






一. Redis概念
1. Nosql
1.1. 什么是Nosql
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,它泛指非关系型的数据库。随着互联网2003年之后web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的交友类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
关系数据库:以关系(由行和列组成的二维表)模型建模的数据库
简单理解:有二维表的数据库
RDBMS【关系型数据库管理系统】: mysql,oracle,SQLserver,db2
非关系型数据库:Nosql
注意:Nosql的出现不是用来代替关系型数据库的
而是用于特定场景中
关系型数据库在处理大数据方便是有瓶颈的 ,不适用于高并发量的访问
很多时候都是关系型数据库和Nosql联合使用
1.2. Nosql分类
NoSQL Databases List by Hosting Data - Updated 2023
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群 |
2. Redis
2.1. 什么是Redis
Redis 是一个高性能的 开源的、C语言写的Nosql(非关系型数据库),数据保存可以存储在内存中或者磁盘中。Redis 是以key-value形式存储,和传统的关系型数据库不一样。不一定遵循传统数据库的一些基本要求,比如说,不遵循sql标准,事务四大特性,表结构等等。redis严格上不是一种数据库,应该是一种【数据结构化存储】方法的集合。
2.2. Redis的特点
-
数据保存在内存,存取速度快,并发能力强
-
它支持存储数据类型比较多,包括string(字符串)、list(链表)、set(集合)、 zset(sorted set - 有序集合)和hash(哈希类型)
-
redis的出现,很大程度补偿了memcached这类key/value存储的不足,支持持久化。在部分场合【数据量大,并发量高】可以对关系数据库(如MySQL)起到很好的补充作用
-
支持Java,C/C++,C#,PHP,JavaScript等客户端,使用很方便
-
Redis支持集群(主从同步)。数据可以主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器
2.3. Redis和Mysql的比较
| mysql | redis | |
|---|---|---|
| 类型 | 关系型 | 非关系型 |
| 存储位置 | 磁盘 | 磁盘和内存 |
| 存储过期 | 不支持 | 支持 |
| 读写性能 | 低 | 非常高 |
2.4. Redis与Memcached比较
Memcached拥有的优势redis都拥有 1. redis支持持久化 2. redis支持更多的数据类型:string,list,set,zset,hash等
2.5. Redis的使用场景
-
缓存
经常查询数据,放到读速度很快的空间(内存),以便下次访问减少时间。减轻数据库压力,减少访问时间。而redis就是存放在内存中的
-
计数器
网站通常需要统计注册用户数,网站总浏览次数等等 ,新浪微博转发数、点赞数
-
实时防攻击系统
防止暴力破解,如使用工具不间断尝试各种密码进行登录。解决方案使用Redis记录某ip一秒访问到达10次以后自动锁定IP,30分钟后解锁
-
设定有效期的应用
设定一个数据,到一定的时间失效。验证码,登录过期, 自动解锁,购物券,红包
-
自动去重应用
使用 Redis 的 set 数据结构自动排重
-
队列
秒杀:可以把名额放到内存队列(redis),内存就能处理高并发访问
-
消息订阅和排行榜
二. Redis的安装
1. 下载和安装
1.1. 下载Redis
英文网站:Download | Redis ;
中文网站:CRUG网站
1.2. Redis单机版安装
(1)安装依赖C语言依赖
yum install -y gcc-c++ automake autoconf libtool make tcl
等待安装即可
(2)上传并解压
使用xftp将redis的压缩包上传到/opt/software中,然后解压文件到/opt/module
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/module/
(3)编译并安装
进入到/opt/module/redis-6.2.7中,使用make命令编译安装
make
等待编译完成
(4)复制一份配置文件
这里复制一份配置文件的目的是为了防止后期修改配置文件出错而导致redis无法运行,方便还原配置。
创建一个文件夹
mkdir conf_backups
复制一份配置文件作为备份
cp ./redis.conf ./conf_backups
(5)开始修改配置文件的原件,不是备份文件!!!
开启守护进程
修改redis.conf
vim redis.conf
把daemonize的值由no修改为yes

关闭保护模式,运行外部访问
注释掉下面的本地IP

将protected-mode yes 改成 no

保存修改
1.3. Redis目录介绍
redis.window.conf #【重要】reids配置文件 redis-benchmark.exe #reids压测工具 redis-check-aof.exe #aof文件校验、修复功能 redis-check-dump.exe #rdb文件校验、修复功能 redis-cli.exe #【重要】命令行客户端,连接Redis服务端可对Redis进行相关操作 redis-server.exe #【重要】Redis服务器,启动Redis
2. Redis启动和测试
2.1. 启动redis-server
进入到Redis安装目录 ,带配置文件启动redis,此时redis是在后台运行的
./src/redis-server ./redis.conf
查看是否6379端口,看看redis是否在运行
lsof -i:6379

2.2. 启动redis-client
-
连接本机Redis
./src/redis-cli
-
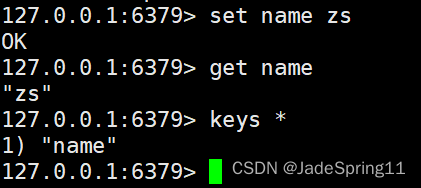
测试Redis
set name zs #设置数据:设置name的值为zs get name #获取数据:获取name的值【如果未nil,则表示没有】 keys * #查看所有的key
3. Redis设置密码
3.1. 设置密码
3.1.1. 临时修改
-
CONFIG SET 命令可以动态地调整 Redis 服务器的配置而无须重启,重启后失效
CONFIG SET requirepass 123456
3.1.2. 永久修改
-
修改配置文件 redis.conf ,增加代码
requirepass 123456

3.2. 登录Redis

启动redis-cli,执行auth命令:
auth 123456

三. Redis命令
1. String的操作
-
String结构模拟图
| key | value |
|---|---|
| name | zs |
| age | 18 |
-
set key value:将单个字符串值value关联到key,存储到Redis
set name zs #key为 name, 值为zs
-
get key:返回key关联的字符串值
get name #获取值,key为 name
-
mset key value key value:同时设置一个或多个 key-value 对
mset name zs age 18 #设置了两对key ,name=zs ; age=18
-
mget key key:获取多个值
mget name zs #获取key为name和zs的数据的值
-
incr key:将 key 中储存的数字值增1(key不存在,则初始化为0,再加1)
incr age #age的值增加1
-
decr key:将 key 中储存的数字值减1(key不存在,则初始化为0,再减1)
decr age #将age的值减去1
-
incrby key number:将 key 中储存的数字值增加指定数字
incrby age 2 #在age的值的基础上增加2
-
decrby key number:将 key 中储存的数字值减少指定数字
decrby age 2 #在age的值的基础上减去2
2. key的操作
-
keys * :查看所有的key
keys *
-
del key:删除指定的某个key
del username #删除key为username的数据
-
expire key secnods:设置key的过期时间(secnods秒后过期)
expire name 10 #设置name的过期时间10s
-
ttl key:查看key的过期时间
ttl name #查看name的过期时间
-
flushall:清空整个redis服务器数据,所有的数据库全部清空
flushall
-
flashdb:清除当前库
flushdb 默认是0号库:redis中默认有16个数据库,名称分别为0,1,2.。。15 切换1号库:select 1
-
select index:选择数据库,redis中默认有16个数据库,名称分别为0,1,2,,,15 , index数据库索引
select 1 #选择第2个数据库
-
exists key:查询key是否存在
exists name
3. List的操作
3.1. List常用操作
list集合可以看成是一个左右排列的队列(列表)
-
List机构模拟图
key value value value names zs ls ls ages 11 18 20 -
lpush key value value:将一个或多个值 value 插入到列表 key 的表头(最左边)
lpush names zs ls ls ww ls #往key为names的list左边依次添加值:zs ls ls ww ls #[ls ww ls ls zs]
-
lrange key start stop:返回列表 key 中指定区间内的元素,查询所有的stop为-1即可
lrange names 0 -1 #查看names的所有元素
-
rpush key value value:将一个或多个值 value 插入到列表 key 的表尾(最右边)
rpush names tom jack jack rose #往key为names的list右边依次添加值:tom jack jack rose #[ls ww ls ls zs tom jack jack rose]
-
lpop key:移除并返回列表 key 的头(最左边)元素。
lpop names #移除并返回names列表的头(最左边)元素 #[ww ls ls zs tom jack jack rose]
-
rpop key:移除并返回列表 key 的尾(最右边)元素。
rpop names #移除并返回names列表的尾(最右边)元素。 #[ww ls ls zs tom jack jack]
-
lrem key count value:根据count值移除列表key中与参数value相等的元素count
-
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 的值
-
count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值
-
count = 0 : 移除表中所有与 value 相等的值
rpush stars zs ls zs zs ls ww tq ls tq zl zs ls #[zs ls zs zs ls ww tq ls tq zl zs ls] lrem stars 2 zs #从左边删除2个zs lrem stars 0 tq #删除所有tq lrem stars -1 zs #从右边删除1个zs #[ls zs ls ww ls zl ls]
-
lindex key index:返回列表 key 中,下标为 index 的元素
lindex names 2 #取names列表中索引为2的元素 #zs
-
ltrim key start stop:对一个列表进行修剪 ,保留范围内的,范围外的删除
ltrim names 2 4 #删除names列表中索引为 2 - 4 以外的元素 #[zs ls ww]
3.2. Redis实现栈和队列
-
list控制同一边进,同一边出就是栈【先进后出FILO】
-
list控制一边进,另一边出就是队列【先进先出FIFO】
4. Hash的操作
4.1. Hash常用操作
Hash类似于jdk中的Map,一个key下面以键值对的方式存储数据
-
hset key field value:设置 key 指定的哈希集中指定字段的值。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。如果字段在哈希集中存在,它将被重写。
hset user1 name zs #给user1这个key设置name=zs键值对
-
hget key name获:取hash类型的name键对应的值
hget user1 name #获取user1中的name对应的值
-
hmset key field value field value:批量添加name=value键值对到key这个hash类型
hmset user2 name zs age 18 #给user2这个key设置name=zs键值对和age=18键值对
-
hmget key field field:批量获取hash类型的键对应的值
hmget user2 name age #获取user2中的name和age所对应的值
-
hkeys key:返回哈希表 key 中的所有键
hkeys user2 #返回user2总的所有字段
-
hvals key:返回哈希表 key 中的所有值
hvals user2 #返回user2中的所有值
-
hgetall key:返回哈希表 key 中所有的键和值
hgetall user2 #返回user2中所有key和value
5. Set的操作
set集合是一个无序的不含重复值的队列
-
set机构模拟图
| key | value | value | value |
|---|---|---|---|
| idcards | 110 | 120 | 130 |
| phones | 182 | 135 | 136 |
-
sadd key value value:将一个或多个member元素加入到集合key当中,已经存在于集合的 member 元素将被忽略
sadd colors red green yellow blue #往colors这个set集合中存放元素
-
smembers key:返回集合 key 中的所有成员
smembers colors
6. sort key
-
对 list,set,zset进行排序
sort ages #对年龄集合进行排序 sort ages desc #对年龄集合进行排序,倒序 sort names alpha #对姓名集合进行字典顺序排序 sort names limit 0 10 #取names集合中,从第0个元素,往后取10个元素
7. 发布/订阅(了解)
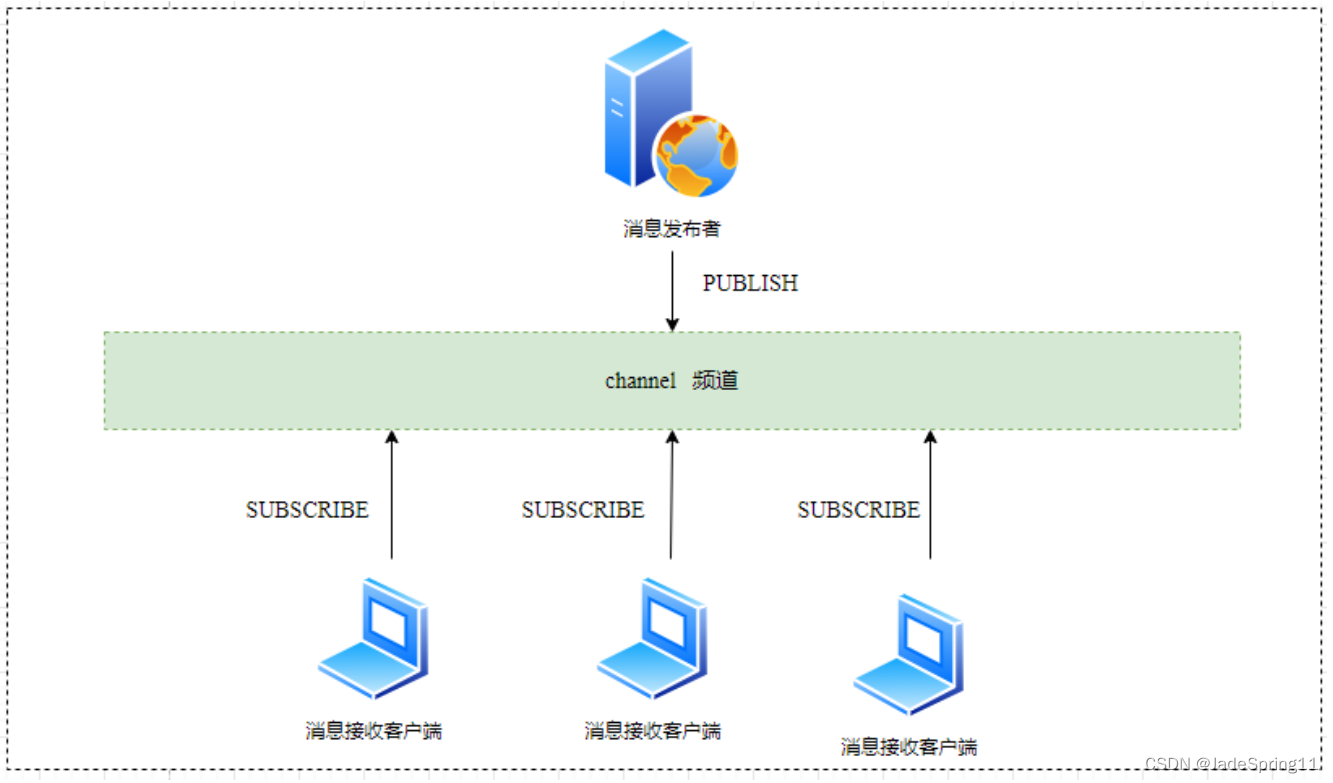
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的频道。没订阅的接受者当然是接受不到消息的,(pub/sub)是一种广播模式,及会把消息发送给所有的订阅者
消息接受者通过 SUBSCRIBE channel 命令订阅某个频道 , 消息发布者通过 PUBLISH channel message 向该频道发布消息,那么订阅了该频道的所有接受者就可以收到消息
-
消息接受者:开启一个 redis-cli 作为接受者,订阅一个频道
SUBSCRIBE cctv #cctv作为订阅的频道,可以任意定义名字
-
消息发布者:开启另一个 redis-cli 作为消息发送者,往 cctv 频道发布消息
PUBLISH cctv 'rose is comming...'
观察redis-cli接受者应该能收到消息内容:rose is comming...
8. 事务(了解)
Redis中事务不会回滚
MULTI:标记一个事务块的开始 EXEC:执行所有事务块内的命令 DISCARD:取消事务,放弃执行事务块内的所有命令
1. redis中事务的用法非常简单,我们通过MULTI命令开启一个事务 2. 在MULTI命令执行之后,我们可以继续发送命令去执行,此时的命令不会被立马执行,而是放在一个队列中 3. 当所有的命令都输入完成后,我们可以通过EXEC命令发起执行,也可以通过DISCARD命令清空队列
9. 命令总结
1. 操作list的命令:基本都是l开头 2. 操作set的命令:基本都是s开发 3. 操作hash的命令:基本都是h开发
四. Java操作Redis
1. Java集成Jedis
开始在 Java 中使用 Redis 前, 我们需要确保已经安装并启动 redis 服务及 Java redis 驱动,且你的机器上能正常使用 Java。可以取Maven仓库下载驱动包jedis.jar
网址:redis.cn
Java - jedis:支持,推荐,主页,链接 链接是一个GitHub的maven项目,可以打包成jar包。还可以打成源码包
1.1. 搭建工程
-
搭建普通java项目,项目名:jedis-demo
1.2. 导入Jedis依赖
-
把Jedis和连接池包一起导入进来
commons-pool2-2.2.jar #连接池 jedis-2.5.2.jar #Jedis核心包
1.3. 入门案例
public class TestCase {
@Test
public void testSetAndGet(){
//获取Jedis对象 = 连接对象,需要提供主机地址,端口号,超时时间
//其中port和timeout可以不写,默认就是6379和2s钟
Jedis jedis = new Jedis("localhost", 6379, 2000);
//设置密码
jedis.auth("123456");
//添加键和值
jedis.set("name", "jack");
//根据键获取值
System.out.println(jedis.get("name"));
//释放连接
jedis.close();
}
}
2. 连接池的使用
如果直接使用 Jedis链接Redis会造成频繁的Jedis对象创建和销毁,对性能会有很大的影响,所以我们会选择使用连接池来链接性能。原理同Mysql连接池
2.1. 连接池原理和作用
连接池实现原理:操作之前先获取一定的连接数,当有操作需要申请连接的时候,不是从redis中获取连接,而是从连接池中去获取空闲的连接,使用完了之后又将连接返回给连接池,重复利用。提高资源利用率
连接池作用:
1. 限定了最大并发连接数,防止redis服务器由于连接过多而崩溃 2. 不用重复创建和关闭连接,节省资源 3. 不用重复创建和关闭连接,用户访问速度更快,体验度提高
2.2. 连接池代码实现
2.2.1. 基本使用
@Test
public void testSetAndGetByJedisPool(){
//创建Jedis连接池配置对象
JedisPoolConfig config = new JedisPoolConfig();
//设置最大空闲连接
config.setMaxIdle(8);
//设置最大连接数
config.setMaxTotal(10);
//设置最大等待时间
config.setMaxWaitMillis(2000);
//设置获取连接时做有效性校验
config.setTestOnBorrow(true);//Borrow - 借用
//获取连接池对象
JedisPool pool = new JedisPool(config, "localhost", 6379, 2000, "123456");
//获取连接
Jedis connection = pool.getResource();
//设置数据
connection.set("id", "1");
System.out.println(connection.get("id"));
//释放或关闭连接
connection.close();//如果检测到有连接池就是释放回连接池中,否则就是关闭连接
pool.destroy();//摧毁连接池
}
2.2.2. 工具类封装
JedisPool是单例的(想想你的Mybatis的DataSource也只是创建了一个),为了方便使用,将JedisPool封装成工具
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.util.Properties;
public enum JedisUtil {
INSTANCE;
private static JedisPool pool = null;
static{
//创建Jedis连接池配置对象
JedisPoolConfig config = new JedisPoolConfig();
//设置最大空闲连接
config.setMaxIdle(8);
//设置最大连接数
config.setMaxTotal(10);
//设置最大等待时间
config.setMaxWaitMillis(2000);
//设置获取连接时做有效性校验
config.setTestOnBorrow(true);//Borrow - 借用
//获取连接池对象 //正常来说,这里应该有个属性文件,管理这些参数
pool = new JedisPool(config, "localhost", 6379, 2000, "123456");
}
//获取连接的方法
public Jedis getConnection(){
return pool.getResource();
}
//关闭连接或释放资源的方法
public void closeConnection(Jedis jedis){
if (jedis != null) {
jedis.close();
}
}
//封装常用的方法:set字符串,set字符串并添加超时时间,get字符串
public void set(String key,String value){
Jedis jedis = null;
try {
jedis = this.getConnection();
jedis.set(key, value);
} catch (Exception e) {
e.printStackTrace();
} finally {
this.closeConnection(jedis);
}
}
public void set(String key,String value,int timeout){
Jedis jedis = null;
try {
jedis = this.getConnection();
jedis.setex(key, timeout, value);//设置超时时间
} catch (Exception e) {
e.printStackTrace();
} finally {
this.closeConnection(jedis);
}
}
public String get(String key){
Jedis jedis = null;
try {
jedis = this.getConnection();
return jedis.get(key);
} catch (Exception e) {
e.printStackTrace();
} finally {
this.closeConnection(jedis);
}
return null;
}
}
2.2.3. 工具类操作key
@Test
public void testKey(){
//获取连接
Jedis jedis = JedisUtil.INSTANCE.getConnection();
//为了数据不受影响,清空数据
jedis.flushAll();
System.out.println("判断名称为name的key是否存在:" + jedis.exists("name"));
System.out.println("判断名称为age的key是否存在:" + jedis.exists("age"));
jedis.set("name", "周芷若");
jedis.set("age", "20");
System.out.println("再次判断名称为name的key是否存在:" + jedis.exists("name"));
System.out.println("再次名称为age的key是否存在:" + jedis.exists("age"));
jedis.del("name");
jedis.keys("*").forEach(System.out::println);
// jedis.expire(, )
// jedis.ttl()
JedisUtil.INSTANCE.closeConnection(jedis);
}
2.2.4. 工具类操作其他
-
操作list
jedis.lpush("students1","1","2","3","5","6"); //添加数据
System.out.println(jedis.lrange("students1", 0, 3)); //获取数据
-
排序操作
//对数字排序
jedis.flushDB();
//添加数据
jedis.lpush("nums","1","2","3","4","8","5","3","1");
//排序
System.out.println(jedis.sort("nums"));
-
set的操作
jedis.sadd("students2","a1","b1","c1","b1"); //添加数据
System.out.println(jedis.smembers("students2")); //获取成员
-
hash操作
jedis.hset("students3","student","zhangsan"); //添加数据
System.out.println(jedis.hget("students3", "student")); //获取数据
五. Spring项目中使用Redis
1. 方案选择
1.1. 工具类JedisUtils
上面已经给出,建议:面向度娘找一个合适的使用
1.2. SpringBoot Spring data redis
Spring data:spring对数据操作支持规范,但是我们的数据是多种类型:rdbms(msyql),redis(Nosql),es,mq
Spring data redis :spring操作redis Spring data jpa :操作关系型数据库 等等
Springboot Spring data redis:简化Spirng data对redis的配置
2. 实战
2.1. 搭建spirngboot项目
略
2.2. 导入依赖
<!--spirngboot springdata对redis支持--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency>
2.3. 配置信息
2.3.1. properties配置或yml配置
#数据源配置
spring:
redis:
host: 192.168.10.101
port: 6379
timeout: 2000
password: 123456
lettuce:
pool:
max-active: 100 # 最大允许连接数
min-idle: 5 # 最小空闲连接数,最少准备5个可用连接在连接池中候着
max-idle: 10 # 最大空闲连接,当超过10个之后会自动释放
max-wait: 30000 # 当连接池到达上限后,,最多等待30秒尝试获取连接,超时报错
2.3.2. 启动类App
略
2.4. 代码中使用
@Resource
RedisTemplate redisTemplate;
@Test
public void testString(){
// 往redis中写入String类型的数据
redisTemplate.opsForValue().set("name", "dw");
String name = (String)redisTemplate.opsForValue().get("name");
System.out.println(name);
}
@Test
public void testHash(){
// 往redis中写入Hash类型的数据
redisTemplate.opsForHash().put("citys", "c1", "WuHan");
redisTemplate.opsForHash().put("citys", "c2", "ChangSha");
redisTemplate.opsForHash().put("citys", "c3", "NanChang");
System.out.println(redisTemplate.opsForHash().get("citys", "c1"));
System.out.println(redisTemplate.opsForHash().get("citys", "c2"));
System.out.println(redisTemplate.opsForHash().get("citys", "c3"));
System.out.println("----------------------------------------------------");
// 将HashMap写入redis
HashMap<String, String> map = new HashMap<>();
map.put("name", "dw");
map.put("province", "HuBei");
map.put("city", "WuHan");
redisTemplate.opsForHash().putAll("person", map);
System.out.println(redisTemplate.opsForHash().get("person", "province"));
System.out.println(redisTemplate.opsForHash().entries("person"));
}
/**
* 将user:uid作为key,将User对象的JSON字符串作为value
* @throws JsonProcessingException
*/
@Test
public void testRedisSerializer() throws JsonProcessingException {
// 创建User对象,然后Jackson序列化为JSON字符串
User user = new User();
user.setUid(1001L);
user.setUsername("dw");
user.setPassword("123456");
user.setAge(25);
// 将User序列化为JSON字符串并存入redis
redisTemplate.opsForValue().set("user:"+user.getUid(), user);
// 手动创建一个map形式的user数据,然后Jackson序列化为JSON字符串
HashMap<String, Object> map = new HashMap<>();
map.put("uid", 1002L);
map.put("name", "张三");
map.put("password", "159753");
map.put("age", 30);
map.put("phone", "15786411234");
redisTemplate.opsForValue().set("user:1002", map);
// 使用BeanUtil将User对象转为Map,然后Jackson序列化为JSON字符串
User user1 = new User(1003L, "李四", "111222", 33, "12345678910");
Map<String, Object> beanMap = BeanUtil.beanToMap(user1);
redisTemplate.opsForValue().set("user:"+user1.getUid(), beanMap);
}
/**
* 将redis中读取的数据进行反序列化
*/
@Test
public void testRedisDeserialize(){
// 从redis中获取的数据会被Jackson转换成LinkedHashMap
LinkedHashMap map = (LinkedHashMap) redisTemplate.opsForValue().get("user:1001");
// 使用BeanUtil将LinkedHashMap转换成User
// User user = BeanUtil.mapToBean(map, User.class, false, CopyOptions.create());
// 或者
User user = BeanUtil.toBean(map, User.class);
System.out.println(user);
}
六. Redis持久化机制
1. Redis常见配置
redis.windows.conf 或者 redis.conf,Redis 版本不一样配置文件名字不一样
bind 127.0.0.1 绑定地址:允许那个人来访问,绑定了之后安全性更高 port 6379 可以修改默认端口 timeout 超时时间 一个用户n秒后不操作自动关闭连接 默认为0,表示不关闭 loglevel notice 日志级别 logfile "" 指定日志文件 databases 16 配置多少个数据库 save 900 1 RDB持久化策略,满足条件做持久化 appendonly AOF持久化
2. Redis持久化概述
2.1. 什么是Redis持久化
因为Redis数据基于内存读写,为了防止Redis服务器关闭或者宕机造成数据丢失,我们通常需要对Redis做持久化化,即:把内从中的数据保存一份到磁盘做一个备份。当Redis服务关闭或者宕机,在Redis服务器重启的时候会从磁盘重新加载备份的数据,不至于数据丢失。 Redis 提供了两种不同级别的持久化方式:RDB和AOF,可以通过修改redis.conf来进行配置。开启持久配置后,对Redis进行写操作,在Redis安装目录将会看到持久文件:appendonly.aof 和 dump.rdb

2.2. Redis如何保存数据
redis为了考虑效率,保存数据在内容中。并且考虑数据安全性,还做数据持久化。如果满足保存策略,就会把内存的数据保存到数据rdb文件,还来不及保存那部分数据存放到aof更新日志中。在加载时把两个数据做一个并集。
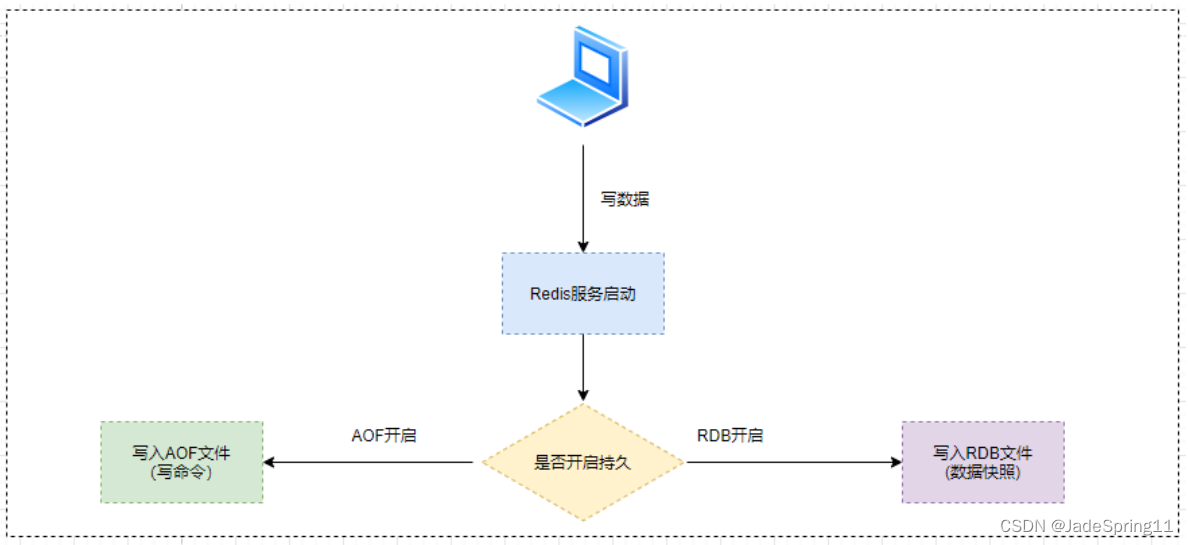
2.3. Redis持久化原理图
-
保存持久化数据
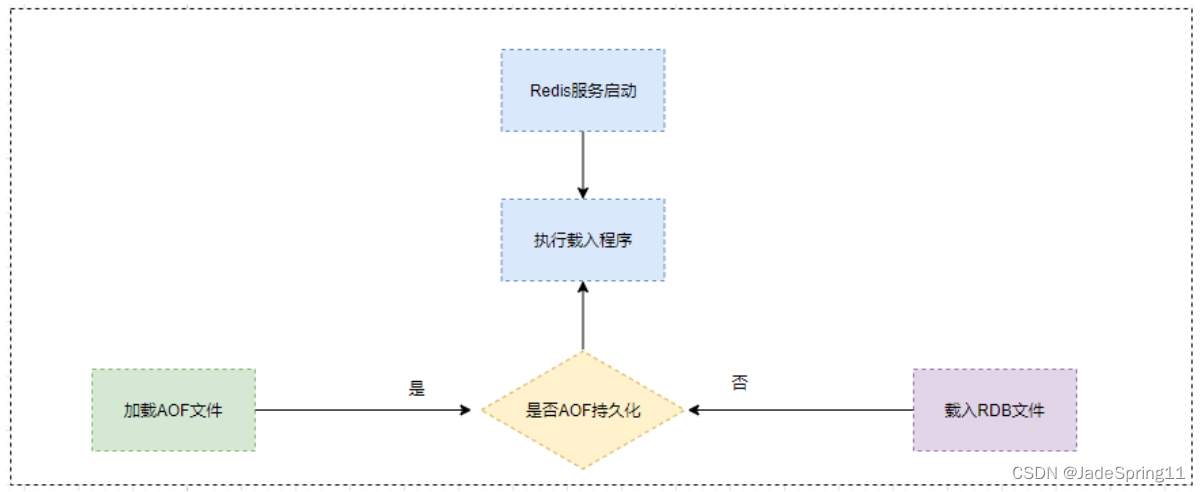
-
启动Redis载入持久化数据
3. Redis持久化操作
3.1. Redis持久化-RDB
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,默认开启该模式
save 900 1 #如果15分操作一次就持久化一次 【900是秒数】 save 300 10 #如果5分钟操作10次就持久化一次 save 60 10000 #如果1分钟操作10000次就持久化一次
演示RDB持久化策略:
1. 启动服务器,启动客户端,输入密码之后,flushall清理所有数据,然后set name zs 2. 关闭窗口【如果没有效就杀进程】重启服务器 3. 数据没有了,说明保存在内存。因为没有满足sava保存机制 4. 添加save保存机制:save 1 1 - 1s中保存一次,再测试一次 会多出一个文件:dump.rdb 注意:1s钟操作一次,和操作关系型数据库没啥区别 所以不能改太频繁,这样会越来越慢
如何关闭 rdb 模式?可以修改配置文件注释如下内容:
# save 900 1 #如果900秒的时间段内操作一次就持久化一次 # save 300 10 # save 60 10000
3.2. Redis持久化-AOF
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集,默认关闭该模式。如何开启aof模式:
appendonly yes #yes 开启,no 关闭
演示AOF持久化策略:
1. 将save 1 1 去掉,将appendonly 改成yes 2. 如果不满足save保存机制,但是数据没有丢失,说明aof机制就生效了 flushall ,set name zs,没有满足save保存机制 断电 - 然后再启动服务和客户端 - 查看数据是否保存
4. Redis持久化小结
1. redis是怎么保存数据? redis为了考虑效率,保存数据在内存中。不仅如此,为了考虑数据安全性,Redis还可以让数据持久化,如果满足保存策略,就会把内存的数据保存到数据rdb文件,还来不及保存那部分数据存放到aof更新日志中。在加载时,把两个数据做一个并集 2.优缺点 RDB:记录数据快照 优点: 1. 产生一个持久化文件,方便文件备份 2. 持久化性能比AOF好,文件体积更小,启动时恢复速度快 缺点: 1. 没办法100%保证数据不丢失 AOF:记录写命令 优点: 1. 保证数据安全 2. AOF日志格式清晰,容易理解 缺点: 1. AOF文件通常要大于RDB文件 2. AOF数据恢复比RDB慢 最佳实践:二者结合,RDB来数据备份,迁移。AOF保证数据安全
七. Redis的淘汰策略
1. 淘汰策略基本概念
1.1. 为什么要淘汰
Redis的数据读写基于内存,Redis虽然快,但是内存成本还是比较高的,而且基于内存Redis不适合存储太大量的数据。Redis可以使用电脑物理最大内存,当然我们通常会通过设置maxmemory参数限制Redis内存的使用, 为了让有限的内存空间存储更多的有效数据,我们可以设置淘汰策略,让Redis自动淘汰那些老旧的,或者不怎么被使用的数据
2.2. 淘汰策略有哪些
常用的:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰 volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 allkeys-lru:从所有数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
不常用:
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰 no-enviction(驱逐):禁止驱逐数据
2. 淘汰策略配置
2.1. 最大内存配置
-
修改配置redis.window.conf,修改maxmemory,放开注释, 根据情况设置大小
maxmemory <bytes>
2.2. 淘汰策略配置
-
修改配置redis.window.conf ,修改maxmemory-policy ,放开注释,按情况修改策略
maxmemory-policy noeviction #noeviction 为默认的策略,根据情况修改
注意:淘汰策略真实环境是需要配置的,测试环境不需要,没办法模拟这么大的数据量
八. 课程总结
1. 重点
1. Redis使用场景 2. Redis的特点 3. 五种数据结构和常用命令 4. Redis持久化方案 5. Redis淘汰策略
九. 课后作业
1. 面试问题 2. 重点总结 - 相同的只写一个 3. 扩展知识中的面试题看下 4. 看下部门后端和前端代码每个功能是怎么实现的 5. 代码作业 新建项目:homework_springboot_redis 1. 在SpringBoot中使用Redis操作对象Student
十. 面试问题
1. 项目中那些地方用到Redis,怎么用的? 2. Redis有哪些数据结构? 3. Redis怎么实现栈和队列? 4. Redis数据满了时会怎么办? 5. 说一下Redis持久化方案? 6. 说一下Redis淘汰策略?
十一. 常见问题
1. 启动redis服务的时候,双击redis-server.exe出现闪退 要通过cmd命令启动:redis-server.exe redis.windows.conf
2. redis.windows.conf设置密码 requirepass 123456前面不能有空格
十二. 扩展知识
Redis的面试题 1. 10个常见的Redis面试题 https://blog.csdn.net/yangzhong0808/article/details/81196472 2. 2018最全Redis面试题整理 https://blog.csdn.net/wchengsheng/article/details/79925654
KB与B # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes #带b【真正存储的容量空间】的多24,不带b【硬件厂商的单位】的都少24。u盘就是不带b的















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









