






前言
● 进程为什么要通信?
进程之间需要某种协同,而协同的前提条件就是通信(怎么协同 – 数据是有类别的,比如通知就绪的数据、单纯传递过来的数据、控制相关的信息……通过这些数据的交流进行协同)
● 进程如何通信
进程间通信,成本可能会高一点(进程具有独立性,它们天然是不能通信的)
进程间通信的前提:先让不同的进程看到同一份(操作系统)资源(一段内存)
某一个进程先需要通信 -> 让OS创建一个共享资源(申请空间)(这个过程就要求操作系统提供很多的系统调用)-> OS创建的共享资源不同,系统调用接口不同,使得进程间通信有不同的种类
● 进程通信的常见方式是什么:
常见标准:systemV 标准(主要用于本地通信)
常见方式(systemV中的):消息队列、共享内存、信号量
人们的偷懒:共享内存还要开空间,不想为通信去修改内核源代码专门设计一个通信模块出来怎么办,能不能直接复用内核代码实现直接通信呢:管道(分为命名管道和匿名管道)
管道
介绍
如果一个文件用读写的方式分别打开,那么它的 内容 和 属性 在内核中只会存在一份,用于描述该文件的内核数据结构(struct file)会有两份
创建子进程时,子进程会继承(拷贝)父进程的文件描述符表 struct files_struct 结构体(这样的话父子进程直接就指向同一份文件的内核数据结构 struct file 了,那进程的独立性?—— 这是文件系统的事情,文件系统不具有独立性)
这就能解释:
1.为什么父子进程会向同一个显示器终端打印数据
2.为什么进程会默认打开3个标准输入输出:因为bash打开了,其下的所有子进程也就能默认打开
3.为什么子进程关闭后不影响父进程继续使用显示器文件:struct file 结构体中有引用计数(和硬链接里的那个没关系但原理一样,内存级的引用计数,引用计数为 0 时才释放文件资源)
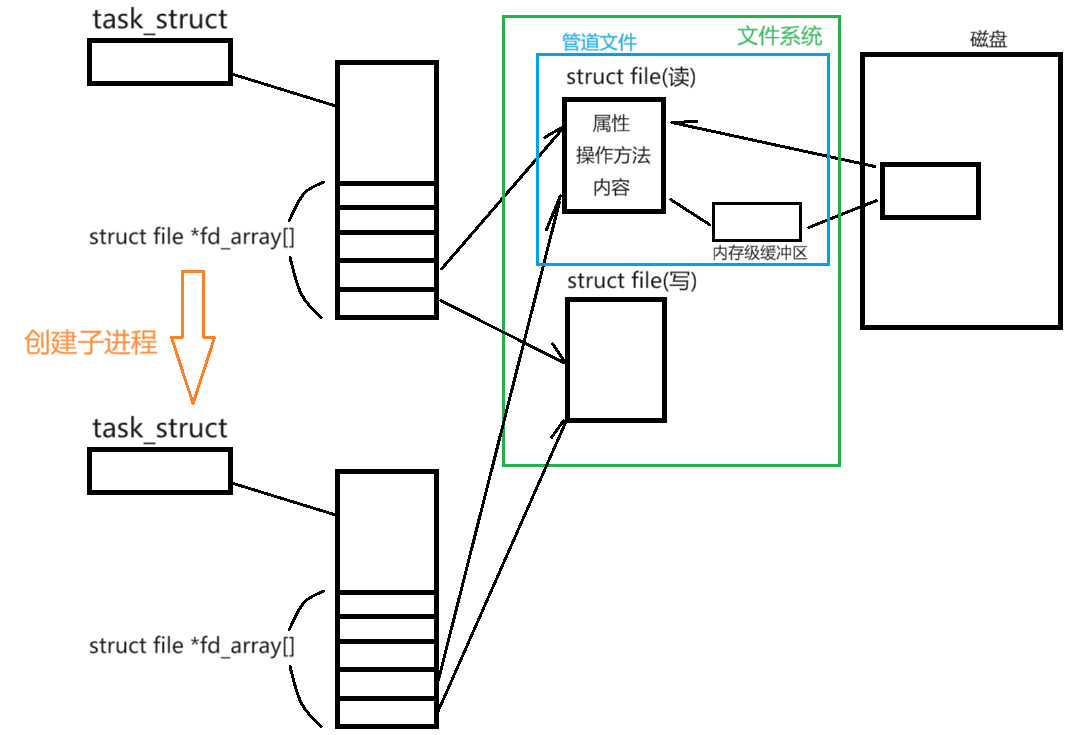
● 管道文件只允许单向通信(只允许父进程给子进程发数据 或者 只允许子进程给父进程发数据),因为它设计简单
为什么只允许单向通信:你说说如果父进程和子进程同时写怎么办
(为确保单向通信我们将文件分别用读写方式打开)
● 以子进程向父进程发数据为例,子进程会关闭文件描述符3的文件,父进程会关闭4
既然要关闭,为什么一开始要打开呢?—— 子进程要用3,父进程如果不打开3的话子进程打个集贸
可以不关闭吗? —— 可以,但建议关掉(文件描述符数组的大小是一定的,即能打开的文件也是一定的,别占着资源不用;再说万一误写了呢)
● 如果想要双向通信呢 —— 用两个管道
创建与使用管道
系统调用:
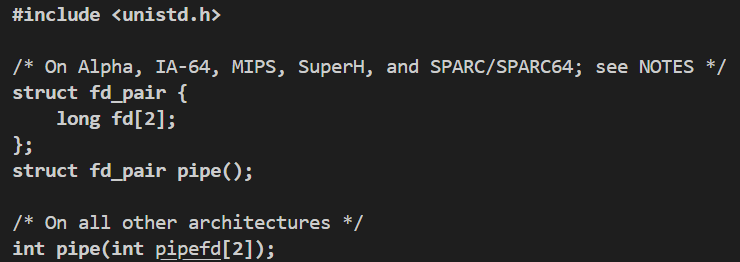
使用示例(创建管道):
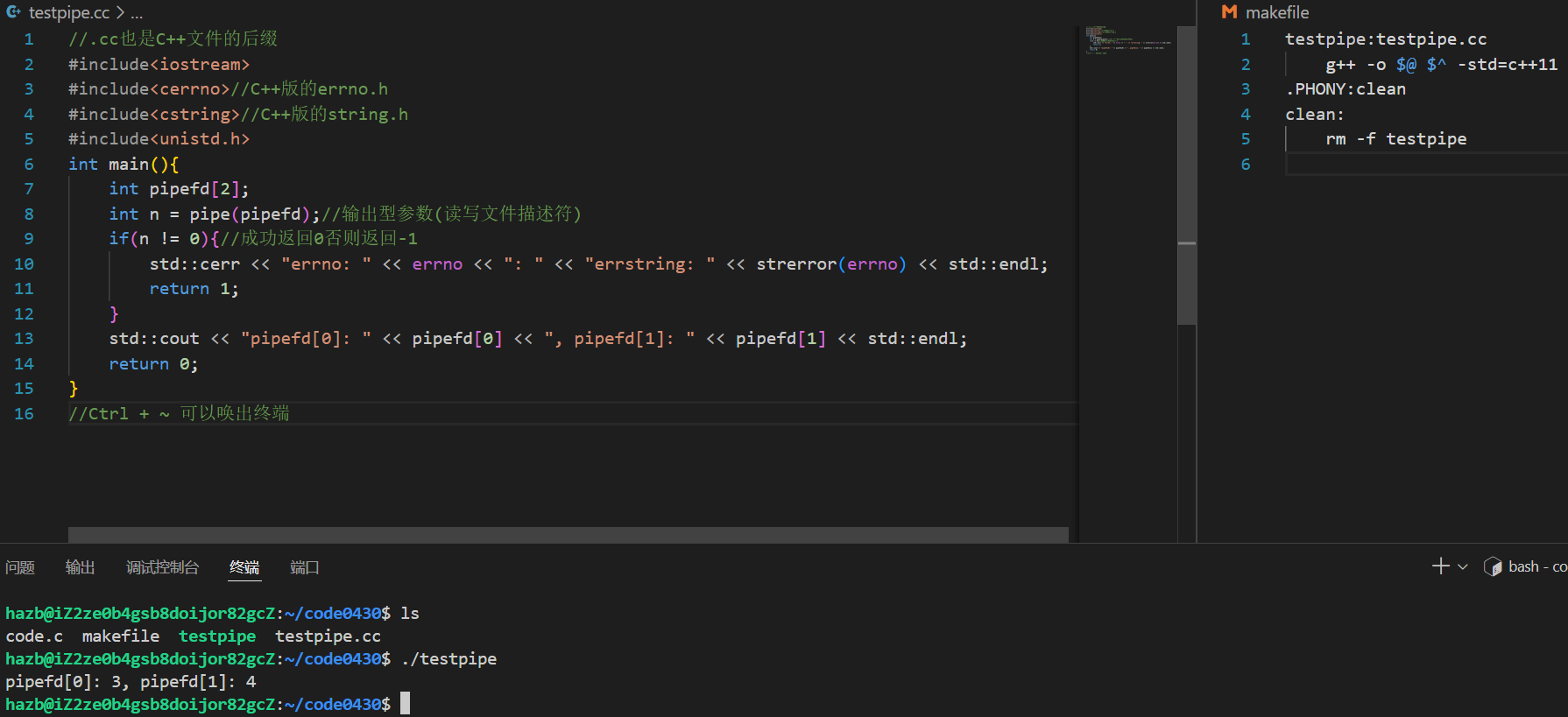
使用示例(子进程写入与父进程读取):
//makefile
testpipe:testpipe.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f testpipe
//testpipe.cc
//.cc也是C++文件的后缀
#include<iostream>
#include<cerrno>//C++版的errno.h
#include<cstring>//C++版的string.h
#include<unistd.h>//pipe的头问价
#include<sys/wait.h>//waitpid的头文件
#include<sys/types.h>//和<unistd.h>一起是getpid的头文件
const int size = 1024;//用于读取的缓冲区的大小--其实没必要在这写
//读点其他的可以动态改变的信息(只是老师想这么写而已)
std::string getOtherMessage(){
//记录这是第几次写入
static int cnt = 1;
std::string messageid = std::to_string(cnt);
cnt++;
//获取子进程的pid
pid_t self_id = getpid();
std::string stringpid = std::to_string(self_id);
std::string message = "messageid: ";
message += messageid;
message += " my pid is: ";
message += stringpid;
return message;//message的样子:messageid: 这是第几次写入 my pid is: 子进程pid
}
//子进程进行写入
void SubProcessWrite(int wfd){//参数为进行写入的文件描述符
std::string message = "I am son process.";
while(true){
std::string info = message + getOtherMessage();
write(wfd, info.c_str(), info.size());//系统调用是用C语言写的,所以我们写C++要用到系统调用时就注定我们的代码是C和C++混用的
//有必要在最后面加个\0吗 —— 不用,字符串以\0结尾是语言的规定不是文件的规定(语言需要在后面读取的时候加上即可)
sleep(1);
}
}
//父进程进行读取
void FatherProcessRead(int rfd){
char inbuffer[size];
while(true){
ssize_t n = read(rfd,inbuffer, sizeof(inbuffer)-1);//ssize_t即有符号整型 size_t无符号整形
//read的返回值:> 0:实际读到的字节数 == 0:读完了 -1:异常
if(n > 0){
inbuffer[n] = '\0';//字符串末尾添加\0
std::cout << "father get message: " << inbuffer << std::endl;
}
}
}
int main(){
//1.创建管道
int pipefd[2];
int n = pipe(pipefd);//输出型参数(读写文件描述符)
if(n != 0){//成功返回0否则返回-1
std::cerr << "errno: " << errno << ": " << "errstring: " << strerror(errno) << std::endl;
return 1;
}
std::cout << "pipefd[0]: " << pipefd[0] << ", pipefd[1]: " << pipefd[1] << std::endl;
sleep(1);
//2.创建子进程
pid_t id = fork();
if(id == 0){
std::cout << "子进程关闭不需要的fd,准备写入消息了" << std::endl;
sleep(1);
//子进程写入(先关掉读取的文件描述符)
close(pipefd[0]);
SubProcessWrite(pipefd[1]);
close(pipefd[1]);//这个其实关不关没什么影响
exit(0);
}
std::cout << "父进程关闭不需要的fd,准备接收消息了" << std::endl;
sleep(1);
//父进程读取(先关掉写入的文件描述符)
close(pipefd[1]);
FatherProcessRead(pipefd[0]);
close(pipefd[0]);//这个其实关不关也没什么影响
return 0;
}
//Ctrl + ~ 可以唤出终端
while :; do ps ajx | head -1 && ps ajx | grep testpipe | grep -v grep; echo "-------------------------"; sleep 1; done
管道的四种情况
1.如果管道内部是空的 且 写入端的 wfd 没有关闭:此时不具备读取条件,读取端会被阻塞,等待写入进程重新写入
2.管道被写满 且 读取端不读且 rfd 没有关闭:此时不具备写入条件,写进程会被阻塞,等待读进程读取数据(可以自己删去子进程的限制时间,大大限制父进程的读取时间并让子进程每次写入一个字符同时记录写入的次数来验证(ubantu 20.04 在写入64KB时会停止))
3.管道一直在被读取 且 写入端 wfd 关闭:读端不会阻塞
此时读端read返回值为0,表示读到了文件的结尾 —— 可以通过看read的返回值判断写端是不是关闭了
4.读端 rfd 关闭 且 写端 wfd 一直在进行写入:操作系统通过向写入端发送13号信号(SIGPIPE)关闭进程
//情况3验证:
#include<unistd.h>
#include<iostream>
#include<string>
using namespace std;
int main(){
int pipefd[2];
pipe(pipefd);
pid_t id = fork();
if(id == 0){
char buffer[100];
while(true){
sleep(1);
close(pipefd[1]);
int n = read(pipefd[0],buffer,sizeof(buffer));
if(n != 0){
buffer[n] = '\n';
cout << "I'm reading:" ;
cout << n<< ":" << buffer << endl;
}
}
}
close(pipefd[0]);
string info = "abcd";
write(pipefd[1], info.c_str(), info.size());
close(pipefd[1]);
sleep(100);
return 0;
}
管道的特征
1.匿名管道:只能用来进行具有血缘关系的进程之间进行通讯,常用于父子进程之间通讯(就像我们上面写的那样)
2.管道内部自带进程之间同步的机制(在我们的代码中并未限制父进程读取间隔,但它会等待子进程写完后再读取)
同步:多执行流执行代码的时候,具有明显的顺序性
3.管道文件的生命周期是随进程的(和普通文件一样)
4.管道文件在通信的时候,是面向字节流的 —— 典型特点:写入和读取的次数不是一一匹配的(eg.写端狂写,读端一段时间才读一次,将写入的东西全读走)
验证方式:让子进程的数据用标准错误输出,父进程的数据用标准输出输出,通过重定向输入到不同的终端显示器上查看:
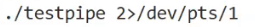
5.管道的通信模式是一种特殊的半双工模式
半双工:A给B发消息时B不能给A发消息,反之同理 ;全双工:A给B发消息时B也能给A发消息
特殊的半双工:半双工是可以双向通信的,但管道只允许一边写一边读
管道对读写的规定:

“写入若小于PIPE_BUF字节那么写入不可中断(不能被读取)”
“PIPE_BUF大小最小应为512字节(Linux中是4096字节)”
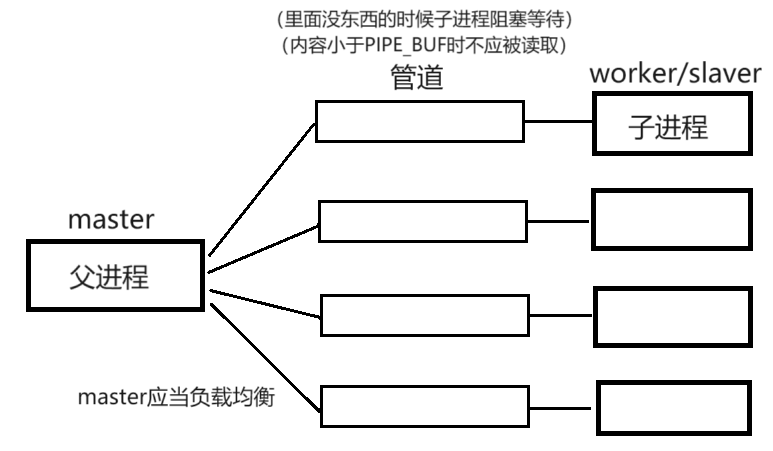
进程池
进程池:父进程预先创建一批子进程(和它们之间的管道),待需要的时候再通过管道向子进程派任务(父进程不往管道里写的时候–管道中没有数据,子进程阻塞等待)
把以上的父进程称为 master,子进程称为 worker/slaver
master向哪个管道写入,就是唤醒哪一个子进程来处理任务
这就能体现出进程之间的协同
均衡地向后端子进程划分任务:负载均衡
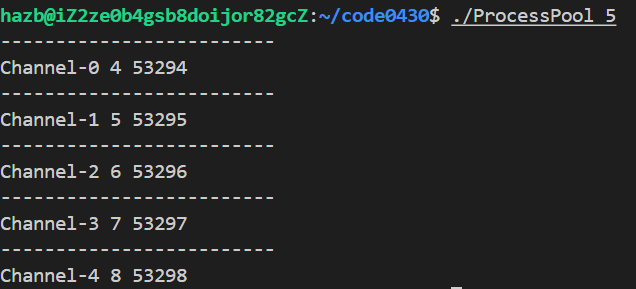
示例(创建如上图所示的结构–创建信道和子进程):
ProcessPool:ProcessPool.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f ProcessPool
//ProcessPool.cc
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
//管道
class Channel{
public:
Channel(int wfd, pid_t id, const std::string &name)
: _wfd(wfd), _subprocessid(id), _name(name)
{}
int GetWfd() { return _wfd; }
pid_t GetProcessId() { return _subprocessid; }
std::string GetName() { return _name; }
private:
int _wfd;
pid_t _subprocessid;
std::string _name;
};
int main(int argc, char* argv[]){//命令行应该是:./ProcessPool n 表示要创建几个管道个子进程(两个参数)
//如果不是两个参数:提醒格式错误
if (argc != 2)
{
std::cerr << "Usage: " << argv[0] << " processnum" << std::endl;
return 1;
}
int num = std::stoi(argv[1]);
std::vector<Channel> channels;
for (int i = 0; i < num; i++)
{
// 1. 创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
exit(1);
// 2. 创建子进程
pid_t id = fork();
if (id == 0)
{
// child - read
close(pipefd[1]);//关闭子进程的wfd
//让子进程干点什么事情
close(pipefd[0]);
exit(0);
}
// 3.构建一个channel名称
std::string channel_name = "Channel-" + std::to_string(i);
// 父进程
close(pipefd[0]);//关闭当前管道的rfd
// a. 子进程的pid b. 父进程关心的管道的w端
channels.push_back(Channel(pipefd[1], id, channel_name));
}
//看看管道建立的怎么样
for(auto e : channels){
std::cout << "-------------------------"<<std::endl;
//管道名,写端文件描述符,读端pid
std::cout<< e.GetName() << " " << e.GetWfd() << " " << e.GetProcessId() << std::endl;
}
return 0;
}
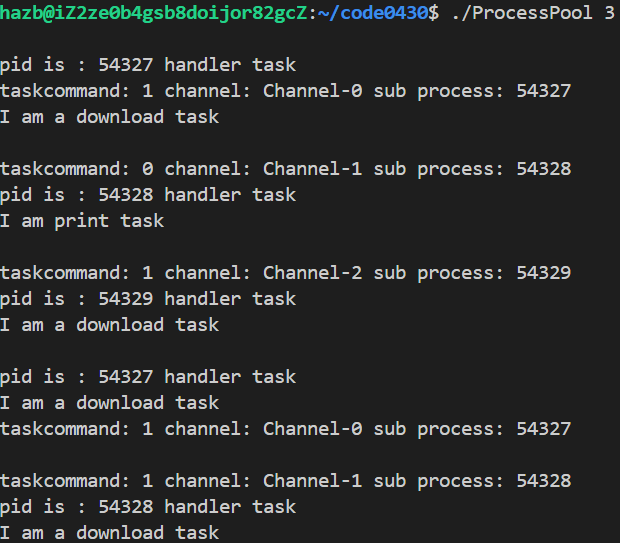
示例(创建管道和子进程 -> 父进程派任务 -> 回收管道和子进程):
父进程向子进程派任务:
让父进程把函数写到管道里让子进程读取执行时不现实的,而派任务无非是让子进程去 执行某段代码 —— 父子进程虽然数据会写时拷贝,但代码共享,故可以让父进程先 规定一些任务 等着让子进程执行;这些任务构成了一张表(函数指针数组),于是父进程给子进程派任务就只需向管道中传入数组下标(任务码,4个字节)
//Task.hpp .hpp也是头文件,且允许声明和实现不分离(常见于开源项目)
#pragma once
#include <iostream>
#include <ctime>
#include <cstdlib>
#include <sys/types.h>
#include <unistd.h>
//定义3个任务
#define TaskNum 3
typedef void (*task_t)(); // 重命名 task_t 为函数指针类型
//极其简陋的3个任务:
void Print() { std::cout << "I am print task" << std::endl; }
void DownLoad() { std::cout << "I am a download task" << std::endl; }
void Flush() { std::cout << "I am a flush task" << std::endl; }
//任务表(函数指针数组)
task_t tasks[TaskNum];
void LoadTask(){ //初始化任务表
srand(time(nullptr) ^ getpid() ^ 17777);//随机数,用于之后随机分派任务
tasks[0] = Print;
tasks[1] = DownLoad;
tasks[2] = Flush;
}
//执行任务
void ExcuteTask(int number)
{
if (number < 0 || number > 2)
return;
tasks[number]();
}
//随机分派任务
int SelectTask()
{
return rand() % TaskNum;
}
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "Task.hpp"
//管道
class Channel
{
public:
Channel(int wfd, pid_t id, const std::string &name)
: _wfd(wfd), _subprocessid(id), _name(name)
{}
//获取管道的信息
int GetWfd() { return _wfd; }
pid_t GetProcessId() { return _subprocessid; }
std::string GetName() { return _name; }
//关闭wfd(相应的子进程会因为写端关闭而结束)
void CloseChannel(){
close(_wfd);
}
//等待子进程
void Wait(){
pid_t rid = waitpid(_subprocessid, nullptr, 0);
if (rid > 0)
{
std::cout << "wait " << rid << " success" << std::endl;
}
}
private:
int _wfd;
pid_t _subprocessid;
std::string _name;
};
//●子进程执行任务(从管道中读取任务码->看是否读到东西以此判断是否将要结束进程)
void work(int rfd)
{
while (true)
{
int command = 0;
int n = read(rfd, &command, sizeof(command));
if (n == sizeof(int))
{
std::cout << "pid is : " << getpid() << " handler task" << std::endl;
ExcuteTask(command);
}
else if (n == 0)
{
std::cout << "sub process : " << getpid() << " quit" << std::endl;
break;
}
}
}
//值得一提的是:形参类型和命名规范:
// const &: 输入型参数
// & : 输入输出型参数
// * : 输出型参数
//●创建管道和子进程
void CreateChannelAndSub(int num, std::vector<Channel> *channels)
{
// 老师说有个小BUG
for (int i = 0; i < num; i++)
{
// 1. 创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
exit(1);
// 2. 创建子进程
pid_t id = fork();
if (id == 0)
{
close(pipefd[1]);
work(pipefd[0]);//子进程执行任务(刚创建时会因为执行任务时读不到东西而阻塞等待)
close(pipefd[0]);
exit(0);
}
// 3.构建一个channel名称
std::string channel_name = "Channel-" + std::to_string(i);
// 父进程
close(pipefd[0]);
// 记录管道
channels->push_back(Channel(pipefd[1], id, channel_name));
}
}
//用于计算父进程下次要向那个管道里写入->下一个执行任务的子进程是哪个
int NextChannel(int channelnum)
{
static int next = 0;//静态变量
int channel = next;
next++;
next %= channelnum;
return channel;
}
//父进程写入任务码
void SendTaskCommand(Channel &channel, int taskcommand)
{
write(channel.GetWfd(), &taskcommand, sizeof(taskcommand));
}
//单次进程控制(父进程随机选择一个任务->依次向每个管道写入该任务码)
void ctrlProcessOnce(std::vector<Channel> &channels)
{
sleep(1);
// a. 选择一个任务
int taskcommand = SelectTask();
// b. 选择一个信道和进程
int channel_index = NextChannel(channels.size());
// c. 发送任务
SendTaskCommand(channels[channel_index], taskcommand);
std::cout << std::endl;
std::cout << "taskcommand: " << taskcommand << " channel: "
<< channels[channel_index].GetName() << " sub process: " << channels[channel_index].GetProcessId() << std::endl;
}
//●进程控制(指定父进程要派几次任务)
void ctrlProcess(std::vector<Channel> &channels, int times = -1)
{
if (times > 0){
while (times--){
ctrlProcessOnce(channels);
}
}
else{
while (true){
ctrlProcessOnce(channels);
}
}
}
//●回收管道和子进程(我们的具体流程:父进程关闭对应的wfd->子进程work函数里read返回值为0,我们判断子进程该结束了 -> 退出work函数,关闭子进程的rfd,子进程退出 -> 父进程等待成功)
void CleanUpChannel(std::vector<Channel> &channels)
{
for (auto &channel : channels)
{
channel.CloseChannel();
}
for (auto &channel : channels)
{
channel.Wait();
}
}
//★
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cerr << "Usage: " << argv[0] << " processnum" << std::endl;
return 1;
}
int num = std::stoi(argv[1]);
LoadTask();
std::vector<Channel> channels;
// 1. 创建信道和子进程
CreateChannelAndSub(num, &channels);
// 2. 通过channel控制子进程
ctrlProcess(channels, 5);
// 3. 回收管道和子进程. a. 关闭所有的写端 b. 回收子进程
CleanUpChannel(channels);
// sleep(100);
return 0;
}
关于代码中提到的BUG:
我们看 CleanUpChannel 这个函数,它抽象的把关闭管道和等待子进程分开进行——为什么不一起进行呢?
如果你把他们写在一起,就会发现在子进程退出这步卡着不动了
原因:
稍微分析可知,如果创建了两个子进程,父子进程间的读写情况如下:
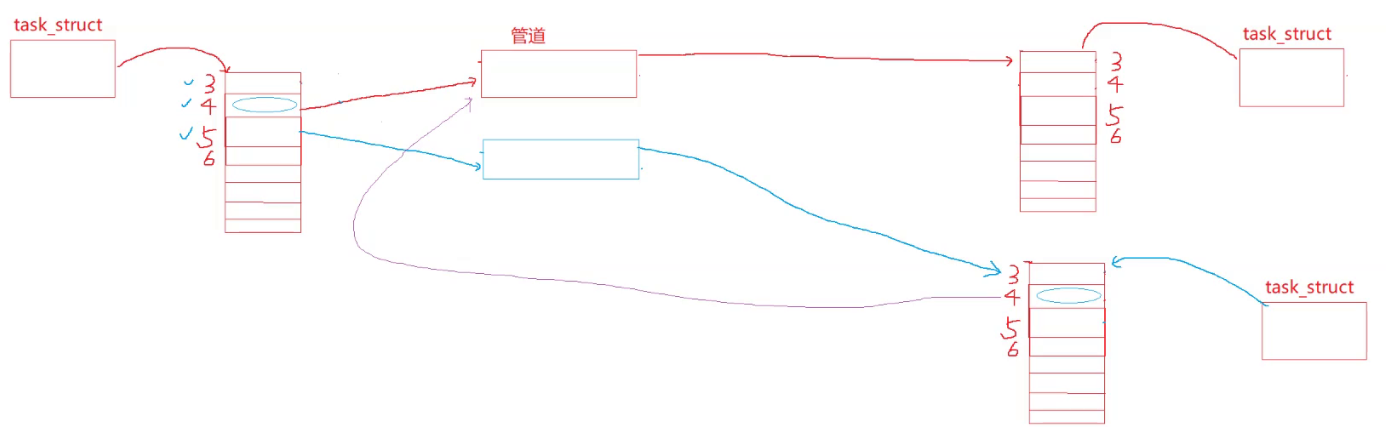
可见子进程(上)有两个写入端
如果是三个子进程:

解决方法:
//在子进程创建后加上:
if (!channels->empty()){
// 第二次之后,开始创建的管道
for(auto &channel : *channels) channel.CloseChannel();
}
//关闭子进程中(channel记录的)所有的wfd
命名管道
具有血缘关系的进程可以使用 匿名管道 进行通信,两个毫不相关的进程使用 命名管道
同匿名管道,两个进程想要使用命名管道就需要都能打开这个管道文件 —— 怎么打开:每一个文件都有其唯一的文件路径
指令创建命名管道
mkfifo [OPTION]... NAME...

while :;do sleep 1; echo "hello"; done >> myfifo

在另一个终端下可以看到:
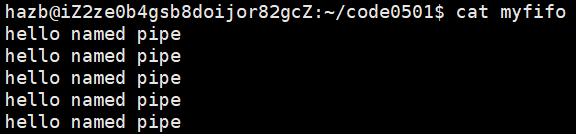
在这过程中,也可以查看到 myfifo 文件的大小一直是 0
如果停止读取,会发现原先的终端直接退出了 —— 读端关闭,写端却一直在写,写端就会退出,echo是内建命令,是bash在执行
系统调用创建:
man 3 mkfifo 可以查看(这不就是一个东西吗):
//下面的参数mode是管道的权限
//返回值:成功0,失败-1

man 2 unlink 可以查看:
//返回值:成功为0,失败设置错误码

//makefile
//两个待通信的进程:client server
.PHONY:all
all:client server
client:client.cc
g++ -o $@ $^ -std=c++11
server:server.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -rf client server
//namedPipe.hpp
#include<iostream>
#inlcude<cstdio>
#include<cerror>
#include<string>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
const std::string comm_path = "./myfifo";//命名管道名
//创建管道
int CreatNamedPipe(const std::string &path){
int res = mkfifo(path.c_str(), 0666);
if(res != 0) perror("mkfifo");
return res;
}
//删除管道
int RemoveNamedPipe(const std::string& path){
int res = unlink(path.c_str());
if(res != 0) perror("unlink");
return res;
}
//server.cc
#include"namePipe.hpp"
int main(){
CreatNamedPipe(comm_path);
sleep(3);
RemoveNamedPipe(comm_path);
return 0;
}
创建和删除管道一定得有一方去做(这里我们让server来,client就不用了)
之后再让一方去读,另一方去写即可
SystemV
共享内存(shm)
管道复用了内核中文件相关的代码以实现通信,并未专门为通信设计一个新的方案
而本地通信方案 SystemV IPC (IPC即进程间通信) 则是专门设计的新的方案
虽然这个通信方案因为现在的网络通信更牛逼、其与文件之间没什么关联而不能很好的在Linux一切皆文件的思想下发光发热……等等原因用的不多,但我们这里还是要学习其中的 共享内存
系统调用:申请共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
//key:用户设置的用于标识共享内存的字段(具有唯一性) size:共享内存大小 shmflg:参考系统调用open,标志位,以位图的方式传递信息
//最常用标志位:
//IPC_CREAT:若要创建的共享内存不存在则创建,存在则获取该共享内存并返回 -> 总能获取一个共享内存
//IPC_EXCL:单独使用没有意义
//IPC_CREAT|IPC_EXCL:若要创建的共享内存不存在则创建,存在则出错返回 -> 成功返回说明该共享内存是全新的
//两个进程通信,总要有一个进行创建(IPC_CREAT|IPC_EXCL)和删除,另一个获取(IPC_CREAT)
//返回值:成功返回共享内存的标识符,失败返回-1,设置错误码(那么这个和key之间的区别是什么呢——后面说)
随机生成key值:
//由操作系统提供但其实算不上系统调用(因为其主要就是做算法方面的设计)
#include <sys/type s.h>
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
//pathname:路径 proj_id:项目id
//返回值:成功返回key值,失败返回-1,错误码表明失败原因
使用相同的路径名和id就能得到同一个key值 -> 两进程一个用这个key值申请共享内存,另一个用这个key值即可获取共享内存
命令行指令:显示与进程间通信有关的信息
ipcs [选项]//-m:显示共享内存

命令行指令:删除与进程间通信有关的信息
ipcrm [选项]
发现 ipcrm -m 0x660103e0 没有用,ipcrm -m 20 才能删除如上的共享内存
key:用户形成,内核使用(用于区分shm的唯一性)的一个字段,用户不能使用key来进行shm的管理
shmid:内核给用户返回的一个标识符,用来进行用户级对共享内存进行管理的id值(以上shmget的返回值就是这个)
系统调用:控制共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
//cmd:对共享内存的操作(eg.删改查) IPC_RMID:删除共享内存,成功返回0,否则-1
//buf:因为这个接口的作用是控制共享内存,这个输出型参数可以获取共享内存的属性
示例(创建、获取共享内存):
//Shm.hpp
#ifndef __SHM_HPP__
#define __SHM_HPP__
#include <iostream>
#include <string>
#include <cerrno>
#include <cstdio>
#include <cstring>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
const int gCreater = 1;
const int gUser = 2;
const std::string gpathname = "/home/hazb/code0501";
const int gproj_id = 0x66;
const int gShmSize = 4096; // 4096*n
class Shm
{
private:
//计算key值
key_t GetCommKey()
{
key_t k = ftok(_pathname.c_str(), _proj_id);
if (k < 0)
{
perror("ftok");
}
return k;
}
//申请共享内存(根据两个进程身份的不同(gCreater,gUser)分为:创建和获取)
int GetShmHelper(key_t key, int size, int flag)
{
int shmid = shmget(key, size, flag);
if (shmid < 0)
{
perror("shmget");
}
return shmid;
}
public:
Shm(const std::string& pathname, int proj_id, int who)
: _pathname(pathname), _proj_id(proj_id), _who(who)
{
//计算key值
_key = GetCommKey();
//申请共享内存
if (_who == gCreater)
GetShmUseCreate();
else if (_who == gUser)
GetShmForUse();
std::cout << "shmid: " << _shmid << std::endl;
std::cout << "_key: " << ToHex(_key) << std::endl;
}
~Shm()
{
if (_who == gCreater)
{
int res = shmctl(_shmid, IPC_RMID, nullptr);
}
std::cout << "shm remove done..." << std::endl;
}
std::string ToHex(key_t key)
{
char buffer[128];
snprintf(buffer, sizeof(buffer), "0x%x", key);
return buffer;
}
bool GetShmUseCreate()
{
if (_who == gCreater)
{
_shmid = GetShmHelper(_key, gShmSize, IPC_CREAT | IPC_EXCL | 0666);
if (_shmid >= 0)
return true;
std::cout << "shm create done..." << std::endl;
}
return false;
}
bool GetShmForUse()
{
if (_who == gUser)
{
_shmid = GetShmHelper(_key, gShmSize, IPC_CREAT | 0666);
if (_shmid >= 0)
return true;
std::cout << "shm get done..." << std::endl;
}
return false;
}
private:
key_t _key;//key值(内核用)
int _shmid;//标识符(用户用)
std::string _pathname;//路径名(两者用于计算key值)
int _proj_id; //id
int _who;//进程身份
};
#endif
//server.cc(创建)
#include "Shm.hpp"
int main()
{
Shm shm(gpathname, gproj_id, gCreater);
return 0;
}
//client.cc(获取)
#include "Shm.hpp"
int main()
{
Shm shm(gpathname, gproj_id, gUser);
return 0;
}
//虽然执行的时候最后面打印说"shm remove done..."但其实我们没有让他关闭共享内存(懒得修正这一段代码)
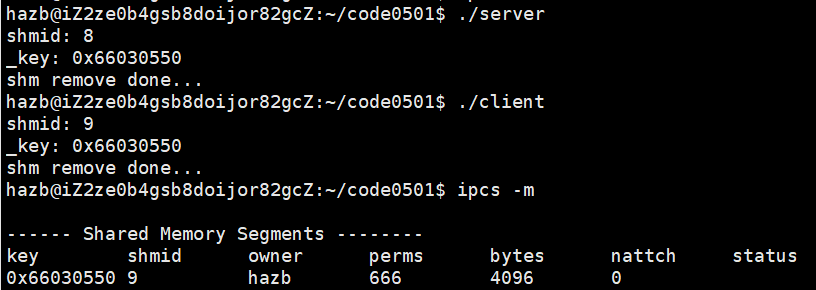
使用共享内存的前提:把共享内存挂接到地址空间上
#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);//attach
//shmaddr:挂接到哪个地址上(暂时不考虑,传nullptr就行) shmflg:访问权限(我们赋予0666) 返回值:地址空间中共享内存的起始地址(失败为nullptr)
int shmdt(const void *shmaddr);//detach
//参数传shmat的返回值即可取消相应的挂接
挂接之后写端和读端可知直接使用地址进行写入(比如读端返回的 *shmat 为 addr,就可以直接通过addr[0] = ‘a’; addr[1] = ‘b’ 写入)
共享内存的特点
1.不同于管道读端和写端会互相等待,共享内存不提供任何保护机制 —— 会出现读写数据不一致问题(信号量解决了这个问题,但我们不学,我们可以通过在读写端之间建管道来解决这个问题,写端通过管道唤起读端去共享内存读取)
2.访问共享内存时并未使用系统调用(如上我们直接使用地址写入信息,因为共享内存被直接挂接到了进程的地址空间上)—— 共享内存是所有进程IPC中速度最快的
消息队列
SystemV进程间通信的另一种方案
原理:一个进程向另一个进程发送数据块(数据块中存在标识符表示是谁发送的信息)
操作系统内部用队列将进程发送的数据块连接起来:
A和B用消息队列通信:
系统中不止AB在用消息队列通信(不止一个消息队列),故消息队列的头部有属性信息,消息队列会被管理起来
接口:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
//创建消息队列
int msgget(key_t key, int msgflg);//key值,标识符
//控制消息队列
int msgctl(int msqid, int cmd, struct msqid_ds *buf);//cmd--eg.IPC_RMID删除消息队列
//发送数据块
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);//msgp为数据块类型(我们要自己创建):
//struct msgbuf {
// long mtype; //数据类型,>0
// char mtext[1];//数据内容
//};
//接收数据块
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
命令:
ipcs -q//查看消息队列
ipcrm -q msgid//删除
信号量
概念渗透
1.共享资源:多个执行流(进程)能看到的资源
2.同步和互斥:即不同进程能否同时访问一份资源(互斥–不能)
3.临界资源:被(用互斥的方式)保护起来的资源
4.临界区:资源注定是要被程序员访问的 -> 通过代码访问 -> 代码 = 用于访问共享资源的代码(临界区) + 不用于访问共享资源的代码(非临界区)
5.对共享资源进行保护本质是对访问共享资源的代码进行保护(保护临界区)
对信号量的认识
信号量,也称信号灯,用于保护临界资源(如上所述,本质是保护临界区)
我们此前学习中,对于共享内存都是把他当做一个整体去使用,实际上它可以被进行划分为许多的部分:

信号量本质就是一个计数器 -> 当信号量计数只能为1或0时 即是把共享资源当做整体使用了(二元信号量)
进程则通过申请信号量去访问共享内存 —— 申请信号量的本质就是对共享资源的一种预定机制
和共享内存、消息队列一样,信号量也需要被进程看到才能使用
信号量也是公共资源,它必须先保证自己的安全性 -> 信号量的++和–操作被设计成了“原子性”的操作(eg.在当前的–操作完成前,它是不会进行其他操作的–为什么这么说,因为普通的–看似就是一个命令,实际被编译后就不止一条命令了,而将其设计成“原子性”的操作后就是一条命令,在执行过程中不会有其他命令能参与进来)
信号量的 – 称为P操作,++称为V操作
信号量的操作(了解就行)
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
//申请信号量(允许一次申请多个,操作系统就会维护一个信号量集)
int semget(key_t key, int nsems, int semflg);//nsems:申请几个信号量
//控制信号量
int semctl(int semid, int semnum, int cmd, ...);//semnum:若申请了多个信号量,即表示要对哪个信号量进行操作(只申请了一个则传入0),cmd:可以进行诸如设置信号量初始值的操作
//...可以传入参数去获取信号量集的属性:
//struct semid_ds {
// struct ipc_perm sem_perm; /* Ownership and permissions */ ->可以看见这里也有ipc_perm结构
// time_t sem_otime; /* Last semop time */
// time_t sem_ctime; //信号量最近一次被改变的时间
// unsigned long sem_nsems; //信号量的个数
//};
//信号量的P、V操作
int semop(int semid, struct sembuf *sops, size_t nsops);//sops:信号量集 nsops:表示要进行操作的信号量有几个
//struct sembuf{//若申请了多个信号量(比如3个)那就创建并传入 struct sembuf[3]
// unsigned short sem_num; //3个信号量分别为 0 1 2(只有1个的话就是0)
// short sem_op; //-1表示对信号量值--,1表示++
// short sem_flg; /* operation flags */
//}
ipcs -s //查看信号量
ipcrm -s semid//删除
OS对共享内存、消息队列、信号量的管理
可以通过man指令看到这些结构:
可以看到三者都具有ipc_perm结构体

















 6328
6328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









