







大家好,今天让我们看一下使用Python进行数据可视化的主要库以及可以使用它们完成的所有类型的图表。我们还将看到建议在每种情况下使用哪个库以及每个库的独特功能。
我们将从最基本的可视化开始,直接查看数据,然后继续绘制图表,最后制作交互式图表。

数据集
我们将使用两个数据集来适应本文中显示的可视化效果,数据集可通过下方链接进行下载。
数据集:github.com/albertsl/dat
这些数据集都是与人工智能相关的三个术语(数据科学,机器学习和深度学习)在互联网上搜索流行度的数据,从搜索引擎中提取而来。
该数据集包含了两个文件temporal.csv和mapa.csv。在这个教程中,我们将更多使用的第一个包括随时间推移(从2004年到2020年)的三个术语的受欢迎程度数据。另外,我添加了一个分类变量(1和0)来演示带有分类变量的图表的功能。
mapa.csv文件包含按国家/地区分隔的受欢迎程度数据。在最后的可视化地图时,我们会用到它。
Pandas
在介绍更复杂的方法之前,让我们从可视化数据的最基本方法开始。我们将只使用熊猫来查看数据并了解其分布方式。
我们要做的第一件事是可视化一些示例,查看这些示例包含了哪些列、哪些信息以及如何对值进行编码等等。
import pandas as pd
df = pd.read_csv('temporal.csv')
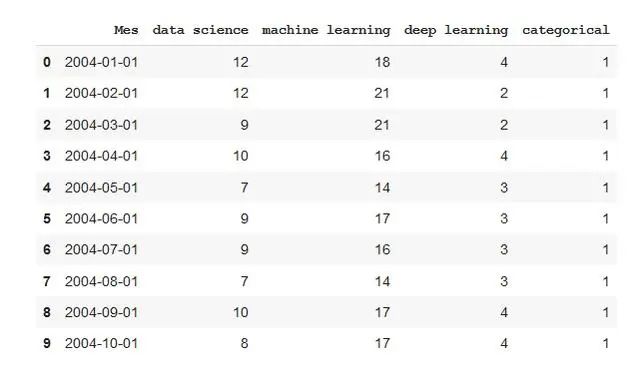
df.head(10) #View first 10 data rows
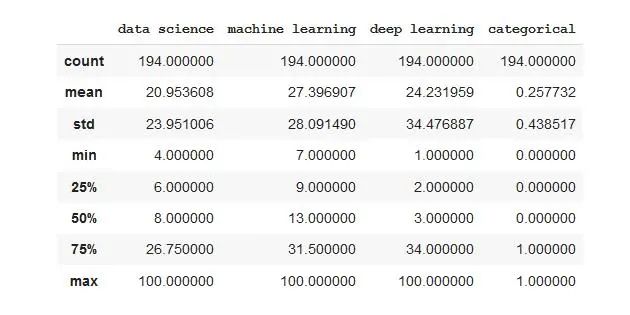
使用命令描述,我们将看到数据如何分布,最大值,最小值,均值……
df.describe()
使用info命令,我们将看到每列包含的数据类型。我们可以发现一列的情况,当使用head命令查看时,该列似乎是数字的,但是如果我们查看后续数据,则字符串格式的值将被编码为字符串。
df.info()

通常情况下,pandas都会限制其显示的行数和列数。这可能让很多程序员感到困扰,因为大家都希望能够可视化所有数据。
使用这些命令,我们可以增加限制,并且可以可视化整个数据。对于大型数据集,请谨慎使用此选项,否则可能无法显示它们。
pd.set_option('display.max_rows',500)
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
使用Pandas样式,我们可以在查看表格时获得更多信息。首先,我们定义一个格式字典,以便以清晰的方式显示数字(以一定格式显示一定数量的小数、日期和小时,并使用百分比、货币等)。不要惊慌,这是仅显示而不会更改数据,以后再处理也不会有任何问题。
为了给出每种类型的示例,我添加了货币和百分比符号,即使它们对于此数据没有任何意义。
format_dict = {'data science':'${0:,.2f}', 'Mes':'{:%m-%Y}', 'machine learning':'{:.2%}'}
#We make sure that the Month column has datetime format
df['Mes'] = pd.to_datetime(df['Mes'])
#We apply the style to the visualization
df.head().style.format(format_dict)
我们可以用颜色突出显示最大值和最小值。
format_dict = {'Mes':'{:%m-%Y}'} #Simplified format dictionary with values that do make sense for our data
df.head().style.format(format_dict).highlight_max(color='darkgreen').highlight_min(color='#ff0000')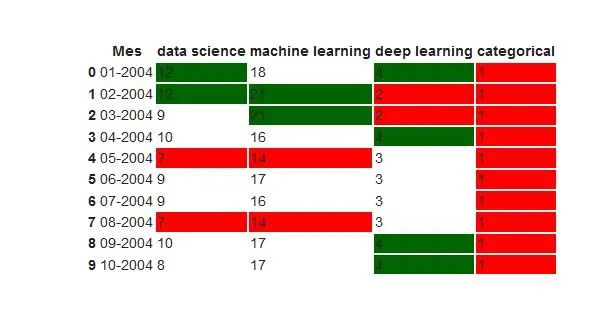
我们使用颜色渐变来显示数据值。
df.head(10).style.format(format_dict).background_gradient(subset=['data science', 'machine learning'], cmap='BuGn')
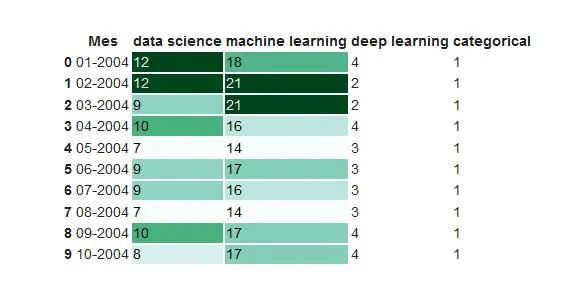
我们也可以用条形显示数据值。
df.head().style.format(format_dict).bar(color='red', subset=['data science', 'deep learning'])

此外,我们还可以结合以上功能并生成更复杂的可视化效果。
df.head(10).style.format(format_dict).background_gradient(subset = ['data science','machine learning'],cmap ='BuGn')。highlight_max(color ='yellow')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









