






 文章详细介绍了五个关于SQL查询的任务,涉及学生平均成绩筛选、课程匹配、特定教师成绩最高学生、多门不及格课程筛选以及平均成绩计算,展示了使用SQL进行数据处理和分析的基本技巧。
文章详细介绍了五个关于SQL查询的任务,涉及学生平均成绩筛选、课程匹配、特定教师成绩最高学生、多门不及格课程筛选以及平均成绩计算,展示了使用SQL进行数据处理和分析的基本技巧。
第1关:查询学生平均分
任务描述
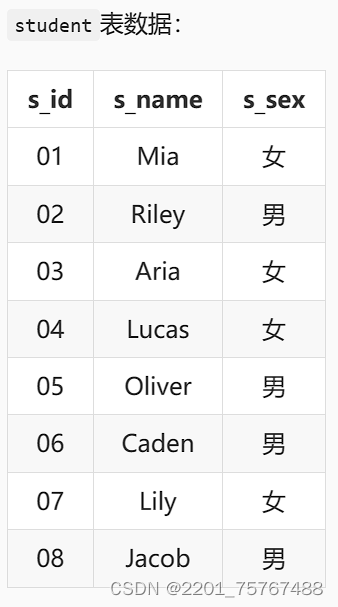
本关任务:根据提供的表和数据,查询平均成绩小于60分的同学的学生编号(s_id)、学生姓名(s_name)和平均成绩(avg_score),要求平均成绩保留2位小数点。(注意:包括有成绩的和无成绩的,无成绩的 score = 0.00)

代码:
#新建一个视图备用
create view Big_tab as
(select stu.s_id,stu.s_name,s.s_score from student stu
left outer join score s on stu.s_id=s.s_id);
#主逻辑
select s_id,s_name,
round(avg(if(s_score is null,0,s_score)) ,2) as avg_score
from Big_tab
group by s_id
having avg(if(s_score is null,0,s_score))<60;解析:
1,新建笛卡尔积视图。(student表左连score表即可)
2,按s_id分组后,用having筛选出满足"AVG()函数表达式<60"的记录。
3,四舍五入(round)保留2位小数。
第2关:查询修课相同学生信息
任务描述
本关任务:根据提供的表和数据,查询与s_id=01号同学学习的课程完全相同的其他同学的信息(学号s_id,姓名s_name,性别s_sex)。
需要用到的表同第一题。
代码:
#新建视图备用(笛卡尔积)
create view Big_tab as
(select a.s_id,a.s_name,a.s_sex,b.c_id,b.s_score from student a
right outer join score b on a.s_id=b.s_id);
#再次新建视图备用(内装s_id=1 的同学选的所有课)
create view elements as
(select c_id from Big_tab where s_id=1);
#再再次新建变量备用
set @n=
(select count(c_id) from Big_tab
where s_id=1); # 在这题中,@n的值为3
#主逻辑:
select s_id,s_name,s_sex from Big_tab
group by s_id
having @n=count(c_id in (select * from elements)) and s_id!=1;解析:
1,新建笛卡尔积视图。(student表右连score表即可)
2,新建elements视图,把s_id=1的同学的所有课程装进来,方便后续判断。
3,算一算这个elements视图的元素个数,放进变量@n中。(在这题中,@n=3)
4,主逻辑是:按s_id分组后,把 每一个组(即每个单独的学生)的每科成绩给遍历一遍,如果这个同学的c_id满足c_id in elements(即c_id是s_id=1的同学的选课集合的子元素),计算这样的记录的条数;如果恰好等于@n(即3——也就是s_id=1的同学的选课集合的数目),则筛选出这样的同学即可。
#这题考察父查询语句和子查询语句的元组匹配问题。关键思想是“若子元素个数等于元素总数,则两元组相等”。
第3关:查询各科成绩并排序
任务描述
本关任务:根据提供的表和数据,查询各科成绩,进行排序并显示排名,按学生编号(s_id)、课程编号(c_id)、学生成绩(s_score)和排名(rank)进行输出,具体效果请查看测试集。
#新建笛卡尔积视图备用
create view Big_tab as
(select a.s_id,b.c_id,b.s_score from student a
right outer join score b on a.s_id=b.s_id);
#主逻辑
select *,(select count(s_score)+1
from Big_tab where s_score>Main.s_score and c_id=Main.c_id) as rank
from Big_tab Main;解析:
1,新建笛卡尔积视图。(student表右连score表即可)
2,主逻辑:观察测试集数据,我们可以发现,右侧的rank列是针对于每一个课程而言的。意即,每一个课程会有单独的排名,总共三个排名(c_id分别为01,02,03),它们塞到了一个表里,作为本题的答案。而这种排名方式,属于【复杂查询(一)】中第三题的第二小问的内容——即“跳跃式”排名。这里不做赘述。只消知道,这里的关键点,在于“如何分别排序”,即“如何就每一种课程单独排序”。如果只对其中一门课程排序,我们可以这样写代码:
#主逻辑:只显示2号课程的排序结果
select *,(select count(s_score)+1
from Big_tab where s_score>Main.s_score and c_id=2) as rank
from Big_tab Main
where c_id=2;我们可以发现,子查询和父查询的连接点,在 “c_id = 2” 这个位置。所以,我们可以将2这个常数用一个变量代替,即父查询的c_id值,这里需写成:"c_id = Main.c_id"(Main是父查询中的表的别名)。如此即可。
第4关:查询张老师课程成绩最高的学生信息
任务描述
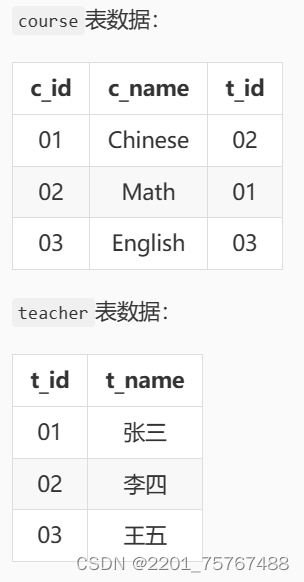
本关任务:根据提供的表和数据,查询选修“张三”老师所授课程的学生中,成绩最高的学生信息(具体输出信息请查看测试说明)及其成绩。
代码:
#新建笛卡尔积视图(需要连接四个表)
create view Big_tab as
(select stu.s_id,stu.s_name,stu.s_sex,s.s_score,c.c_id,c.c_name,t.t_name
from student stu
left outer join score s on stu.s_id=s.s_id
left outer join course c on s.c_id=c.c_id
left outer join teacher t on c.t_id=t.t_id);
#主逻辑
select s_id,s_name,s_sex,s_score,c_id,c_name from Big_tab
where t_name='张三'
and s_score=(select Max(s_score) from Big_tab where t_name='张三');解析:
1,新建视图。
2,主逻辑:先用where筛出被张三老师教的学生,然后按学号分组,筛出满足聚合函数(即s_score=Max(...) )条件的记录即可。
第5关:查询两门课程不及格同学信息
任务描述
本关任务:根据提供的表和数据,查询两门及其以上不及格课程的同学的学号(s_id)、姓名(s_name)及其平均成绩(avg_score),要求计算平均成绩后为整数。
代码:
#新建笛卡尔积视图
create view Big_tab as
(select stu.s_id,stu.s_name,s.s_score from student stu
right outer join score s on stu.s_id=s.s_id);
#主逻辑
select s_id,s_name, round(AVG(s_score))as avg_score from Big_tab Main
group by s_id
having count(if(s_score>=60,null,1))>=2;解析:
1,新建视图。(student右连score即可)
2,主逻辑:按学号分组,对每个组,计算其s_score<60的记录数,然后筛选出这个值大于等于2的组。在这里,count函数的参数为if,第一个参数是条件,第二个是null,表示“如果满足分数及格,则返回null,即不会被计数”;第三个参数是任意值,表示“如果不及格,则会被计数”。
以上。

















 5682
5682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









