










博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈: Python语言、Flask框架、MySQL数据库、数据分析、Echarts可视化大屏、中国地图、HTML
中国地级市城镇化率数据可视化分析系统+大屏
2、项目界面
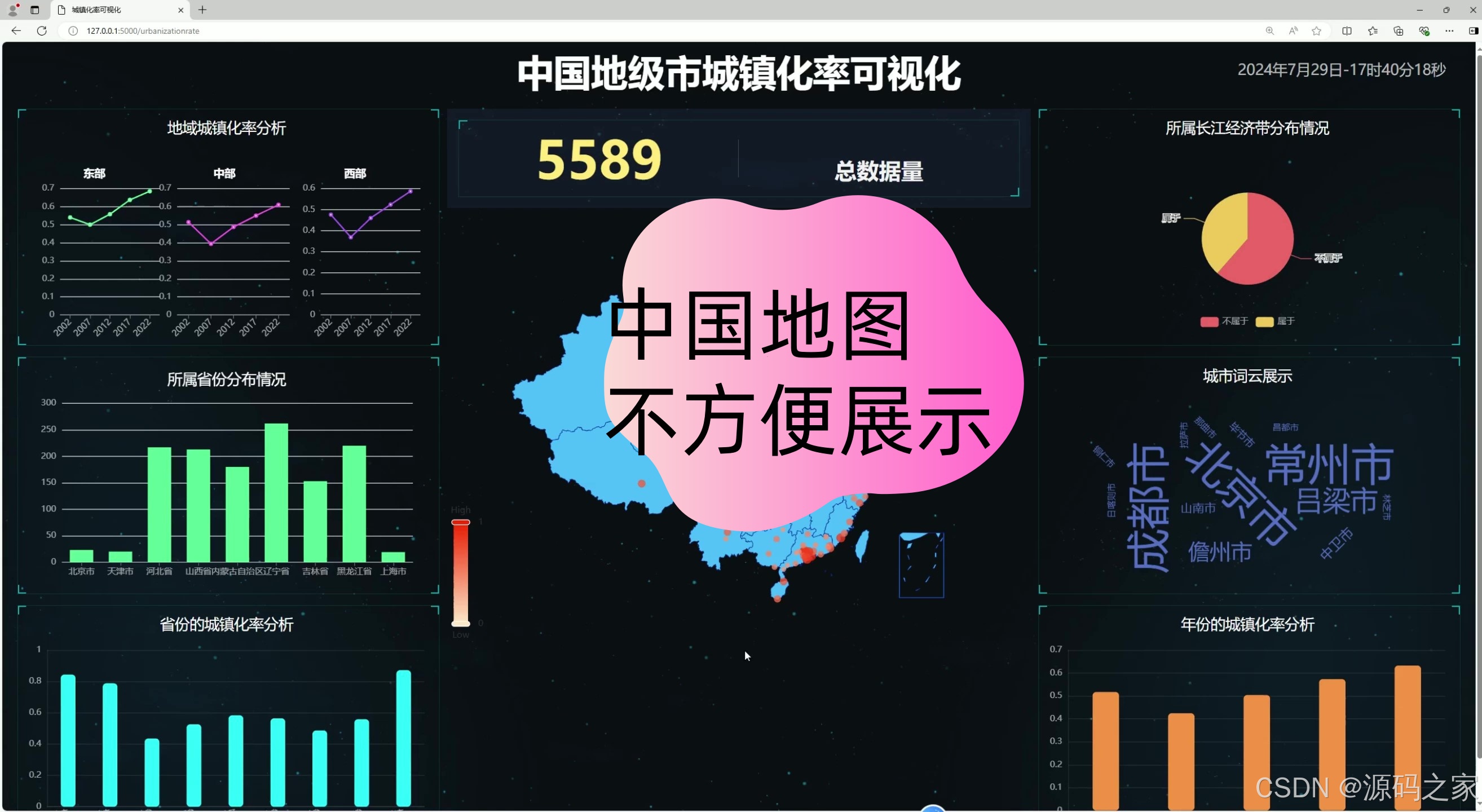
(1)数据可视化大屏
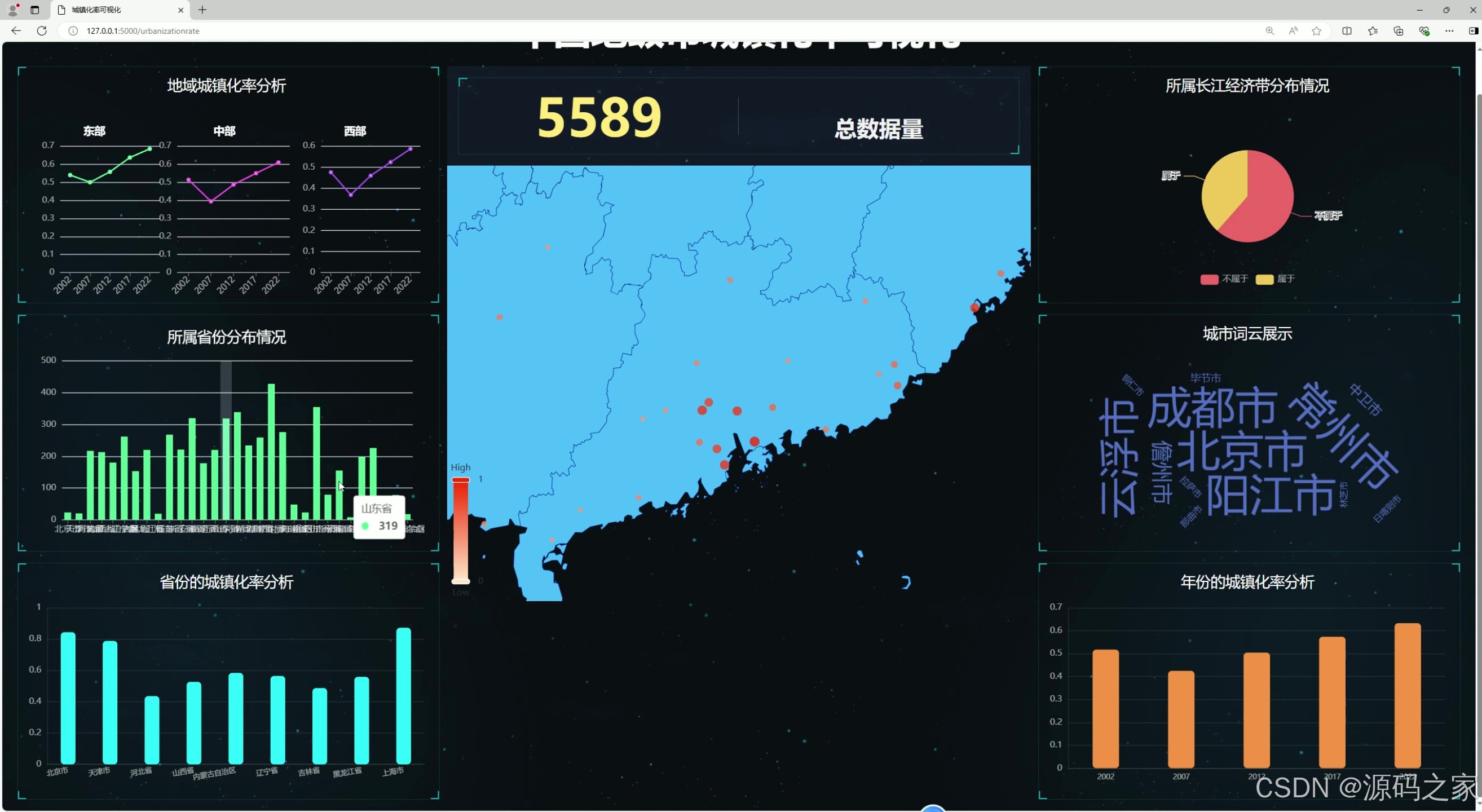
(2)放大各城市查看数据
3、项目说明
系统概述
该系统通过可视化的方式展示中国各地区的城镇化率数据,帮助用户更直观地了解不同地区城镇化率的变化和分布情况。系统使用了Python语言、Flask框架、MySQL数据库、数据分析技术、Echarts可视化大屏和中国地图等技术栈。
系统功能
-
数据展示:
- 总数据量:显示系统中包含的总数据量(5589条)。
- 地图展示:通过中国地图展示各地区的城镇化率数据,用户可以通过点击地图上的不同区域查看详细信息。
- 城市词云展示:展示城镇化率较高的城市名称,词云的大小和颜色代表城镇化率的高低。
-
数据分析:
- 地域城镇化率分析:通过折线图展示东部、中部和西部地区的城镇化率变化趋势。
- 所属省份分布情况:通过柱状图展示不同省份的城镇化率数据分布情况。
- 省份的城镇化率分析:通过柱状图展示各省份的城镇化率数据。
- 年份的城镇化率分析:通过柱状图展示不同年份的城镇化率变化情况。
-
经济带分布情况:
- 所属长江经济带分布情况:通过饼图展示长江经济带内不同地区的城镇化率分布情况。
技术栈
- 编程语言:Python
- Web框架:Flask
- 数据库:MySQL
- 数据分析:Python数据分析库(如Pandas、NumPy等)
- 可视化:Echarts
- 地图:中国地图
- 前端技术:HTML、CSS、JavaScript
系统界面
系统界面分为多个部分,包括地图展示、数据图表展示、词云展示等。界面设计简洁明了,用户可以通过点击不同的图表和地图区域查看详细信息。
系统优势
- 数据可视化:通过图表和地图直观展示城镇化率数据,便于用户理解和分析。
- 实时更新:系统可以实时更新数据,确保用户获取最新的城镇化率信息。
- 多维度分析:提供地域、省份、年份等多个维度的城镇化率分析,帮助用户全面了解城镇化率的变化和分布情况。
总结
该系统是一个功能强大的中国地级市城镇化率数据可视化分析系统,通过多种图表和地图展示城镇化率数据,帮助用户更直观地了解和分析城镇化率的变化和分布情况。系统使用了多种先进技术,确保了数据的准确性和实时性。
4、核心代码
from flask import Flask, render_template
from config import Config
from views.urbanizationrate import urbanizationrate_blueprint
app = Flask(__name__, template_folder="templates", static_folder="static")
# 从Config配置文件中加载配置信息
app.config.from_object(Config)
# 注册蓝图
app.register_blueprint(urbanizationrate_blueprint)
@app.route('/')
def index():
# 在这里渲染登录页面模板
return render_template('login.html')
if __name__ == '__main__':
# 启动flask服务
app.run(debug=True, port=5000)
from flask import Blueprint, render_template, redirect, url_for, jsonify
from models import DBJob
db = DBJob.DBMySql()
urbanizationrate_blueprint = Blueprint('urbanizationrate', __name__)
@urbanizationrate_blueprint.route('/')
def index():
return redirect(url_for('urbanizationrate.urbanizationrate'))
# 大屏展示
@urbanizationrate_blueprint.route('/urbanizationrate')
def urbanizationrate():
# 数据库总数据量
sql_count = "SELECT COUNT(zoning_code) FROM `urbanizationrate`;"
data_count = db.findAll(sql_count)[0][0]
# 所属地域——东部
sql_geography_East = '''SELECT `year`, ROUND(AVG(`urbanization_rate`), 3) AS avg_urbanization_rate
FROM `urbanizationrate`
WHERE `year` IN (2002, 2007, 2012, 2017, 2022)
AND `geography` = '东部'
GROUP BY `year`, `geography` ORDER BY `year`;'''
data_geography_East = db.findAll(sql_geography_East)
geography_East = {}
for item in data_geography_East:
geography_East[item[0]] = item[1]
# 所属地域——中部
sql_geography_Centralregion = '''SELECT `year`, ROUND(AVG(`urbanization_rate`), 3) AS avg_urbanization_rate
FROM `urbanizationrate`
WHERE `year` IN (2002, 2007, 2012, 2017, 2022)
AND `geography` = '中部'
GROUP BY `year`, `geography` ORDER BY `year`;'''
data_geography_Centralregion = db.findAll(sql_geography_Centralregion)
geography_Centralregion = {}
for item in data_geography_Centralregion:
geography_Centralregion[item[0]] = item[1]
# 所属地域——西部
sql_geography_West = '''SELECT `year`, ROUND(AVG(`urbanization_rate`), 3) AS avg_urbanization_rate
FROM `urbanizationrate`
WHERE `year` IN (2002, 2007, 2012, 2017, 2022)
AND `geography` = '西部'
GROUP BY `year`, `geography` ORDER BY `year`;'''
data_geography_West = db.findAll(sql_geography_West)
geography_West = {}
for item in data_geography_West:
geography_West[item[0]] = item[1]
# 所属省份
sql_provinces = "SELECT provinces,COUNT(provinces) AS count FROM `urbanizationrate` GROUP BY provinces;"
data_provinces = db.findAll(sql_provinces)
provinces = {}
for item in data_provinces:
provinces[item[0]] = item[1]
# 各省份的城镇化率 # WHERE
# # (`provinces`='新疆维吾尔自治区' OR `provinces`='湖北省' OR `provinces`='江苏省' OR `provinces`='广东省' OR `provinces`='黑龙江省')
sql_year_provinces = '''SELECT `provinces`, ROUND(AVG(`urbanization_rate`), 5) AS avg_urbanization_rate
FROM
`urbanizationrate`
GROUP BY
`provinces`;'''
data_year_provinces = db.findAll(sql_year_provinces)
year_provinces = {}
for item in data_year_provinces:
year_provinces[item[0]] = item[1]
# 所属长江经济带分布情况
sql_yangtze_river_EconomicBelt = '''SELECT
CASE `yangtze_river_EconomicBelt`
WHEN 0 THEN '不属于'
WHEN 1 THEN '属于'
END AS yangtze_river_EconomicBelt_status,
COUNT(`yangtze_river_EconomicBelt`) AS count
FROM
`urbanizationrate`
GROUP BY
`yangtze_river_EconomicBelt`;'''
data_yangtze_river_EconomicBelt = db.findAll(sql_yangtze_river_EconomicBelt)
yangtze_river_EconomicBelt = {}
for item in data_yangtze_river_EconomicBelt:
yangtze_river_EconomicBelt[item[0]] = item[1]
# 各年份的城镇化率
sql_year = '''SELECT `year`, ROUND(AVG(`urbanization_rate`), 5) AS avg_urbanization_rate
FROM `urbanizationrate`
WHERE `year` IN (2002, 2007, 2012, 2017, 2022)
GROUP BY `year`;'''
data_year = db.findAll(sql_year)
year = {}
for item in data_year:
year[item[0]] = item[1]
# 城市词云展示
sql_region = "SELECT `region`,COUNT(`region`) AS count FROM `urbanizationrate` GROUP BY `region`;"
data_region = db.findAll(sql_region)
region = {}
for item in data_region:
region[item[0]] = item[1]
return render_template("urbanizationrate.html", data_count=data_count, geography_East=geography_East,
geography_Centralregion=geography_Centralregion, geography_West=geography_West,
provinces=provinces,
year_provinces=year_provinces, yangtze_river_EconomicBelt=yangtze_river_EconomicBelt,
year=year, region=region)
# 中国地图
@urbanizationrate_blueprint.route('/china', methods=['GET'])
def china():
sql_china = '''SELECT region,ROUND(AVG(`urbanization_rate`), 3) AS avg_urbanization_rate
FROM `urbanizationrate` GROUP BY region;'''
data_china = db.fetchAllDict(sql_china)
data = [{'name': item['region'].replace("市", ""), 'value': item['avg_urbanization_rate']} for item in data_china]
return jsonify(data)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 6159
6159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









