






code:
Abstract
我们提出Zero-Painter,这是一种新颖的无训练框架,用于布局条件下的文本到图像合成,有助于从文本提示创建详细和受控的图像。我们的方法利用对象蒙版和个体描述,加上全局文本提示,生成高保真度的图像。Zero-Painter采用了两个阶段的过程,包括我们新颖的提示调整交叉注意(PACA)和区域分组交叉注意(ReGCA)块,确保生成的对象与文本提示和掩模形状精确对齐。我们广泛的实验表明,ZeroPainter在保留文本细节和坚持掩模形状方面超越了目前最先进的方法。
Introduction
基于布局条件的文本到图像模型,该模型利用了额外的输入,如分割蒙版[1 - 3,22]或边界框[22,28,57]以及文本。这种方法有助于创建具有精确属性的图像,使艺术家和设计师能够对视觉组件进行细粒度控制。
贡献:
我们引入Zero-Painter,这是一种新的无训练框架,用于布局条件下的文本到图像合成,能够生成具有特定形状和不同属性的对象。
我们提出了快速调整交叉注意(PACA)和区域分组交叉注意(ReGCA)块,它们显著提高了生成对象的形状保真度和特征保存。
通过定量和定性比较,全面的实验验证了Zero-Painter优于现有最先进的方法。
Related Work
Text-to-Image Generation
dall - e2[36]利用CLIP[32]通过扩散机制进行文本到图像的映射过程,并训练一个CLIP解码器。此外,Imagen[42]利用文本数据[33]上的大型预训练语言模型(如T5),实现了图像和文本之间的卓越对齐,并增强了样本保真度。最后,ediffi[2]采用基于专家的方法,在不同的时间步长范围内使用不同的专家模型处理生成。
Layout-to-Image Generation
基本模型通过连接输入图像和绘制掩模作为附加条件对UNet模型的潜在输入进行增强。附加通道的权重已初始化为零,并使用随机生成的inpainting蒙版对LAION[43]数据集进行微调。
Text-Guided Image Inpainting
Method
介绍了零画家的概述,我们的两阶段pipeline,包括单对象生成(SOG)和综合构图(CC)。我们深入研究了每个阶段,重点介绍了快速调整交叉注意(PACA)和区域分组交叉注意(ReGCA)层的设计,以改善形状对齐和特征保存。
Stable Diffusion


Zero-Painter
layout-conditional text-to-image的问题可以表述如下:给定一个layout作为一组二进制掩码Mi∈{0,1}H×W, i = 1,…, n,表示所需图像中单个物体的形状和位置,并附有分别描述每个物体的相应文本提示符τi,以及描述整个图像的全局提示符τglobal;目标是生成一个匹配τglobal的输出图像I∈RH×W,同时包含遵循布局{Mi} I =1的形状和位置的对象,并且提示符{τi}n I =1。
Zero-Painter引入了一个无需优化的两阶段管道,可以独立生成对象,然后将其无缝合成为单个图像。
一阶段 PACA生成独立图像Ii,每个包含平面背景上的单个对象,该背景遵循二进制掩码Mi的形状/位置并匹配描述τi(参见图)。使用平面背景有助于轻松识别和分割生成的对象,特别是当它们与原始掩码略有不同时。
二阶段获取生成图像并根据全局提示和单个掩码提示对组合起来![]() ,为了将生成物体连贯组合在一起,先用SAM将背景与物品分离,得到新的掩码
,为了将生成物体连贯组合在一起,先用SAM将背景与物品分离,得到新的掩码![]()
![]() 。如果生成的对象形状与给定的布局掩码Mi有轻微的不匹配,使用初始掩码Mi在Ii中分离前景对象可能会导致不希望的对象切割(见图)。然后我们利用我们的区域分组交叉注意(ReGCA)模块修改的稳定Inpainting[38]来无缝地结合生成的用
。如果生成的对象形状与给定的布局掩码Mi有轻微的不匹配,使用初始掩码Mi在Ii中分离前景对象可能会导致不希望的对象切割(见图)。然后我们利用我们的区域分组交叉注意(ReGCA)模块修改的稳定Inpainting[38]来无缝地结合生成的用![]() 在τglobal的文本指导下完成了绘制。
在τglobal的文本指导下完成了绘制。
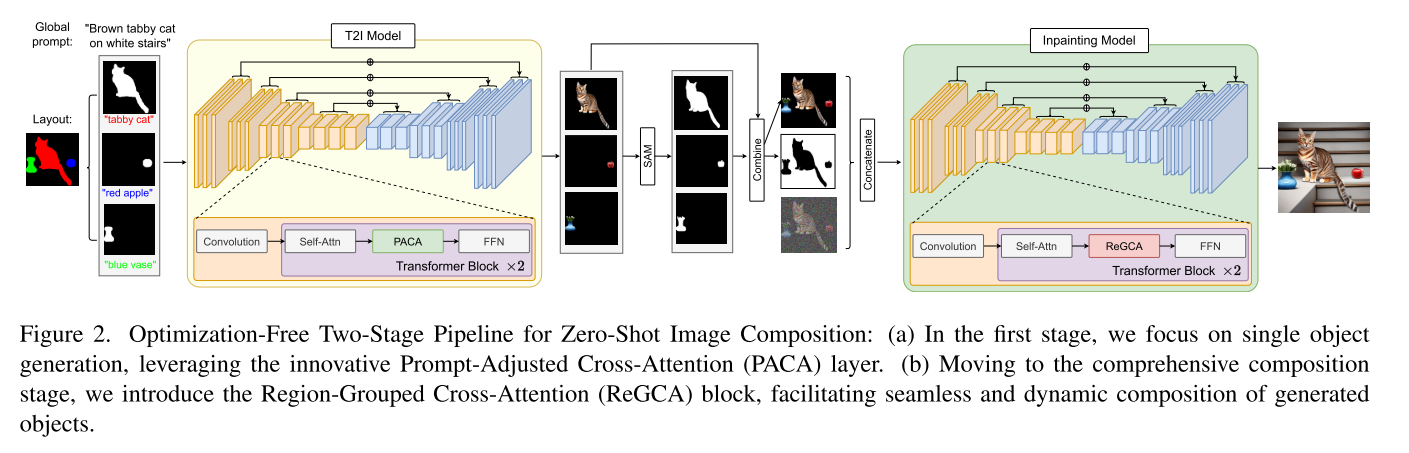
Single Object Generation (SOG)
从二进制掩码Mi和文本描述τi中生成图像,确保生成的对象的形状与Mi匹配,其描述与τi匹配。
我们使用预训练的稳定扩散(SD)[38]模型生成具有指定对(Mi,τi)的图像。
扩散过程中的高时间步长主要负责创建物体轮廓,而后面的步骤创建细节并细化物体。
目标形状是已知并由Mi描述的,因此我们从中间时间步T ' < T开始扩散后向过程,并通过使用掩模Mi获得的起始潜函数xT '来提供形状信息。
为了构造xT ',考虑两个因素:
(i)最终图像的背景应该是平坦的颜色;
(ii)前景目标应约束为Mi。
首先通过对常数黑色图像的隐编码施加噪声,得到时间步长T’对应的平坦背景的隐编码:
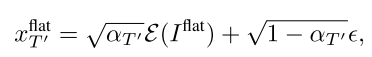
Iflat是常熟黑色图像,E是VAE编码器,噪声从高斯分布中采样。
We initialize the foreground region Mi of xT′ from a sampled Gaussian noise ϵ ∼ N(0, 1).
在Zero-Painter的对象合成阶段添加了一个细化子阶段,旨在纠正生成图像中的任何剩余错误。
单对象生成阶段的起始潜空间xT '定义为
![]()
Mi是掩码,噪声服从高斯分布。
在得到初始xT '后,应用DDIM后向过程。通过利用SD,增强了即时感知交叉注意(PACA)层,该层设计用于单个对象形状与Mi对齐并与提示τi
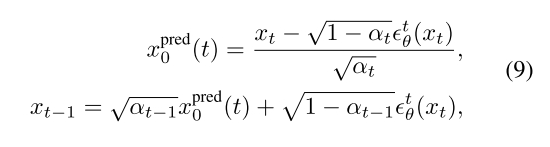
其中ϵt θ()为SD增强后的PACA层。
为了进一步保证目标不会延伸到掩蔽区域之外,将平面背景的噪声潜值xflat t与预测的xt在每个时间步长t = t′,…, 0:
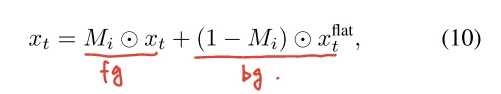
Prompt-Aware Cross-Attention (PACA)
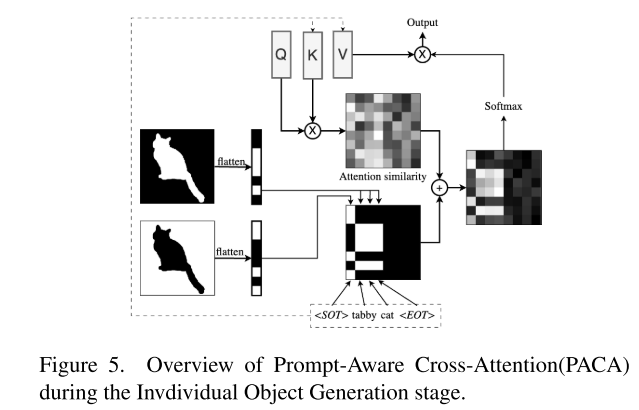
到在普通文本到图像的生成过程中,增加与SOT标记的像素相似度会导致输出像素成为通用背景像素(见图3和图4)。

对PACA层,采用了类似于eDiff-I[2]的机制,即通过修改交叉注意相似度矩阵s来鼓励屏蔽区域内对象的生成,我们使用除SOT外的所有提示令牌的键值来增加与屏蔽区域Mi对应的查询qj, j∈Mi的相似度值。因此,将所选交叉关注层的相似度矩阵S修改为:
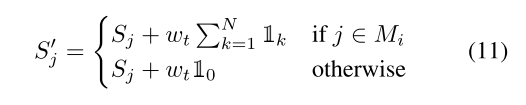
Sj为索引为j的像素对应的相似度矩阵列,1k =[0…1…0]为指示向量,N为EOT令牌索引,因此索引0为SOT令牌。受ediff-i的启发,选择![]()
其中σt为信噪比,w '为超参数
Comprehensive Composition (CC)
CC阶段的目的是将所有之前生成的对象组合成符合全局提示符τglobal描述的单个图像。
Object Segmentation
使用预训练的Segment-Anything-Model[20],将原始掩码的边界框作为输入,我们找到了输出和原始掩码的交集。
![]()
bbox(M_i)是跨越掩码Mi (in [x, y, w, h]格式)的最小边界框。

Inpainting
使用预训练的 Stable Inpainting model [38]。不是在掩蔽区域中创建一个新的对象,而是利用该模型在现有对象周围合成一个背景。

与3.3节类似,我们选择起始步骤T”< T,阻止模型生成新对象,并提示其专注于生成背景。此外,为了更好地保持预先存在对象的结构一致性,我们将已知区域内的初始潜在噪声xT”初始化为输入图像xknown的带噪潜在噪声xknown T”。
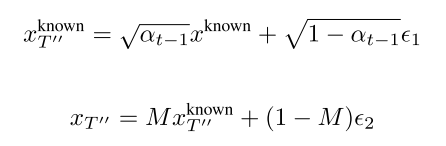
Region-Grouped Cross-Attention (ReGCA)
我们修改交叉注意层有两个目的:
首先,我们使用负面提示来禁止模型生成已知区域之外的现有对象。
其次,我们确保模型通过交叉注意值接收到关于现有对象的足够信息,
全局标题中缺少响应对象提示。为了实现这一点,我们将潜在向量的像素分成不同的组,根据它们所属的对象或背景(见图)。对于索引为0的对象,掩码为![]() ,对文本提示To选择查询的子集
,对文本提示To选择查询的子集![]() 。对于每一个组,我们计算它自己的一组键值对
。对于每一个组,我们计算它自己的一组键值对![]() 以及它们的无条件对应项
以及它们的无条件对应项 ![]() 是从对象提示符To的记号中计算出来的,而
是从对象提示符To的记号中计算出来的,而![]() 使用空字符串。
使用空字符串。
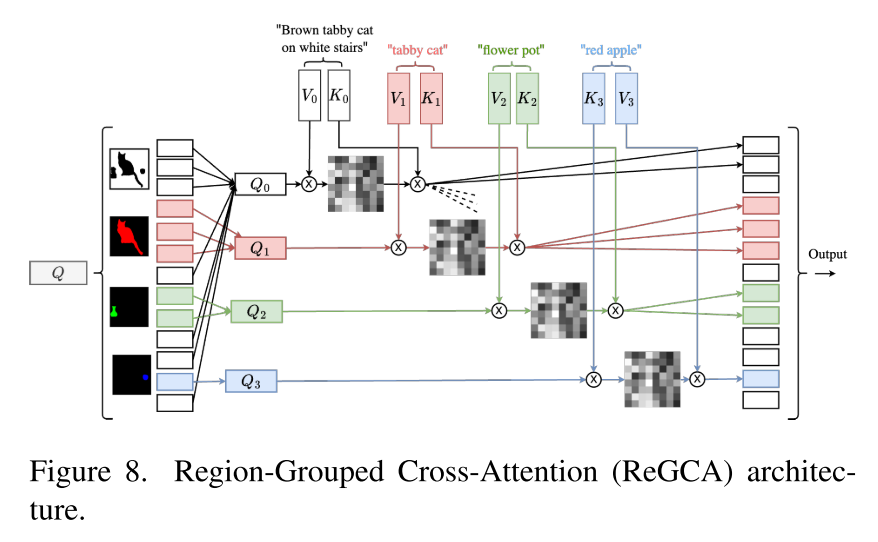
我们为属于背景![]() 的像素添加了一个额外的组。对于这个组,我们使用全局提示符τglobal来计算
的像素添加了一个额外的组。对于这个组,我们使用全局提示符τglobal来计算![]() 和
和![]() ,而对于
,而对于![]() ,我们从所有对象的逗号分隔的连接中构造一个新的提示符:
,我们从所有对象的逗号分隔的连接中构造一个新的提示符:![]() 。在无条件模型中使用非空提示作为否定提示,防止在背景区域中生成现有对象。
。在无条件模型中使用非空提示作为否定提示,防止在背景区域中生成现有对象。
在分别计算每个组的交叉注意输出后,通过将每个输出的像素放在原始输入的相应位置,将它们组合成一个单一的输出。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











