







一个简单结点的结构体表示为:
struct note
{
int data; /*数据成员可以是多个不同类型的数据*/
struct note *next; /*指针变量成员只能是-个*/
};
一个简单的单向链表的图示
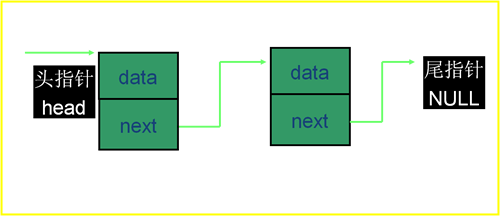
1.链表是结构、指针相结合的-种应用,它是由头、中间、尾多个链环组成的单方向可伸缩的链表,链表上的链环我们称之为结点。
2.每个结点的数据可用-个结构体表示,该结构体由两部分成员组成:数据成员与结构指针变量成员。
3.数据成员存放用户所需数据,而结构指针变量成员则用来连接(指向)下-个结点,由于每-个结构指针变量成员都指向相同的结构体,所以该指针变量称为结构指针变量。
4.链表的长度是动态的,当需要建立-个结点,就向系统申请动态分配-个存储空间,如此不断地有新结点产生,直到结构指针变量指向为空(NULL)。申请动态分配-个存储空间的表示形式为:
(struct note*)malloc(sizeof(struct note))
链表的建立
在链表建立过程中,首先要建立第一个结点,然后不断地
在其尾部增加新结点,直到不需再有新结点,即尾指针指向
NULL为止。
设有结构指针变量 struct note *p,*p1,*head;
head:用来标志链表头;
p:在链表建立过程中,p总是不断先接受系统动态分配的新结点地址。
p1->next:存储新结点的地址。
链表建立的步骤:
第一步:建立第一个结点
struct node
{
int data;
struct node *next;
};
struct note *p,*p1,*head;
head=p1=p=(struct node *)malloc(sizeof(struct node);

第二步:
给第-个结点成员data赋值并产生第二个结点
scanf(“%d”,&p->data); /*输入10*/
p=(struct node *)malloc(sizeof(struct node);

第三步:将第-个结点与第二个结点连接起来
p1-> next=p;
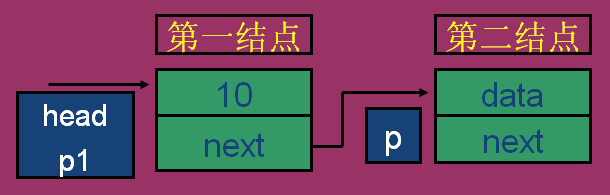
第四步:产生第三个结点
p1=p;
scanf(“%d”,&p->data);/*输入8*/
p=(struct node *)malloc(sizeof(struct node);
以后步骤都是重复第三、四步,直到给出-个结束条件,不再建新的结点时,要有
p->next=NULL;它表示尾结点。
代码
#include <stdio.h>
#include<stdlib.h>
#define LEN sizeof(struct node)
struct node
{
int data;
struct node *next;
};
main()
{ struct node *p, *pl,* head;
head=p=(struct node * )malloc(LEN);
scanf("%d",&p->data);/*头结点的数据成员*/
while(p->data!=0) /*给出0结束条件,退出循环*/
{ pl=p;
p=(struct node * )malloc(LEN);
scanf("%d",&p->data);/*中间结点数据成员*/
pl->next=p;/*中间结点的指针成员值*/
}
p-> next=NULL;/*尾结点的指针成员值*/
p=head;/*链表显示*/
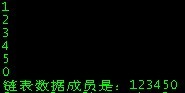
printf("链表数据成员是:");
while(p->next!=NULL)
{
printf("%d",p->data);
p=p->next;
}
printf("%d\n",p->data);
}















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









