








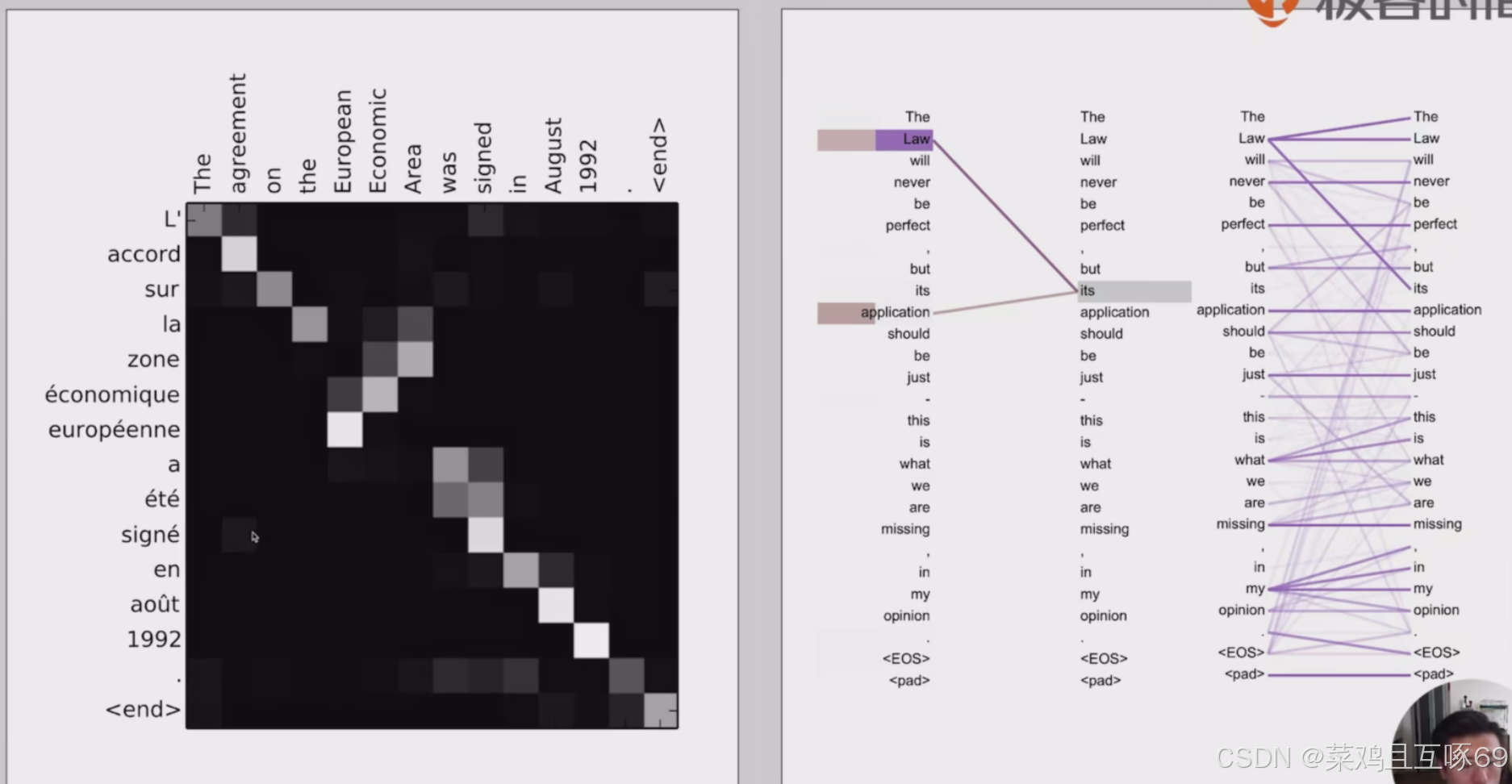
注意力机制可视化出来的结果
通过混淆矩阵来可视化注意力,越高亮表示相关度越高

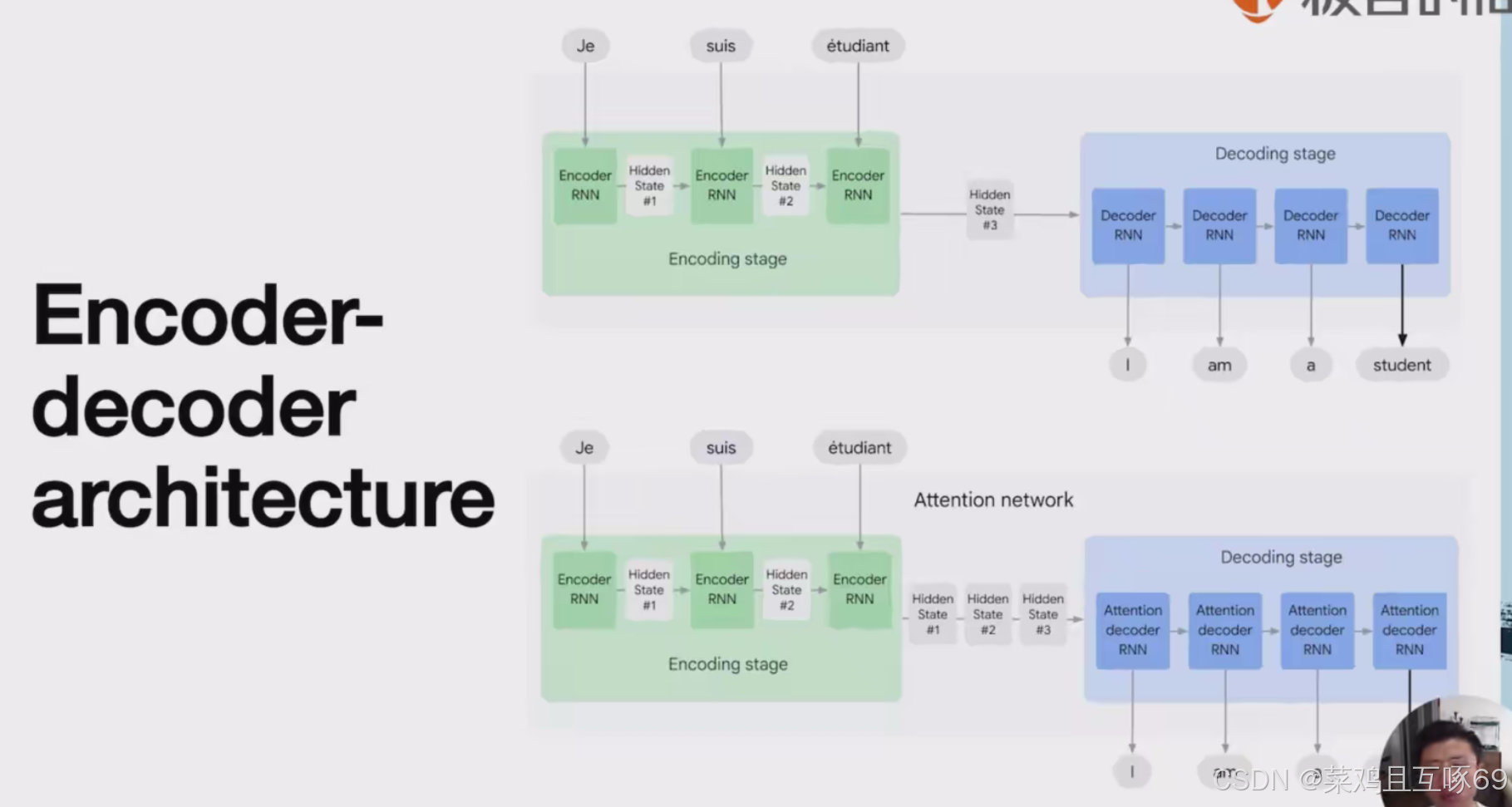
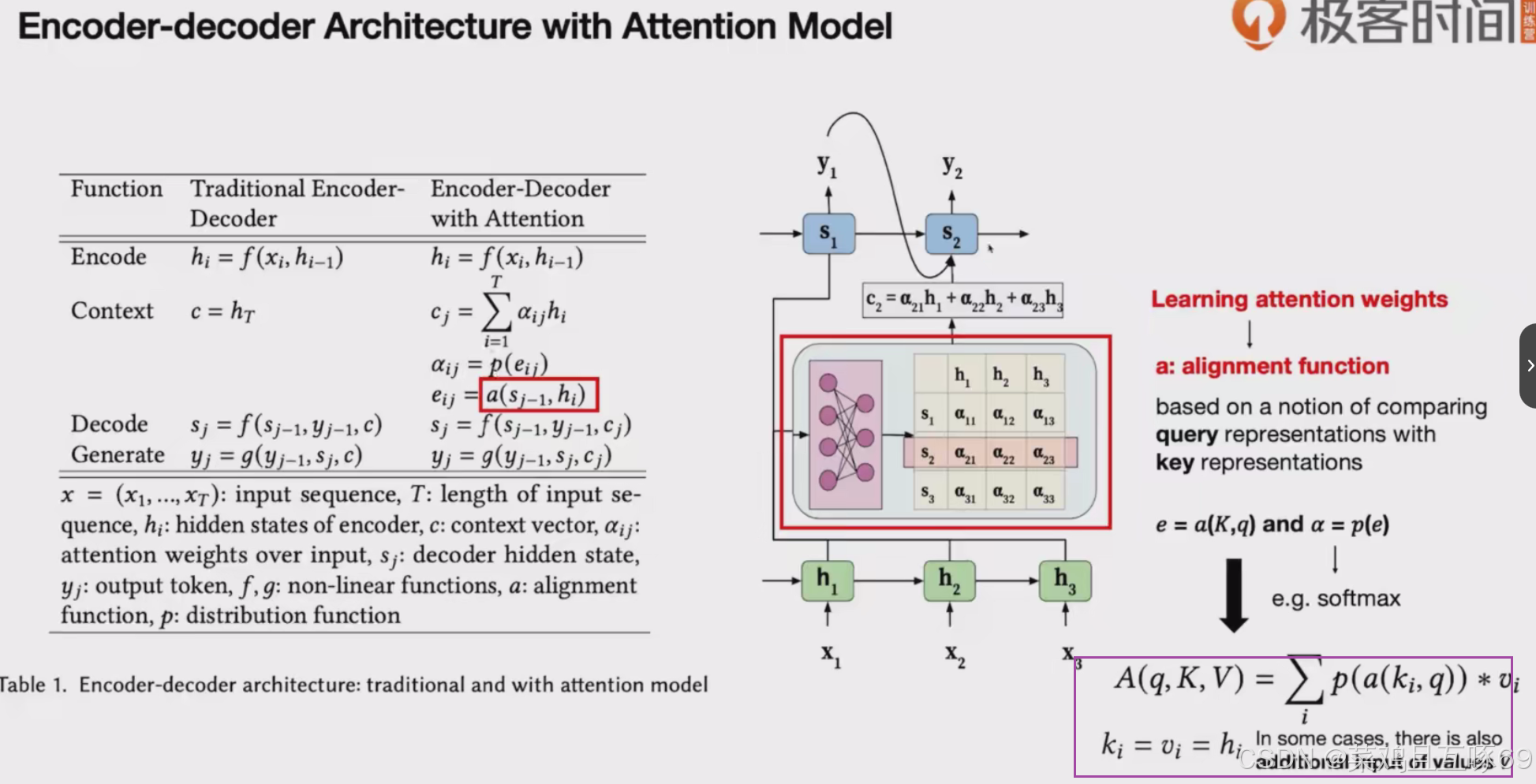
q时输入的一些query key是关键位置的key v是一些额外的输入
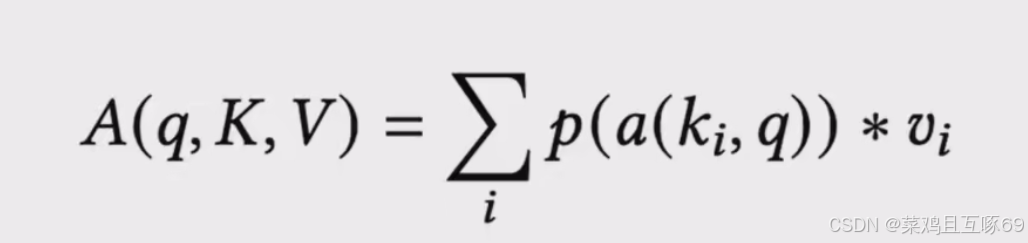
self-attention 因为我们想要其理解语义

其抛弃了rnn 所以就不用解决RNN的一些缺点
gpu可以并行处理,因为RNN是前后文依赖的所以不能并行运算,但是transformer前后没有依赖关系,所以可以并行运算(不用先学完一年级再去学二年级)
可以捕获句子级别的语义关系,理解了语义就能过更多的任务了

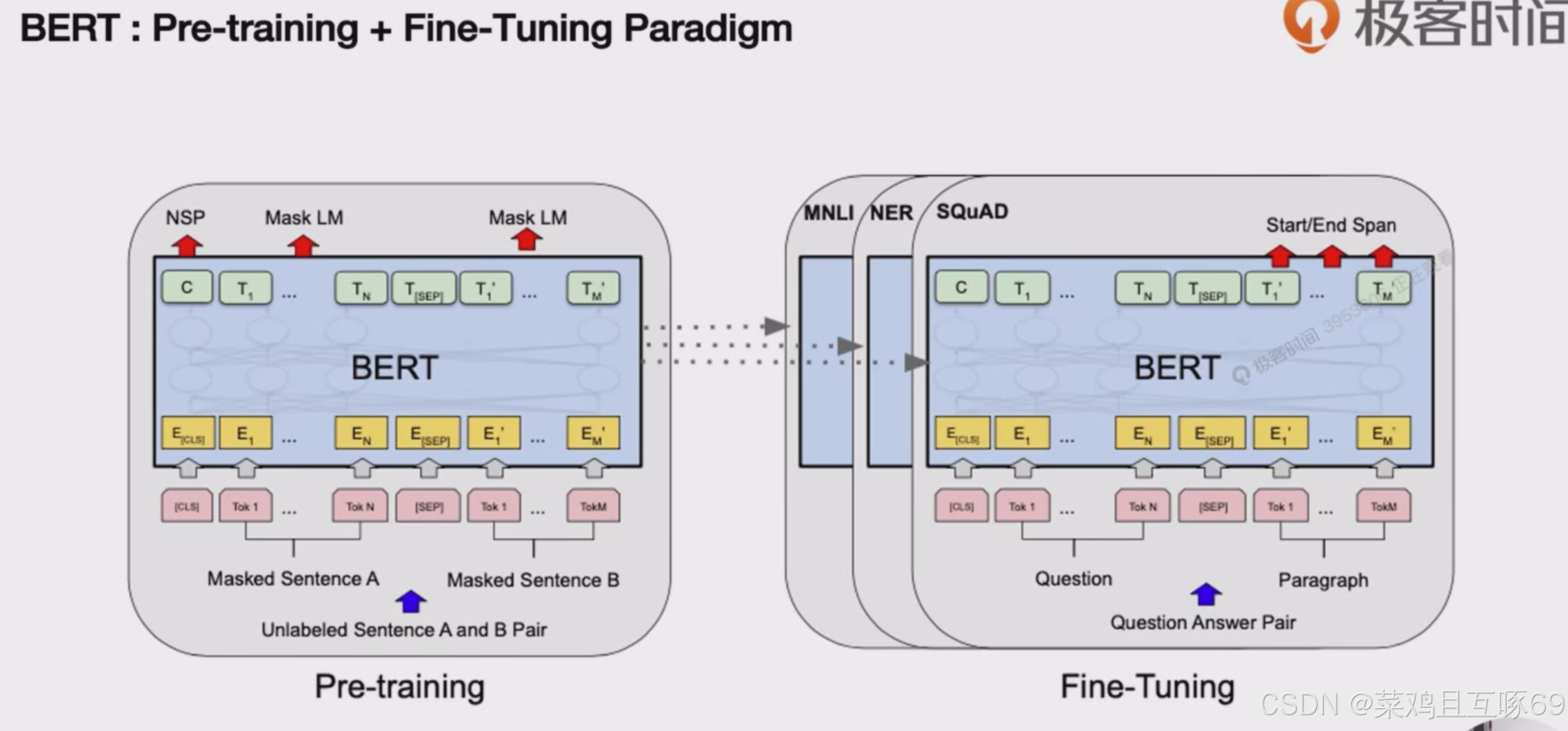
 1.BERT模型采用了预训练(Pre-training)加微调(Fine-tuning)的训练范式。 2.预训练使用大量无标签数据,微调使用少量有标签数据。 3.这种范式降低了数据标注的成本,提高了模型的泛化能力。
1.BERT模型采用了预训练(Pre-training)加微调(Fine-tuning)的训练范式。 2.预训练使用大量无标签数据,微调使用少量有标签数据。 3.这种范式降低了数据标注的成本,提高了模型的泛化能力。
右图中的squad,ner,,uli是数据集,是根据不同的任务做微调
BERT模型的预训练方法
1.BERT模型的预训练过程:使用大量无标签文本进行训练。 2.预训练任务:完形填空,通过mask掉部分词汇来训练模型。 3.mask的数量和替换方式:15%的词汇被mask掉,其中80%替换为mask,10%替换为随机词汇,10%保持原样。

1.BERT模型是自编码的,不需要大量标注训练数据。 2.GPT是自回归的,适合生成类任务,但上下文理解能力较弱。 3.BERT模型更适合理解上下文,适用于信息提取、问答系统等任务。


首先在无监督学习进行一个预训练,然后 在有监督的情况下进行一个微调,做下游任务


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









