






使用场景:DOUYING抓包过程中无法全部抓取,需要下拉页面获取。
导入模块:
from DrissionPage import ChromiumPage, ChromiumOptions
from DrissionPage.common import Actions
import re
import requests
加入代理IP,请求头,定义存放视频链接的列表;代理IP可有可无。
并输入相应网址,获取视频的数量,评论包的数量(评论包数量要写小一点)因为代码并不完善。写个评论少的视频写不要大于5。
proxies = {需要自己获取}
headers = {填写自己的信息}
video_list = []
打开浏览器,并进入相应网站,定义在该网页的动作链。
tab_1 = ChromiumPage().latest_tab
tab_1.get(url)
ac = Actions(tab_1)
move = ac.move_to('x://*[@id="semiTabpost"]/div').click().scroll(500)# 模拟鼠标移动到相应元素xapth位置,左键点击后滚轮转动。
获取子视频链接位置。鼠标一秒向下滚动500个像素,用xapth索引视频在元素中的位置,然后正则化提取,最后拼接成完整视频链接存放在列表中。
for i in range(1, video_count):
move.wait(1)
move.scroll(delta_y=500)
a = tab_1.ele(f'x://*[@id="douyin-right-container"]/div[2]/div/div/div/div[3]/div/div/div[2]/div[2]/div[2]/ul/li[{i}]/div/a')
# print(a)
b = re.findall("<ChromiumElement a href='(.*?)'", str(a))
# print(b)
video = 'https://www.douyin.com'+b[0]
video_list.append(video)
print(video_list)
遍历列表,提取有用链接,创建一个新的标签,打开相应链接,监听相应包,等待包的加载,获取包的内容,返回的是json字典型,通过字典索引提取所需内容。
for i in video_list:
if len(i) == 48:
# print(i)
tab_2 = ChromiumPage().new_tab()
tab_2.get(i)
tab_2.listen.start('/aweme/v1/web/aweme/detail/')
wait = tab_2.listen.wait()
json_data = wait.response.body
title = json_data['aweme_detail']['desc']
video_z = json_data['aweme_detail']['video']["bit_rate"][0]['play_addr']['url_list'][0]
dian_zan_count = json_data['aweme_detail']["statistics"]['digg_count']
ping_lun_count = json_data['aweme_detail']["statistics"]["comment_count"]
shou_can_count = json_data['aweme_detail']["statistics"]["collect_count"]
zhuan_fa_count = json_data['aweme_detail']["statistics"]["share_count"]
print(dian_zan_count)
print(ping_lun_count)
print(shou_can_count)
print(zhuan_fa_count)
print(title)
print(video_z)
创建相应文件来存放内容。
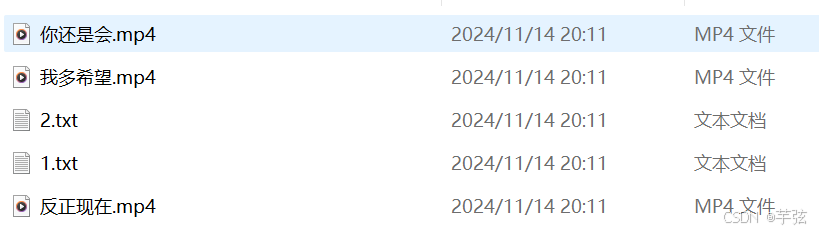
with open(title[0:4]+'.mp4', mode='wb') as f:
f.write(requests.get(video_z, headers=headers, proxies=proxies).content)
with open('1.txt', mode='a') as f:
f.write(title+'\n')
评论内容的获取,创建第二个动作链,模拟鼠标移动到相应位置,监听相应数据包,向下滚动1800个元素,循环获取相应评论包的内容。并每次向下刷新评论内容。
ac_1 = Actions(tab_2)
move_2 = ac_1.move_to('x://*[@id="douyin-right-container"]/div[2]/div/div/div[1]/div[3]/div/div[2]/div[1]/div[1]/span')
tab_2.listen.start('/aweme/v1/web/comment/list/')
move_2.scroll(delta_y=1800)
for page in range(pl_count):
move_2.scroll(delta_y=1200)
move_2.wait(1)
wait_2 = tab_2.listen.wait()
json_data_2 = wait_2.response.body
comments = json_data_2['comments']
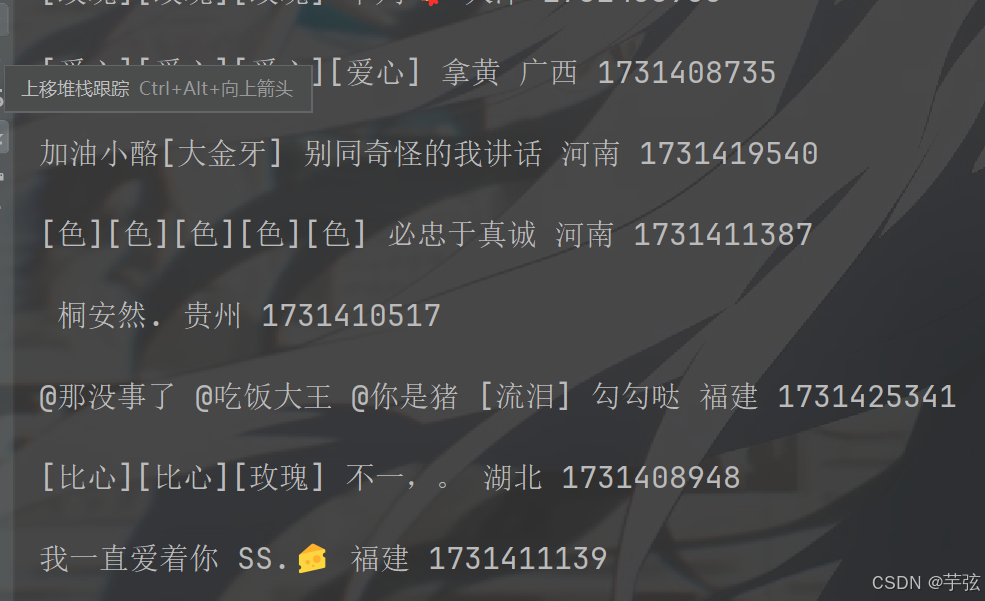
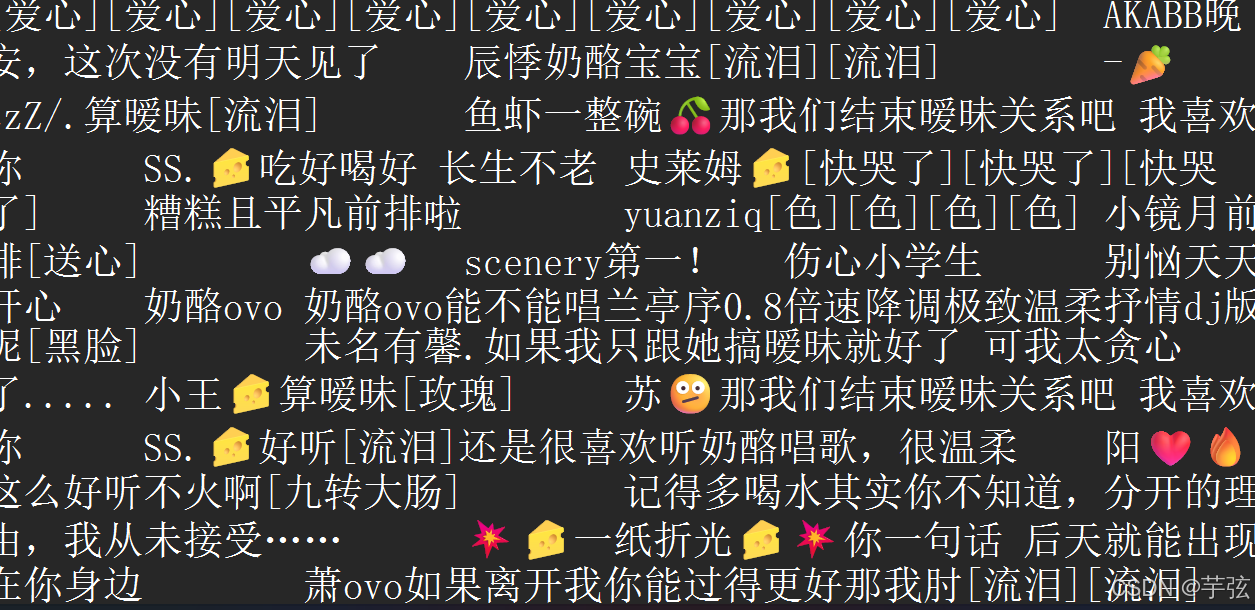
获取到评论包后,循环提取评论者的昵称,内容,时间,地点,并且创建相应文件来存放相应内容。
for comment in comments:
text = comment['text']
name = comment['user']['nickname']
print(comment['text'], end=' ') # 评论内容
print(comment['user']['nickname'], end=' ') # 评论昵称
if 'ip_label' in comment:
print(comment['ip_label'], end=' ') # 评论地区
print(comment['create_time'], end='\n') # 评论时间
with open('2.txt', mode='a', encoding='utf-8') as f:
f.write(text+'\n'+name)
tab_2.close()
完整代码: 下方没有使用代理IP,填写相应请求头即可使用。
注意评论包的数量对于评论少的视频要填少一点,1,2即可。如果代码卡顿到一个页面,刷新页面即可。
请求头的填写请参考前几篇文章。
from DrissionPage import ChromiumPage, ChromiumOptions
from DrissionPage.common import Actions
import re
import requests
# proxies = {}
headers = {}
video_list = []
url = input('请输入所要获取视频的主页链接:')
video_count = int(input('请输入获取视频数量:'))
pl_count = int(input('请输入获取评论数据包的数量:'))
tab_1 = ChromiumPage().latest_tab
tab_1.get(url)
ac = Actions(tab_1)
move = ac.move_to('x://*[@id="semiTabpost"]/div').click().scroll(500)
for i in range(1, video_count):
move.wait(1)
move.scroll(delta_y=500)
a = tab_1.ele(f'x://*[@id="douyin-right-container"]/div[2]/div/div/div/div[3]/div/div/div[2]/div[2]/div[2]/ul/li[{i}]/div/a')
# print(a)
b = re.findall("<ChromiumElement a href='(.*?)'", str(a))
# print(b)
video = 'https://www.douyin.com'+b[0]
video_list.append(video)
print(video_list)
for i in video_list:
if len(i) == 48:
# print(i)
tab_2 = ChromiumPage().new_tab()
tab_2.get(i)
tab_2.listen.start('/aweme/v1/web/aweme/detail/')
wait = tab_2.listen.wait()
json_data = wait.response.body
title = json_data['aweme_detail']['desc']
video_z = json_data['aweme_detail']['video']["bit_rate"][0]['play_addr']['url_list'][0]
dian_zan_count = json_data['aweme_detail']["statistics"]['digg_count']
ping_lun_count = json_data['aweme_detail']["statistics"]["comment_count"]
shou_can_count = json_data['aweme_detail']["statistics"]["collect_count"]
zhuan_fa_count = json_data['aweme_detail']["statistics"]["share_count"]
print(dian_zan_count)
print(ping_lun_count)
print(shou_can_count)
print(zhuan_fa_count)
print(title)
print(video_z)
with open(title[0:4]+'.mp4', mode='wb') as f:
f.write(requests.get(video_z, headers=headers).content)
with open('1.txt', mode='a') as f:
f.write(title+'\n')
ac_1 = Actions(tab_2)
move_2 = ac_1.move_to('x://*[@id="douyin-right-container"]/div[2]/div/div/div[1]/div[3]/div/div[2]/div[1]/div[1]/span')
tab_2.listen.start('/aweme/v1/web/comment/list/')
move_2.scroll(delta_y=1800)
for page in range(pl_count):
move_2.scroll(delta_y=1200)
move_2.wait(1)
wait_2 = tab_2.listen.wait()
json_data_2 = wait_2.response.body
comments = json_data_2['comments']
for comment in comments:
text = comment['text']
name = comment['user']['nickname']
print(comment['text'], end=' ') # 评论内容
print(comment['user']['nickname'], end=' ') # 评论昵称
if 'ip_label' in comment:
print(comment['ip_label'], end=' ') # 评论地区
print(comment['create_time'], end='\n') # 评论时间
with open('2.txt', mode='a', encoding='utf-8') as f:
f.write(text+'\n'+name)
tab_2.close()
执行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









