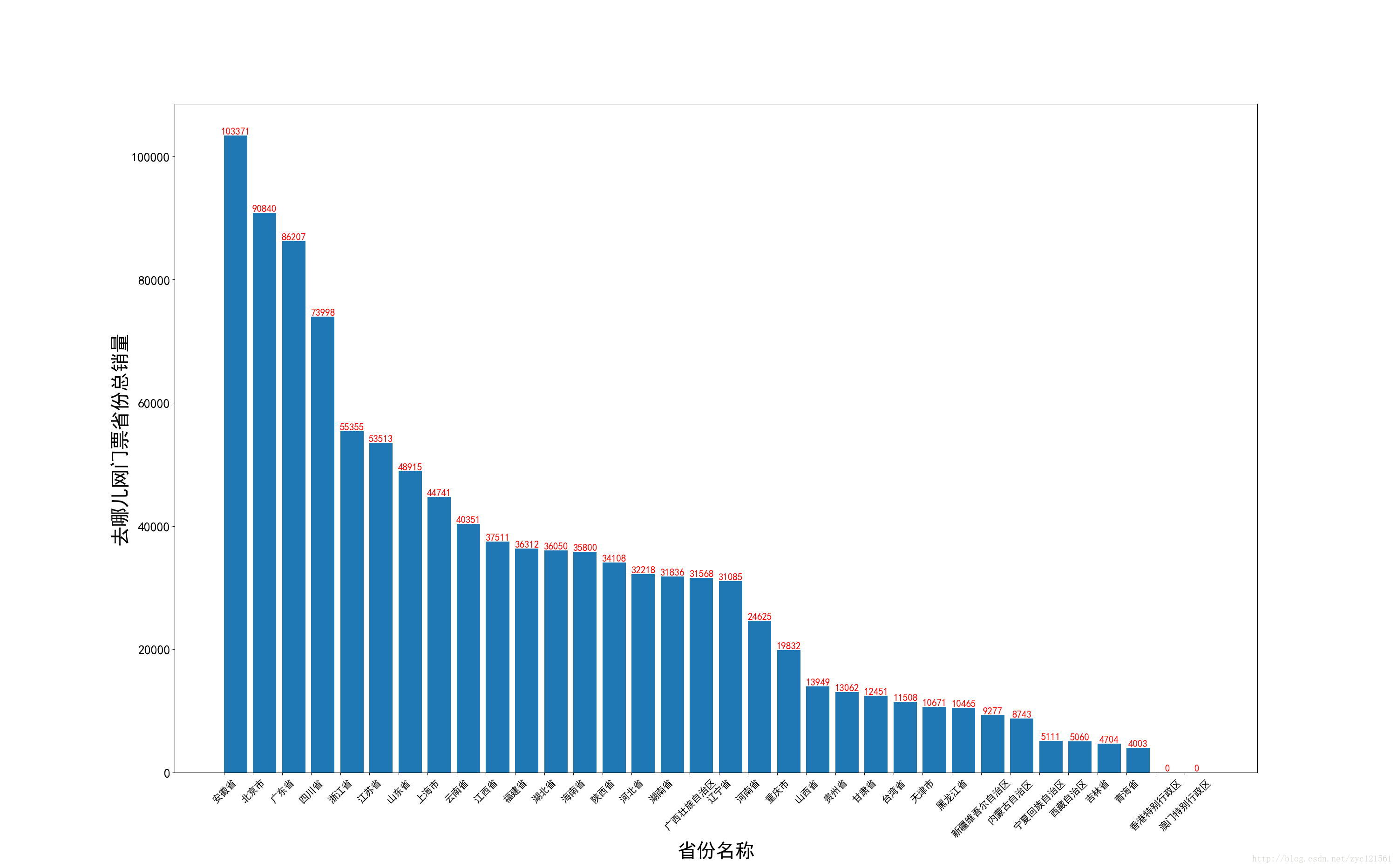
-
准备省份名单
访问是按照省份来进行搜索的,所以我们需要准备一份全国各省份的名单,这里,我已经准备好了这份名单
北京市,天津市,上海市,重庆市,河北省,山西省,辽宁省,吉林省,黑龙江省,江苏省,浙江省,安徽省,福建省,江西省,山东省,河南省,湖北省,湖南省,广东省,海南省,四川省,贵州省,云南省,陕西省,甘肃省,青海省,台湾省,内蒙古自治区,广西壮族自治区,西藏自治区,宁夏回族自治区,新疆维吾尔自治区,香港,澳门将这些数据保存为TXT,一行
然后使用Python加载:
def ProvinceInfo(province_path): tlist = [] with open(province_path, 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: tlist = line.split(',') return tlist -
构建URL
这里URL是根据城市名称信息来生成的
site_name = quote(province_name) # 处理汉字问题 url1 = 'http://piao.qunar.com/ticket/list.htm?keyword=' url2 = '®ion=&from=mps_search_suggest&page=' url = url1 + site_name + url2当然上面这个URL还不是最终的URL,因为一个城市搜索后有很多页面,我们需要定位到具体页面才行,这涉及到了如何判断页面数的问题,放在下文。
-
抓取页面信息函数
# 获得页面景点信息 def GetPageSite(url): try: page = urlopen(url) except AttributeError: logging.info('抓取失败!') return 'ERROR' try: bs_obj = BeautifulSoup(page.read(), 'lxml') # 不存在页面 if len(bs_obj.find('div', {'class': 'result_list'}).contents) <= 0: logging.info('当前页面没有信息!') return 'NoPage' else: page_site_info = bs_obj.find('div', {'class': 'result_list'}).children except AttributeError: logging.info('访问被禁止!') return None return page_site_info -
获得页面数目
# 获取页面数目 def GetPageNumber(url): try: page = urlopen(url) except AttributeError: logging.info('抓取失败!') return 'ERROR' try: bs_obj = BeautifulSoup(page.read(), 'lxml') # 不存在页面 if len(bs_obj.find('div', {'class': 'result_list'}).contents) <= 0: logging.info('当前页面没有信息!') return 'NoPage' else: page_site_info = bs_obj.find('div', {'class': 'pager'}).get_text() except AttributeError: logging.info('访问被禁止!') return None # 提取页面数 page_num = re.findall(r'\d+\.?\d*', page_site_info.split('...')[-1]) return int(page_num[0]) -
对取得的数据进行解析取得感兴趣的数据
# 格式化获取信息 def GetItem(site_info): site_items = {} # 储存景点信息 site_info1 = site_info.attrs site_items['name'] = site_info1['data-sight-name'] # 名称 site_items['position'] = site_info1['data-point'] # 经纬度 site_items['address'] = site_info1['data-districts'] + ' ' + site_info1['data-address'] # 地理位置 site_items['sale number'] = site_info1['data-sale-count'] # 销售量 site_level = site_info.find('span', {'class': 'level'}) if site_level: site_level = site_level.get_text() site_hot = site_info.find('span', {'class': 'product_star_level'}) if site_hot: site_hot = site_info.find('span', {'class': 'product_star_level'}).em.get_text() site_hot = site_hot.split(' ')[1] site_price = site_info.find('span', {'class': 'sight_item_price'}) if site_price: site_price = site_info.find('span', {'class': 'sight_item_price'}).em.get_text() site_items['level'] = site_level site_items['site_hot'] = site_hot site_items['site_price'] = site_price return site_items -
获取一个省的全部页面数据,这里用到了前面的几个函数
# 获取一个省的所有景点 def GetProvinceSite(province_name): site_name = quote(province_name) # 处理汉字问题 url1 = 'http://piao.qunar.com/ticket/list.htm?keyword=' url2 = '®ion=&from=mps_search_suggest&page=' url = url1 + site_name + url2 NAME = [] # 景点名称 POSITION = [] # 坐标 ADDRESS = [] # 地址 SALE_NUM = [] # 票销量 SALE_PRI = [] # 售价 STAR = [] # 景点星级 SITE_LEVEL = [] # 景点热度 i = 0 # 页面 page_num = GetPageNumber(url + str(i + 1)) # 页面数 logging.info('当前城市 %s 存在 %s 个页面' % (province_name, page_num)) flag = True # 访问非正常退出标志 while i < page_num: # 遍历页面 i = i + 1 # 随机暂停1--5秒,防止访问过频繁被服务器禁止访问 time.sleep(1 + 4 * random.random()) # 获取网页信息 url_full = url + str(i) site_info = GetPageSite(url_full) # 当访问被禁止的时候等待一段时间再进行访问 while site_info is None: wait_time = 60 + 540 * random.random() while wait_time >= 0: time.sleep(1) logging.info('访问被禁止,等待 %s 秒钟后继续访问' % wait_time) wait_time = wait_time - 1 # 继续访问 site_info = GetPageSite(url_full) if site_info == 'NoPage': # 访问完成 logging.info('当前城市 %s 访问完成,退出访问!' % province_name) break elif site_info == 'ERROR': # 访问出错 logging.info('当前城市 %s 访问出错,退出访问' % province_name) flag = False break else: # 返回对象是否正常 if not isinstance(site_info, Iterable): logging.info('当前页面对象不可迭代 ,跳过 %s' % i) continue else: # 循环获取页面信息 for site in site_info: info = GetItem(site) NAME.append(info['name']) POSITION.append(info['position']) ADDRESS.append(info['address']) SALE_NUM.append(info['sale number']) SITE_LEVEL.append(info['site_hot']) SALE_PRI.append(info['site_price']) STAR.append(info['level']) logging.info('当前访问城市 %s,取到第 %s 组数据: %s' % (province_name, i, info['name'])) return flag, NAME, POSITION, ADDRESS, SALE_NUM, SALE_PRI, STAR, SITE_LEVEL -
最后就是把数据写入到Excel中,这里因为数据量很大,而且是获得了一个城市的数据后再写入一次,而在爬取过程中很可能由于各种原因中断,因而每次读取Excel都会判断当前省份是否已经读取过
# 创建Excel def CreateExcel(path, sheets, title): try: logging.info('创建Excel: %s' % path) book = xlwt.Workbook() for sheet_name in sheets: sheet = book.add_sheet(sheet_name, cell_overwrite_ok=True) for index, item in enumerate(title): sheet.write(0, index, item, set_style('Times New Roman', 220, True)) book.save(path) except IOError: return '创建Excel出错!' # 设置Excel样式 def set_style(name, height, bold=False): style = xlwt.XFStyle() # 初始化样式 font = xlwt.Font() # 为样式创建字体 font.name = name # 'Times New Roman' font.bold = bold font.color_index = 4 font.height = height # borders= xlwt.Borders() # borders.left= 6 # borders.right= 6 # borders.top= 6 # borders.bottom= 6 style.font = font # style.borders = borders return style # 加载Excel获得副本 def LoadExcel(path): logging.info('加载Excel:%s' % path) book = xlrd.open_workbook(path) copy_book = copy(book) return copy_book # 判断内容是否存在 def ExistContent(book, sheet_name): sheet = book.get_sheet(sheet_name) if len(sheet.get_rows()) >= 2: return True else: return False # 写入Excel并保存 def WriteToTxcel(book, sheet_name, content, path): logging.info('%s 数据写入到 (%s-%s)' % (sheet_name, os.path.basename(path), sheet_name)) sheet = book.get_sheet(sheet_name) for index, item in enumerate(content): for sub_index, sub_item in enumerate(item): sheet.write(sub_index + 1, index, sub_item) book.save(path) -
数据分析、可视化
完成了前面几个步骤之后,我们就已经做好了爬取数据的工作了,现在就是需要可视化数据了,这里,设计的主要内容有:读取Excel数据,然后对每一个sheet(一个省份)读取数据,并去处重复数据,最后按照自己的要求可视化,当然,这里地图可视化部分使用了百度的heatmap.js工具,首先需要把景点的经纬度等信息生成json格式
def GenerateJson(ExcelPath, JsonPath, SalePath, TransPos=False): try: if os.path.exists(JsonPath): os.remove(JsonPath) if os.path.exists(SalePath): os.remove(SalePath) sale_file = open(SalePath, 'a', encoding='utf-8') json_file = open(JsonPath, 'a', encoding='utf-8') book = xlrd.open_workbook(ExcelPath) except IOError as e: return e sheets = book.sheet_names() sumSale = {} # 总销售量 for sheet_name in sheets: sheet = book.sheet_by_name(sheet_name) row_0 = sheet.row_values(0, 0, sheet.ncols - 1) # 标题栏数据 # 获得热度栏数据 for indx, head in enumerate(row_0): if head == '销售量': index = indx break level = sheet.col_values(index, 1, sheet.nrows - 1) # 获得景点名称数据 for indx, head in enumerate(row_0): if head == '名称': index = indx break site_name = sheet.col_values(index, 1, sheet.nrows - 1) if not TransPos: for indx, head in enumerate(row_0): if head == '经纬度': index = indx break pos = sheet.col_values(index, 1, sheet.nrows - 1) temp_sale = 0 # 临时保存销售量 for i, p in enumerate(pos): if int(level[i]) > 0: lng = p.split(',')[0] lat = p.split(',')[1] lev = level[i] temp_sale += int(lev) sale_temp = sheet_name + site_name[i] + ',' + lev json_temp = '{"lng":' + str(lng) + ',"lat":' + str(lat) + ', "count":' + str(lev) + '}, ' json_file.write(json_temp + '\n') sale_file.write(sale_temp + '\n') sumSale[sheet_name] = temp_sale else: pass json_file.close() sale_file.close() return sumSale当然,上面这个函数同时还绘制了景点销量信息的图。不过这里先讨论生成json文本后接下来处理。运行上面的程序会在你指定的路径下生成一个名为LngLat.json的文件,使用文本编辑器打开,然后把内容复制到heatmap.html这个文件的数据部分,这里为了代码不至于太长我删除了大部分数据信息,只保留了一部分,你只需要把下面的代码复制保存为html格式然后在 var points =[]中添加生成的json内容就可以了。最后使用浏览器打开,即可看到下面这样的效果:
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta name="viewport" content="initial-scale=1.0, user-scalable=no" /> <script type="text/javascript" src="http://gc.kis.v2.scr.kaspersky-labs.com/C8BAC707-C937-574F-9A1F-B6E798DB62A0/main.js" charset="UTF-8"></script><script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak=x2ZTlRkWM2FYoQbvGOufPnFK3Fx4vFR1"></script> <script type="text/javascript" src="http://api.map.baidu.com/library/Heatmap/2.0/src/Heatmap_min.js"></script> <title>热力图功能示例</title> <style type="text/css"> ul,li{list-style: none;margin:0;padding:0;float:left;} html{height:100%} body{height:100%;margin:0px;padding:0px;font-family:"微软雅黑";} #container{height:500px;width:100%;} #r-result{width:100%;} </style> </head> <body> <div id="container"></div> <div id="r-result"> <input type="button" onclick="openHeatmap();" value="显示热力图"/><input type="button" onclick="closeHeatmap();" value="关闭热力图"/> </div> </body> </html> <script type="text/javascript"> var map = new BMap.Map("container"); // 创建地图实例 var point = new BMap.Point(105.418261, 35.921984); map.centerAndZoom(point, 5); // 初始化地图,设置中心点坐标和地图级别 map.enableScrollWheelZoom(); // 允许滚轮缩放 var points =[ {"lng":116.403347,"lat":39.922148, "count":19962}, {"lng":116.03293,"lat":40.369733, "count":3026}, {"lng":116.276887,"lat":39.999497, "count":3778}, {"lng":116.393097,"lat":39.942341, "count":668}, {"lng":116.314607,"lat":40.01629, "count":1890}, {"lng":116.020213,"lat":40.367229, "count":2190}, {"lng":116.404015,"lat":39.912729, "count":904}, {"lng":116.398287,"lat":39.94015, "count":392}, {"lng":89.215713,"lat":42.94202, "count":96}, {"lng":89.212779,"lat":42.941938, "count":83}, {"lng":90.222236,"lat":42.850153, "count":71}, {"lng":80.931218,"lat":44.004188, "count":82}, {"lng":89.087234,"lat":42.952765, "count":40}, {"lng":86.866582,"lat":47.707518, "count":54}, {"lng":85.741271,"lat":48.36813, "count":4}, {"lng":87.556853,"lat":43.894646, "count":83}, {"lng":89.699515,"lat":42.862384, "count":81}, {"lng":80.903663,"lat":44.286633, "count":53}, {"lng":89.254534,"lat":43.025333, "count":50}, {"lng":86.1271,"lat":41.789203, "count":63}, {"lng":84.537278,"lat":43.314894, "count":81}, {"lng":84.282954,"lat":41.286104, "count":94}, {"lng":77.181601,"lat":37.397422, "count":32}, {"lng":82.666502,"lat":41.611567, "count":64}, {"lng":89.577441,"lat":44.008065, "count":57}, {"lng":83.056664,"lat":41.862089, "count":79}, {"lng":82.639664,"lat":41.588593, "count":53}, {"lng":89.537959,"lat":42.888903, "count":61}, {"lng":89.52734,"lat":42.876443, "count":95}, {"lng":87.11464,"lat":48.310173, "count":86}, {"lng":80.849732,"lat":44.238021, "count":6}, {"lng":89.488521,"lat":42.991858, "count":59}, {"lng":89.550783,"lat":42.882572, "count":92}, {"lng":88.055115,"lat":44.13238, "count":61}, {"lng":77.100143,"lat":39.095865, "count":63}, {"lng":78.992124,"lat":41.103398, "count":42}, {"lng":77.699877,"lat":39.013786, "count":62}, {"lng":81.912557,"lat":43.222123, "count":61}, {"lng":87.526264,"lat":47.75415, "count":33}, {"lng":87.556853,"lat":43.894632, "count":110}, {"lng":87.622686,"lat":43.820354, "count":10}, ] if(!isSupportCanvas()){ alert('热力图目前只支持有canvas支持的浏览器,您所使用的浏览器不能使用热力图功能~') } //详细的参数,可以查看heatmap.js的文档 https://github.com/pa7/heatmap.js/blob/master/README.md //参数说明如下: /* visible 热力图是否显示,默认为true * opacity 热力的透明度,1-100 * radius 势力图的每个点的半径大小 * gradient {JSON} 热力图的渐变区间 . gradient如下所示 * { .2:'rgb(0, 255, 255)', .5:'rgb(0, 110, 255)', .8:'rgb(100, 0, 255)' } 其中 key 表示插值的位置, 0~1. value 为颜色值. */ heatmapOverlay = new BMapLib.HeatmapOverlay({"radius":20}); map.addOverlay(heatmapOverlay); heatmapOverlay.setDataSet({data:points,max:10000}); //是否显示热力图 function openHeatmap(){ heatmapOverlay.show(); } function closeHeatmap(){ heatmapOverlay.hide(); } closeHeatmap(); function setGradient(){ /*格式如下所示: { 0:'rgb(102, 255, 0)', .5:'rgb(255, 170, 0)', 1:'rgb(255, 0, 0)' }*/ var gradient = {}; var colors = document.querySelectorAll("input[type='color']"); colors = [].slice.call(colors,0); colors.forEach(function(ele){ gradient[ele.getAttribute("data-key")] = ele.value; }); heatmapOverlay.setOptions({"gradient":gradient}); } //判断浏览区是否支持canvas function isSupportCanvas(){ var elem = document.createElement('canvas'); return !!(elem.getContext && elem.getContext('2d')); } </script>最后粘贴上完整代码,大家可直接复制后运行。
当然,有些库可能需要安装。把下面的代码放在一个
.py文件中运行即可。from urllib.parse import quote from urllib.request import urlopen from bs4 import BeautifulSoup import time import logging from collections import Iterable import os import random import xlwt import xlrd from xlutils.copy import copy import re logging.basicConfig(level=logging.INFO) # 创建Excel def CreateExcel(path, sheets, title): try: logging.info('创建Excel: %s' % path) book = xlwt.Workbook() for sheet_name in sheets: sheet = book.add_sheet(sheet_name, cell_overwrite_ok=True) for index, item in enumerate(title): sheet.write(0, index, item, set_style('Times New Roman', 220, True)) book.save(path) except IOError: return '创建Excel出错!' # 设置Excel样式 def set_style(name, height, bold=False): style = xlwt.XFStyle() # 初始化样式 font = xlwt.Font() # 为样式创建字体 font.name = name # 'Times New Roman' font.bold = bold font.color_index = 4 font.height = height # borders= xlwt.Borders() # borders.left= 6 # borders.right= 6 # borders.top= 6 # borders.bottom= 6 style.font = font # style.borders = borders return style # 加载Excel获得副本 def LoadExcel(path): logging.info('加载Excel:%s' % path) book = xlrd.open_workbook(path) copy_book = copy(book) return copy_book # 判断内容是否存在 def ExistContent(book, sheet_name): sheet = book.get_sheet(sheet_name) if len(sheet.get_rows()) >= 2: return True else: return False # 写入Excel并保存 def WriteToTxcel(book, sheet_name, content, path): logging.info('%s 数据写入到 (%s-%s)' % (sheet_name, os.path.basename(path), sheet_name)) sheet = book.get_sheet(sheet_name) for index, item in enumerate(content): for sub_index, sub_item in enumerate(item): sheet.write(sub_index + 1, index, sub_item) book.save(path) # 获得页面景点信息 def GetPageSite(url): try: page = urlopen(url) except AttributeError: logging.info('抓取失败!') return 'ERROR' try: bs_obj = BeautifulSoup(page.read(), 'lxml') # 不存在页面 if len(bs_obj.find('div', {'class': 'result_list'}).contents) <= 0: logging.info('当前页面没有信息!') return 'NoPage' else: page_site_info = bs_obj.find('div', {'class': 'result_list'}).children except AttributeError: logging.info('访问被禁止!') return None return page_site_info # 获取页面数目 def GetPageNumber(url): try: page = urlopen(url) except AttributeError: logging.info('抓取失败!') return 'ERROR' try: bs_obj = BeautifulSoup(page.read(), 'lxml') # 不存在页面 if len(bs_obj.find('div', {'class': 'result_list'}).contents) <= 0: logging.info('当前页面没有信息!') return 'NoPage' else: page_site_info = bs_obj.find('div', {'class': 'pager'}).get_text() except AttributeError: logging.info('访问被禁止!') return None # 提取页面数 page_num = re.findall(r'\d+\.?\d*', page_site_info.split('...')[-1]) return int(page_num[0]) # 去除重复数据 def FilterData(data): return list(set(data)) # 格式化获取信息 def GetItem(site_info): site_items = {} # 储存景点信息 site_info1 = site_info.attrs site_items['name'] = site_info1['data-sight-name'] # 名称 site_items['position'] = site_info1['data-point'] # 经纬度 site_items['address'] = site_info1['data-districts'] + ' ' + site_info1['data-address'] # 地理位置 site_items['sale number'] = site_info1['data-sale-count'] # 销售量 site_level = site_info.find('span', {'class': 'level'}) if site_level: site_level = site_level.get_text() site_hot = site_info.find('span', {'class': 'product_star_level'}) if site_hot: site_hot = site_info.find('span', {'class': 'product_star_level'}).em.get_text() site_hot = site_hot.split(' ')[1] site_price = site_info.find('span', {'class': 'sight_item_price'}) if site_price: site_price = site_info.find('span', {'class': 'sight_item_price'}).em.get_text() site_items['level'] = site_level site_items['site_hot'] = site_hot site_items['site_price'] = site_price return site_items # 获取一个省的所有景点 def GetProvinceSite(province_name): site_name = quote(province_name) # 处理汉字问题 url1 = 'http://piao.qunar.com/ticket/list.htm?keyword=' url2 = '®ion=&from=mps_search_suggest&page=' url = url1 + site_name + url2 NAME = [] # 景点名称 POSITION = [] # 坐标 ADDRESS = [] # 地址 SALE_NUM = [] # 票销量 SALE_PRI = [] # 售价 STAR = [] # 景点星级 SITE_LEVEL = [] # 景点热度 i = 0 # 页面 page_num = GetPageNumber(url + str(i + 1)) # 页面数 logging.info('当前城市 %s 存在 %s 个页面' % (province_name, page_num)) flag = True # 访问非正常退出标志 while i < page_num: # 遍历页面 i = i + 1 # 随机暂停1--5秒,防止访问过频繁被服务器禁止访问 time.sleep(1 + 4 * random.random()) # 获取网页信息 url_full = url + str(i) site_info = GetPageSite(url_full) # 当访问被禁止的时候等待一段时间再进行访问 while site_info is None: wait_time = 60 + 540 * random.random() while wait_time >= 0: time.sleep(1) logging.info('访问被禁止,等待 %s 秒钟后继续访问' % wait_time) wait_time = wait_time - 1 # 继续访问 site_info = GetPageSite(url_full) if site_info == 'NoPage': # 访问完成 logging.info('当前城市 %s 访问完成,退出访问!' % province_name) break elif site_info == 'ERROR': # 访问出错 logging.info('当前城市 %s 访问出错,退出访问' % province_name) flag = False break else: # 返回对象是否正常 if not isinstance(site_info, Iterable): logging.info('当前页面对象不可迭代 ,跳过 %s' % i) continue else: # 循环获取页面信息 for site in site_info: info = GetItem(site) NAME.append(info['name']) POSITION.append(info['position']) ADDRESS.append(info['address']) SALE_NUM.append(info['sale number']) SITE_LEVEL.append(info['site_hot']) SALE_PRI.append(info['site_price']) STAR.append(info['level']) logging.info('当前访问城市 %s,取到第 %s 组数据: %s' % (province_name, i, info['name'])) return flag, NAME, POSITION, ADDRESS, SALE_NUM, SALE_PRI, STAR, SITE_LEVEL def ProvinceInfo(province_path): tlist = [] with open(province_path, 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: tlist = line.split(',') return tlist # 生成Json格式文本 def GenerateJson(ExcelPath, JsonPath, TransPos=False): try: if os.path.exists(JsonPath): os.remove(JsonPath) json_file = open(JsonPath, 'a', encoding='utf-8') book = xlrd.open_workbook(ExcelPath) except IOError as e: return e sheets = book.sheet_names() for sheet_name in sheets[0:1]: sheet = book.sheet_by_name(sheet_name) row_0 = sheet.row_values(0, 0, sheet.ncols - 1) # 标题栏数据 # 获得热度栏数据 for indx, head in enumerate(row_0): if head == '销售量': index = indx break level = sheet.col_values(index, 1, sheet.nrows - 1) if not TransPos: for indx, head in enumerate(row_0): if head == '经纬度': index = indx break pos = sheet.col_values(index, 1, sheet.nrows - 1) for i, p in enumerate(pos): if int(level[i]) > 0: lng = p.split(',')[0] lat = p.split(',')[1] lev = level[i] json_temp = '{"lng":' + str(lng) + ',"lat":' + str(lat) + ', "count":' + str(lev) + '}, ' json_file.write(json_temp + '\n') else: pass json_file.close() return 'TransPos=%s,Trans pos to json done.' % TransPos if __name__ == '__main__': excel_path = r'c:/users/fanyu/desktop/Info.xls' province_path = r'c:/users/fanyu/desktop/info.txt' # Excel表头信息 title = ['名称', '经纬度', '地址', '销售量', '起售价', '星级', '热度'] # 加载省份列表 province_list = ProvinceInfo(province_path) # 如果旧表不存在则创建新表 if not os.path.exists(excel_path): CreateExcel(excel_path, province_list, title) # 爬取内容 book = LoadExcel(excel_path) for index, province in enumerate(province_list): # 判断内容是否存在,存在则跳过当前城市 if ExistContent(book, province): logging.info('当前访问城市 %s,该内容存在,跳过' % province) continue # 获取城市的景点信息 Contents = GetProvinceSite(province) if Contents[0]: # 获取正常则保存 WriteToTxcel(book, province, Contents[1:], excel_path)下面这个用来可视化数据,这个放在另外的
.py文件下
# 销量统计
# encoding=utf-8
import os
import xlrd
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
def Init(SalePath):
with open(SalePath, 'r', encoding='utf-8') as f:
lines = f.readlines()
return lines
def GetSaleData(Lines):
sale_info = {}
for line in Lines:
info = line.rstrip('\n').split(',')
sale_info[info[0]] = int(info[1])
return sale_info
def SaleViewer(SaleInfo, sumSale, TopN):
# 获得top-n排行
Num = []
Name = []
n = TopN
result = sorted(SaleInfo.items(), key=lambda e: e[1], reverse=True)
for name, num in result:
Num.append(num)
Name.append(name)
Y = Num[0:n]
X = np.arange(n)
yt = Name[0:n]
plt.bar(X, Y, align='edge')
plt.yticks(fontsize=20)
plt.ylabel('去哪儿网门票销售量', fontsize=30)
plt.xlabel('国内热门景点名称', fontsize=30)
if n <= 40:
plt.xticks(rotation=45, fontsize=10)
plt.xticks(X, yt)
for x, y in zip(X, Y):
plt.text(x + 0.4, y + 0.05, '%d' % y, ha='center', va='bottom', fontsize=15, color='red')
plt.show()
# 获得全国热门总销量
xt = []
yv = []
Sale = sorted(sumSale.items(), key=lambda e: e[1], reverse=True)
for k, v in Sale:
xt.append(k)
yv.append(v)
X = np.arange(len(sumSale))
plt.bar(X, yv, align='edge')
plt.xticks(rotation=45, fontsize=15)
plt.xticks(X, xt)
plt.yticks(fontsize=20)
plt.ylabel('去哪儿网门票省份总销量', fontsize=30)
plt.xlabel('省份名称', fontsize=30)
for x, y in zip(X, yv):
plt.text(x + 0.4, y + 0.05, '%d' % y, ha='center', va='bottom', fontsize=15, color='red')
plt.show()
def GenerateJson(ExcelPath, JsonPath, SalePath, TransPos=False):
try:
if os.path.exists(JsonPath):
os.remove(JsonPath)
if os.path.exists(SalePath):
os.remove(SalePath)
sale_file = open(SalePath, 'a', encoding='utf-8')
json_file = open(JsonPath, 'a', encoding='utf-8')
book = xlrd.open_workbook(ExcelPath)
except IOError as e:
return e
sheets = book.sheet_names()
sumSale = {} # 总销售量
Name = []
for sheet_name in sheets:
sheet = book.sheet_by_name(sheet_name)
row_0 = sheet.row_values(0, 0, sheet.ncols - 1) # 标题栏数据
# 获得热度栏数据
for indx, head in enumerate(row_0):
if head == '销售量':
index = indx
break
level = sheet.col_values(index, 1, sheet.nrows - 1)
# 获得景点名称数据
for indx, head in enumerate(row_0):
if head == '名称':
index = indx
break
site_name = sheet.col_values(index, 1, sheet.nrows - 1)
if not TransPos:
for indx, head in enumerate(row_0):
if head == '经纬度':
index = indx
break
pos = sheet.col_values(index, 1, sheet.nrows - 1)
temp_sale = 0 # 临时保存销售量
for i, p in enumerate(pos):
name = sheet.cell(i, 0).value
if name in Name: # 存在重复,直接跳过
continue
else:
Name.append(name)
if int(level[i]) > 0:
lng = p.split(',')[0]
lat = p.split(',')[1]
lev = level[i]
temp_sale += int(lev)
sale_temp = sheet_name + site_name[i] + ',' + lev
json_temp = '{"lng":' + str(lng) + ',"lat":' + str(lat) + ', "count":' + str(lev) + '}, '
json_file.write(json_temp + '\n')
sale_file.write(sale_temp + '\n')
sumSale[sheet_name] = temp_sale
else:
pass
json_file.close()
sale_file.close()
return sumSale
if __name__ == '__main__':
ExcelPath = 'c:/users/fanyu/desktop/Info.xls'
JsonPath = 'c:/users/fanyu/desktop/LngLat.json'
SalePath = 'c:/users/fanyu/desktop/SaleInfo.txt'
Path = 'c:/users/fanyu/desktop/SaleInfo.txt'
sumSale = GenerateJson(ExcelPath, JsonPath, SalePath, False)
Lines = Init(Path)
SaleNum = GetSaleData(Lines)
TopN = 20
SaleViewer(SaleNum, sumSale, TopN)















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











