







基于Spring Boot爬虫、网页开发和数据抓取技术的在线新闻聚合平台是一个集成了新闻抓取、处理、展示和管理功能的综合性系统。以下是对该系统设计与实现的详细介绍:
一、系统概述
该系统旨在通过爬虫技术从各大新闻网站上抓取新闻数据,经过处理和整合后,在平台上进行展示和管理。用户可以方便地浏览和搜索感兴趣的新闻,管理员则可以对新闻数据进行管理和维护。
二、技术栈
后端:Spring Boot框架,用于快速搭建和简化配置Web应用,提高开发效率和降低维护成本。同时,Spring Boot支持RESTful API的开发,实现数据的实时更新和传输。
前端:Vue框架,提供了响应式的组件化开发方式和简洁的语法结构,能够提供良好的用户体验和友好的界面设计。
数据库:MySQL数据库,作为优秀的关系型数据库管理系统,具有稳定、高效、安全等特点,能够满足系统对数据管理和存储的需求。
爬虫框架:如WebMagic等Java爬虫框架,用于实现新闻的抓取和处理。
三、系统架构设计
系统采用前后端分离的设计模式,前端使用Vue框架构建用户界面,后端则基于Spring Boot框架提供RESTful API接口,实现业务逻辑的处理和数据的交互。同时,系统还集成了数据库和爬虫框架,用于存储和管理新闻数据以及实现新闻的抓取和处理。
四、功能模块
1.
新闻抓取模块:
2.
利用爬虫框架从各大新闻网站上抓取新闻数据,包括新闻标题、内容、发布时间、来源等。
对抓取到的新闻数据进行清洗和处理,去除重复和无效数据,确保数据的准确性和完整性。
3.
新闻处理模块:
4.
对抓取到的新闻数据进行分类和标签化处理,方便用户进行搜索和筛选。
对新闻内容进行分词和索引处理,提高搜索效率和准确性。
5.
新闻展示模块:
6.
在前端页面上展示新闻列表和详细内容,支持分页和搜索功能。
提供个性化的新闻推荐服务,根据用户的浏览历史和兴趣偏好推荐相关新闻。
7.
管理模块:
8.
提供管理员登录和权限管理功能,确保系统的安全性。
管理员可以对新闻数据进行审核、删除和修改等操作,确保新闻数据的准确性和合法性。
提供新闻来源管理和爬虫配置功能,方便管理员对爬虫进行管理和维护。
效果图

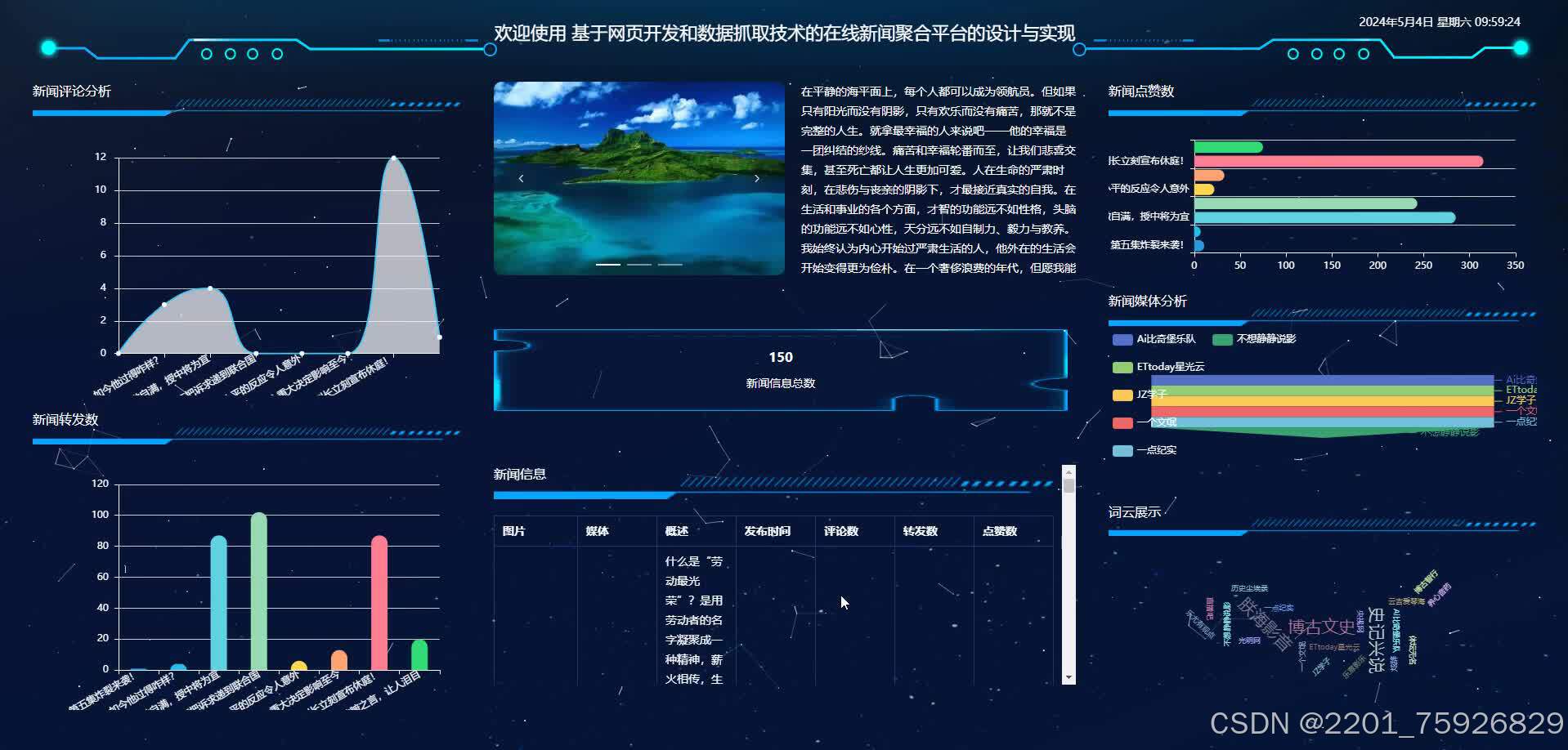
五、实现步骤
1.环境搭建:安装和配置Spring Boot、Vue、MySQL和爬虫框架等开发环境。
2.后端开发:基于Spring Boot框架搭建后端服务,实现新闻数据的抓取、处理和存储功能。同时,提供RESTful API接口供前端调用。
3.前端开发:使用Vue框架构建前端页面,实现新闻的展示、搜索和管理功能。同时,与后端服务进行交互,实现数据的实时更新和传输。
4.数据库设计:根据系统需求设计数据库表结构,包括新闻表、用户表、来源表等。同时,对数据库进行优化和性能调优。
5.爬虫实现:利用爬虫框架实现新闻的抓取和处理功能。根据各大新闻网站的页面结构和数据格式编写爬虫规则,并进行测试和调试。
6.系统集成:将前端页面、后端服务和数据库进行集成和测试,确保系统的正常运行和功能的完整性。
7.部署上线:将系统部署到服务器上,并进行性能监控和维护工作。同时,根据用户需求进行功能迭代和优化。
六、系统特点
1.高效性:利用爬虫技术实现新闻的自动化抓取和处理,提高了新闻更新的速度和准确性。
2.个性化:根据用户的浏览历史和兴趣偏好推荐相关新闻,提供了个性化的新闻阅读体验。
3.可扩展性:系统采用模块化设计,可以方便地添加新的功能模块和扩展现有功能。同时,Spring Boot的生态系统也提供了丰富的第三方库和插件,进一步增强了系统的可扩展性。
4.安全性:系统实现了管理员登录和权限管理功能,对新闻数据进行审核和过滤,确保了新闻数据的合法性和安全性。
七、应用场景
该系统适用于新闻聚合网站、新闻资讯平台等场景,可以为用户提供丰富的新闻内容和个性化的阅读体验。同时,该系统也可以作为新闻数据分析和挖掘的基础平台,为新闻行业提供数据支持和决策依据。
综上所述,基于Spring Boot爬虫、网页开发和数据抓取技术的在线新闻聚合平台是一个功能完善、高效、可扩展且安全的解决方案。它能够帮助新闻聚合网站和资讯平台实现新闻的自动化抓取、处理和展示功能,为用户提供个性化的新闻阅读体验。

















 6094
6094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









