






Intel oneAPI 简介
Intel oneAPI是Intel提供的统一o编程模型和软件开发框架。 它旨在简化可充分利用英特尔各种硬件架构(包括 CPU、GPU 和 FPGA)的应用程序的开发。
oneAPI 提供了一组工具、库和框架o,使开发人员能够编写跨不同硬件平台的高性能代码。 它支持多种编程语言,包括 C++、Fortran 和数据并行 C++ (DPC++)。 借助 oneAPI,开发人员可以使用熟悉的编程模型编写代码并针对不同的硬件架构,而无需对代码进行重大修改。
推荐的软件硬件环境
使用oneAPI中支持SYCL编程模型的C++编译器 ,利用CPU作为主机(Host)同时利用GPU作为设备(Device)完成作业,可选利用CPU作为设备(Device)进行运行性能比对和讨论。
推荐使用英特尔oneAPI Developer Cloud 服务,可免安装额外环境,直接利用Developer Cloud平台中的CPU与GPU硬件。 相应注册及启用服务可参考相应的使用手册,关于在登录节点上运行的JupyterLab递交代码到计算节点的排队系统的相关操作方式及命令,可以参考任务递交相应命令参考 以及 队列管理参考 。
如果使用自有硬件,推荐使用基于英特尔酷睿6代或更新版本的处理器与系统中同时可用的基于Xe或Arc的集成显卡,通过完成与安装操作系统配套的相应oneAPI软件工具,通过构建自有开发环境方式。 相应的工具可参考oneAPI基础工具套件或独立编译器的网页, 硬件要求可参考发布说明中的具体要求。
如果使用的自有硬件,同时包含有英特尔酷睿6代或更新版本的处理器以及Nvidia的GPU,也可以尝试在安装参考oneAPI基础工具套件后,通过安装CodePlay提供的oneAPI支持Nvidia插件,参考安装指南进行环境搭建。
SYCL编程实战——矩阵乘法
要求
组建2个序列(向量)的浮点数,每个序列的规格是N(如N=1024*1024),构成矩阵输入值。用随机值初始化序列。使用缓存和存储来实现对设备(GPU)上矩阵内存的分配并运行。运行SYCL Kernel实现两个矩阵的并行运算,运用SYCL nd_range概念来定义Kernel的运行范围。使用SYCL排队系统来运行设备上的Kernel。 Kernel运行结束后,使用存储将结果从设备(GPU)检索回主机。
使用Buffer-Accessor Memory Model
为了控制主机和设备之间的数据共享和传输,SYCL 提供了一个 buffer 类。这里使用二维的buffer,能更直观的展现矩阵相乘。
//创建三个vector,两个用来存输入矩阵,一个用来存输出矩阵
std::vector<float> A(Size),B(Size),C(Size,0);
//随机数初始化A和B矩阵
std::mt19937 rng(42);
uniform_int_distribution<int> dist(0, 4);
for (size_t i = 0; i < Size; i++) {
A[i] = dist(rng);
B[i] = dist(rng);
}
//创建二维buffers
buffer<float, 2> Matrix1_buffer(A.data(), range<2>(N, N)),
Matrix2_buffer(B.data(), range<2>(N, N)), Output_buffer(C.data(), range<2>(N, N));
接下来是创建队列。队列是一种将工作提交给设备的机制。
queue q;
begin=clock();
q.submit([&](handler &h) {
//创建与buffer相对应的accessor
accessor M1 (Matrix1_buffer,h,read_only);
accessor M2 (Matrix2_buffer,h,read_only);
accessor M3 (Output_buffer,h,write_only);
//执行并行运算
h.parallel_for(nd_range<2>({N, N}, {16, 16}), [=](nd_item<2> item) {
//# Multiplication
size_t row = item.get_global_id(0);
size_t col = item.get_global_id(1);
for (size_t k = 0; k < N; ++k) {
M3[row][col] += M1[row][k] * M2[k][col];
}
});
});
在计算矩阵乘法需要用到二维的nd_range,具体原理如下图:

最后还需要创建一个accessor来进行结果的读取
//创建host accessor读取最终结果
host_accessor h_a(Output_buffer,read_only);
完整代码如下:
%%writefile lab/vector_add.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <sycl/sycl.hpp>
#include <iostream>
#include <vector>
#include <random>
#include<ctime>
using namespace sycl;
using namespace std;
//# Reference of the former method to select the best device
class CustomDeviceSelector {
public:
CustomDeviceSelector(std::string vendorName) : vendorName_(vendorName){};
int operator()(const device &dev) {
int device_rating = 0;
//We are querying for the custom device specific to a Vendor and if it is a GPU device we
//are giving the highest rating as 3 . The second preference is given to any GPU device and the third preference is given to
//CPU device.
if (dev.is_gpu() & (dev.get_info<info::device::name>().find(vendorName_) !=
std::string::npos))
device_rating = 3;
else if (dev.is_gpu())
device_rating = 2;
else if (dev.is_cpu())
device_rating = 1;
return device_rating;
};
private:
std::string vendorName_;
};
int main() {
const int N = 1024;
const int Size = N * N;
clock_t begin,end;
double t;
//# Create two vectors for the input matrices and one for the output
std::vector<float> A(Size),B(Size),C(Size,0);
//# Initialize matrices A and B with random values
std::mt19937 rng(42);
uniform_int_distribution<int> dist(0, 4);
//std::uniform_real_distribution<float> dist(0.0, 1.0);
for (size_t i = 0; i < Size; i++) {
A[i] = dist(rng);
B[i] = dist(rng);
}
std::cout<<"\nInput Matrix1:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << A[i*N+j] << " ";
}
std::cout << "\n";
}
std::cout<<"\nInput Matrix2:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << B[i*N+j] << " ";
}
std::cout << "\n";
}
//# Create buffers
buffer<float, 2> Matrix1_buffer(A.data(), range<2>(N, N)),
Matrix2_buffer(B.data(), range<2>(N, N)), Output_buffer(C.data(), range<2>(N, N));
//# Choose the best device
// Pass in the name of the vendor for which the device you want to query
std::string vendor_name = "Intel";
// std::string vendor_name = "AMD";
// std::string vendor_name = "Nvidia";
CustomDeviceSelector selector(vendor_name);
//# Submit task to multiply matrices
queue q(selector);
begin=clock();
q.submit([&](handler &h) {
//# Create accessors for buffers
accessor M1 (Matrix1_buffer,h,read_only);
accessor M2 (Matrix2_buffer,h,read_only);
accessor M3 (Output_buffer,h,write_only);
h.parallel_for(nd_range<2>({N, N}, {16, 16}), [=](nd_item<2> item) {
//# Multiplication
size_t row = item.get_global_id(0);
size_t col = item.get_global_id(1);
for (size_t k = 0; k < N; ++k) {
M3[row][col] += M1[row][k] * M2[k][col];
}
});
});
//# Create a host accessor to copy data from device to host
host_accessor h_a(Output_buffer,read_only);
end=clock();
//# Print Output values
std::cout<<"\nOutput Values:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << C[i*N+j] << " ";
}
std::cout << "\n";
}
t=double(end-begin)/CLOCKS_PER_SEC;
std::cout<<"RUN_TIME:"<<t<<"\n";
return 0;
}由于源代码采用两个1024*1024的矩阵相乘不方便展示,此处展示将N改为4后(同时nd_range需要修改为nd_range<2>({N, N}, {2, 2})的运行结果,如下图:

使用Unified Shared Memory
相交于Buffer-Accessor Memory Model,Unified Shared Memory(简称USM)更为简洁,其原理是开辟一片CPU和GPU可以公共使用的内存区域。
这里使用malloc-shared开辟内存
//使用malloc_shared开辟内存
float *M1 = malloc_shared<float>(Size, q);
float *M2 = malloc_shared<float>(Size, q);
float *M3 = malloc_shared<float>(Size, q);
//初始化同Buffer-Accessor Memory Model由于空间是线性的,程序中通过一维的方式来表示二维的矩阵(即下标为ij的元素在第i*N+j的位置上)。矩阵乘法的原理同上。
queue q;
q.parallel_for(nd_range<2>({N, N}, {16, 16}), [=](nd_item<2> item) {
//# Multiplication
size_t row = item.get_global_id(0);
size_t col = item.get_global_id(1);
for (size_t k = 0; k < N; ++k) {
M3[row*N+col] += M1[row*N+k] * M2[k*N+col];
}
}).wait();
完整代码如下:
%%writefile lab/usm_lab.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <sycl/sycl.hpp>
#include <iostream>
#include <vector>
#include <random>
#include<ctime>
using namespace sycl;
using namespace std;
//# Reference of the former method to select the best device
class CustomDeviceSelector {
public:
CustomDeviceSelector(std::string vendorName) : vendorName_(vendorName){};
int operator()(const device &dev) {
int device_rating = 0;
//We are querying for the custom device specific to a Vendor and if it is a GPU device we
//are giving the highest rating as 3 . The second preference is given to any GPU device and the third preference is given to
//CPU device.
if (dev.is_gpu() & (dev.get_info<info::device::name>().find(vendorName_) !=
std::string::npos))
device_rating = 3;
else if (dev.is_gpu())
device_rating = 2;
else if (dev.is_cpu())
device_rating = 1;
return device_rating;
};
private:
std::string vendorName_;
};
int main() {
const int N = 1024;
const int Size = N * N;
clock_t begin,end;
double t;
//# Choose the best device
// Pass in the name of the vendor for which the device you want to query
std::string vendor_name = "Intel";
// std::string vendor_name = "AMD";
// std::string vendor_name = "Nvidia";
CustomDeviceSelector selector(vendor_name);
//# Submit task to multiply matrices
queue q(selector);
std::cout << "Device : " << q.get_device().get_info<info::device::name>() << "\n";
//# USM allocation using malloc_shared
float *M1 = malloc_shared<float>(Size, q);
float *M2 = malloc_shared<float>(Size, q);
float *M3 = malloc_shared<float>(Size, q);
//# Initialize matrices A and B with random values
std::mt19937 rng(42);
uniform_int_distribution<int> dist(0, 4);
//std::uniform_real_distribution<float> dist(0.0, 1.0);
for (size_t i = 0; i < Size; i++) {
M1[i] = dist(rng);
M2[i] = dist(rng);
M3[i]=0;
}
std::cout<<"\nInput Matrix1:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << M1[i*N+j] << " ";
}
std::cout << "\n";
}
std::cout<<"\nInput Matrix2:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << M2[i*N+j] << " ";
}
std::cout << "\n";
}
begin=clock();
q.parallel_for(nd_range<2>({N, N}, {16, 16}), [=](nd_item<2> item) {
//# Multiplication
size_t row = item.get_global_id(0);
size_t col = item.get_global_id(1);
for (size_t k = 0; k < N; ++k) {
M3[row*N+col] += M1[row*N+k] * M2[k*N+col];
}
}).wait();
end=clock();
t=double(end-begin)/CLOCKS_PER_SEC;
//# Print Output values
std::cout<<"\nOutput Values:\n";
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
std::cout << M3[i*N+j] << " ";
}
std::cout << "\n";
}
std::cout<<"RUN_TIME:"<<t<<"\n";
free(M1, q);
free(M2, q);
free(M3, q);
return 0;
}
由于源代码采用两个1024*1024的矩阵相乘不方便展示,此处展示讲N改为8后(同时nd_range需要修改为nd_range<2>({N, N}, {2, 2})的运行结果,如下图:

程序运行结果分析
通过调用ctime库中的函数来测量程序的运行时间(已添加到上面给出的代码中)。两个程序使用的相同的随机数种子,以减小测量误差。
当矩阵大小为1024*1024时,两组程序的运行时间对比如下:
使用Buffer-Accessor Memory Model

使用Unified Shared Memory
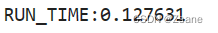
由此可见,当数据运算量大时,使用USM能够提高运行速度。
心得体会
使用SYCL进行编程需要掌握一定的标准和框架。在实验中,我对SYCL的语法和编程模型有了更深入的了解。使用SYCL进行矩阵乘法的过程中,我意识到了异构计算平台的优势。能够在CPU和GPU等不同设备上并行执行代码,有效地利用硬件资源,提高整体性能。同时并行编程通常需要更加深入地理解硬件架构和并行计算的原理。在实验过程中,那些并行性、数据同步和错误处理相关的挑战,对于我日后的进行并行编程任务将会很有帮助。此外,矩阵乘法涉及大量的数据运算,因此对内存的优化显得尤为重要。本次实验让我学到了如何有效地管理数据的内存布局、传输以及缓存的使用,以提高程序的整体性能。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









