










博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、requests爬虫、HTML、MySQL数据库
药材数据可视化、中药数据可视化
药材:枸杞、黄芪、金银花、当归、陈皮、柴胡、升麻
中药材天地网 https://www.zyctd.com/
2、项目界面
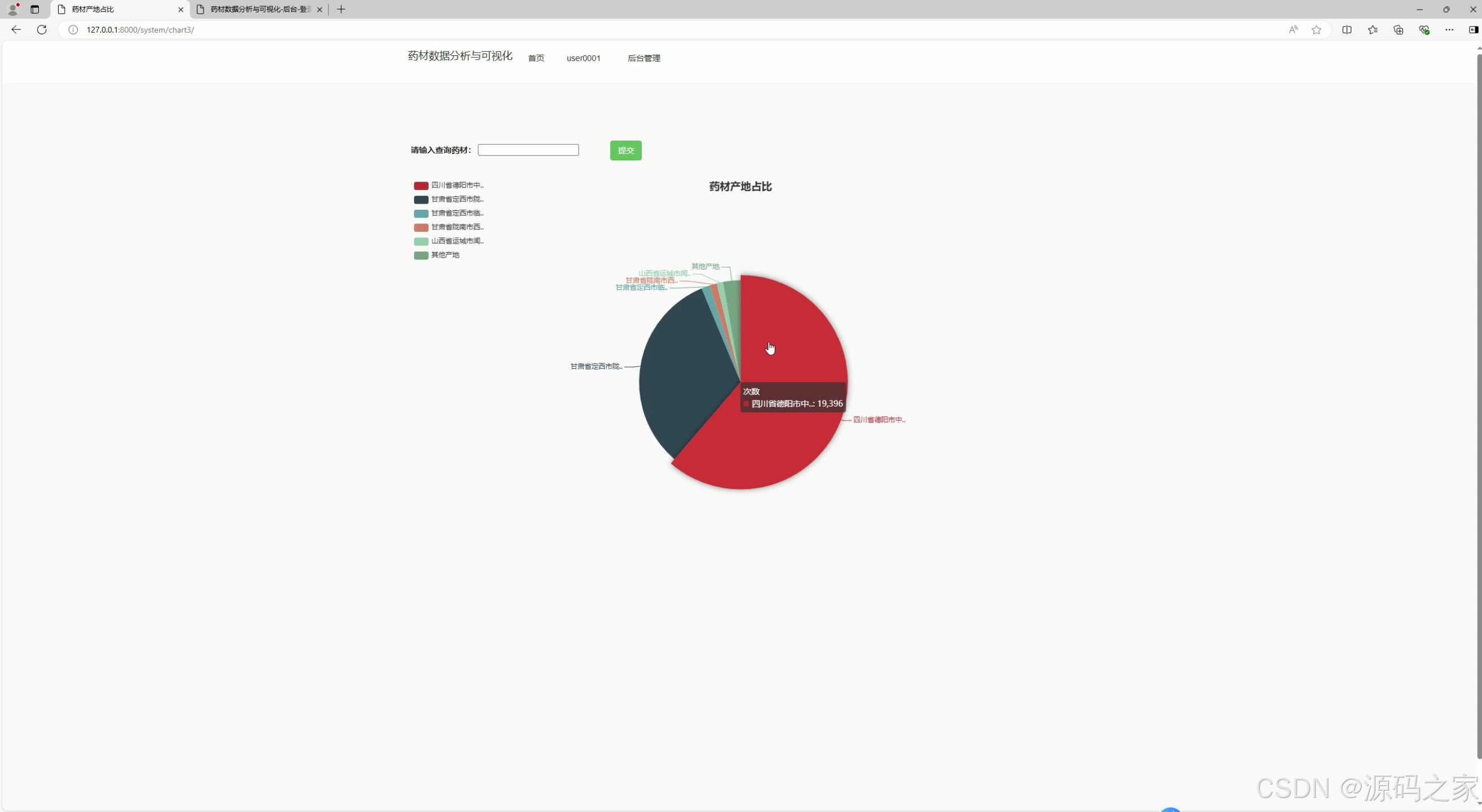
(1)药材产地占比饼图分析
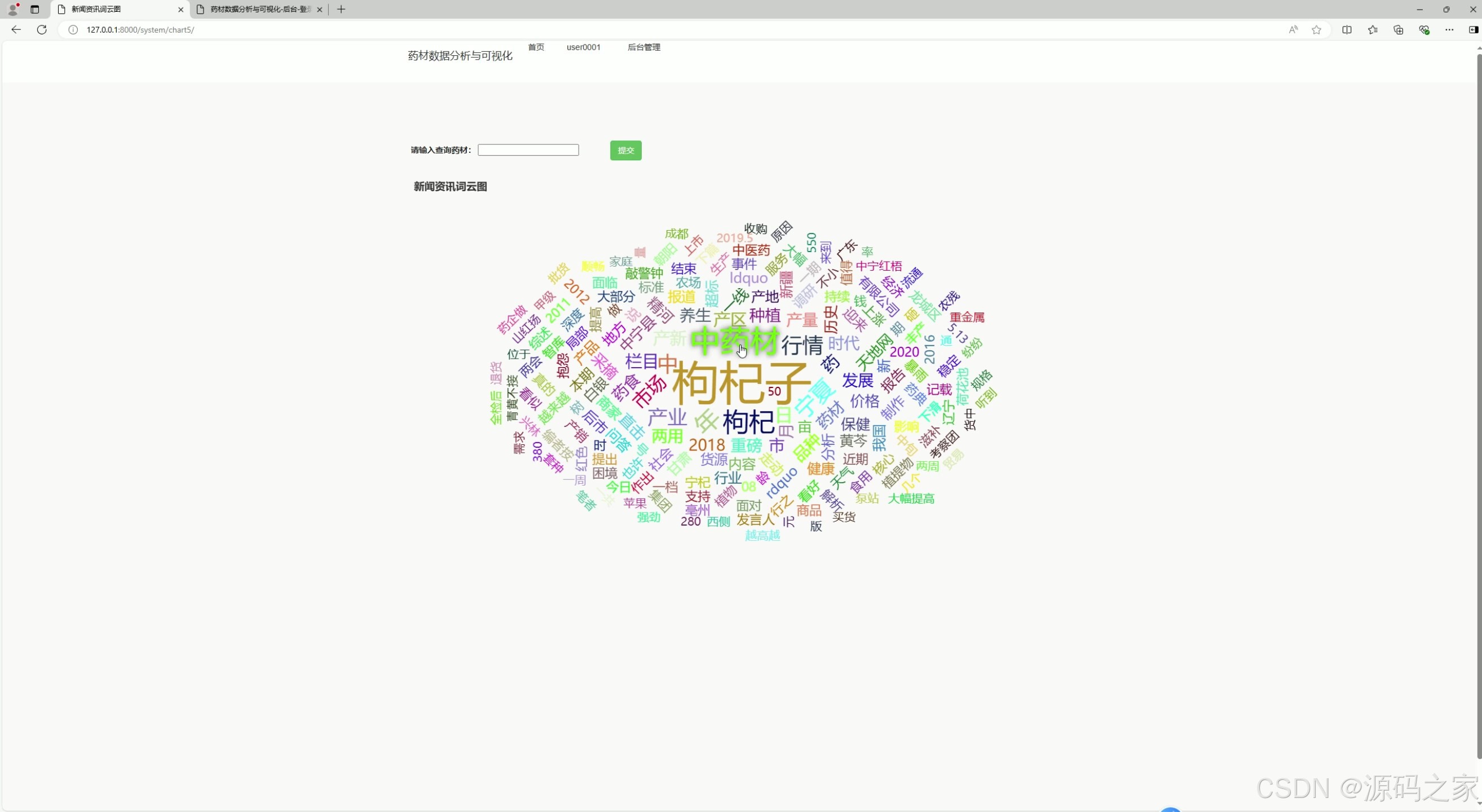
(2)词云图分析
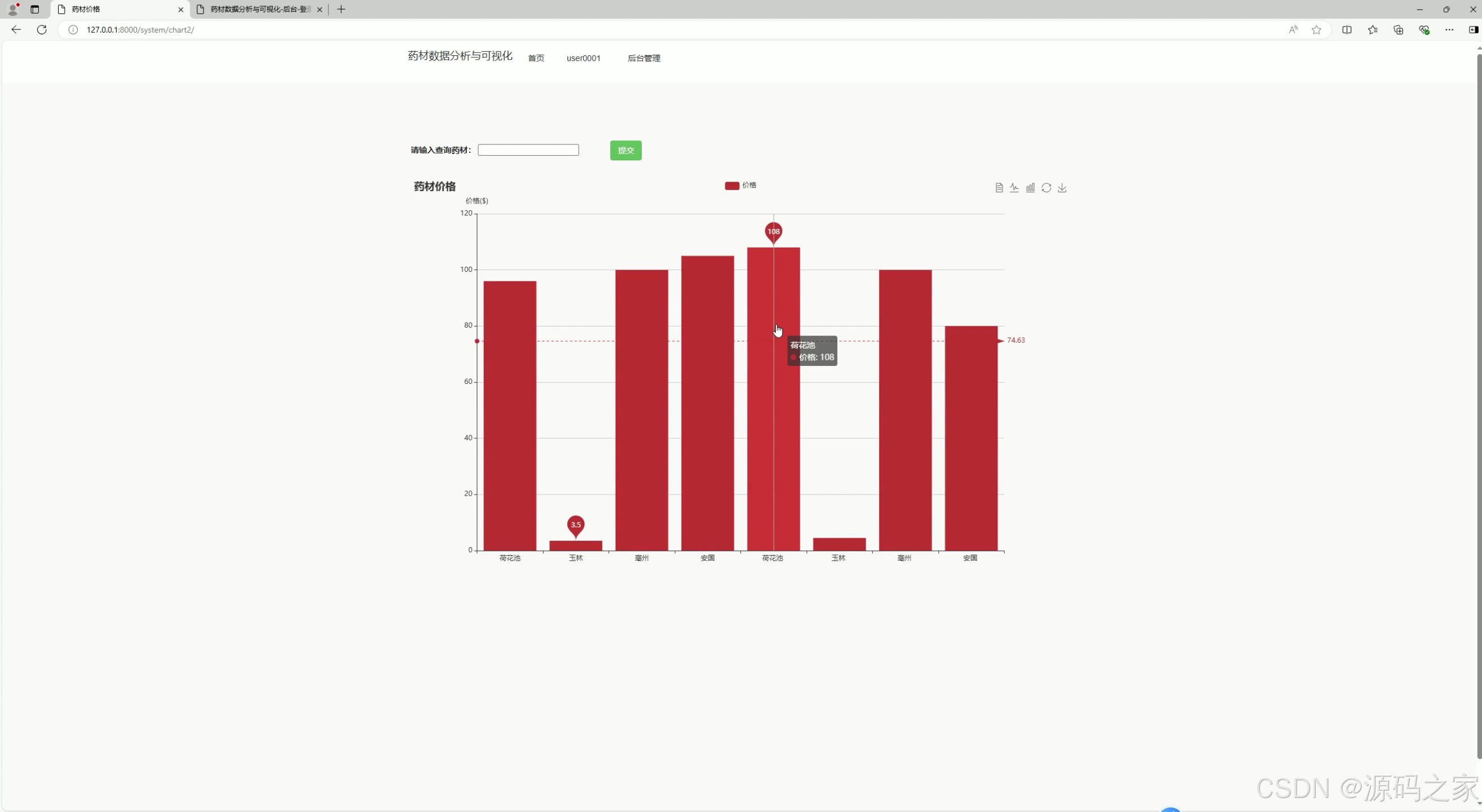
(3)药材价格柱状图分析
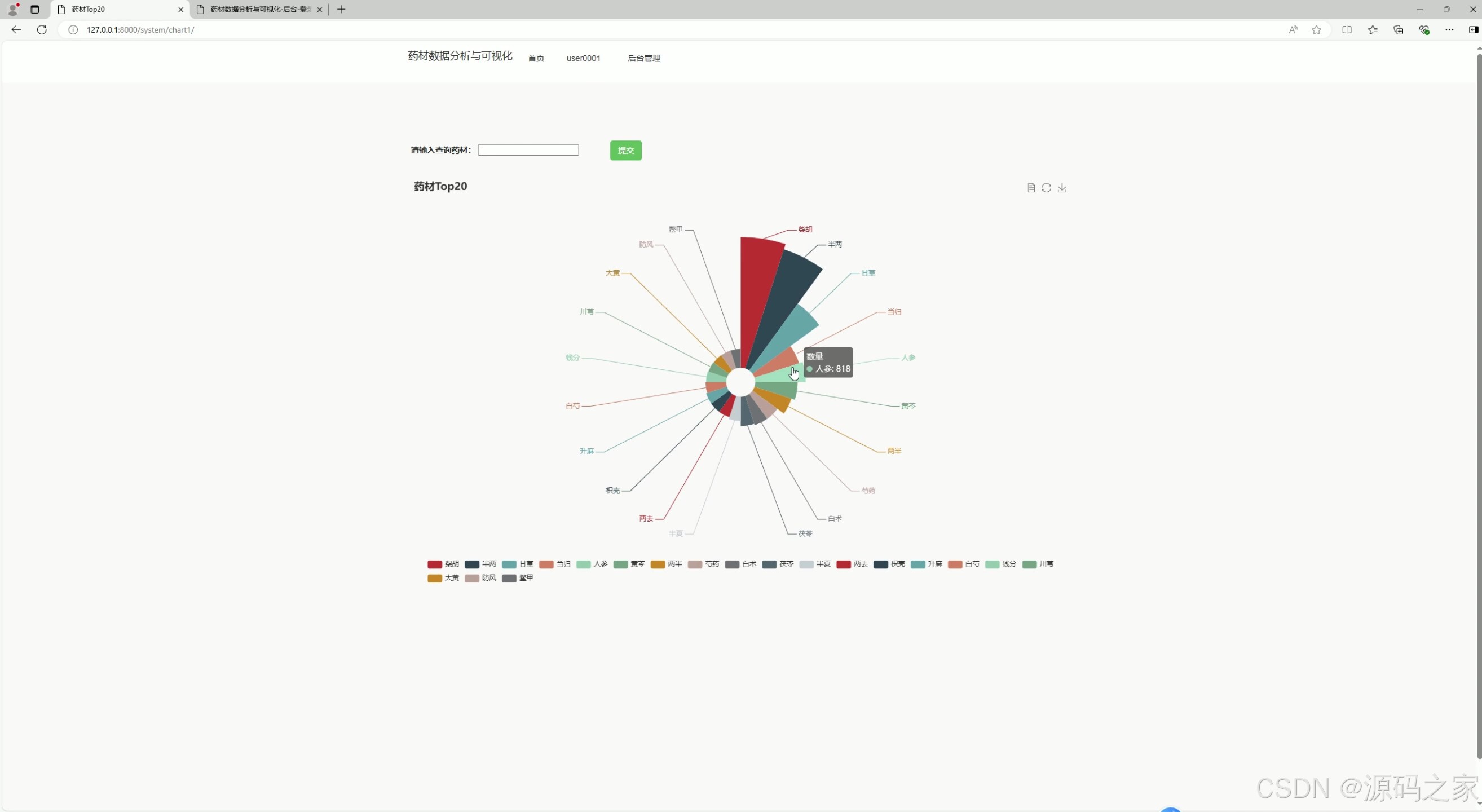
(4)药材成分分析
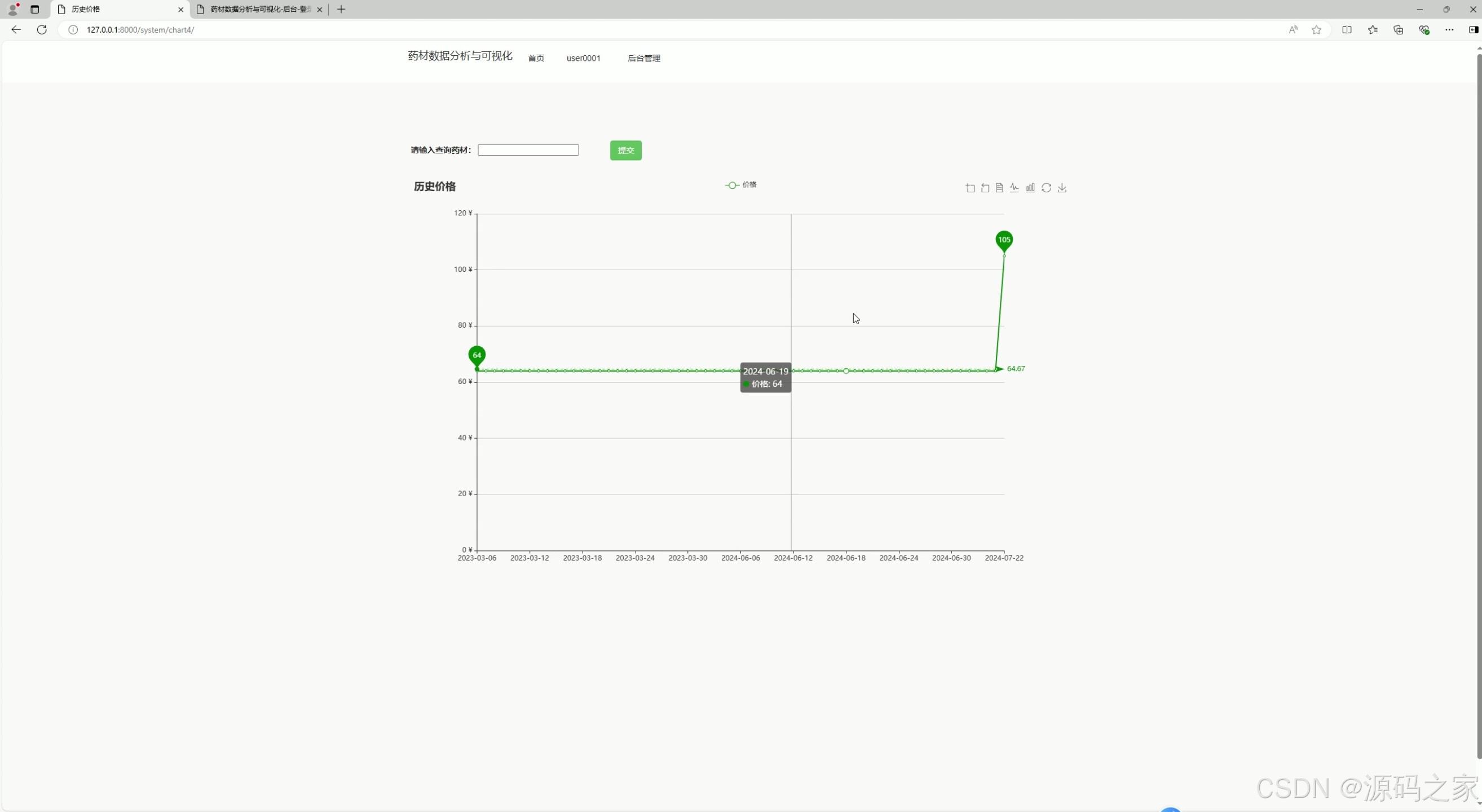
(5)历史价格分析
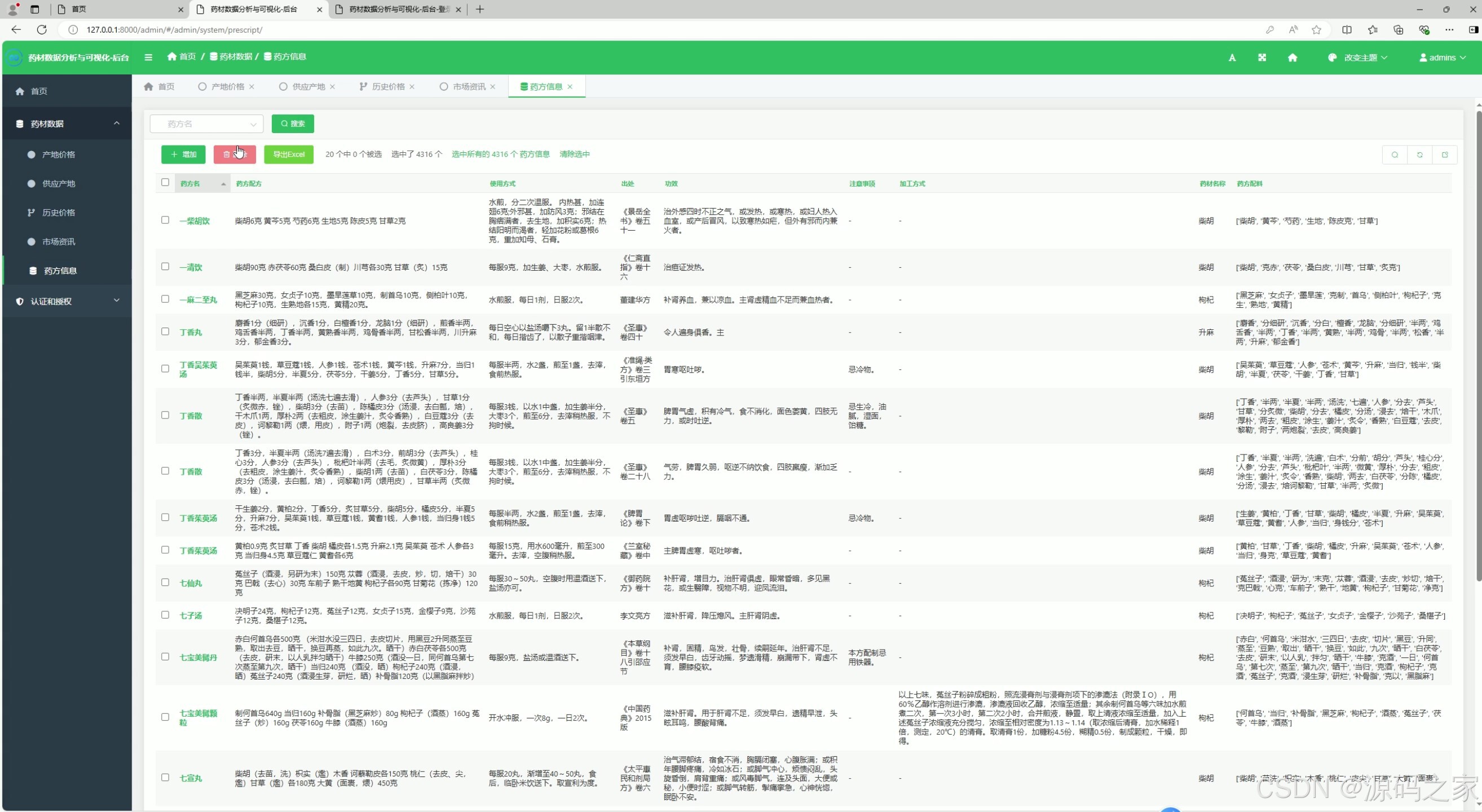
(6)后台数据管理
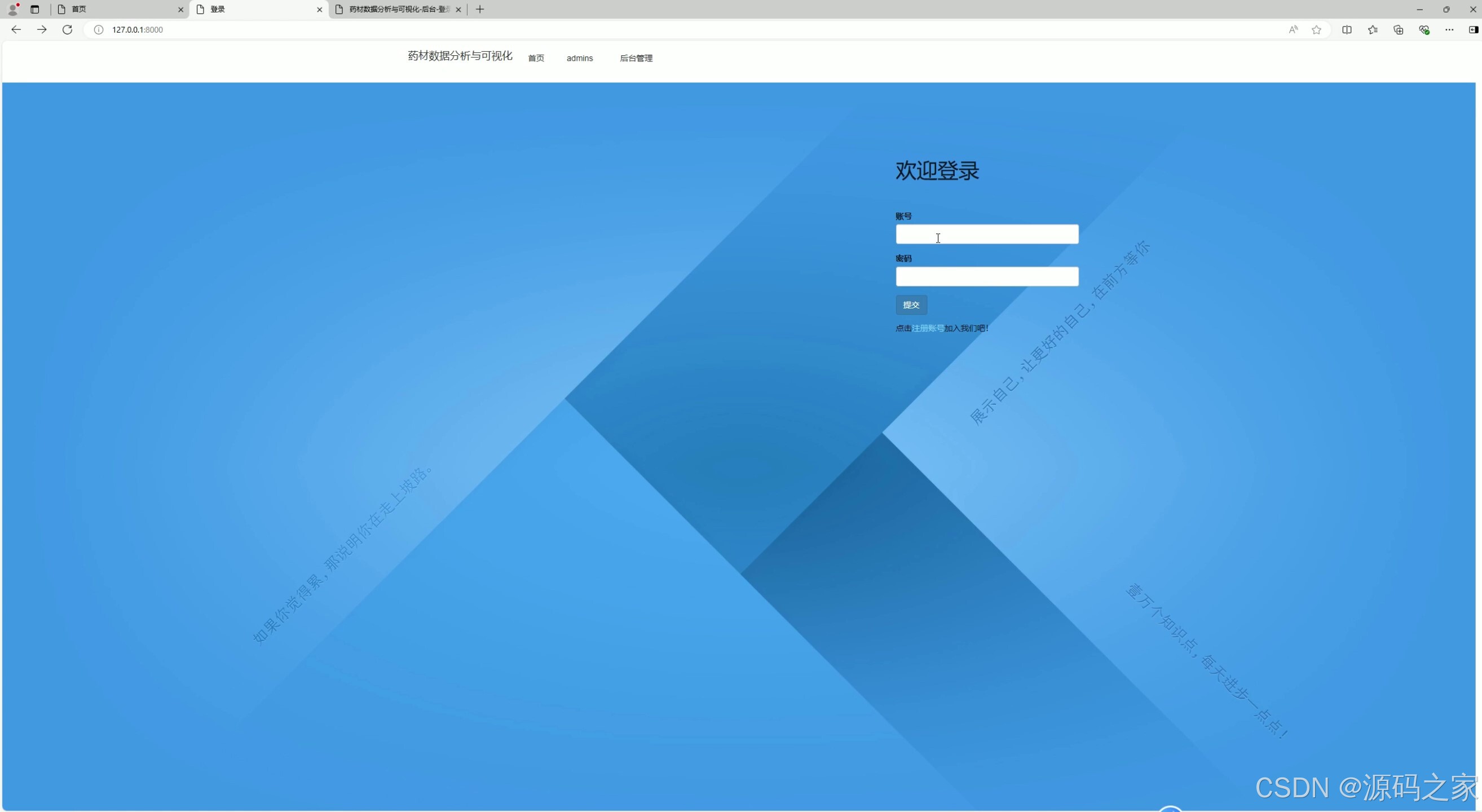
(7)注册登录
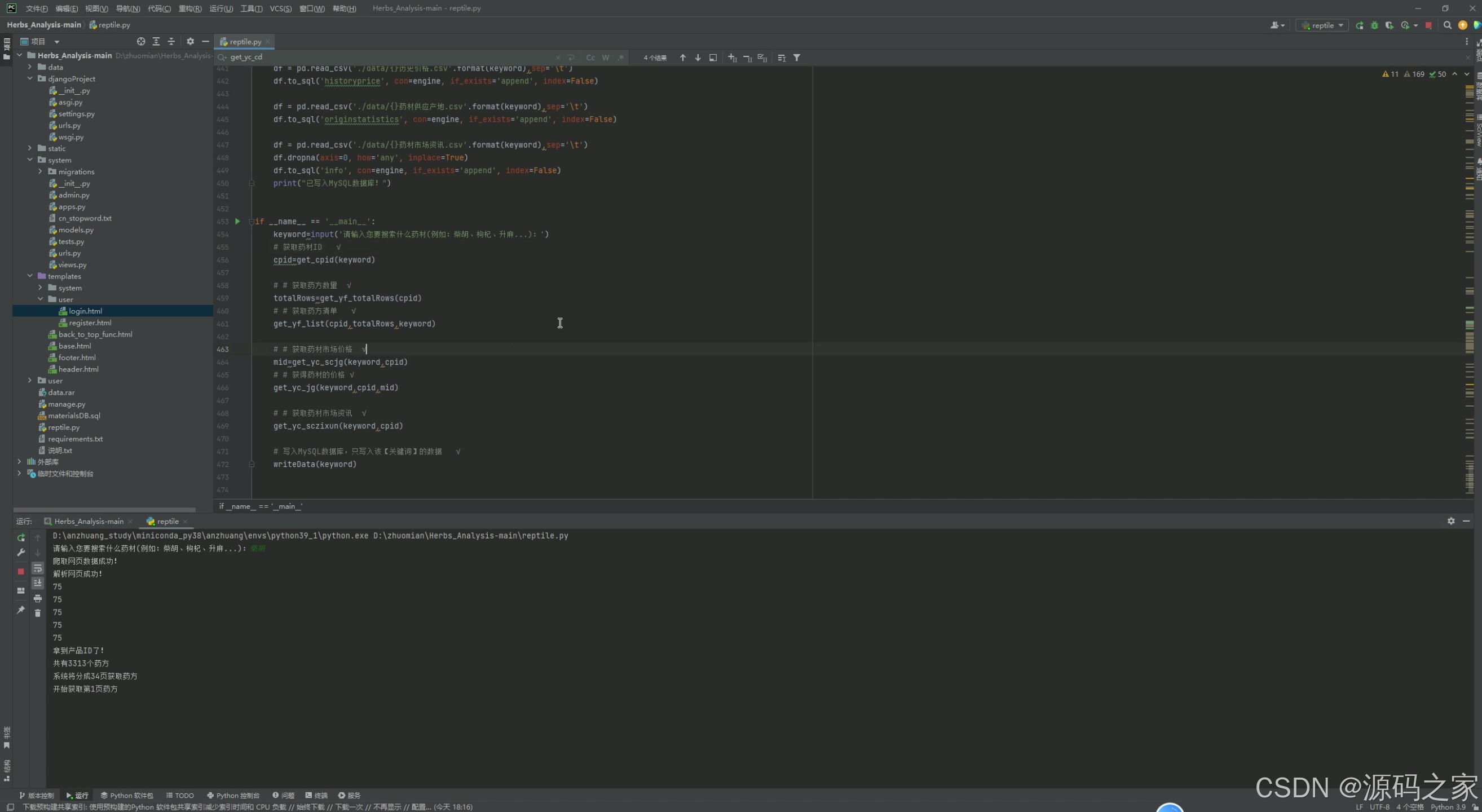
(8)数据采集
3、项目说明
功能模块介绍
(1)药材产地占比饼图分析
- 功能描述:
- 通过饼图展示不同产地的药材在市场中的占比情况。
- 帮助用户了解哪些地区是主要的药材产地,以及各产地药材的市场贡献比例。
- 技术实现:
- 使用 ECharts 的饼图组件进行可视化展示。
- 数据通过爬虫从中药材天地网等渠道采集,存储到 MySQL 数据库中。
- Django 后端负责从数据库中提取数据,并传递到前端页面。
(2)词云图分析
- 功能描述:
- 生成与药材相关的高频词汇的词云图。
- 帮助用户快速了解当前市场中热门的药材品种、产地、功效等关键词。
- 技术实现:
- 使用 Python 的
wordcloud库生成词云图。 - 数据来源可以是中药材天地网的新闻、论坛帖子、用户搜索记录等。
- Django 后端将生成的词云图传递到前端页面展示。
- 使用 Python 的
(3)药材价格柱状图分析
- 功能描述:
- 展示不同药材在当前市场中的价格分布情况。
- 通过柱状图直观地比较不同药材的价格高低,帮助用户了解市场行情。
- 技术实现:
- 使用 ECharts 的柱状图组件进行可视化展示。
- 数据通过爬虫从中药材天地网等渠道采集,存储到 MySQL 数据库中。
- Django 后端负责从数据库中提取数据,并传递到前端页面。
(4)药材成分分析
- 功能描述:
- 提供药材的主要成分分析,帮助用户了解药材的药用价值。
- 可能包括药材中不同化学成分的含量及其功效说明。
- 技术实现:
- 使用 HTML 和 CSS 构建成分分析页面。
- 数据可以来源于中药材天地网的药材介绍页面或其他专业资料。
- Django 后端负责从数据库中提取数据,并传递到前端页面。
(5)历史价格分析
- 功能描述:
- 展示药材在不同时间段内的历史价格走势。
- 帮助用户了解药材价格的波动趋势,预测未来价格变化。
- 技术实现:
- 使用 ECharts 的折线图组件进行可视化展示。
- 数据通过爬虫从中药材天地网等渠道采集,存储到 MySQL 数据库中。
- Django 后端负责从数据库中提取数据,并传递到前端页面。
(6)后台数据管理
- 功能描述:
- 提供管理员对药材数据的管理功能,包括数据录入、更新、删除等操作。
- 确保数据库中存储的药材数据的准确性和完整性。
- 技术实现:
- 使用 Django 框架构建后台管理系统。
- 数据存储在 MySQL 数据库中,通过 Django 后端进行数据操作。
- 提供用户认证和权限管理功能,确保只有管理员可以访问后台管理系统。
(7)注册登录
- 功能描述:
- 提供用户注册和登录功能。
- 用户可以通过用户名和密码登录系统,访问个人中心和其他功能模块。
- 技术实现:
- 使用 Django 的用户认证模块(如 Django-Auth)实现用户登录功能。
- 用户信息存储在 MySQL 数据库中,通过 Django 后端进行数据验证和管理。
(8)数据采集
- 功能描述:
- 使用 Python 的
requests库和爬虫技术从中药材天地网等渠道采集药材数据。 - 定期更新数据库中的药材信息,确保数据的时效性。
- 使用 Python 的
- 技术实现:
- 编写爬虫脚本,使用
requests库发送 HTTP 请求,获取网页内容。 - 使用正则表达式或 HTML 解析库(如 BeautifulSoup)提取网页中的药材数据。
- 将采集到的数据存储到 MySQL 数据库中,供其他模块使用。
- 编写爬虫脚本,使用
4、核心代码
import requests
from bs4 import BeautifulSoup
import re
import jieba
import pandas as pd
import time
import collections
import pymysql
from sqlalchemy import create_engine
#爬虫获取产品ID
def get_cpid (keyword):
url=f'http://www.zyctd.com/Search/Index?keyword={keyword}'
#获取网页数据
res=requests.get(url)
#编码
res.encoding = 'utf-8'
#解析网页数据
# print(res.text)
print("爬取网页数据成功!")
soup = BeautifulSoup(res.text, 'lxml')
print("解析网页成功!")
#通过正则表达式返回要的数据
# reg=re.compile('(?<=gongxiao).*?(?=.html)')
# print("正则表达式提取数据成功!")
# print(reg)
# 找到所有class为'cloud-data'的<a>标签
links = soup.find_all('a', class_='cloud-data')
for link in links:
href = link['href']
match = re.search(r'id=(\d+)', href)
if match:
cpid=match.group(1)
print(cpid) # 输出: 75
#对返回值进行数据提取。拿到产品ID
# cpid = reg.findall(str(soup.find('li','hover')))[0]
print("拿到产品ID了!")
# print(f"产品ID为:{cpid}")
return cpid
def get_yf_fun(cpid,ys=0):
# 药方: https://www.zyctd.com/data/zzjf.html?id=75
# 请求地址
url = 'https://www.zyctd.com/api/data-service/api/v1/product/getTcmPrescriptionPage'
# 设置tcmid=cpid,设置药方数量每次为100个,
j = {"init": 0, "tcmId": cpid, "nameAndIndications": '', "years": "0",
"pageRequest": {"pageNumber": ys+1, "pageSize": 100}}
# 得到链接的内容
res = requests.post(url, json=j, headers=headers)
# 编码
res.encoding = 'utf-8'
# 将返回值转化为元组,方便提取
return eval(res.text)
def get_yf_totalRows(cpid):
result=get_yf_fun(cpid,1)
if result['code']==0:
totalRows=result['data']['totalRows']
print(f"共有{totalRows}个药方")
return totalRows
else:
print('获取药方数量失败')
# 获取药方清单
def get_yf_list(cpid,totalRows,keyword):
datas = {
'uid': [],
'name': [],
'recipe': [],
'dosage': [],
'excerpt': [],
'indications': [],
'note': [],
'processing':[],
'tcmName': [],
'recipe_pz': [],
}
counts = {}
print(f"系统将分成{totalRows // 100 + 1}页获取药方")
# 去除一些语气词和没有意义的词
del_words = ['的', ' ', '克', '两', 'g', '千克', '钱', '斤','毫升','浸一宿','两钱','各克']
# 除100(每次取100个药方)向下取整然后+1,遍历所有药方清单
for row_i in range(totalRows // 100 + 1):
print(f'开始获取第{row_i+1}页药方')
result=get_yf_fun(cpid,row_i)
for res in result['data']['pageContent']:
if ('克' in res['recipe']) or ('g' in res['recipe']) or('钱' in res['recipe']) or('斤' in res['recipe'])or('两' in res['recipe']):
datas['uid'].append(res['id'])
datas['dosage'].append(res['dosage'])
datas['excerpt'].append(res['excerpt'])
datas['indications'].append(res['indications'])
datas['name'].append(res['name'])
datas['note'].append(res['note'])
datas['processing'].append(res['processing'])
datas['recipe'].append(res['recipe'])
datas['tcmName'].append(res['tcmName'])
# 对药方进行处理
# 去掉标点符号
all_quotes = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+", "", res['recipe'])
# 结巴分词自动切割,得到每个药方有什么药材
words = jieba.lcut(all_quotes)
words_final = []
# 如果词不在即将去除的内容中,就添加
for word in words:
if word not in del_words and len(word)>1:
words_final.append(word)
counts[word] = counts.get(word, 0) + 1
datas['recipe_pz'].append(words_final)
#把药方药材存到excel
pd_datas=pd.DataFrame(datas)
pd_datas.to_excel(f'./data/{keyword}药方.xlsx',index=None)
print(f"经过排除后,共获取到{len(datas['uid'])}个药方")
# # 获取药材市场价格
def get_yc_scjg(keyword,cpid):
url=f'https://www.zyctd.com/jh{cpid}.html'
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
# 解码
soup = BeautifulSoup(res.text, 'lxml')
# print(soup)
tbody_s = soup.find('table', class_='full center price').find('tbody').find_all('tr') # 寻找 zixun-item 类型的类
# tbody_s = soup.find('table', class_='tableBase').find('tbody').find_all('tr') # 寻找 zixun-item 类型的类 #原始代码
print("已经拿到了tbody_s")
print(tbody_s)
cd_s=[] #产地
jg_s=[] #价格
for tbody in tbody_s:
td_s=tbody.find_all('td')
cd=td_s[1].text
jg=td_s[2].text.replace('¥','')
cd_s.append(cd)
jg_s.append(float(jg))
# 保存 产地价格
with open("./data/{}产地价格.csv".format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\torigin\tprice\n")
for idx in range(len(cd_s)):
fp.write(keyword+'\t'+cd_s[idx]+"\t"+str(jg_s[idx])+"\n")
# 获取历史价格 (取 产地价格 最后一行数据作为“历史价格”)
print("获取历史价格开始--------------")
mid = jg_s[-1] # 使用-1作为索引来获取列表的最后一个元素
# print(jg_s)
# mid = jg_s
print(mid)
#原始代码: 通过正则表达式返回要的数据
# reg=re.compile('(?<=historyPriceMID = parseInt\(\").*?(?=\"\);)')
# mid = reg.findall(str(soup))[0]
#这个mid在获取历史价格的时候需要
return mid
from datetime import datetime
# 如果你只想要日期部分(格式化的字符串)
formatted_updateTime_date_only = datetime.now().strftime('%Y-%m-%d')
print(formatted_updateTime_date_only)
keyword=ycmc
updateTime=formatted_updateTime_date_only
price=mid
print(keyword,updateTime,price)
# 使用with语句打开文件,确保正确关闭,并且以追加模式打开
with open('./data/{}历史价格.csv'.format(keyword), 'a', encoding='utf-8', newline='') as fp:
# 写入一行数据,每个字段之间用制表符(\t)分隔
fp.write("{}\t{}\t{}\n".format(keyword, updateTime, price))
# with open('./data/{}历史价格.csv'.format(keyword),'w+',encoding='utf-8') as fp:
# fp.write("keyword\tupdateTime\tprice\n")
# # 写入数据行,注意每个字段之间用制表符(\t)分隔
# fp.write("{}\t{}\t{}\n".format(keyword, updateTime, price))
# for idx in range(len(x)):
# fp.write(keyword+'\t'+x[idx]+'\t'+str(y[idx])+'\n')
#
def get_yc_cd_url(cpid,ys):
url=f'https://www.zyctd.com/gqgy/{cpid}-0-p{ys}.html'
print(f'正在获取第{ys}页药材供应内容数据')
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
return res.text
#获得药材产地
def get_yc_cd(keyword,cpid):
# url : get_yc_cd_url函数 url=f'https://www.zyctd.com/gqgy/{cpid}-0-p{ys}.html' ys是页数
sl_s=[]
kcd_s=[]
cd_s=[]
#获取前10页药材供应内容。每页10个产品
for i in range(10):
res_data=get_yc_cd_url(cpid,i+1)
# 解码
soup = BeautifulSoup(res_data, 'lxml')
div_name_list = soup.find_all('div', class_='supply_list') # 寻找 supply_list 类型的类
for div_name in div_name_list:
#数量
sl=div_name.find_all('li')[1].find('span').text
#排除供应数量少于吨的
if '吨' not in sl:
continue
sl_s.append(sl.replace('吨',''))
#库存地
kcd=div_name.find_all('li')[2].find('span').text
kcd_s.append(kcd)
#产地
cd=div_name.find_all('li')[3].find('span').text
cd_s.append(cd)
#准备数据
cd_arr=[]
cd_cd_sl_arr=[]
for cd_s_i in range(len(cd_s)):
cd_sl=0
for cd_s_j in range(cd_s_i+1,len(cd_s)):
if cd_s[cd_s_i] not in cd_arr and cd_s[cd_s_i]==cd_s[cd_s_j]:
cd_sl+=int(sl_s[cd_s_j])
if cd_s[cd_s_i] not in cd_arr:
cd_arr.append(cd_s[cd_s_i])
cd_sl+=int(sl_s[cd_s_i])
cd_cd_sl_arr.append((cd_s[cd_s_i],cd_sl))
result_sort = sorted(cd_cd_sl_arr, key=lambda x: x[1], reverse=True) # 排序
result_sort = collections.OrderedDict(result_sort)
othervalue = 0
for i in range(5, len(cd_cd_sl_arr)):
othervalue += list(result_sort.values())[i]
values = []
labels = []
for i in range(5):
values.append(list(result_sort.values())[i])
labels.append(list(result_sort.keys())[i])
values.append(othervalue)
labels.append('其他产地')
print(keyword,labels,values)
with open('./data/{}药材供应产地.csv'.format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\torigin\tcount\n")
for idx in range(len(values)):
fp.write(keyword+'\t'+labels[idx]+'\t'+str(values[idx])+'\n')
def get_yc_sczixun_url(cpid,ys):
url = f'https://www.zyctd.com/zixun/202/pz{cpid}-{ys}.html'
print(f'正在获取第{ys}页数据')
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
return res.text
print(res.text)
# 市场资讯
def get_yc_sczixun(keyword,cpid):
# 爬取:get_yc_sczixun_url函数 https://www.zyctd.com/zixun/202/pz{cpid}-{ys}.html
# 例如: https://www.zyctd.com/zixun/202/pz75-1.html
zx_title=[]
zx_content=[]
#获取前3页药材市场资讯。每页10个资讯
for i in range(3):
# print("调用get_yc_sczixun_url开始")
res_data=get_yc_sczixun_url(cpid,i+1)
print("调用get_yc_sczixun_url结束")
# 解码
soup = BeautifulSoup(res_data, 'lxml')
print("解码完成")
# print(soup)
# 定位<div class="zixun-list">的内容(但这里我们通常只是用它来定位,不直接用它的内容)
# 遍历所有<div class="zixun-item-box">元素(因为它们是包含所需信息的容器)
item_boxes = soup.find_all('div', class_='zixun-item-box')
# 提取每个item-box的标题和内容
for item_box in item_boxes:
# 提取标题
title = item_box.find('div', class_='zixun-item-title').find('span').text.strip()
# 提取描述
content = item_box.find('div', class_='zixun-item-desc').find('div', class_='lay3').find('p').text.strip()
# 打印结果
print(f"标题: {title}")
print(f"描述: {content}\n")
zx_title.append(title)
zx_content.append(content)
# print(zx_title,zx_content)
print("已完成:获取前3页药材市场资讯")
print("---------------------------------------------------")
with open('./data/{}药材市场资讯.csv'.format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\ttitle\tcontent\n")
for i in range(len(zx_title)):
title = zx_title[i]
content = zx_content[i]
print(title,type(title))
print(content,type(content))
if not title:
continue
elif not content:
continue
elif len(content) < 50:
continue
elif "BORDER-BOTTOM" in content:
continue
elif "spanstyle" in content:
continue
else:
s = keyword+'\t'+title+'\t'+content+'\n'
if len(s) < 50:
continue
else:
fp.write(s)
print("---------------------------------------------------")
print("药材市场资讯已写入.csv文件!")
def writeData(keyword):
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/materialsDB?charset=utf8")
df = pd.read_excel('./data/{}药方.xlsx'.format(keyword))
df.to_sql('prescript', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}产地价格.csv'.format(keyword),sep='\t')
df.to_sql('originprice', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}历史价格.csv'.format(keyword),sep='\t')
df.to_sql('historyprice', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}药材供应产地.csv'.format(keyword),sep='\t')
df.to_sql('originstatistics', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}药材市场资讯.csv'.format(keyword),sep='\t')
df.dropna(axis=0, how='any', inplace=True)
df.to_sql('info', con=engine, if_exists='append', index=False)
print("已写入MySQL数据库!")
if __name__ == '__main__':
keyword=input('请输入您要搜索什么药材(例如:柴胡、枸杞、升麻...):')
# 获取药材ID √
cpid=get_cpid(keyword)
# # 获取药方数量 √
totalRows=get_yf_totalRows(cpid)
# # 获取药方清单 √
get_yf_list(cpid,totalRows,keyword)
# # 获取药材市场价格 √
mid=get_yc_scjg(keyword,cpid)
# # 获得药材的价格 √
get_yc_jg(keyword,cpid,mid)
# # 获取药材市场资讯 √
get_yc_sczixun(keyword,cpid)
# 写入MySQL数据库,只写入该【关键词】的数据 √
writeData(keyword)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 6231
6231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









