










文章目录

如何搜寻文献
- 文献搜寻是学术研究中至关重要的步骤。通过高效的文献搜寻方法,研究者可以获取领域内的最新研究成果,为自己的研究提供理论支持,并发现研究中的创新点。以下是几种常见的文献搜寻方法及其对应的工具和平台。

1. 使用关键词搜索
Google Scholar、百度学术、知网等平台是常用的学术文献检索工具。通过输入关键词,可以快速获取相关领域的学术论文。这些平台支持多种筛选功能,如按时间、期刊、引用次数等过滤文献,从而精准找到符合研究需求的文献。
- 在关键词选择时,建议使用精确的学术术语,并结合布尔逻辑(如AND、OR、NOT)优化检索结果。
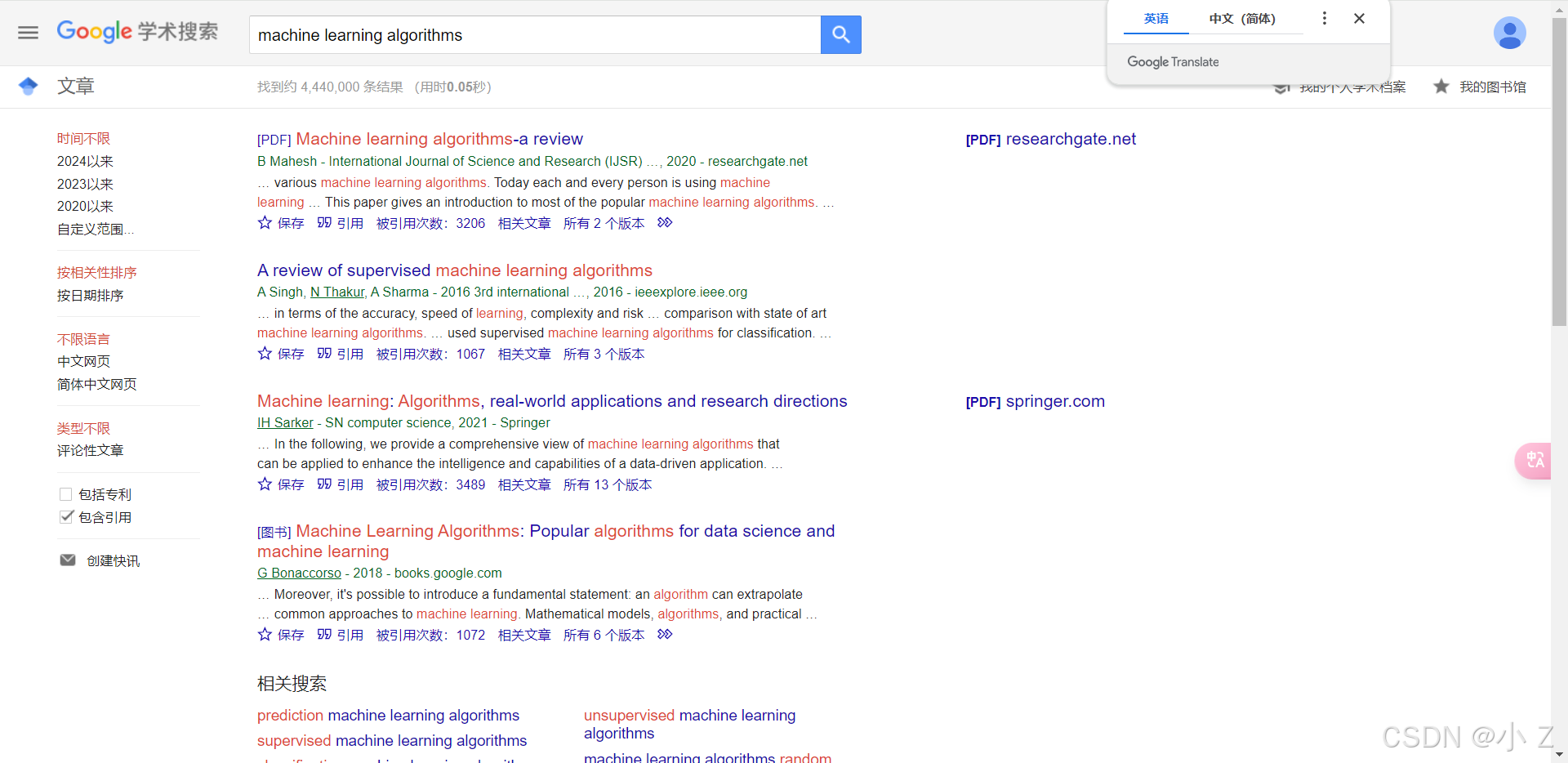
- 例如:在Google Scholar中搜索“machine learning algorithms”可以展示各种相关的研究文献,并根据不同的年份和来源进行筛选。
2. 查阅专家主页
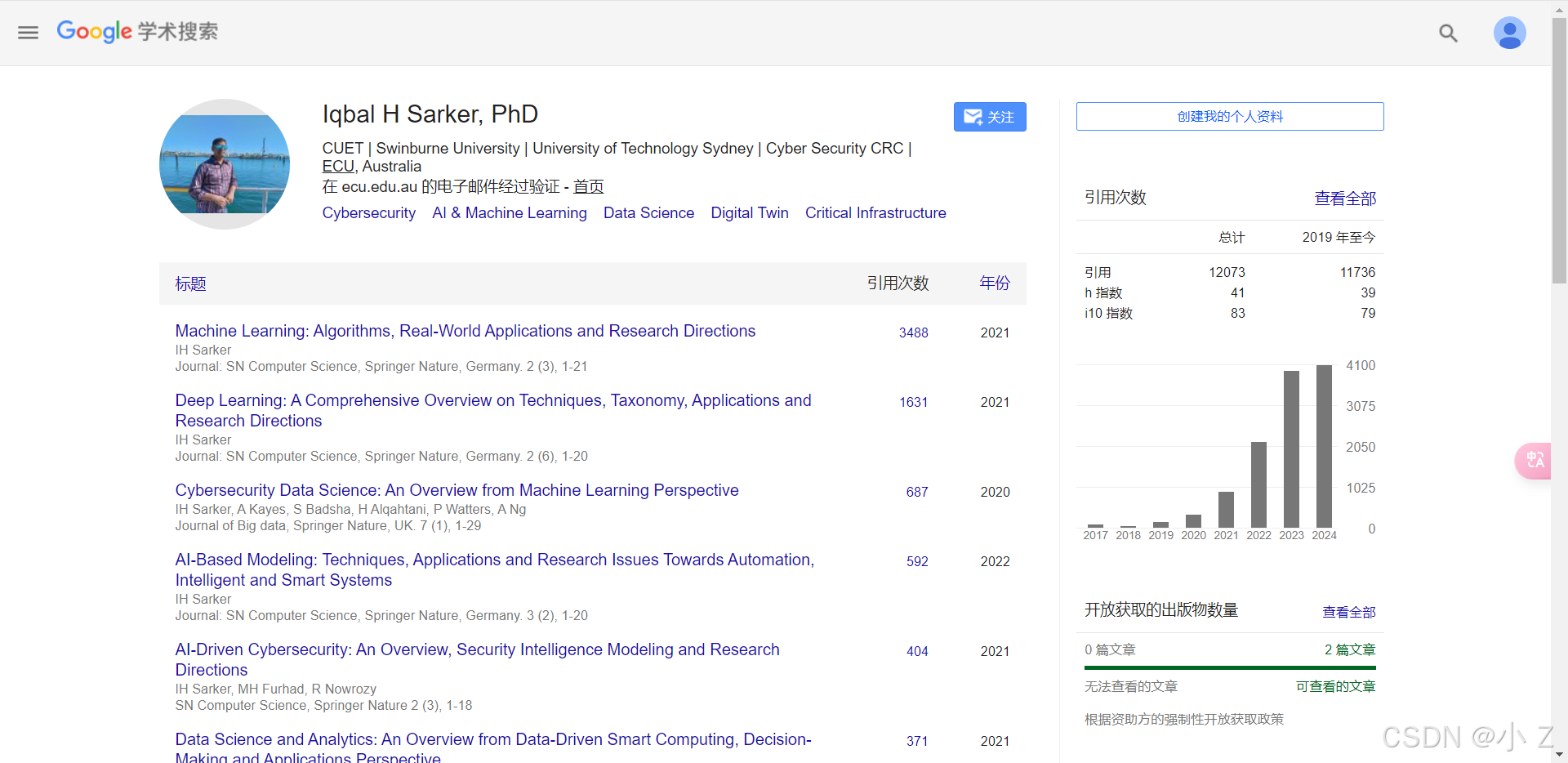
- 在相关领域的大佬主页中,通常能找到他们已发表的论文列表。这是掌握该学者研究方向、方法及其最新成果的有效方式。例如,可以通过访问知名学者的Google Scholar个人主页或高校研究团队主页,查阅其已发表的高引用文献,直接获取前沿研究动态。
3. 期刊主页
高质量的学术期刊主页是获取权威文献的重要渠道。在期刊主页上,可以查看高引用率的文献,如《Cell》、IEEE等顶尖期刊。这些高引用文献往往在领域内具有重要的学术影响力,阅读这些文献可以迅速掌握领域内的核心理论和研究进展。
- 期刊主页通常会列出“最近引用次数最多的文献”或“最热门的文献”,为研究者提供快速了解领域热点的途径。
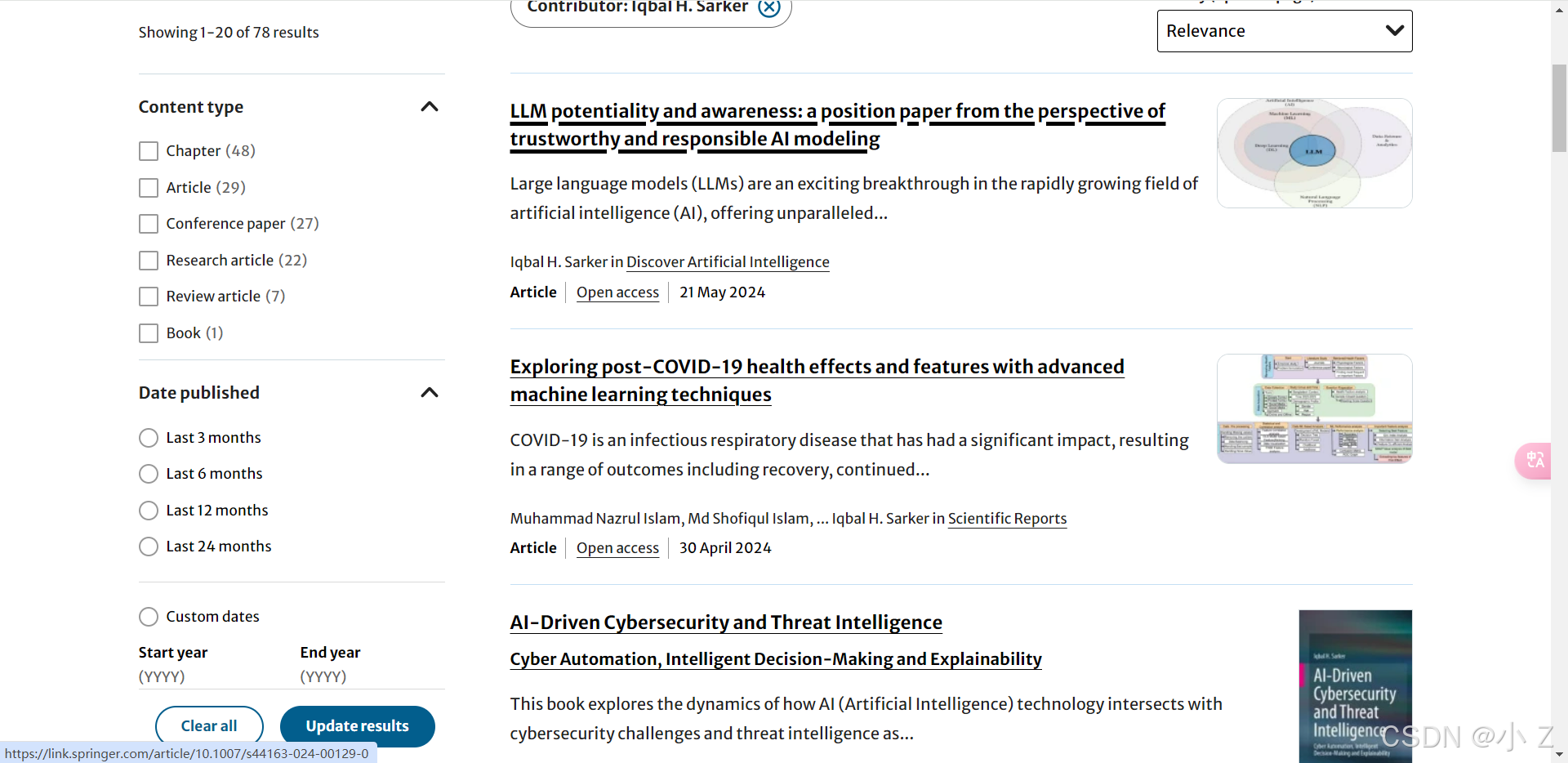
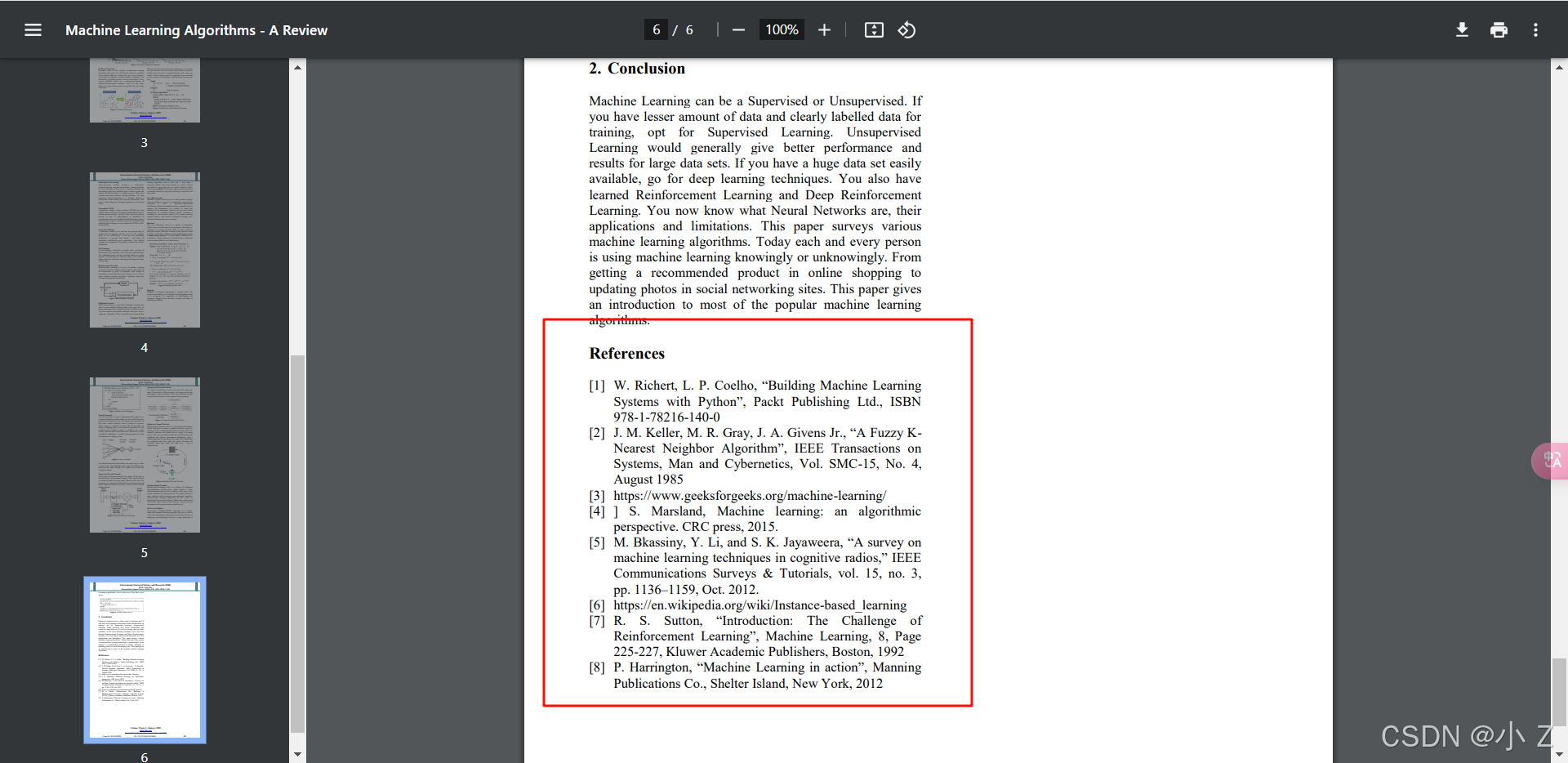
4. 通过参考文献挖掘
在阅读过程中,研究者可以通过文献中的参考文献列表,找到更多相关的经典或基础文献。这是一种扩展文献范围的有效方式,能够帮助研究者进一步了解领域内的历史研究和背景知识。
- 例如,当阅读一篇机器学习领域的论文时,通过参考文献可以深入挖掘该领域的先前研究,找到其他方法或模型的相关文献。
5. 文献命名与分类
为了有效管理检索到的文献,建议在保存文献时遵循一定的命名规则。简洁明了的命名不仅能提高分类效率,还能方便后期检索。推荐的命名格式为:方向 + 问题 + 方法 + 缺陷。
- 例子:若研究方向为“深度学习在图像识别中的应用”,可命名为“深度学习+图像识别+卷积神经网络+效率提升”。
如何管理文献
- 文献管理在学术研究中至关重要。它不仅帮助研究者高效地整理已阅读的文献,还能在撰写论文时快速引用,确保研究有条不紊地进行。以下是几款常用的文献管理工具,以及它们的功能介绍。

1. EndNote
EndNote 是一款强大的文献管理工具,广泛应用于学术界。它不仅可以用来存储、整理文献,还可以自动生成参考文献格式,帮助研究者在撰写学术论文时节省大量时间。
- 功能特点:
- 文献分类和标签管理。
- 支持PDF文献的批量导入和自动归类。
- 自动生成参考文献,支持多种引用格式。
- 与Microsoft Word集成,实时插入参考文献。
EndNote的界面友好,支持多种格式的文献管理,适合需要处理大量文献的研究者。
2. 知云文献翻译
知云文献翻译 是一款支持逐段翻译文献的工具,特别适合需要翻译外文文献的研究者使用。它可以帮助研究者快速理解非母语的学术论文,大幅提高阅读外文文献的效率。
- 功能特点:
- 支持逐句翻译,确保准确理解专业术语。
- 支持多种格式的文献,包括PDF、Word等。
- 翻译结果清晰直观,便于对照原文。
知云文献翻译功能强大,特别适合需要大量阅读外文资料的研究人员。
3. 福昕PDF
福昕PDF 是一款专业的PDF文档管理工具,尤其适用于文献的标注和批注。它帮助研究者在阅读过程中做出高效的笔记和高亮标记,便于后期整理和引用。
- 功能特点:
- 支持在文献中做批注、标注和高亮显示。
- 支持将PDF文献导出为多种格式,如Word、Excel等,方便后期整理。
- 提供强大的搜索功能,可以快速找到文献中的关键内容。
福昕PDF对文献的标注功能使其成为学术研究中的得力助手,尤其适合需要深入分析文献的学者。
如何阅读文献
- 在学术研究过程中,有效地阅读文献是获取知识、了解研究动态的重要方法。阅读文献不仅仅是浏览内容,而是要深刻理解其逻辑、方法和结论。以下是阅读文献的几个关键步骤。

1. 论文的结构
一篇标准的学术论文通常包括以下几个部分,每一部分在论文中的作用和意义都不同:
- 标题:简明概括地传达论文的核心内容,通常涵盖研究的问题、方法以及亮点。
- 作者单位:了解作者的背景及单位,有助于判断论文的权威性与可信度。
- 摘要:提供论文研究的概述,帮助快速了解研究的核心问题、方法及结论。
- 引言:详细介绍研究的背景和动机,讨论当前研究的现状及相关领域的不足。
- 主体:
- 方法:详细介绍研究采用的方法,便于评估其科学性与创新性。
- 实验结果:展示研究所得到的数据和结果,考察其准确性和可重复性。
- 结论:总结实验结果,解释研究的意义,并提出未来研究的建议。
- 致谢:向提供帮助的机构或个人表达感谢。
- 参考文献:展示论文引用的所有相关研究,帮助读者进一步扩展阅读。

2. 标题
论文标题应具备以下特点:
- 准确传达问题:标题需要清晰表达研究的核心问题。
- 体现方法:标题中可以反映出研究中使用的方法或技术。
- 突出亮点:通过标题展示论文的创新之处或独特视角。
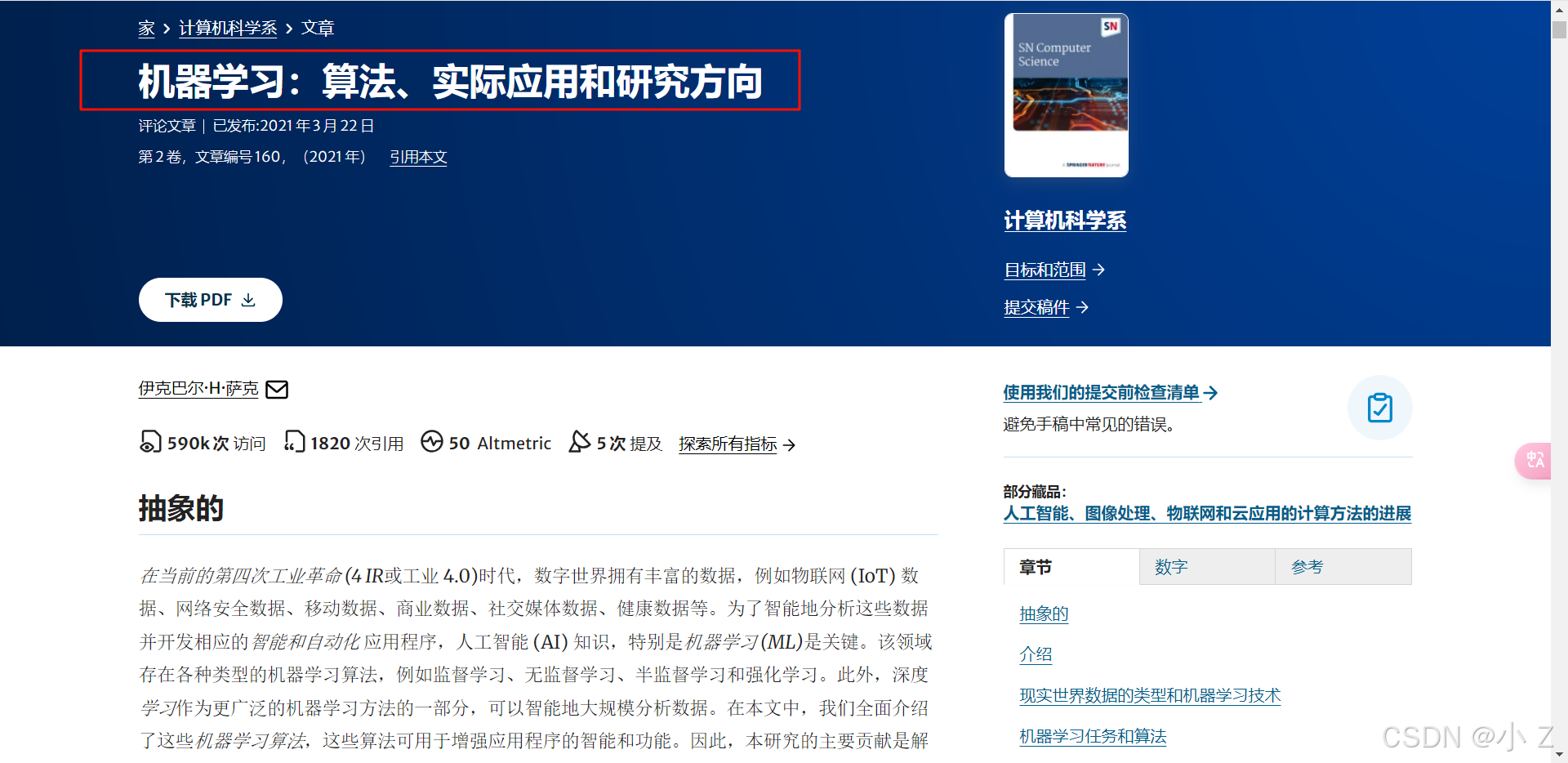
3. 作者单位
在阅读文献时,了解作者的背景可以帮助判断其研究的权威性:
- 作者信息:了解作者的姓名、单位、研究领域,评估其在学术界的地位。
- 确保准确性:在引用时,作者和单位信息需要准确无误,以保持学术的严谨性。
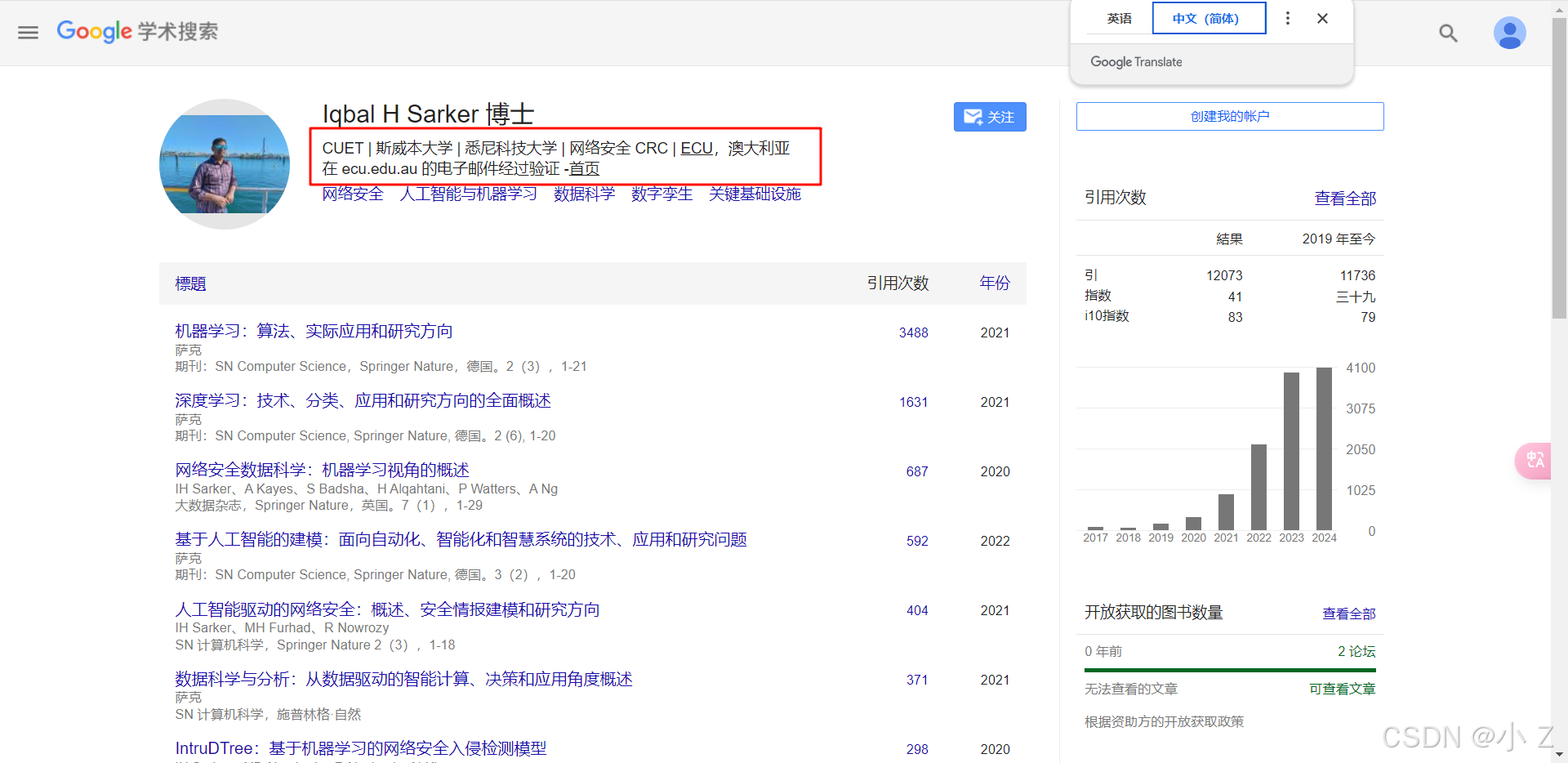
4. 摘要
阅读摘要时,需关注以下几方面:
- 研究意义:了解该课题的研究价值和学术意义。
- 当前方法的不足:明确现有研究面临的问题,了解其局限性。
- 研究方法:作者采用了哪些新的方法来克服现有的困难。
- 方法概述:从摘要中获取对研究方法和细节的简要介绍。

5. 引言
引言部分往往介绍研究的背景和动机,是理解研究问题的关键:
- 研究背景:引言中会详细介绍课题研究的背景及意义。
- 现状概述:讨论当前领域的研究现状以及其他学者的方法。
- 研究缺陷:指出现有研究的不足或需要改进的地方。
- 方法概述:提出本文所用的新方法或改进方案,展示其可行性和重要性。
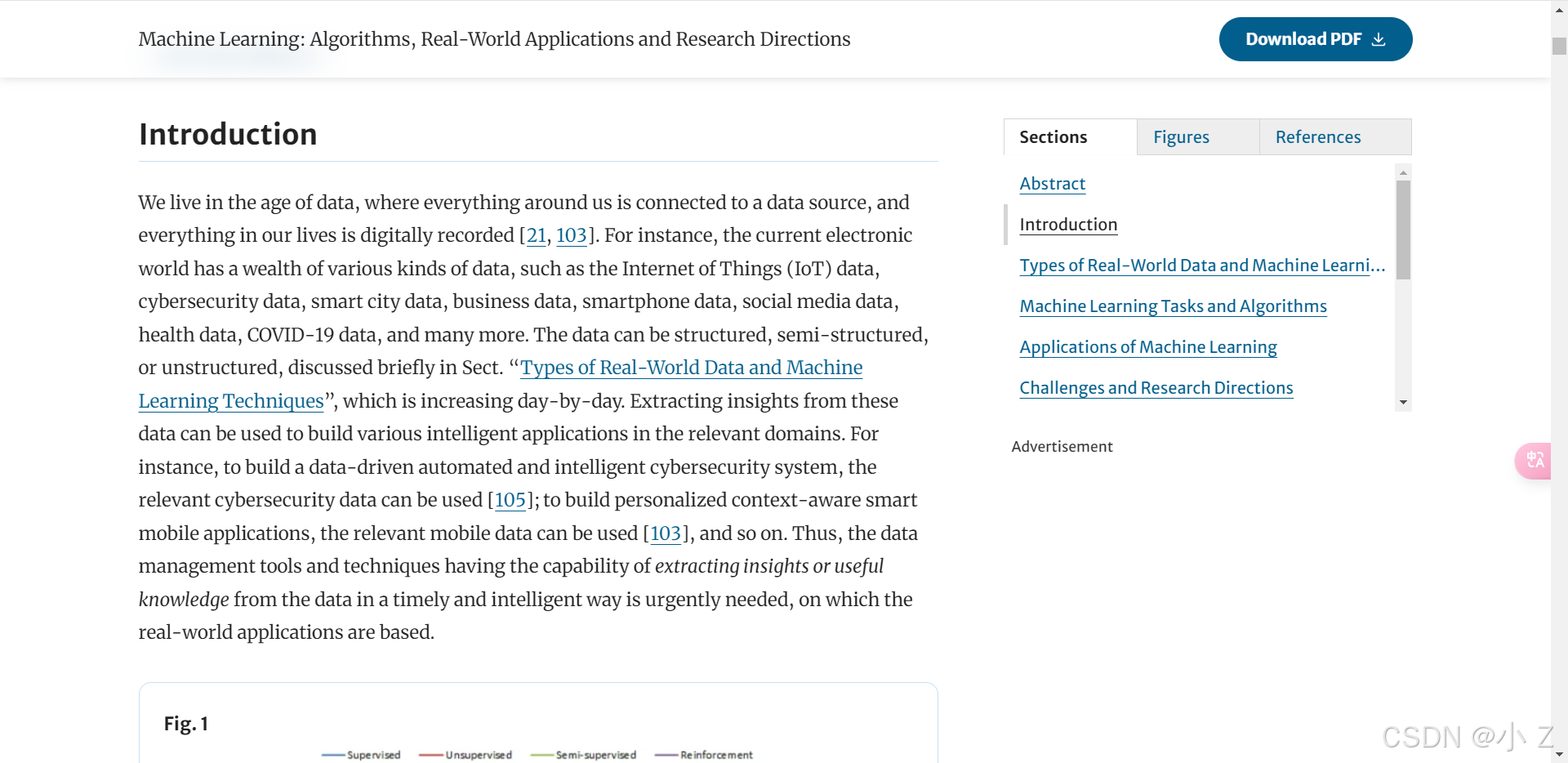
6. 方法
阅读方法部分时,注意以下要点:
- 方法细节:明确作者采用了哪些具体的技术或实验手段。
- 方法评估:评估这些方法的合理性、科学性和创新性。
- 缺点与不足:同时发现该方法在应用过程中可能面临的挑战或不足。
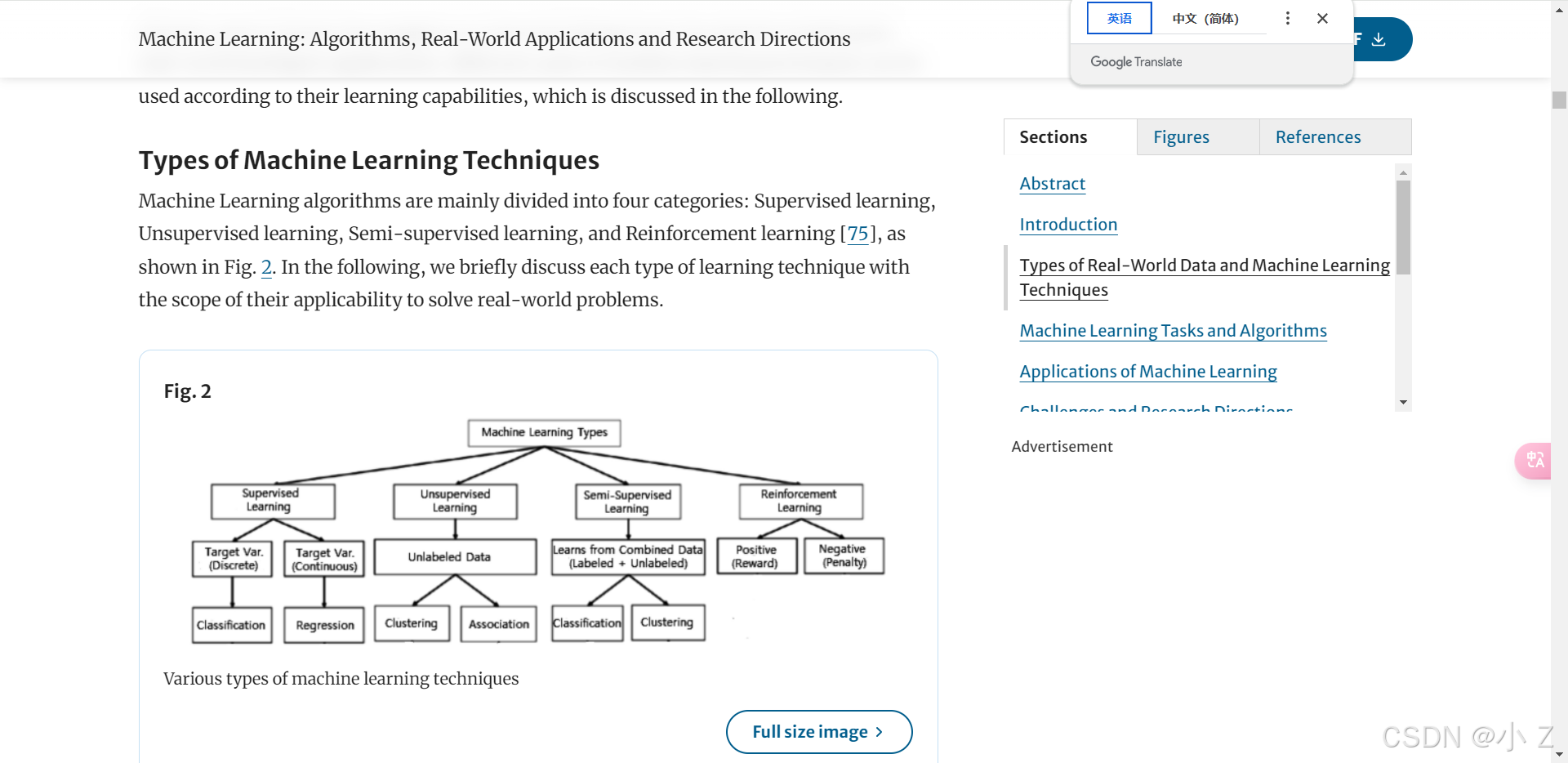
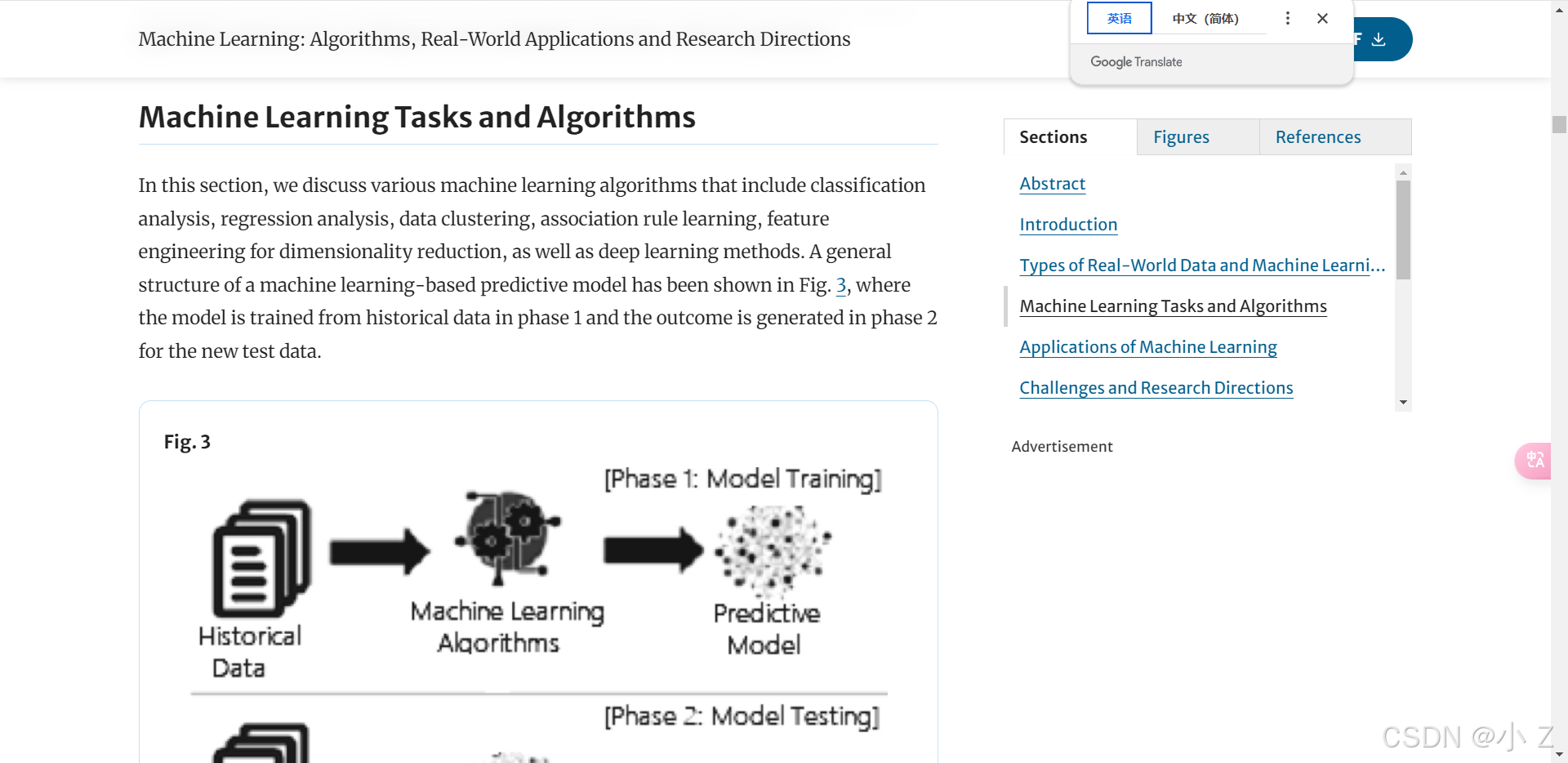
7. 实验结果
实验结果部分展示研究的核心数据和发现:
- 性能指标:论文中通常会提出多个关键的性能指标,衡量方法或实验的有效性。
- 性能参数:关注影响实验结果的关键参数,理解其调节对实验的影响。
- 结果展示方式:学习作者是如何有效展示实验结果,便于在自己的研究中借鉴。
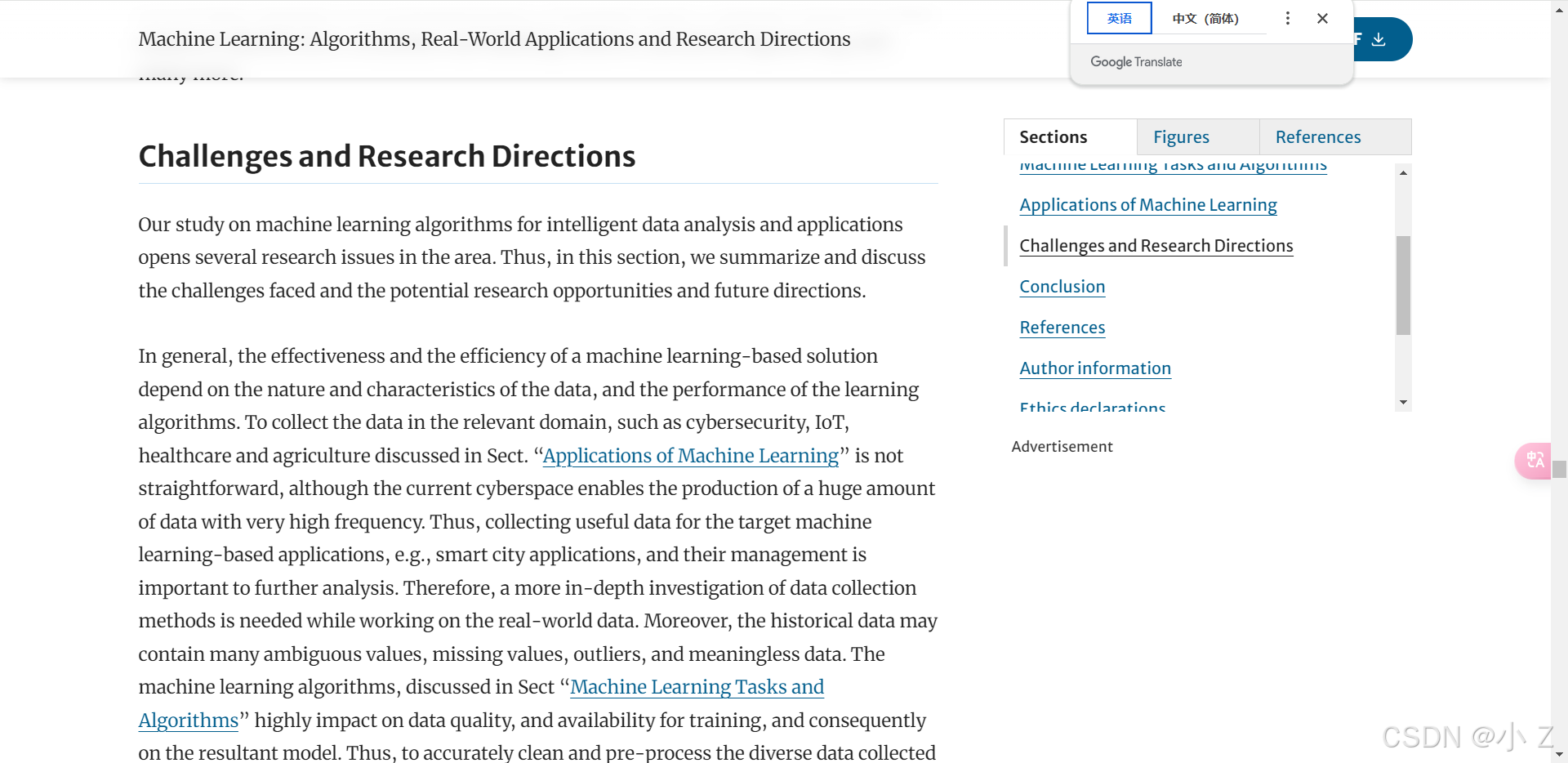
8. 结论
结论部分是对实验结果的总结和升华:
- 直接结论:通过实验数据得出的直接结论,通常是研究的核心发现。
- 间接结论:根据实验结果推断出的间接结论,可以为未来研究提供新的思路。
- 写作技巧:结论需要简洁而富有概括性,指明研究的意义和未来方向。
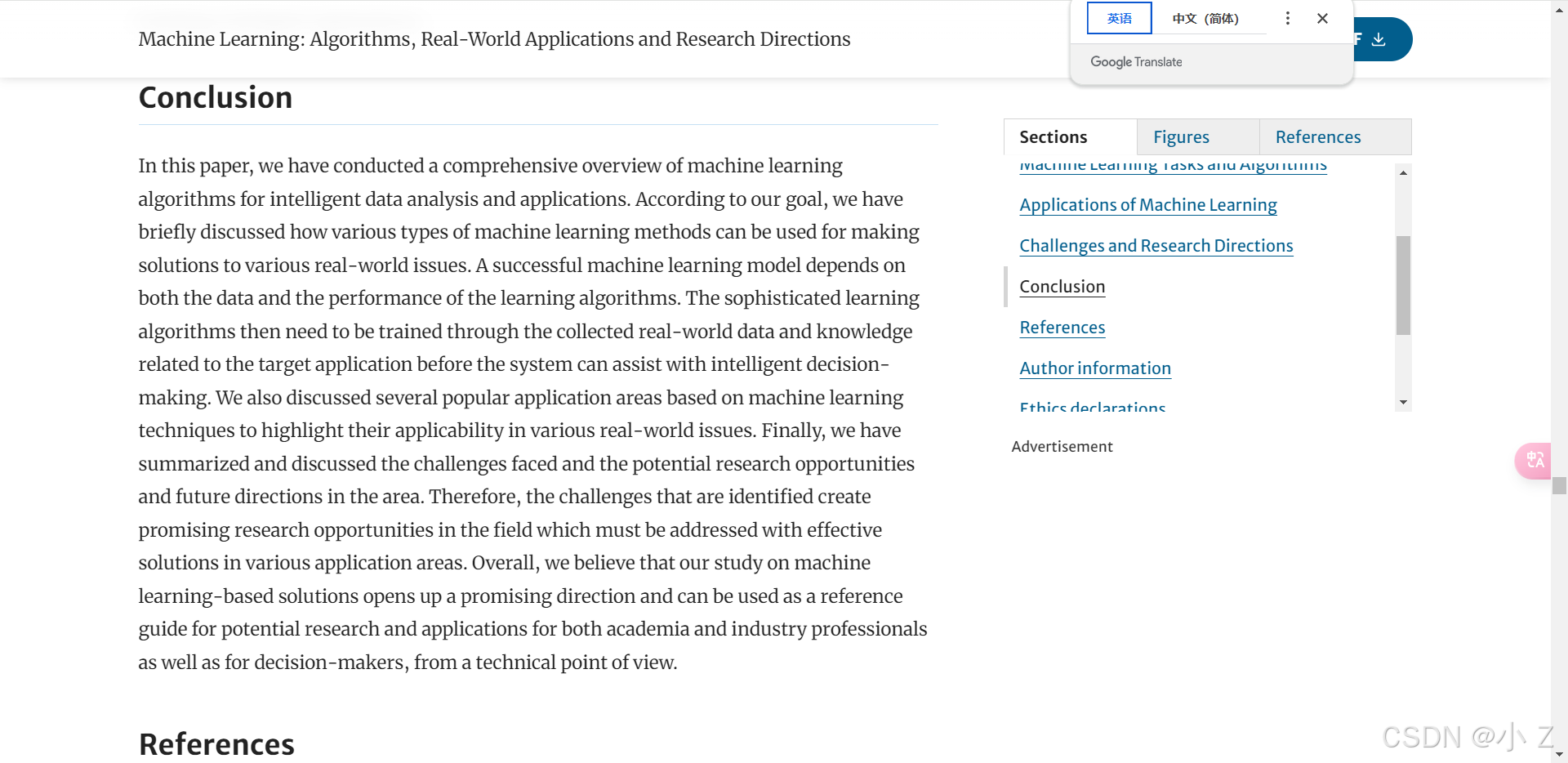
如何书写文献综述
- 文献综述是科研写作中至关重要的一部分,它不仅展示了对特定领域文献的全面理解,也为后续研究奠定理论基础。撰写高质量的文献综述需要遵循一定的方法和策略。以下是书写文献综述的几个要点:

1. 阅读大量相关领域文献
在撰写文献综述前,研究者需要广泛阅读并掌握该领域的现有研究成果。通过阅读文献,可以了解该领域的发展现状、技术更迭以及研究热点,为综述提供背景支持。
- 建议:选择高质量期刊文章,尤其是引用率高、影响力大的文献,帮助构建权威的知识框架。
2. 对文献进行归纳总结
文献综述不应只是简单罗列每篇文献的研究工作,还需要对这些工作进行归纳和总结。这包括提炼出不同文献的共同点和差异,并在总结时对这些研究进行批判性分析。
- 建议:通过对比不同研究的方法、结果和结论,揭示领域中的共性与个性,展示出整个领域的演进路径。

3. 讨论文献的优点和不足
在文献综述中,不仅要讨论现有文献的贡献,还要客观指出其存在的缺陷或不足。这有助于展示现有研究的局限性,并为自己的研究提供创新点。
- 建议:对于文献的不足,可以通过批判性阅读分析出问题所在,并提出可能的改进方向。

4. 分类整理文献
将文献根据一定的标准(如方法、应用领域或研究问题)进行分类,有助于更加清晰地展示某一领域的发展脉络。分类后可以根据类别逐一介绍和总结,形成逻辑清晰的文献综述结构。
- 建议:可以根据研究的主题或方法学的不同,将文献分为几大类,便于梳理和比较不同研究的贡献。

5. 保持客观,避免主观判断
在撰写文献综述时,语言应保持中立,避免带有强烈的主观色彩。批判性分析应基于客观事实和数据,而不是个人偏见。
- 建议:使用科学的、数据驱动的语言,避免过于夸大的语气,确保综述的严谨性与学术性。

import requests, re, json; from bs4 import BeautifulSoup; def fetch_google_scholar(query, num_results=10): headers = {"User-Agent": "Mozilla/5.0"}; url = f"https://scholar.google.com/scholar?q={query}"; response = requests.get(url, headers=headers); soup = BeautifulSoup(response.text, 'html.parser'); results = []; for result in soup.find_all('div', class_="gs_ri")[:num_results]: title = result.find('h3').text; link = result.find('h3').find('a')['href'] if result.find('h3').find('a') else None; snippet = result.find('div', class_="gs_rs").text; results.append({"title": title, "link": link, "snippet": snippet}); return results; def fetch_journal_papers(journal_url, num_papers=10): headers = {"User-Agent": "Mozilla/5.0"}; response = requests.get(journal_url, headers=headers); soup = BeautifulSoup(response.text, 'html.parser'); papers = []; for paper in soup.find_all('div', class_="paper-title")[:num_papers]: title = paper.text; link = paper.find('a')['href']; papers.append({"title": title, "link": link}); return papers; def categorize_papers(papers, categories): categorized = {category: [] for category in categories}; for paper in papers: for category in categories: if re.search(category, paper['title'], re.IGNORECASE): categorized[category].append(paper); return categorized; def summarize_paper_titles(papers): summary = "Summary of Papers:\n"; for paper in papers: summary += f"- {paper['title']}\n"; return summary; papers_google = fetch_google_scholar("machine learning", 5); papers_journal = fetch_journal_papers("https://journal.com/latest", 5); combined_papers = papers_google + papers_journal; categories = ["deep learning", "neural networks", "reinforcement learning"]; categorized_papers = categorize_papers(combined_papers, categories); print(json.dumps(categorized_papers, indent=2)); print(summarize_paper_titles(combined_papers))




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











