










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、scikit-learn机器学习、Echarts可视化、requests爬虫、车主之家
3种预测算法:
(1)ARIMA差分自回归移动平均算法
(2)决策树回归算法
(3)Ridge岭回归算法
时间序列分析(ARIMA)、回归任务(决策树回归、岭回归)的模型。
2、项目界面
(1)首页–注册登录
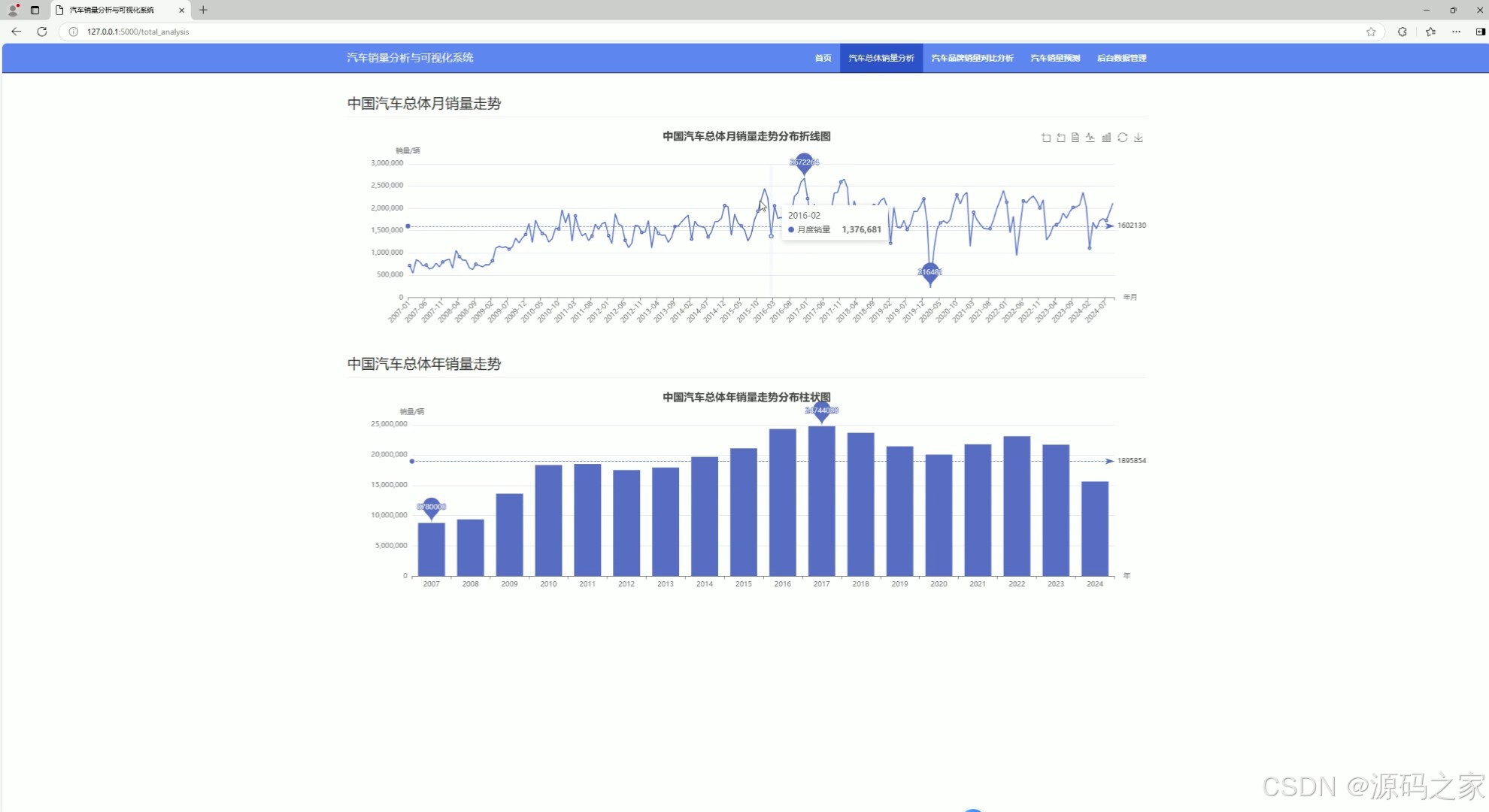
(2)汽车销量分析
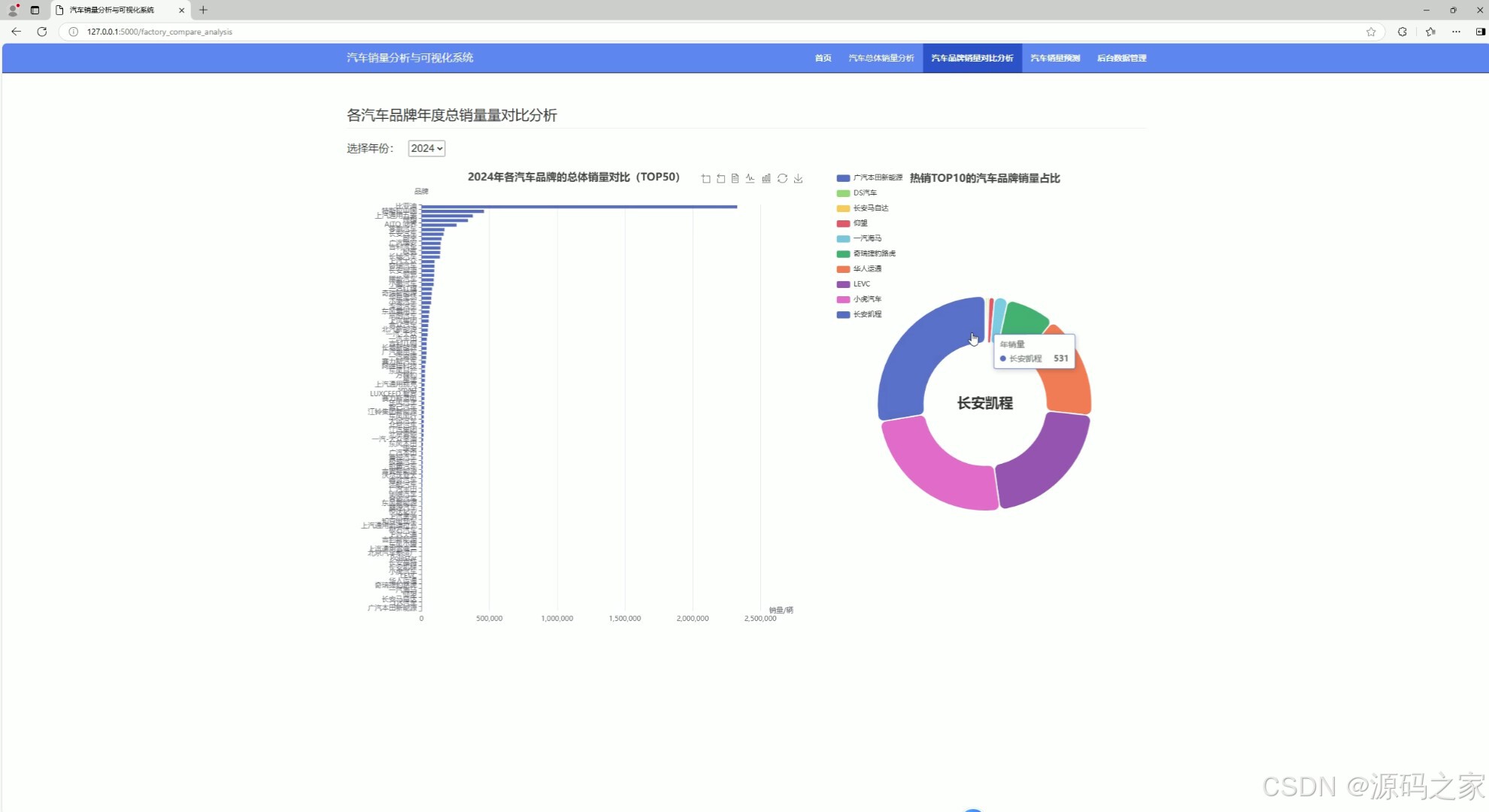
(3)汽车不同品牌销量对比分析
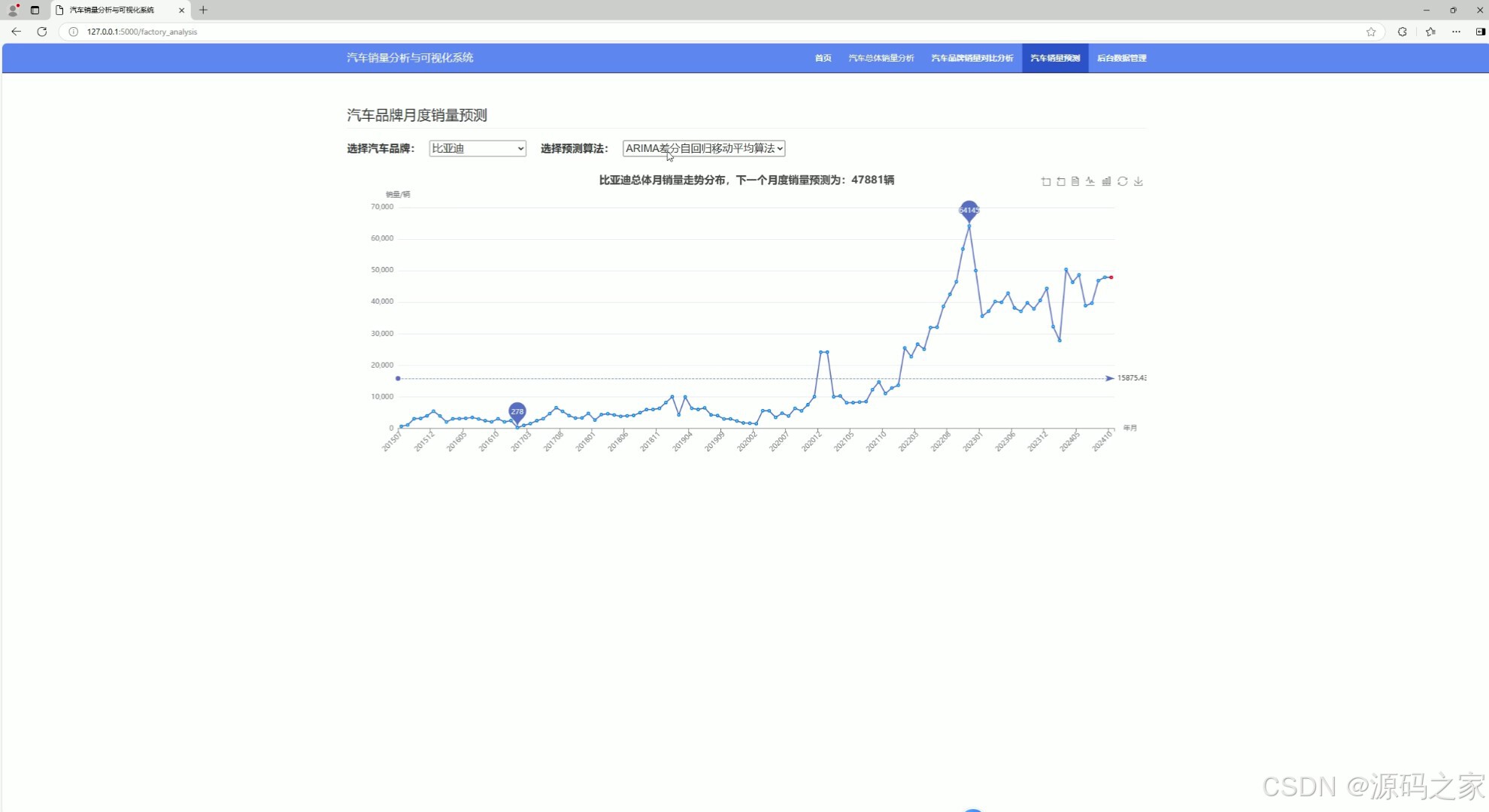
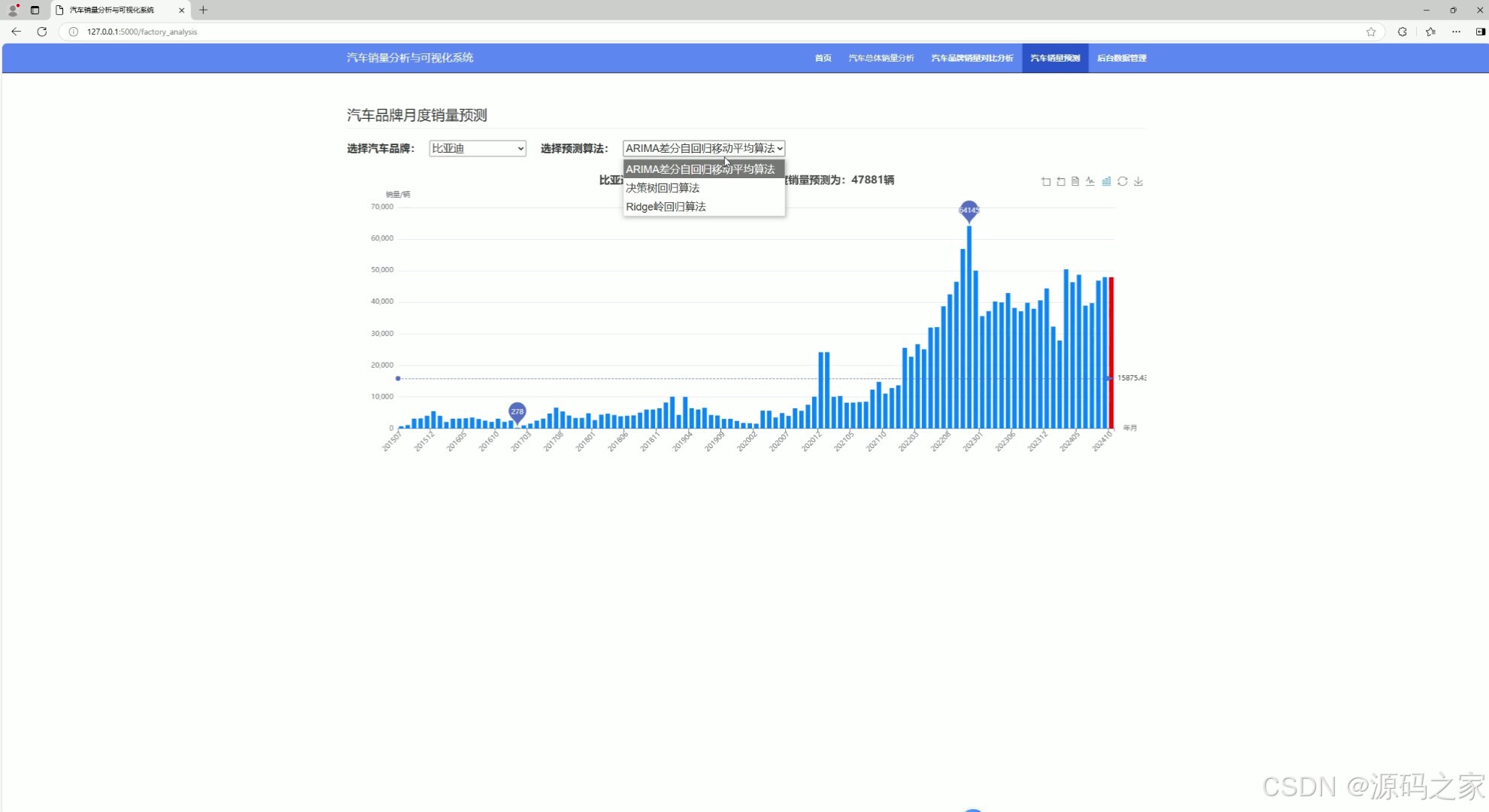
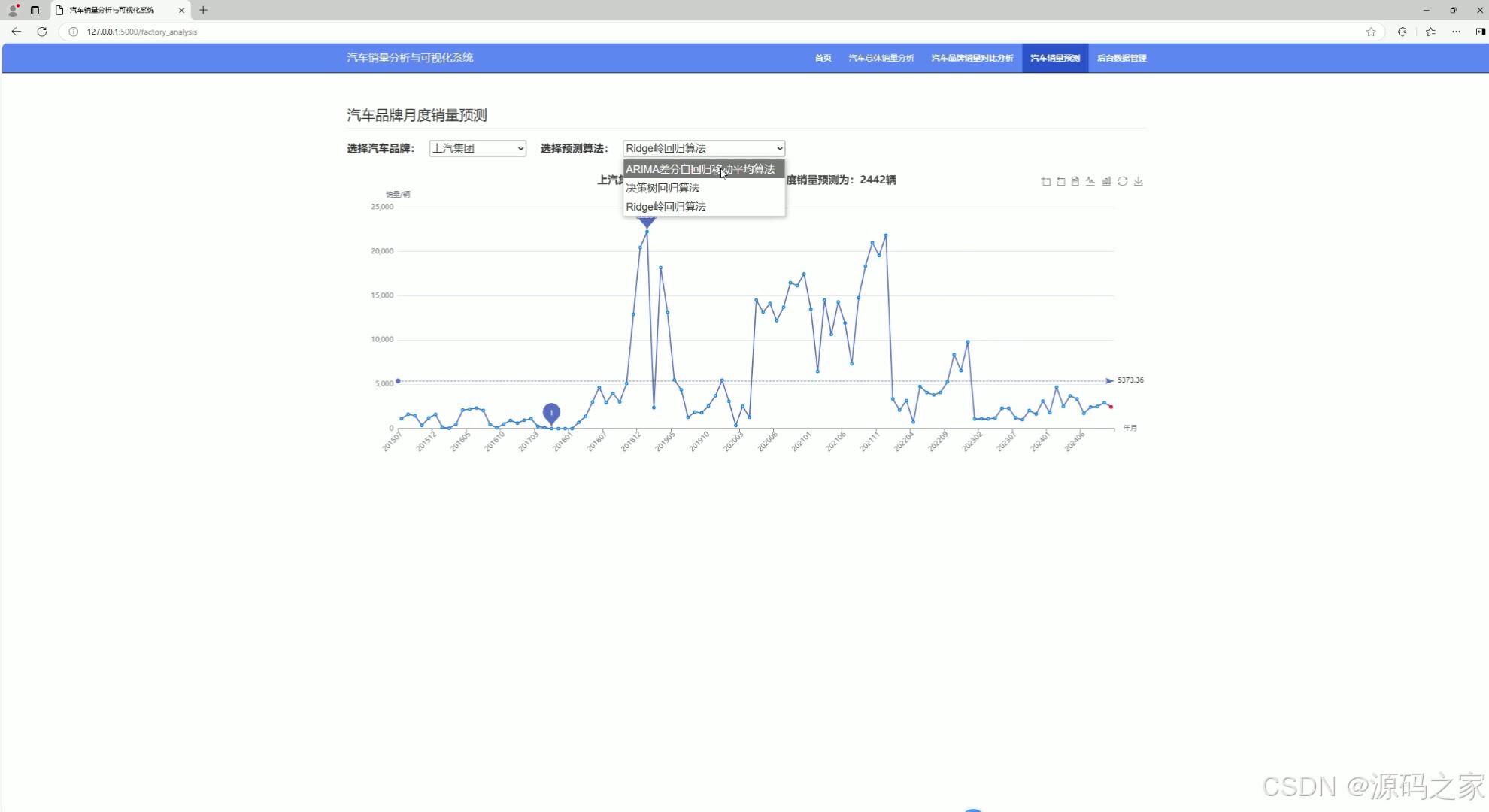
(4)汽车销量预测—3种预测算法
(5)后台数据管理
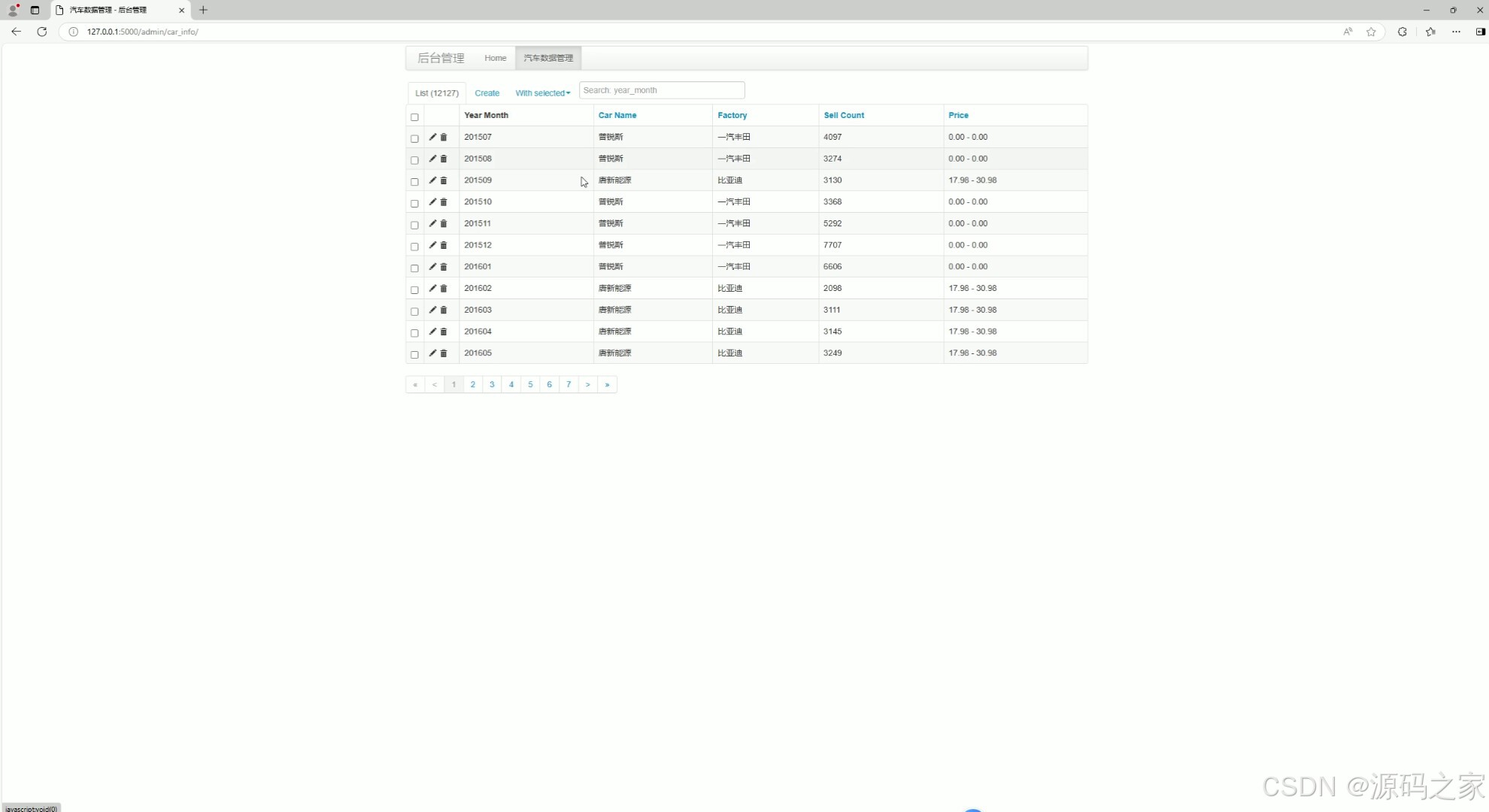
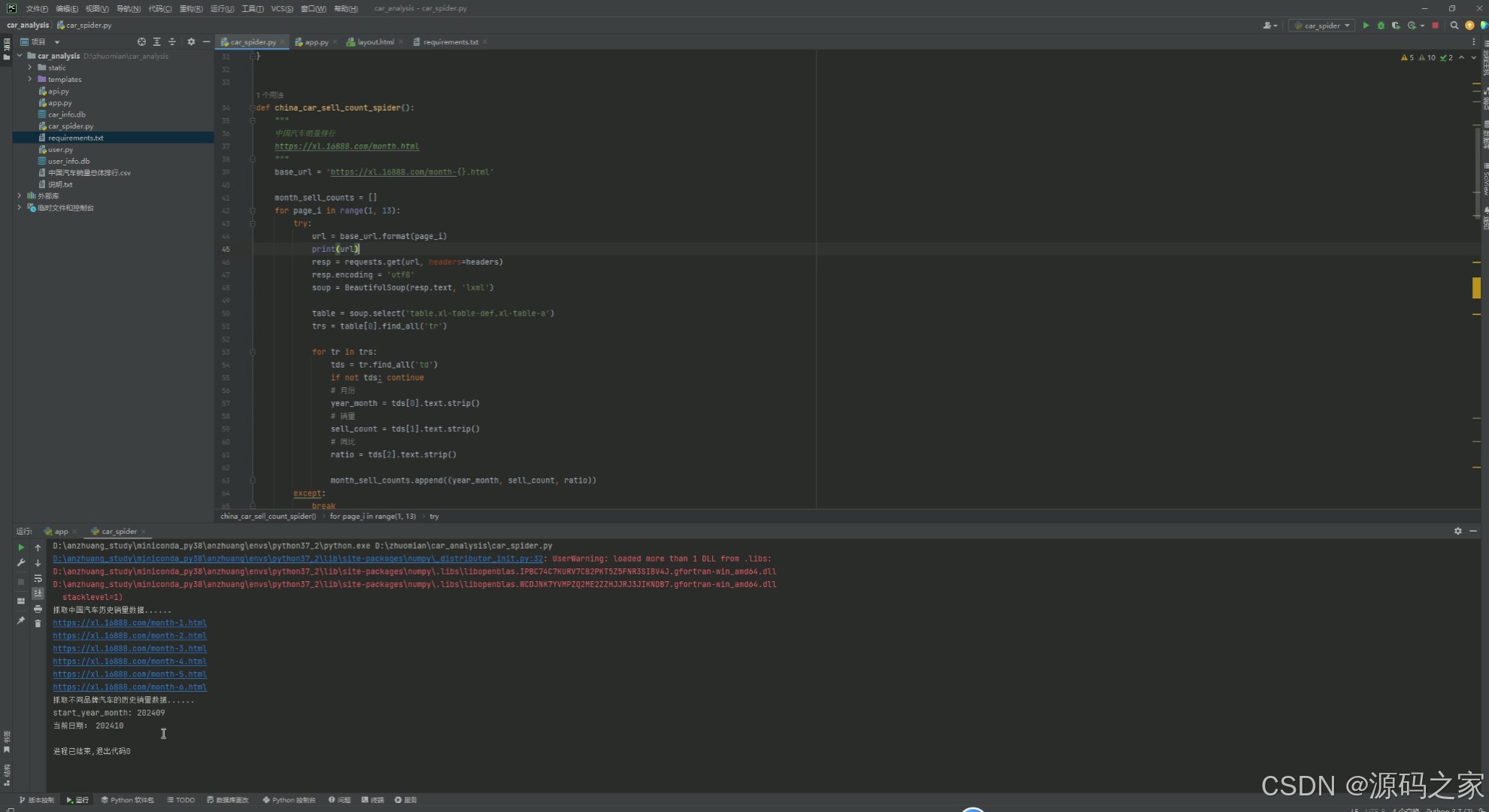
(6)数据采集
3、项目说明
项目功能模块介绍
1. 首页——注册登录
- 功能:用户可以通过此界面注册新账号或登录已有账号。
- 实现方式:
- 使用 Flask 框架搭建后端服务,提供用户注册和登录的接口。
- 前端使用 HTML 和 CSS 设计注册登录页面,用户输入用户名和密码后通过表单提交到后端进行验证。
- 后端验证用户信息,成功后允许用户进入系统。
2. 汽车销量分析
- 功能:展示汽车销量的整体分析结果,包括历史销量数据、趋势等。
- 实现方式:
- 使用
requests爬虫从车主之家等数据源获取汽车销量数据。 - 数据存储到本地数据库(如 SQLite 或 MySQL)。
- 使用 Flask 后端从数据库中提取数据。
- 前端通过 Echarts 生成图表,展示销量数据的趋势和分布。
- 使用
3. 汽车不同品牌销量对比分析
- 功能:对比不同品牌汽车的销量数据,帮助用户了解市场表现。
- 实现方式:
- 数据通过爬虫获取并存储到数据库。
- 使用 Flask 后端从数据库中提取不同品牌的销量数据。
- 前端通过 Echarts 生成柱状图或折线图,展示品牌之间的销量对比。
4. 汽车销量预测——3种预测算法
- 功能:使用三种不同的预测算法(ARIMA、决策树回归、岭回归)预测汽车未来的销量。
- 实现方式:
- 使用 Python 的
scikit-learn库实现决策树回归和岭回归算法。 - 使用 Python 的
statsmodels库实现 ARIMA 算法。 - 用户可以通过前端界面选择不同的算法进行预测。
- 后端根据用户选择的算法和输入的特征数据进行预测,并将结果返回到前端。
- 前端通过 Echarts 展示预测结果。
- 使用 Python 的
5. 后台数据管理
- 功能:管理员可以在此模块管理网站的数据,包括汽车信息、用户数据、销量数据等。
- 实现方式:
- 使用 Flask 提供管理接口,管理员可以通过网页操作数据库。
- 前端使用 HTML 和 CSS 设计管理界面,方便管理员进行数据操作。
- 提供数据的导入、导出、更新等功能。
6. 数据采集
- 功能:定期从外部数据源(如车主之家)采集汽车销量数据。
- 实现方式:
- 使用 Python 的
requests库编写爬虫脚本,从车主之家等网站获取数据。 - 数据采集脚本定期运行,将数据存储到数据库。
- 可以通过后台管理界面手动触发数据采集任务。
- 使用 Python 的
技术细节
预测算法
-
ARIMA 差分自回归移动平均算法
- 适用于时间序列数据的预测。
- 通过差分处理使时间序列平稳,然后建立自回归和移动平均模型。
-
决策树回归算法
- 使用决策树模型进行回归预测。
- 通过树结构划分数据,预测目标值。
-
Ridge 岭回归算法
- 一种线性回归算法,通过引入正则化项防止过拟合。
- 适用于特征较多的回归任务。
数据可视化
- 使用 Echarts 可视化库生成各种图表,包括柱状图、折线图、饼图等。
- 前端通过 Flask 后端提供的数据动态生成图表。
数据采集
- 使用
requests爬虫从车主之家等网站获取数据。 - 数据存储到 MySQL 数据库,方便后续分析和预测。
4、核心代码
from flask import jsonify, Blueprint
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
import sqlite3
from statsmodels.tsa.arima.model import ARIMA
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import Ridge
import numpy as np
api_blueprint = Blueprint('api', __name__)
# 读取数据库的数据
query_sql = "select * from car_info"
conn = sqlite3.connect('car_info.db')
cursor = conn.cursor()
cursor.execute(query_sql)
results = cursor.fetchall()
month_sell_counts = pd.read_csv('中国汽车销量总体排行.csv')
factory_month_sell_counts = pd.DataFrame(results)
factory_month_sell_counts.columns = ['时间', '车型', '厂商', '销量', '售价']
factory_month_sell_counts['年'] = factory_month_sell_counts['时间'].map(lambda x: str(x)[:4])
month_sell_counts = month_sell_counts.sort_values(by='时间', ascending=True)
month_sell_counts['年'] = month_sell_counts['时间'].map(lambda x: x.split('-')[0])
@api_blueprint.route('/month_year_sell_count')
def month_year_sell_count():
"""
基础折线图
"""
x = month_sell_counts['时间'].values.tolist()
y1 = month_sell_counts['销量'].values.tolist()
return jsonify({
'x': x,
'y1': y1
})
@api_blueprint.route('/year_sell_count')
def year_sell_count():
"""
基础折线图
"""
tmp = month_sell_counts[['年', '销量']].groupby('年').sum().reset_index()
x = tmp['年'].values.tolist()
y1 = tmp['销量'].values.tolist()
return jsonify({
'x': x,
'y1': y1
})
@api_blueprint.route('/get_all_factories')
def get_all_factories():
"""获取所有汽车品牌"""
factory_counts = factory_month_sell_counts['厂商'].value_counts().reset_index()
return jsonify({"factory": factory_counts['index'].values.tolist()})
@api_blueprint.route('/get_all_years')
def get_all_years():
years = factory_month_sell_counts['年'].values.tolist()
years = list(sorted(set(years), reverse=True))
return jsonify({"年": years})
def arima_model_train_eval(history):
"""
ARIMA差分自回归移动平均算法
"""
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit()
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0]
return yhat
# 训练数据集构造
# 使用历史数据的窗口
window = 5
x_train = []
y_train = []
factory_counts = factory_month_sell_counts['厂商'].value_counts().reset_index()
for factory in factory_counts['index'].values:
factory_history = factory_month_sell_counts[factory_month_sell_counts['厂商'] == factory]
if factory_history.shape[0] <= window:
continue
# 滑窗构造数据集
history_counts = factory_history['销量'].values
for i in range(0, len(history_counts) - window):
x = history_counts[i: i + window]
y = history_counts[i + window]
x_train.append(x)
y_train.append(y)
# 训练决策树和Ridge岭回归算法
ridge_model = Ridge()
ridge_model = ridge_model.fit(x_train, y_train)
tree_model = DecisionTreeRegressor()
tree_model = tree_model.fit(x_train, y_train)
print("Ridge岭回归算法训练集分数:", ridge_model.score(x_train, y_train))
print("决策树回归算法训练集分数:", tree_model.score(x_train, y_train))
def ridge_predict(history):
"""
Ridge岭回归算法
"""
x_test = np.array([history[-window:]])
pred_y = ridge_model.predict(x_test)
pred_y = pred_y[0]
return pred_y
def decision_tree_predict(history):
"""
决策树回归算法
"""
x_test = np.array([history[-window:]])
pred_y = tree_model.predict(x_test)
pred_y = pred_y[0]
return pred_y
@api_blueprint.route('/factory_month_year_sell_count_predict/<factory>/<algo>')
def factory_month_year_sell_count_predict(factory, algo):
"""
基础折线图
"""
tmp = factory_month_sell_counts[factory_month_sell_counts['厂商'] == factory]
tmp = tmp.drop_duplicates(subset=['时间'], keep='first')
year_months = tmp['时间'].values.tolist()
sell_counts = tmp['销量'].values.tolist()
# 销量预测算法
predict_sell_count = 0
if algo == "arima":
predict_sell_count = arima_model_train_eval(sell_counts)
elif algo == 'tree':
predict_sell_count = decision_tree_predict(sell_counts)
elif algo == 'ridge':
predict_sell_count = ridge_predict(sell_counts)
else:
raise ValueError(algo + " not supported.")
# 下一个月度
next_year_month = datetime.strptime(year_months[-1], '%Y%m')
next_year_month = next_year_month + relativedelta(months=1)
next_year_month = next_year_month.strftime('%Y%m')
year_months.append(next_year_month)
# 转为 int 类型
predict_sell_count = int(predict_sell_count)
sell_counts.append(predict_sell_count)
return jsonify({
'x': year_months,
'y1': sell_counts,
'predict_sell_count': predict_sell_count
})
@api_blueprint.route('/factory_year_compare/<year>')
def factory_year_compare(year):
"""
不同品牌年销量之间的对比情况
"""
tmp = factory_month_sell_counts[factory_month_sell_counts['年'] == year]
tmp = tmp[['厂商', '销量']].groupby('厂商').sum().reset_index()
tmp = tmp.sort_values(by='销量', ascending=True)
print(tmp)
x = tmp['厂商'].values.tolist()
y1 = tmp['销量'].values.tolist()
print(y1)
return jsonify({
'x': x,
'y1': y1
})
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 6133
6133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









