






1、什么是布隆过滤器
以下定义来自百度百科:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
从上述定义我们可以得到以下关键信息:
布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。
布隆过滤器的作用是检索一个元素是否存在我们的集合之中。
优点是空间效率和查询时间都比一般的算法要好的多;缺点是有一定的误识别率和删除困难。
2、布隆过滤器的应用场景
1.用于防止redis缓存的击穿
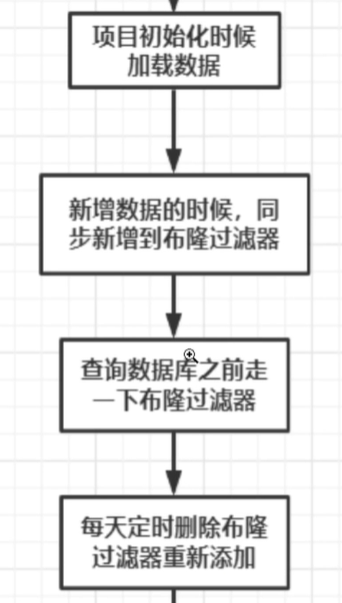
2.使用布隆过滤器+唯一消息ID来保证消息队列的消费的幂等性(防止重复消费)
具体的情况如下:
生产者在数据发送时,将数据放入布隆过滤器,消费者在消费数据的时候先去布隆过滤器中查看是否使用过,如果使用过了,则说明已经消费过,则进行数据的丢弃,如果没有,进行消息的消费并返回ack
3、布隆过滤器的原理
布隆过滤器其实是一串很长很长的数组例如
000000000000000000000000000000000
这个数组的长度在初始化布隆过滤器时,是可以被指定的
当有一个数据插入布隆过滤器时,就会有几个哈希函数对这个数据进行哈希计算,将计算的结果放到对应的槽中
例如
001001000010000000000000000000000
下次再来数据的时候,该数据会被哈希函数进行计算,然后到相应的位置进行检查,如果有一个位置是0,则代表不存在;
解析:为什么有一个位置是0就是不存在呢?
因为布隆过滤是有几率会有覆盖的情况的,可能会出现某一个位置被其他的数据的1进行了覆盖,所以要检查所有的,只要是有一个位置是0就代表着博隆过滤器之前没有进行这个数据的插入,这也是为什么布隆过滤器说数据在,那么有可能在,说数据不在,那么数据一定不在


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









