







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
保存到本地
img.save(image_name)
return image_name
现在可以使用百度提供的 API 获取到上面截图的人脸列表。
def parse_face_pic(pic_url, pic_type, access_token):
“”"
人脸识别
5秒之内
:param pic_url:
:param pic_type:
:param access_token:
:return:
“”"
url_fi = ‘https://aip.baidubce.com/rest/2.0/face/v3/detect?access_token=’ + access_token
调用identify_faces,获取人脸列表
json_faces = identify_faces(pic_url, pic_type, url_fi)
if not json_faces:
print(‘未识别到人脸’)
return None
else:
返回所有的人脸
return json_faces
从上述的人脸列表中筛选出性别为女,年龄为 18-30 岁之间,颜值超过 70 的小姐姐。
def analysis_face(face_list):
“”"
分析人脸,判断颜值是否达标
18-30之间,女,颜值大于80
:param face_list:识别的脸的列表
:return:
“”"
是否能找到高颜值的美女
find_belle = False
if face_list:
print(‘一共识别到%d张人脸,下面开始识别是否有美女~’ % len(face_list))
for face in face_list:
判断是男、女
if face[‘gender’][‘type’] == ‘female’:
age = face[‘age’]
beauty = face[‘beauty’]
if 18 <= age <= 30 and beauty >= 70:
print(‘颜值为:%d,及格,满足条件!’ % beauty)
find_belle = True
break
else:
print(‘颜值为:%d,不及格,继续~’ % beauty)
continue
else:
print(‘性别为男,继续~’)
continue
else:
print(‘图片中没有发现人脸.’)
return find_belle
由于视频是连续播放的,很难通过截取视频某一帧,判断视频有出现颜值高的小姐姐。
另外,大部分短视频播放时长为「10s+」,这里需要对每一个视频多次截图去做人脸识别,直到识别到颜值高的小姐姐。
一条视频最长的识别时间
RECOGNITE_TOTAL_TIME = 10
识别次数
recognite_count = 1
对当前视频截图去人脸识别
while True:
获取截图
print(‘开始第%d次截图’ % recognite_count)
截取屏幕有用的区域,过滤视频作者的头像、BGM作者的头像
screen_name = get_screen_shot_part_img(‘images/temp%d.jpg’ % recognite_count)
人脸识别
recognite_result = analysis_face(parse_face_pic(screen_name, TYPE_IMAGE_LOCAL, access_token))
recognite_count += 1
第n次识别结束后的时间
recognite_time_end = datetime.now()
这一条视频出现了颜值高的小姐姐
if recognite_result:
pass
else:
print(‘超时!!!这是一条没有吸引力的视频!’)
跳出里层循环
break
一旦当前播放的视频识别出有颜值高的小姐姐,就需要模拟保存视频到本地的操作。
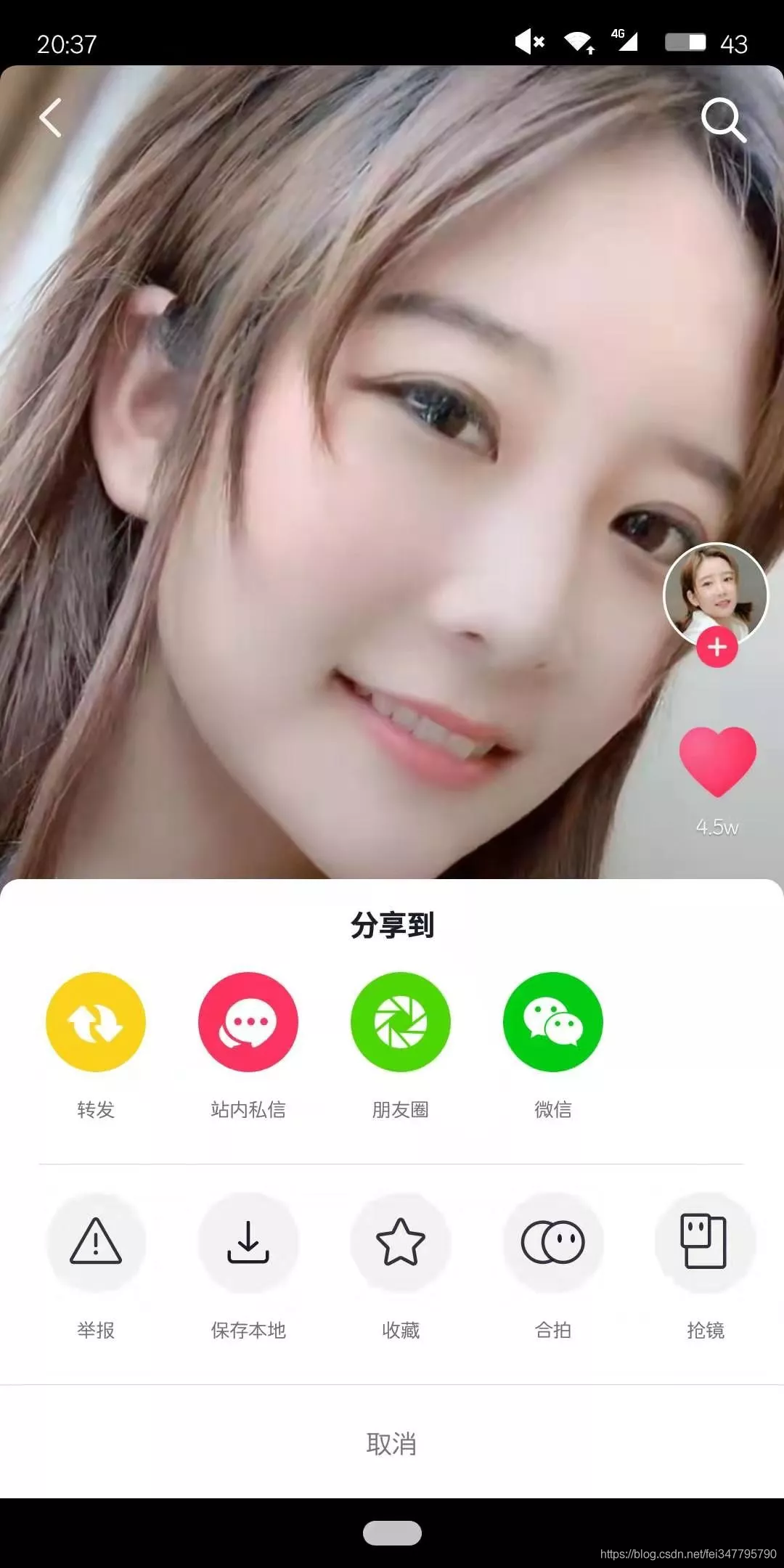
获取「分享」和「保存本地」两个按钮的坐标位置,依次利用 adb 执行点击操作即可下载视频到本地。
def save_video_met():
“”"
:return:
“”"
分享
os.system(“adb shell input tap 1000 1500”)
time.sleep(0.05)
保存到本地
os.system(“adb shell input tap 350 1700”)
另外,由于下载视频的过程是一个耗时操作,在下载进度对话框还未消失之前,需要做一个「模拟等待」的操作。
def wait_for_download_finished(poco):
“”"
从点击下载,到下载完全
:return:
“”"
element = Element()
while True:
由于是对话框,不能利用Element类来判断是否存在某个元素来准确处理
element_result = element.findElementByName(‘正在保存到本地’)
当前页面UI树元素信息
注意:保存的时候可能会获取元素异常,这里需要抛出,并终止循环
com.netease.open.libpoco.sdk.exceptions.NodeHasBeenRemovedException: Node was no longer alive when query attribute “visible”. Please re-select.
try:
ui_tree_content = json.dumps(poco.agent.hierarchy.dump(), indent=4).encode(‘utf-8’).decode(‘unicode_escape’)
except Exception as e:
print(e)
print(‘异常,按下载处理~’)
break
if ‘正在保存到本地’ in ui_tree_content:
print(‘还在下载中~’)
time.sleep(0.5)
continue
else:
print(‘下载完成~’)
break
在视频保存到本地之后,就可以模拟向上滑动的操作,跳到播放「下一条视频」。
循环上面的操作,即可筛选出所有颜值高的小姐姐,并保存到本地。
def play_next_video():
“”"
下一个视频
从下往上滑动
:return:
“”"
os.system(“adb shell input swipe 540 1300 540 500 100”)
在脚本一条条刷视频的过程中,可能会遇到一下广告,我们需要对这类视频进行过滤。
def is_a_ad():
“”"
判断的当前页面上是否是一条广告
:return:
“”"
element = Element()
ad_tips = [‘去玩一下’, ‘去体验’, ‘立即下载’]
find_result = False
for ad_tip in ad_tips:
try:
element_result = element.findElementByName(ad_tip)
是一条广告,直接跳出
find_result = True
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









