






专栏:写这篇文章为了分享一下我在机器学习中一些感悟。感兴趣的小伙伴欢迎私信或者评论区留言!我们一起探讨。
梯度下降算法概述
本文旨在利用具体的例子帮助大家理解梯度下降算法的基本原理,不做严谨的推导。
随机梯度下降法是一种优化算法,在线性回归分析中主要用于优化线性函数的特征值的权重,使其更准确,从而得到更好的预测模型。
我将用一个形象的例子,帮助大家理解。
案例分析
假设我们有关于房子价格(**y**)与房子面积(**x1**);中心区域距离(**x2**)和城市一氧化碳浓度(**x3**)这三个自变量的数据100条。
例:
| 房子价格(y) | 房子面积(x1) | 中心区域距离(x2) | 城市一氧化碳浓度(x3) |
|---|---|---|---|
| 12000 | 43 | 50 | 3 |
| 14000 | 66 | 70 | 5 |
| ... | ... | ... | ... |
此数据可以写成y=ax1+bx2+cx3+d的格式,其中a,b,c为自变量系数,也称为特征值的权重;d为偏置值;y为结果,也称为标签值。例如:12000=a*43+b*50+ c*3+d。这就是把一条数据写为函数格式。
假设新增了一条数据:
| 房子价格(y) | 房子面积(x1) | 中心区域距离(x2) | 城市一氧化碳浓度(x3) |
|---|---|---|---|
| 未知 | 56 | 30 | 4 |
代价
显而易见,我们如果已知abcd的值便可以轻松的求得房子价格。从这里开始便要用到梯度下降算法。
梯度下降算法步骤
1.假设法
要算出abcd的值,我们首先想到假设法,随机假设三个变量的权重和偏置值分别为a=30,b=5,c=6,d=10000。我们带入已知数据算出:43*30+5*50+3*6+10000=11558。发现与12000不等,说明随机假设的权重不准确。
那我们需要做的有俩步,第一是度量这个权重有多不准确;二是我如何能让这个权重变得准确。
2.引入代价函数
所谓代价函数就是用来度量这个权重有多不准确,对于一条数据我们用12000-11558就可以度量,显而易见,得出的结果越小,我们假设的权重值就越准确。对于多条数据,需要刨除负值与异常值的影响,我们使用平方与取平均值的方法;即: (其中z为:第二条数据乘假设权重。)
数据公式如下,与上面例子同理,J()为代价函数。
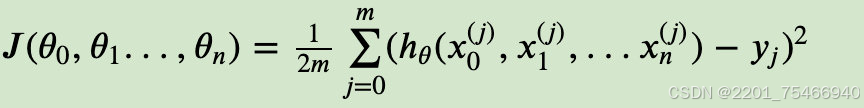
我们就可以通过代价函数来观测出权重有多不准确。
3.代价函数优化
第二步我们需要让我们假设的权重值一步一步的变得准确。显然只要代价函数的值越来越小,即权重的值就越来越准确。如何让代价函数越来越小呢?
我们观察代价函数,代价函数由abcd四个自变量组成,而我们的假设法就可以看成取了abcd的一个特殊值,即:a=30,b=5,c=6,d=10000,也就是代价函数中的一个点(称为假设点)。代价函数有四个自变量则为四维空间函数,我们只需要找到这个函数的最小值即代价函数最小,此时abcd为最优权重。
此时就是梯度下降算法的核心,我们求函数在假设点的导数,此时要用到多元函数求导,由于多元函数在一点有无穷多方向的导数,我们只需要找到一个斜率最大的方向,即在此方向上代价函数可以下降最快。
此时我们需要引入一个常量,用来控制下降距离。防止出现以下状况:
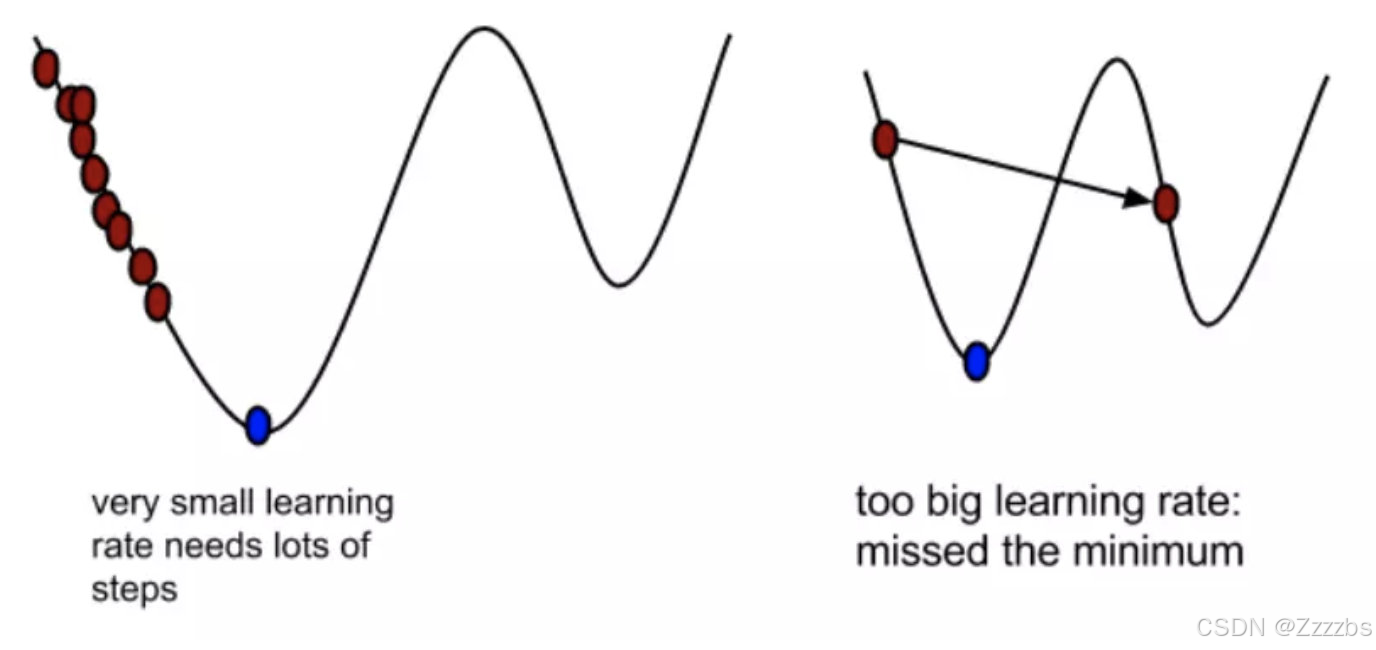
4.迭代
如上图所示,我们会一个点一个点的往下走,直到找到最低点,即为代价函数最小值,此时abcd也为最优权重。
5.结束迭代
我们设计一个常数,当梯度下降距离都小于
时迭代结束。
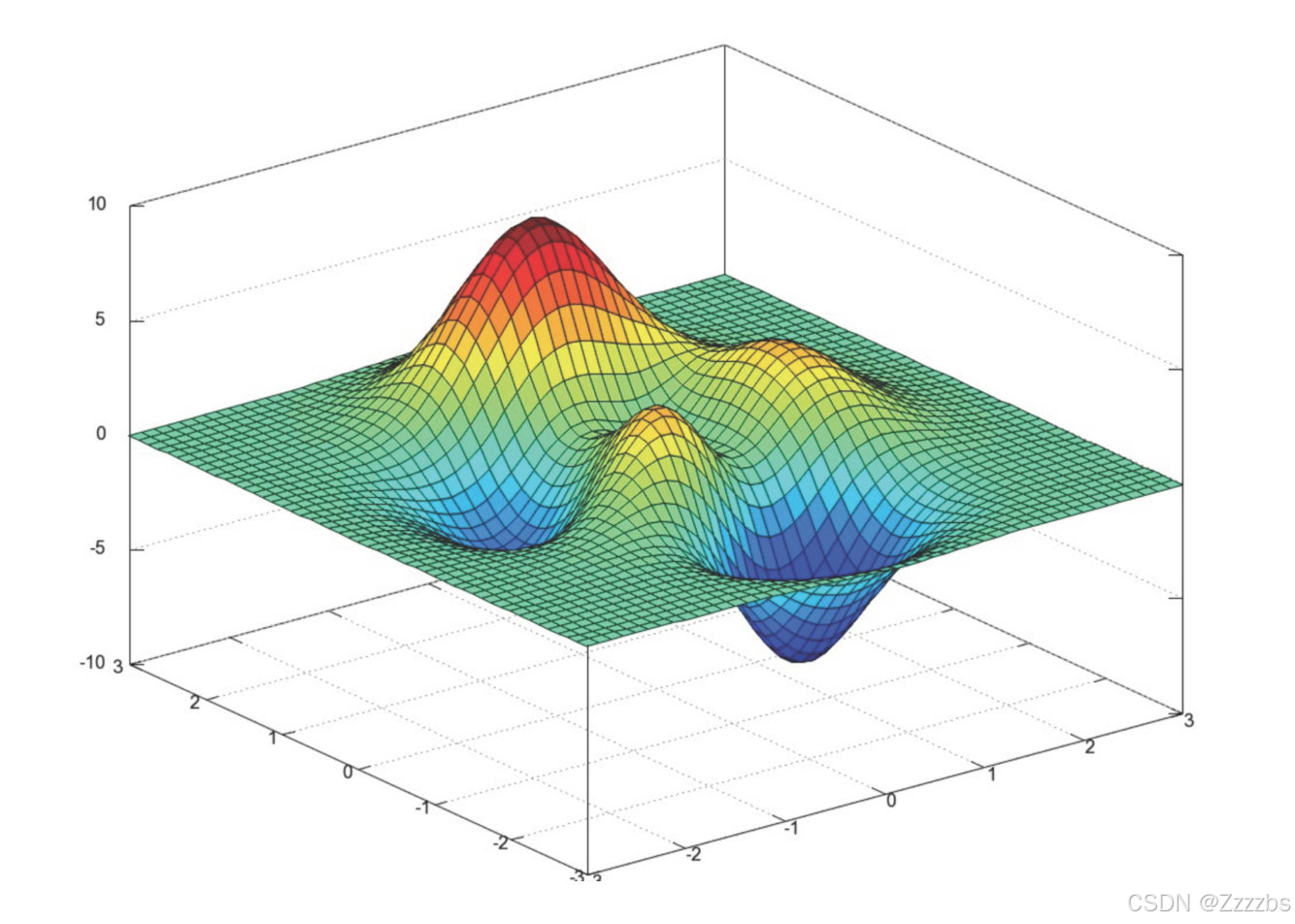
6.算法问题
目前梯度下降算法最大的问题就是无法找到最优值,只能找到相对优值,因为在多元函数中有很多谷底,即只能找到极小值,无法找到最小值。如图所示:
总结:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









