






算法设计
一、判断回文序列
1、算法思路:
输入想要判断的字符串,用数组来存放该字符串,给数组一个最左的下标low,和最右的下标right.比较两端的字符是否相等,如果相等那么low++,right--.直到遍历完字符串,如果字符不相等返回0说明不是回文。当遍历完之后low>right,则说明该字符串是回文。递归调用自己,一直判断两端是否相等。
2、代码实现:
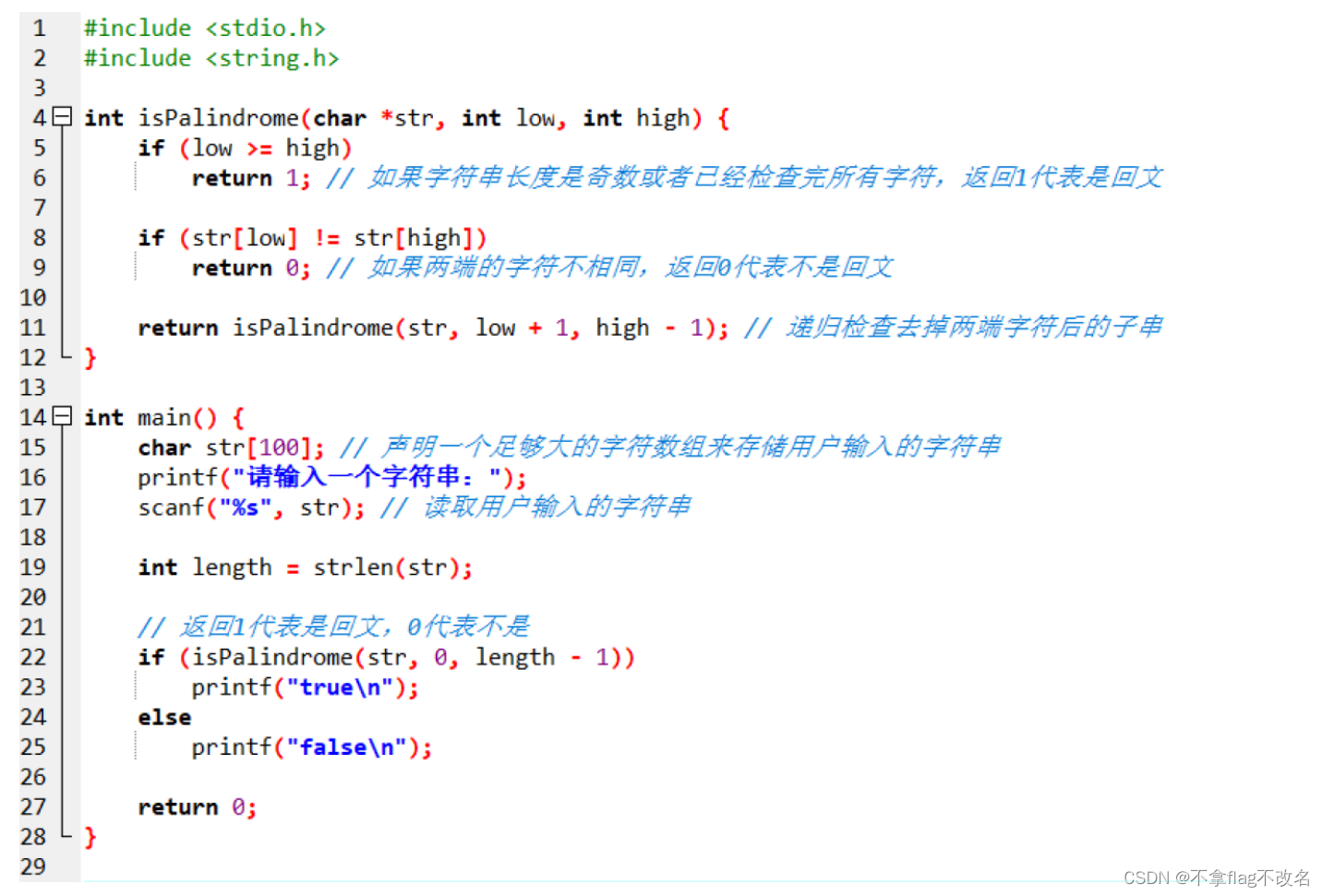
3、运行结果

二、递归算法实现单链表操作
(1)求链表中的最大整数
- 思路:
首先我们要将用户输入的数据插入链表中,之后再递归调用函数来求最大值。用开辟一块空间p来存放用户的输入在p->data。p是用来存储指向链表节点的指针。在函数中,比较当前节点和max,如果当前节点的数据大于 max,则更新 max。递归地调用 GetMax(L->next, Max),继续查找下一个节点。直到遍历完整个链表,输出最大值。
(2)代码实现:

(3)运行结果:

(2)求链表的结点个数
- 思路:当链表不为空,就继续调用递归函数,直到指针指向空,若是一开始head等于空,返回0,否则就又递归调用函数,head->next,并计算加1,直到链表为空,返回计数结果。
- 代码实现:

3.运行结果:

(3)求所有整数的平均值
1、思路:判断头指针的下一个结点是否有数据,没有的话平均值就是当前结点的值,如果有多个结点,就递归调用直到最后为空,会返回值,依次再回溯回去,最终可求得平均值。
2、代码实现:

3、运行结果:

- 总代码
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
struct LNode {
int data;
struct LNode* next;
};
// 递归函数,求链表中的最大整数
int GetMax(struct LNode* f, int Max) {
if (f == NULL)
return Max;
if (f->data > Max) {
Max = f->data;
}
return GetMax(f->next, Max);
}
// 递归函数,求链表中的结点个数
int CountNodes(struct LNode* f) {
// 递归终止条件:链表为空
if (f == NULL) {
return 0;
}
// 递归调用,累加结点个数
return CountNodes(f->next) + 1;
}
// 递归函数,求链表中所有整数的平均值
double GetAverage(struct LNode* f, int n) {
if (!f->next)
return f->data;
else {
double ave = GetAverage(f->next, n - 1);
return (ave * (n - 1) + f->data) / n;
}
}
int main() {
struct LNode* f = NULL;
struct LNode* p;
int n;
int Max = -31555;
printf("请输入链表的长度:\n");
scanf("%d", &n);
printf("请输入 %d 个数:\n", n);
for (int i = 0; i < n; i++) {
p = (struct LNode*)malloc(sizeof(struct LNode));
scanf("%d", &p->data);
p->next = f;
f = p;
}
printf("链表中最大数为:%d\n", GetMax(f, Max));
int count = CountNodes(f);
printf("链表中的结点个数:%d\n", count);
double average = GetAverage(f, n);
printf("链表中所有整数的平均值为:%.2f\n", average);
// 释放内存
while (f != NULL) {
p = f;
f = f->next;
free(p);
}
return 0;
}















 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









