






爬虫工程师面试题
http协议
- GET和POST有什么区别?
1):数据传输不用:get使用url传输数据。post则通过请求体提交数据
2):安全性不同:get安全性低,post的安全性高
3):幂等性:get请求时幂等的。多次执行统一get请求会返回相同结果。post不是幂等的,每次提交会创建新的资源
4):缓存:get请求可以缓存,post则不会 - http2的特点:
1):二进制分帧:不再使用文本格式传输数据,而将信息分割帧,通过二进制方式传输
2):多路复用:允许单个tcp连接中并行处理多个请求和响应。
3):头部压缩:即共享头部信息,减少网络的消耗
4):服务器推送(Server Push): 服务端可以主动给客户端发消息 - http的请求和响应报文是什么样子的?
1):请求:请求行,请求头部,请求体组成
2):响应:状态行,响应头,响应数据组成的 - 从输入url到看到页面的过程?
1):输入url
2):解析url:(浏览器内部解析URL,先查询本地hosts文件,如果没有则浏览器将域名转发DNS解析,将域名转化ip成对应服务器的ip地址)
3):建立TCP连接:浏览器拿到ip地址后,建立tcp连接。这一过程需要三次挥手,确保通讯连接
4):发送HTTP请求:建立连接后,会向服务器发送请求。
5):服务器处理请求并返回响应数据。
6):浏览器解析和渲染页面 - 跨域和解决思路:
跨域指浏览器出于安全考虑,会限制从一个源(域名+端口)加载的脚本访问另一个源的资源。
常见解决思路:
1):CORS(跨域资源共享):服务器在响应头添加 *告诉浏览器我允许这个源来访问
2):JSONP:利用 script 标签不受同源限制的特点,通过回调函数接收服务器返回的 JSON 数据
3):代理转发:加入中间层 Nginx
4):Window.postMessage。
5):WebSocket - 浏览器的渲染机制是什么样子的?
1):加载html,css,js资源
2):构建 DOM 树:html解释器会从html标签解析开始,遇到开始标题则创建DOM节点,遇到结束标签就回退
3)构建 CSSOM 树
4)布局:会根据渲染树的信息计算每个节点的大小,生成布局。
5)绘制:会将每个节点的样式转为像素,绘制到屏幕上 - 浏览器事件和node事件:
1):浏览器有 DOM 专用的事件模型(捕获→目标→冒泡),事件循环 interleave 宏/微任务和渲染;
2):Node 用 EventEmitter 发布/订阅,事件循环按“Timers→Pending→Poll→Check→Close”阶段执行,并在各阶段后清空微任务(nextTick 优先于 Promise) - tcp和ucp的区别:
1):连接:tcp建立连接前需要握手会挥手,ucp则不需要。
2):可靠机制:tcp会在每个字节打上序号,对应ack应答。超时重传,保证数据完成。ucp丢包不重传
3):流量与堵塞:tcp使用滑动窗口控制接收方压力,利用慢启动,堵塞避免来应对网络堵塞,ucp:不做任何流量控制。 - tcp三次挥手和四次响应?
三次挥手:
1):SYN:客户端发送 SYN (客户端的初始序列号)报文到服务器,请求建立连接
2):SYN‑ACK:服务器收到报文,会发送SYN-ACK包,表示同意连接并确认客户端的序列号
3):ACK:服务端收到后,在发送ACK报文建立连接。
四次响应:
1):客户端发送FIN包到服务器
2):服务器发送ACK包到客户端
3):服务器发送FIN包到客户端
4):客户端发送ACK包到服务器 - COOKIE和SESSION有什么区别?
python基础
- 爬虫中的可变数据类型和不可变数据类型有哪些?
1):不可变数据类型:整数、浮点数、字符串、元组、布尔
2):可变数据类型:列表、集合、字典 - 深拷贝和浅拷贝的区别是什么?
浅拷贝:只复制对象的指针,而不是复制对象本身,新旧对象还是公用一块内存
深拷贝:会创造一个一摸一样的对象,新对象和老对象不共用一块内存,修改新对象不会影响老对象。 - 什么是Python中的装饰器(Decorator)?有什么用途?
装饰器是一种设计模式,在不改变原来代码的基础上,为函数或类添加新功能。通过包装函数来实现。用途:日志记录,性能测试 - 什么是Python中的生成器(Generator)?如何使用?
生成器是一种特殊的迭代器,使用yield关键字逐个生成值。而不是一次生成所有值,节约内存。 - 什么是Python中的闭包(Closure)?有什么用途?
闭包是一个函数。他引用了外部作用域的变量,即使外部作用域已执行完毕也能访问这些变量。常用于创建装饰器、工厂函数或保存状态 - python中的__init__和__new__方法有什么区别?
1):init:初始化对象,在创建对象后调用。参数:self和其他初始化参数
2):new:创建对象实例,在__init__前调用。 - 什么是python中的GIL?有什么影响
GIL是python解释器中的全局锁。限制同一时刻只有一个线程执行python字节码 - 如何在Python中实现单例模式?
单例模式确保一个类只有一个实例,并提供全局访问点,通过重写__new__方法控制实例创建。 - 什么是python中的lamba函数。用什么用途。
匿名函数。用于 - Python 中的 map、filter 和 reduce 函数是什么?
map:对每个元素应用函数,返回迭代器
filter:筛选满足条件的元素。
reduce累积计算,需从 functools 导入。
爬虫框架(Scrapy)
-
简述 Scrapy 框架的基本工作流程,并说明各组件的作用?
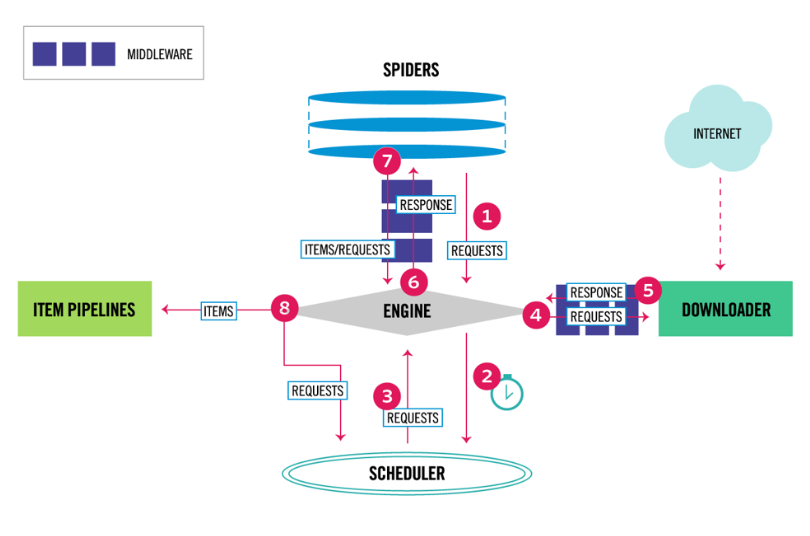
Scrapy是一个python异步爬虫框架。基于Twisted实现高并发爬取。 核心组件:Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spiders(爬虫)、Item Pipeline(管道)以及 Downloader/Spider 中间件。引擎负责协调各部分的数据流,调度器负责管理请求队列,下载器负责获取网页内容,爬虫负责解析页面和生成数据,管道负责后续的数据处理(如清洗、保存),中间件则可以在请求与响应的路径中插入自定义逻辑。
-
解释 Scrapy 的请求调度与并发控制机制。
Scrapy 使用 Twisted 异步框架实现并发非阻塞操作,并通过设置控制并发数和请求延迟。关键设置包括:CONCURRENT_REQUESTS(全局最大并发请求,默认为 16)。CONCURRENT_REQUESTS_PER_DOMAIN(每个域名的并发数上限,默认为 8)。DOWNLOAD_DELAY(下载延迟)以及 AUTOTHROTTLE 扩展,自动根据目标响应时间调整并发和延迟。Scrapy 引擎会从调度器中获取请求,通过异步方式交给下载器。下载完成后,响应回到引擎,再由引擎传给爬虫处理 -
Scrapy 如何处理动态页面?有什么策略?
scrapy本身无法渲染JS内容。但可以借助中间件Scrapy-Playwright。 -
如何使用 Scrapy 下载网页中的图片、文件或视频等二进制内容?
Scrapy 提供了 FilesPipeline 和 ImagesPipeline 来方便地下载和存储媒体内容 -
Scrapy 的异步模型是如何工作的?为什么它能高并发?
Scrapy 基于 Twisted 的 事件驱动异步架构这意味着 Scrapy 发起 HTTP 请求后不会阻塞等待响应,而是注册一个回调函数,当响应到达时再触发回调继续处理。底层使用 Reactor 循环管理事件。因此,Scrapy 可以同时处理多个连接的 I/O 操作而不需为每个请求开启新线程,大大减少了线程上下文切换的开销
puppeteer、playwriht自动化框架
- 如何在 Puppeteer/Playwright 中实现高并发爬取
本质上是对单个浏览器实例的控制。常见策略有:
1):多标签页或者多上下文:在同一个浏览器内打开多个页面同时执行任务。
2):多浏览器实例:开启多个浏览器并发进程。 - 在 Puppeteer 或 Playwright 中,如何防止被目标网站识别为爬虫?
修改/伪装 User-Agent。通过setUserAgent参数。
覆盖插件标记:puppetee使用puppeteer-extra-plugin-stealth自动修复Webdrider检测 - Playwright 在 Python 中如何使用多进程或多线程提高爬取速度?
多进程:使用 Python 的 multiprocessing。每个子进程独立启动一个或多个浏览器实例,互不影响。
异步并发:aywright 的 async API 与 asyncio 结合通过 asyncio.gather() 并行打开多个页面或浏览器上下文 - 比较 Puppeteer 和 Playwright,有什么异同?
相似点:都使用无头浏览器、支持自动等待元素、网络拦截和截图等功能;都可以集成到测试框架。区别:Playwright 原生支持多浏览器,Puppeteer 主要支持 Chromium/Chrome。2。Playwright 支持 Python、Java、.NET 等多语言。puppeteer只支持js。playwriht支持移动端测试。
js逆向及反爬措施
验证码
验证码的作用是什么?
验证码的作用是防止恶意爬虫或自动化脚本注入。保证网站的安全性和数据的完整性
验证码的主要类型?
文本验证码、图像验证码、旋转验证码、行为验证码、滑动验证码
遇到验证码时通常有哪些解决方案?
降低爬虫频率:设置合理的延迟避免触发验证码
ip/账号切换。当遇到验证码时候切换ip绕过限制
打码平台:调用第三方打码平台服务。将图片发送平台获取结果
使用OCR:对于简单的验证码使用cor库tessract识别。图像预处理:在OCR前对图像进行二值化、去噪、腐蚀膨胀等处理,提高识别准确率。可借助 OpenCV 等库实现。
ip
- 什么是ip地址轮换?为什么需要它?
ip轮换是指在爬虫中ip定时轮换更新使用的ip地址。避免单个ip因访问频率过高而被目标网站检查和封禁。 - 在爬虫中如何使用代理ip?
发起请求时指定proxies参数。
在Scrapy中:使用代理:request.meta配置代理
Playwright:可以在启动浏览器时通过无头代理参数指定代理
常见反爬机制及应对方法
- UA检测/Refere:网站通过检查请求头的 User-Agent 字段来识别爬虫工具。对策是在请求时随机或伪装为常见浏览器的 User-Agent
- 请求频率:如果同一 IP 短时间内请求过多,服务器可能封禁该 IP。对策是控制并发量和请求间隔
- IP 限制:基于 IP 的封禁或黑名单,常见于流量阈值检测。对策是使用代理池进行 IP 轮换
- Cookie/登录验证:部分页面在访问前需要登录获取特定 Cookie对策是模拟登录流程,获取并携带有效的 Cookie 才能获取数据
- 验证码:如同上题所述,当检测到异常行为时会弹出验证码。常用 OCR、打码平台或模拟行为等方式解决
- JavaScript 渲染或动态加载:Playwright来获取内容;使用Requests-HTML。这是一个基于 requests 的库,内置了对 Chromium 的支持,可以通过 render() 方法执行 JavaScript
- 浏览器指纹检测:
正常浏览器中 navigator.webdriver 为 undefined,而使用 Selenium 或 Playwright 时默认为 true。 - WebGL/Canvas 指纹:通过 WebGL 参数或 Canvas 绘图值来区别不同浏览器或设备指纹。一些自动化环境可能会有特征性的值
- 如 Puppeteer 的 puppeteer-extra-plugin-stealth 或 Playwright 的相关库,可以自动修改用户代理、WebGL 参数、屏蔽无头特征等
常见的加密
- 对称加密:AES,DES
- 非对称加密:RSA
- 哈希加密:MD5,SHA-256


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









