






目录
使用node.js的模块之前需要在使用的js中引入相应模块
如:
let fs=require('fs');
let url=require('url');
let qs=require('querystring');
一.fs
fs模块内的方法均有同步和异步操作,如读取文件夹的同步操作为fs.readdirSync(path[, options]),异步操作为fs.readdir(path[, options], callback)
1.读取文件目录
同步读取: fs.readdirSync(path[, options])
其中path为文件夹路径,[ ]中的内容可以不写
let dirs=fs.readdirSync('./');
console.log(dirs); 异步读取:fs.readdir(path[, options], callback)
其中path为文件夹路径,[ ]中的内容可以不写,callback是回调函数
回调有两个参数 (err, files),其中 files 是目录中文件名的数组
err默认为null,当执行出现错误时,err为错误
let dirs=fs.readdir('./',(err,data)=>{
if(err){
console.log(err);
}else{
console.log(data);
}
})
console.log(dirs);2.创建文件(覆盖写入)
fs.writeFile(file, data[, options], callback)
其中file为文件名或文件描述符,data为文件内容,callback为回调函数
当 file 是文件名时,将数据异步地写入文件,如果文件已存在则替换该文件。 data 可以是字符串或缓冲区。
当 file 是文件描述符时,其行为类似于直接调用 fs.write()
fs.writeFile('next.txt','今天是个好日子',(err,data)=>{
if(err){
console.log(err);
}
})3.将数据追加到文件
fs.appendFile(path, data[, options], callback)
异步地将数据追加到文件,如果该文件尚不存在,则创建该文件。 data 可以是字符串或<Buffer>
其中path为文件名或文件描述符,data为追加内容,callback为回调函数
fs.appendFile('next.txt','加油加油',(err)=>{
console.log(err);
})4.读取文件
fs.readFile(path[, options], callback)
异步地读取文件的全部内容
path为文件名或文件描述符,callback为回调函数
fs.readFile('next.txt',(err,msg)=>{
if(err){
console.log(err);
}else{
console.log(msg.toString('UTF-8')); //默认读取二进制数据流
}
})5.删除文件
fs.unlink(path, callback)
异步地删除文件或符号链接。 除了可能的异常(err)之外,没有为完成回调提供任何参数
path为文件名或文件描述符,callback为回调函数
fs.unlink('./next.txt',(err)=>{
if(err){
console.log(err);
}
})注:fs.unlink() 不适用于目录,无论是空目录还是其他目录。 要删除目录,请使用fs.rmdir()
二.URL
URL代表着是统一资源定位符(Uniform Resource Locator),是一个给定的独特资源在 Web 上的地址,理论上说,每个有效的 URL 都指向一个唯一的资源。
网址字符串是包含多个有意义组件的结构化字符串。 解析时,将返回包含每个组件的属性的网址对象。
url结构组成:
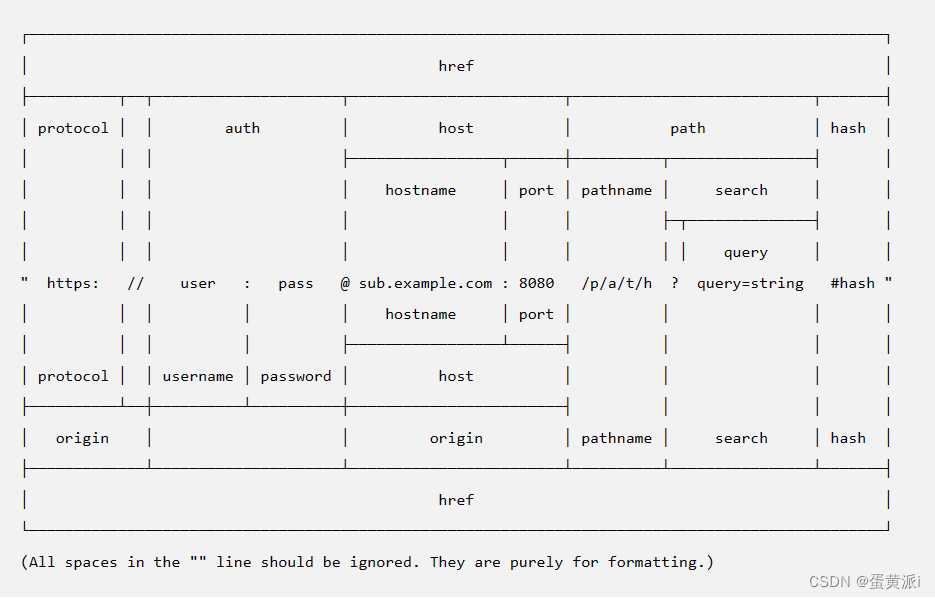
1.url字符串转对象
url.parse(urlString[, parseQueryString[, slashesDenoteHost]])
urlString为要解析的 URL 字符串
let url=require('url');
let urlString='https://nodejs.org/dist/v18.15.0/docs/api/url.html';
let urlobj=url.parse(urlString)
console.log(urlobj);输出结果为:
Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'nodejs.org',
port: null,
hostname: 'nodejs.org',
hash: null,
search: null,
query: null,
pathname: '/dist/v18.15.0/docs/api/url.html',
path: '/dist/v18.15.0/docs/api/url.html',
href: 'https://nodejs.org/dist/v18.15.0/docs/api/url.html'
}
2.url对象转字符串
url.format(urlObject)
urlobject为网址对象
url.format() 方法返回从 urlObject 派生的格式化网址字符串。
let obj={
protocol: 'https:',
slashes: true,
auth: null,
host: 'nodejs.org',
port: null,
hostname: 'nodejs.org',
hash: null,
search: null,
query: null,
pathname: '/dist/v18.15.0/docs/api/url.html',
path: '/dist/v18.15.0/docs/api/url.html',
href: 'https://nodejs.org/dist/v18.15.0/docs/api/url.html'
}
let string=url.format(obj);
console.log(string);输出结果为:
https://nodejs.org/dist/v18.15.0/docs/api/url.html三.qs (querystring)
node:querystring 模块提供了用于解析和格式化网址查询字符串的实用工具
1.字符串转对象
querystring.parse(str[, sep[, eq[, options]]])
将网址查询字符串 (str) 解析为键值对的集合
str要解析的网址查询字符串sep用于在查询字符串中分隔键值对的子字符串。 默认值:'&'eq用于分隔查询字符串中的键和值的子字符串。 默认值:'='
let qs=require('querystring');
let string='name=hahaha&key=lalala&pass=123';
let obj=qs.parse(string)
console.log(obj); //{ name: 'hahaha', key: 'lalala', pass: '123' }2.对象转字符串
querystring.stringify(obj[, sep[, eq[, options]]])
该方法通过遍历对象的 "自有属性" 从给定的 obj 生成 URL 查询字符串。
obj为要序列化为网址查询字符串的对象
let strings=qs.stringify(obj,'#','-');
console.log(strings); //name-hahaha#key-lalala#pass-1233.编码
querystring.escape(str)
该方法以针对网址查询字符串的特定要求优化的方式对给定的 str 执行网址百分比编码。
let ojb=qs.escape(strign)
console.log(ojb); //w%3D%E4%BD%A0%E5%A5%BD%E5%91%80%26name%3Dhaha4.解码
querystring.unescape(str)
方法在给定的 str 上执行网址百分比编码字符的解码。
let strgin=qs.unescape(ojb);
console.log(strgin); //w=你好呀&name=haha













 1469
1469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









