







ISCAS 2025
Abstract
为定制应用程序微调大型扩散模型需要大量的功率和时间,这对在移动设备上有效实施构成了重大挑战。在本文中,我们开发了一种新的训练加速器,专门用于扩散模型的低秩自适应(LoRA),旨在简化过程并降低计算复杂度。通过利用完全量化的LoRA微调训练方案,我们在保持高模型保真度的同时大幅降低了内存使用和功耗。所提出的加速器具有灵活的数据流,在LoRA过程中可以对不规则和可变张量形状进行高利用率。实验结果表明,与基线相比,训练速度提高了1.81倍,能源效率提高了5.5倍,对图像生成质量的影响最小。
INTRODUCTION
在传统的深度神经网络(DNN)训练中,32位单精度浮点数(FP32)一直是许多深度神经网络训练框架和硬件系统的默认值。虽然在微调期间只有5%的权重被更新,但冻结的权重仍然参与后续步骤的计算。因此,尽管扩散模型很强大,但它们的应用受到大量参数和计算复杂性的限制。例如,运行Stable Diffusion需要16GB的内存和gpu以及超过10GB的VRAM(Video Random Access Memory)显存,这对于大多数消费级pc来说是不切实际的,更不用说资源受限的边缘设备了。
为了解决上述挑战,我们提出了一种高效的自定义扩散模型硬件加速器。
贡献:
1)提出了一种基于低秩自适应(LoRA)[12]的高效微调方法,旨在加快概念融合过程。随后,提出了一种量化训练方法,大大减少了计算资源和内存需求,便于在训练过程中实现整数计算。
2) 设计了一个灵活的硬件加速器,具有可配置的数据流,支持重量固定(WS)和输出固定(OS)模式。这种灵活性允许在LoRA自定义扩散中有效地处理不规则和小张量计算。
3) 实验评估显示,与基线架构相比,训练速度提高了1.81倍,能效提高了5.5倍。我们的设计分别达到了1.64倍和1.83倍,与之前的工作相比,在能源效率和面积效率方面分别有所提高。
ALGORITHM
我们的方法由两个关键部分组成:利用低秩自适应(LoRA)的微调方案和完全量化方案。
Fine-Tuning Scheme Based on LoRA
如图1所示,在自定义扩散模型的微调过程中,在类别名称前面引入了一个新的修饰符V *。这种微调主要优化扩散模型的交叉注意层中的键和值投影矩阵,以及修饰符令牌。参与优化的层称为非冻结层,而不参与优化的层称为冻结层。因此,压缩概念融合过程的挑战转化为使用更少的资源优化这些层。
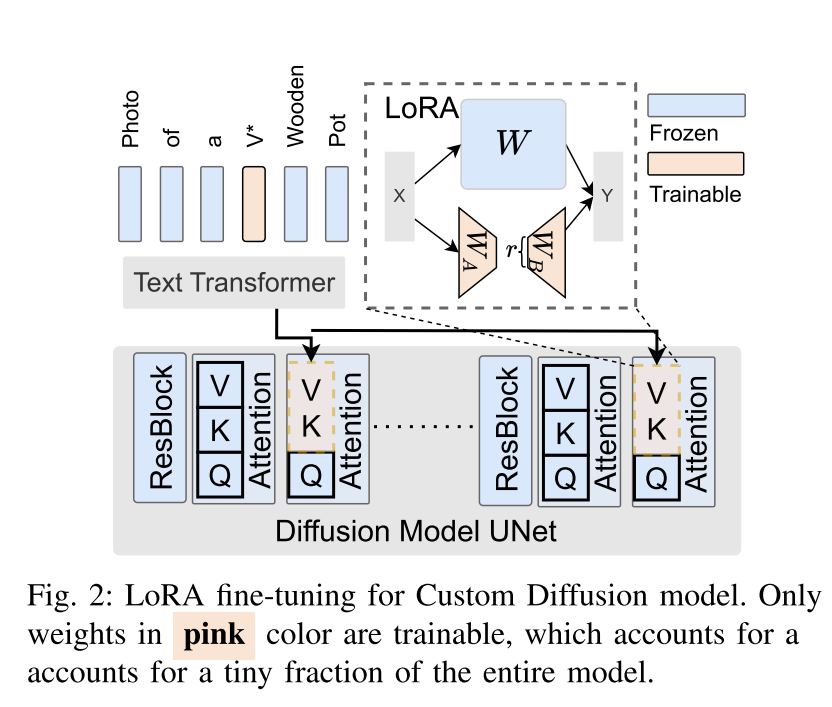
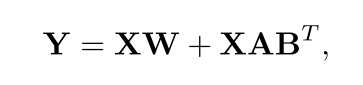
为了解决这个问题,我们已经用低秩适应(LoRA)实现了一些非冻结层的替代。如图2所示,这种调整将交叉注意层中的原始线性变换重新定义为方程(1),![]() r≪min(d1, d2)。相应地,将大尺寸权重矩阵W的更新转换为两个低秩矩阵A和b的更新,这样一来,只有5%的总参数主动参与更新,从而大大节省了计算资源和内存成本。此外,考虑到扩散模型框架内对LoRA的固有支持,用LoRA替换部分模型不会导致准确性的重大损失。
r≪min(d1, d2)。相应地,将大尺寸权重矩阵W的更新转换为两个低秩矩阵A和b的更新,这样一来,只有5%的总参数主动参与更新,从而大大节省了计算资源和内存成本。此外,考虑到扩散模型框架内对LoRA的固有支持,用LoRA替换部分模型不会导致准确性的重大损失。
Fully Quantized Training Scheme
尽管对扩散模型应用自定义LoRA微调后,训练参数显著减少,但总体MAC操作量和权重和中间数据的内存消耗仍然相对较高。训练过程的总体计算图如图图3所示,从中可以看出,冻结权仍然参与了反向传播的计算。
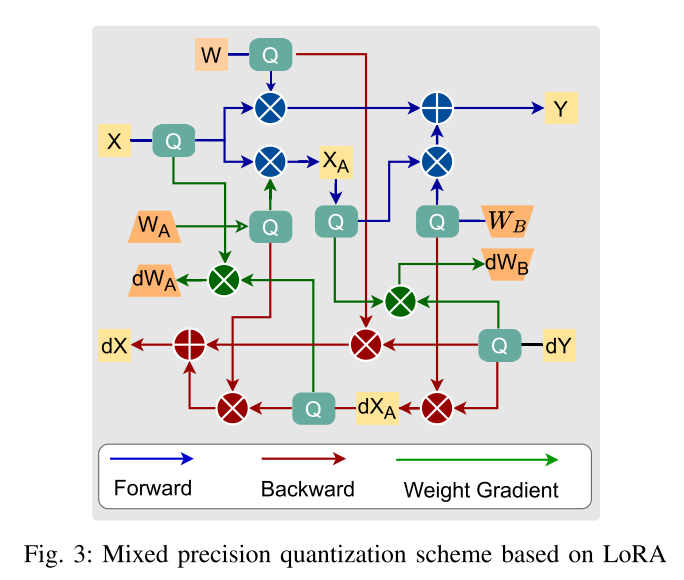
为了进一步降低复杂性,引入了一种完全量化的训练方法,其中权重、激活和梯度都量化为8位整数格式(INT8)。为了保证训练的收敛性,权重采用了逐张量量化方案,激活和梯度采用了逐通道/逐列量化方案。量化过程如方程所示。
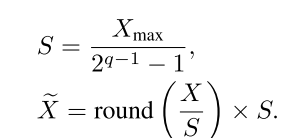
PROPOSED FLEXIBLE HARDWARE DESIGN
Hardware Architecture
系统架构如图图4a所示,由控制模块、基于N ×N收缩阵列的计算模块和SRAM存储器组成。控制模块负责接收指令和配置,同时协调其他模块的操作。计算模块可配置为使用WS和OS数据流执行通用矩阵乘法(GEMM)。SRAM存储器存储从片外DRAM获取的权重、输入和输出张量。
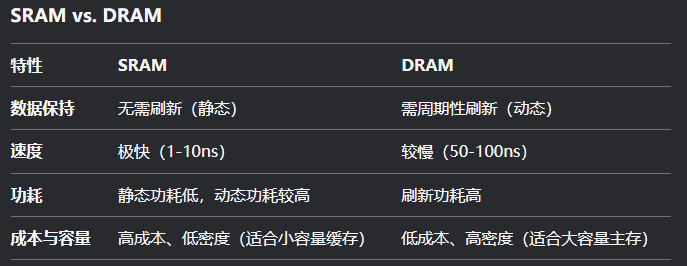
SRAM(Static Random-Access Memory)是静态随机存取存储器,一种基于触发器电路设计的半导体存储器
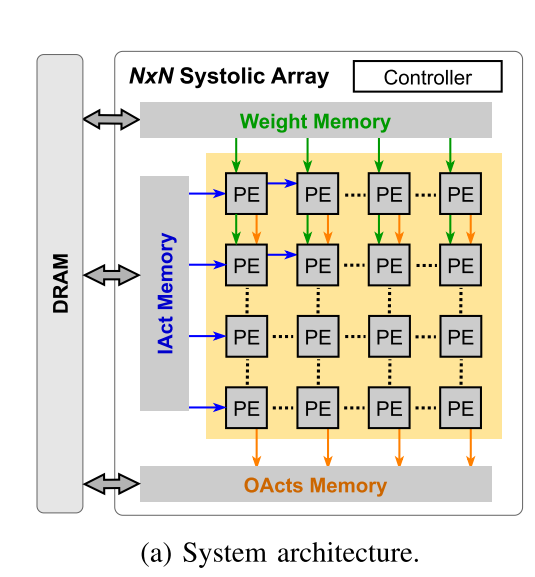
在我们的实现中,收缩数组的大小为64×64。内存容量为512KB,分别用于输入和权重内存,1MB用于输出内存。为了减少由外部存储器访问引起的延迟,采用了双缓冲区技术。
Dataflow
在自定义扩散模型中,交叉注意层将文本提示嵌入与图像特征结合起来。然而,文本嵌入的序列长度较小(< 77),而图像的序列长度较大(4096),这导致了计算特征的显著差异。LoRA引入的低秩权重加剧了这个问题。如果处理不当,将严重影响硬件计算效率。因此,我们的加速器被设计成在统一的PE阵列上支持WS和OS数据流。不同的数据流模式如图图4b和4c所示。
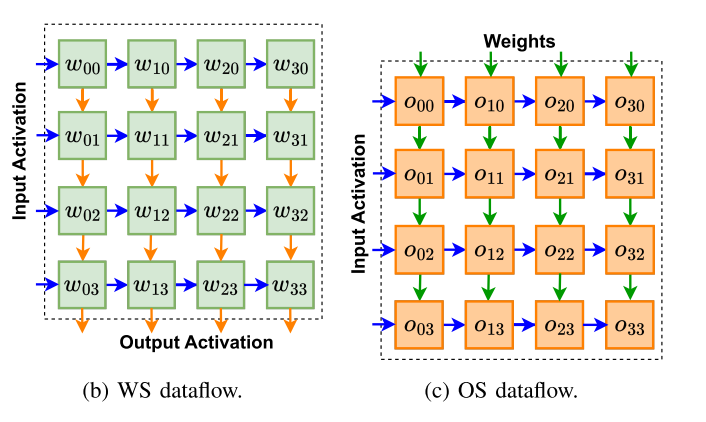
WS : 使用WS数据流,gem以内部产品的方式执行。权向量首先被加载到PE数组中,并存储在每个PE的本地寄存器中以供重用。然后输入向量从左到右流进PE行,并以收缩方式传播。从底部PE数组行收集输出并对齐以形成输出向量。
OS : 操作系统数据流以外部产品的方式执行gemm。获取一对输入和权重向量来生成N × N个输出部分和。输入向量和权重向量分别在PE阵列上水平和垂直传播。部分金额暂时累积在pe中,一旦累积完成就流出。然后将这些输出存储在输出内存中。
WS和OS数据流采用不同的数据传播和部分累加方案,这导致PE利用率和内存流量的变化。通过为每一层选择最优的数据流,可以显著提高整体性能。
EXPERIMENTS
Evaluation Methodology
1) Algorithm :根据自定义扩散中的实验设计,我们在多个目标数据集上进行了实验,这些数据集跨越了各种类别,包括场景、宠物和对象。
2) Hardware: 我们在System Verilog RTL中实现了加速器。RTL设计采用Synopsys design Compiler和45nm FreePDK技术[13]进行合成,得到了RTL的面积和功耗。我们使用CACTI 7.0[14]来模拟SRAM缓冲区的能量和面积消耗。基于SCALE-Sim[15]开发了一个周期级模拟器,以确定最佳的数据流配置。
Qualitative evaluation
在图中,我们比较了原始Custom Diffusion和量化压缩模型的图像生成效果。我们使用一组提示来测试每个微调模型,以评估目标概念与新场景的整合以及目标概念属性(例如颜色,形状)的修改。图的第2列和第3列显示了来自自定义扩散和我们的方法的样本世代。我们的方法演示了类似的文本到图像对齐,捕获目标对象的视觉细节,并有效地融合概念,同时保持较低的模型存储需求。

Hardware Performance
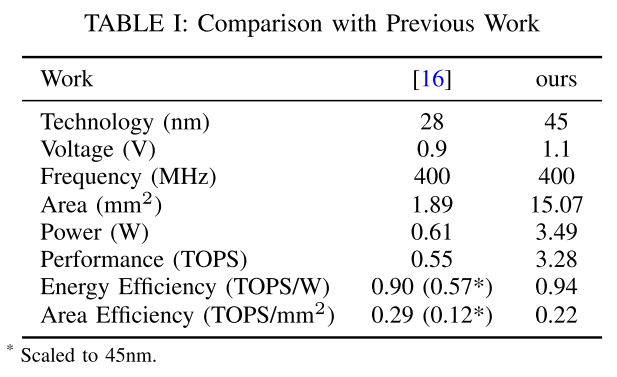
表1将提议的加速器与先前设计的扩散模型进行了比较。提出的设计实现了3.28 TOPS(每秒Tera次操作)的峰值性能,同时消耗3.49W的功率。该设计占地面积15.07mm2,换算成面积效率为0.22 TOPS/mm2。它在计算性能和功耗之间取得了很好的平衡,与[16]相比,它的能效和面积效率分别为1.64倍和1.83倍。
图显示了不同配置之间的性能比较:Full Model、LoRA OS、LoRA WS和LoRA Hybrid。评估两个关键指标:延迟和能量延迟积(EDP)。
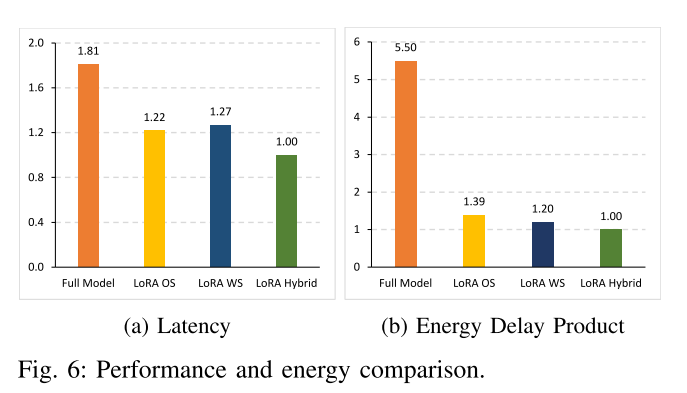
如图图6a所示,我们的LoRA Hybrid配置在完整模型基线上提供了1.81倍的加速。与使用固定数据流的LoRA OS和LoRA WS相比,混合数据流的速度分别提高了1.22倍和1.27倍。图6b显示,与全模型、LoRA OS和LoRA WS相比,LoRA Hybrid设计的EDP分别降低了5.5倍、1.39倍和1.20倍。这些结果表明了我们的设计在性能和能源效率方面的优越性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











