







数据集
数据集介绍
数据集我们选择UEC FOOD 100数据集。
数据集“UEC FOOD 100”包含100种食物照片。每张食物照片都有一个边框,指示照片中食物的位置。
该数据集中的大多数食品类别都是日本流行的食品。因此,有些目录可能不为日本人以外的其他人所熟悉。
[1-100]:目录名称对应食物ID。
[1-100]/*.jpg :食物照片文件(某些照片在两个或更多目录中重复,因为它们包含两个或更多食物。)
[1-100]/bb_info.txt:各目录下照片文件的边界框信息
category.txt :食物列表,包括食物ID和食物英文名称的对应关系
category_ja.txt :食物列表,包括食物ID和食物名称的日文对应关系
multiple_food.txt:表示包含两个或多个食品的食品照片的列表
以上是官网的介绍,实际上我下载下来解压后,是一个UECFOOD100文件夹:

查看内部结构:
是1-100文件夹:
还有几个index和类别的映射文件:
category.txt记录了1到100对应着什么食物:

multiple_food.txt记录了表示包含两个或多个食品的食品照片的列表:
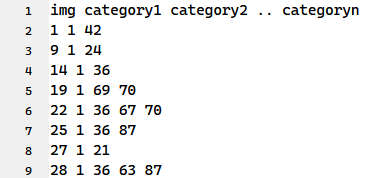
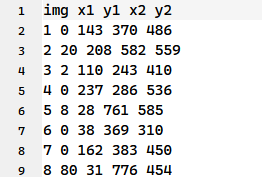
每个文件夹下存放了一类食物的图片,还有一个bb_info.txt文件,是每张图片的标注框的坐标信息。其中img一列表示的是UECFOOD100/1/文件夹下图片的名称,x1、y1、x2、y2分别表示该类食物(1类食物)在该图片中的位置的框的左上坐标和右下坐标。
数据集格式转换
显然,这个数据集的格式不是我们想要的,于是我写了一个python脚本,将其变成符合yolo格式的数据集
yolo格式数据集要求如下:
由两个文件夹构成:images和labels
images文件夹下是图片,labels文件夹中有每张图片对应的同名的txt文件,该txt文件中内容格式如下:
1 0.6245612541289654 0.8125469325469415 0.0794512586321524 0.0808451256325814
3 0.3245614232849654 0.4125469348669415 0.0394512584621724 0.0408454686325544
第一个数字表示这张图片中的每个目标对象的类别编号(即是什么食物),剩下四个为x、y、w、h,其中x、y表示目标对象框的中心在该图片中的相对位置(归一化),即将该图片左上角设为(0,0),向右为x正半轴,图片右上角(1,0),向下为y正半轴,图片左下角(0,1)。w和h代表归一化后框的相对宽度和高度。
脚本如下:

import os
import shutil
from PIL import Image
# 读取bb_info.txt获取边界框信息
def read_bounding_boxes(input_folder):
bounding_boxes = {
}
if os.path.isdir(input_folder):
bb_info_file = os.path.join(input_folder, "bb_info.txt")
if os.path.isfile(bb_info_file):
with open(bb_info_file, 'r') as file:
next(file) # 跳过文件的第一行(标题行)
for line in file:
parts = line.strip().split()
img_id = int(parts[0])
boxes = [(int(parts[i]), int(parts[i + 1]), int(parts[i + 2]), int(parts[i + 3])) for i in
range(1, len(parts), 4)]
bounding_boxes[img_id] = boxes
return bounding_boxes
# 生成YOLO格式标签
def generate_yolo_labels(input_folder, output_folder):
for folder_name in os.listdir(input_folder):
folder_path = os.path.join(input_folder, folder_name)
if os.path.isdir(folde 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









