






一、集群架构总论
1、什么是集群
集群就是把多台设备(服务器+网络设备)集中到一起
形成一个群体,相当于一个整体在对外提供服务
(类比:你们家的网络是如何构建的)
单点故障:
提供服务的设备只有一台,这台挂掉,整体就访问不了了
如何防单点故障:=====》高可用
再来一台设备做冗余,一台挂掉,另外一台可以继续提供服务
2、多种流量类型:
南北流量(14%):内网机器与外网通信(业务量影响)
东西流量(77%):内网机器在局域网内彼此之间进行通信(占比较高,取决于集群规模)
跨数据中心的流量(9%):跨数据中心的流量,例如数据中心之间的灾备,私有云和公有云之间的通讯。(防止机房级别的单点故障,保持数据中心数据的一致)
eg: 个人家庭网络链路
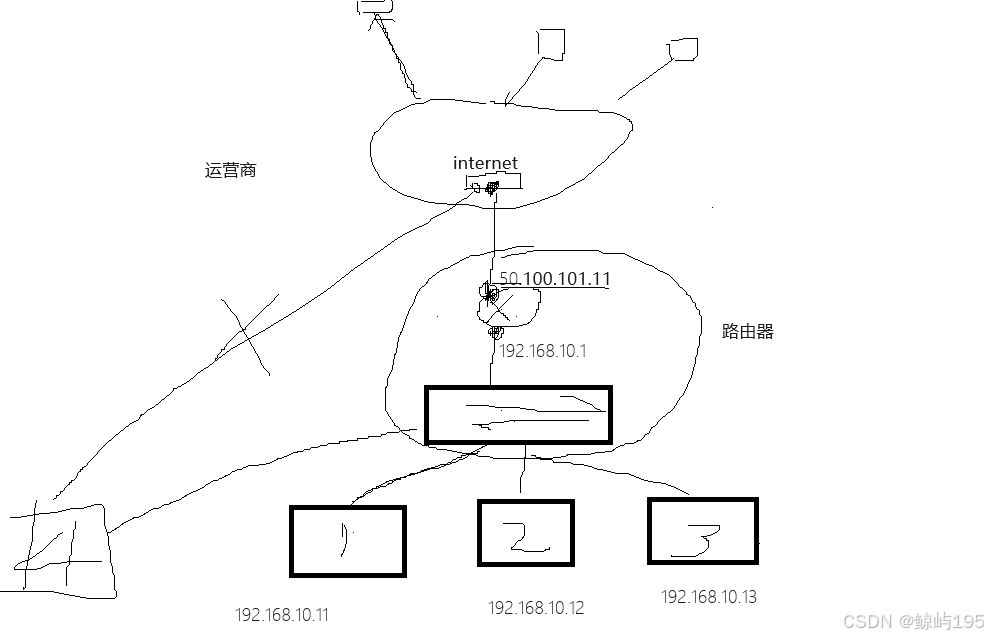
# 可以使用路由器+交换器实现多设备上网,也可以直接将一台设备直接与买的运营商IP相连
 (查询公网# ip curl cip.cc)
(查询公网# ip curl cip.cc)
3、上万台服务器集群是如何构建的
痛点:
1、交换机的性能问题
交换机的接口数有限(没有上万个接口)
广播包不能很大
2、地域限制
总结下来其实就一个点------想要把服务器都组织到一个二层网络里,但是无法把所有机器都组织到一台交换机里
解决方案:分层组织
1、接入层: 负责接入服务器,形成一个个的局域网
2、汇聚层:把接入层的交换机重新汇聚成一个二层网络
不同汇聚层代表不同的业务场景
3、核心层:把多个汇聚层给组织到一起
# 不断进行细分----专门的人做专门的事-----解耦合----拓展性强,方便性能优化,高可用(隔离故障),降低复杂性
# 接入Internet骨干网----用于业务服务 接入业务骨干网络----用于不同地域公司服务器间的通信
# 出口方案: 1.防火墙(也具有路由功能) 2.路由器(特殊场景) 3.路由器+防火墙
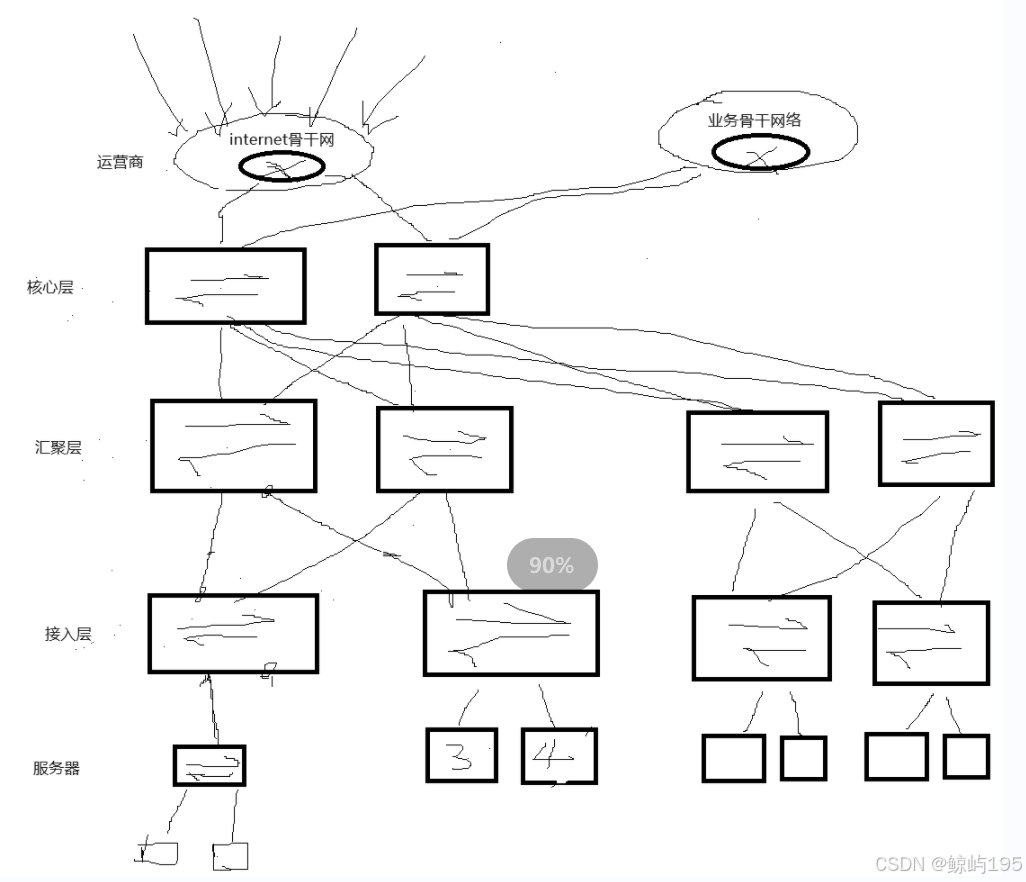
4、数据中心
把接入层以上的网络都组好了,你的服务器托管到数据中心即可(用户自己组好二层网络接入接入层)
5、SDN网络(了解)
SDN网络:软件定义网络--》附加在/依托于物理网络之上的虚拟网络
云服务:
## 公有云---用户买入,标准化服务 私有云---自行搭建,可定制化
用户请求-----》云平台管理软件(例如openstack)------》虚拟化软件(kvm、esxi、xen)---》虚拟机----》为虚拟机准备好sdn网络
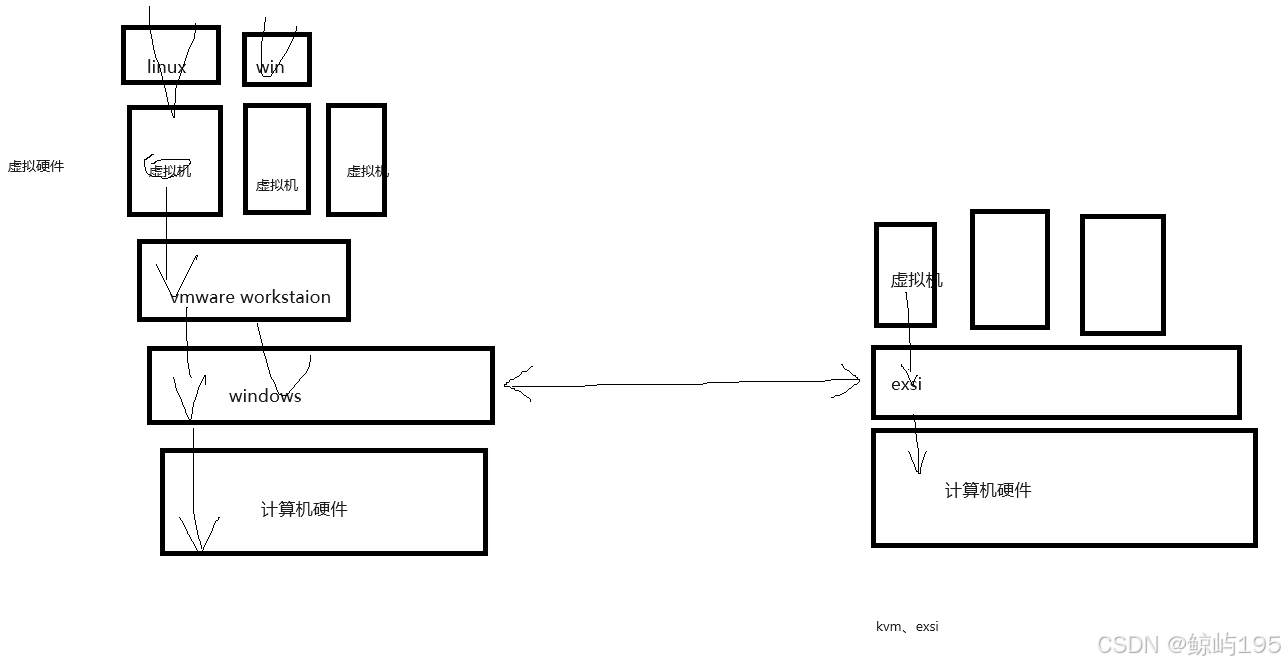 (虚拟化)
(虚拟化)
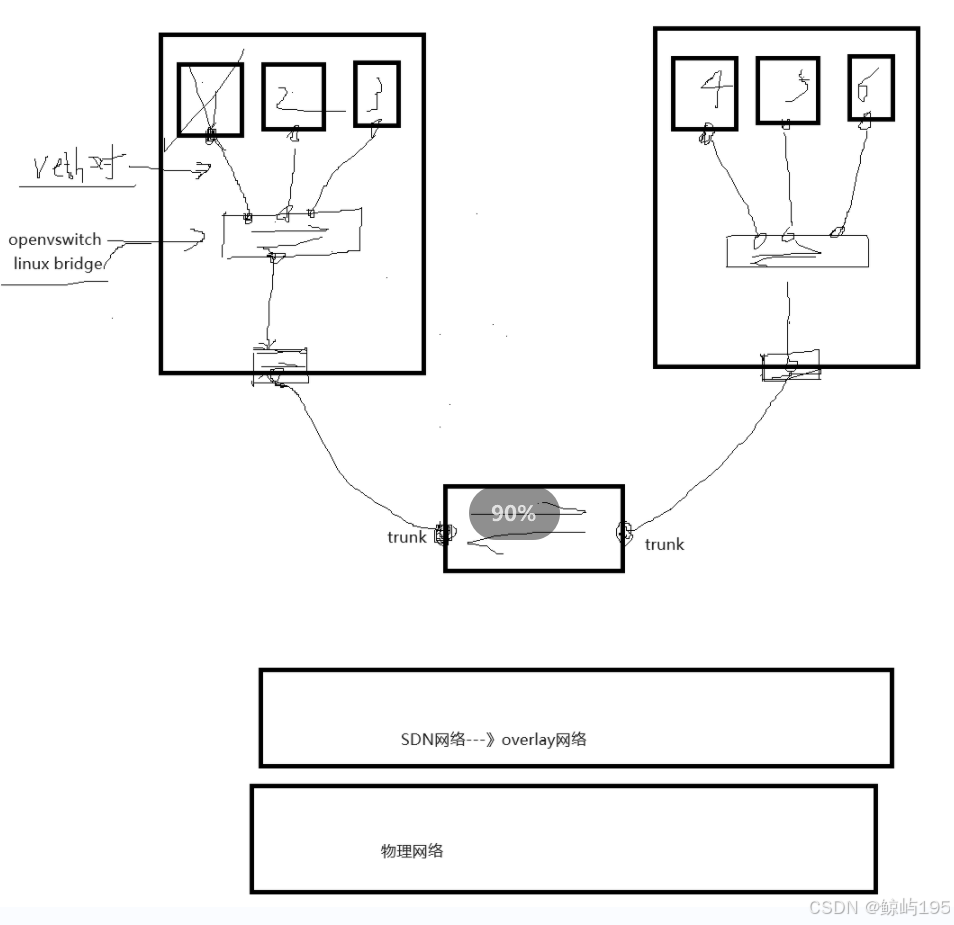
# Veth 对----是一对虚拟网络接口,相当于一条虚拟网线
# Overlay 网络是 SDN 实现网络虚拟化的重要手段之一
sdn网络中的网络模式
vlan模式:
底层依托的物理网络:二层网络(局限性)
缺点: 公有云用户过多vlanid(4096个)不够用 不能跨地域(数据中心)通信
gre、vxlan
底层依托的物理网络:二层网络、三层网络
6、云计算
IAAS:卖虚拟机
PAAS:卖虚拟机+操作系统
SAAS:卖虚拟机+操作系统+应用程序
7、内网服务器集群架构
VPN--------在两个公网ip之间搭建一个隧道,使其可以通过隧道访问私网ip
内网:服务器集群的网络
集群:
部署集群的目的是为了承载/运行我们的基于网络通信的应用程序
网络通信的应用程序服务端构成:
负责网络通信--------------》拿来主义,直接用现成的
负责处理业务逻辑
例如:
用php开发网络应用软件
1、业务逻辑部分:用php语言写
2、网络通信部分:直接用别人开发好的php-fpm
===
用python开发网络应用软件
1、业务逻辑部分:用python语言写
2、网络通信部分:直接用别人开发好的uwsgi
===
用java开发网络应用软件
1、业务逻辑部分:用java语言写
2、网络通信部分:直接用别人开发好的tomcat
===
用go开发网络应用软件
1、业务逻辑部分:用go语言写
2、网络通信部分:go程序编译后的二进制文件直接就带http服务,不需要额外安装
网络通信的应用程序有两种架构
CS架构
client(放到“网盘”里让用户下载)-------------------------server
BS架构
浏览器+前端代码(html给内容打记号、css进行修饰、js动态效果)---------------server
# 浏览器访问某个服务端就去某个服务端将其客户端代码拿到本地运行
重要:
访问以此页面,会产生很多次请求
集群两大注意点:
时间
网络
二、集群性能指标与集群架构
1、构建前:
需要预估出集群的容量/规模----》依据性能指标
性能指标:
PV与UV(一般都是以天为单位统计)-----吸引用户的能力
PV:page view,访问一次页面算一次pv
强调:加一个页面会产生很多请求
UV:user view,一个用户访问一次算一个uv
查询----nginx---->access.log
根据访问ip统计uv awk '{print $1}' access.log | sort | uniq -c |wc -l
统计访问url统计pv awk '{print $7}' access.log | wc -l
注意:
1、看日志分析出的pv、uv代表的是过去的信息,不能用于评估未来的集群规模
最多可以作为一个经验参考,例如:发现用户80%的访问都是集中在20%的时间内
2、预估集群规模,应该与业务人员对齐,拿到一个未来可能发生的pv与uv数
通常会在此基础上乘以一个系数(经验值)
吞吐量(Throughput)---》请求与响应的速率---------反应集群的性能
QPS(Queries Per Second)1s内完成的请求数(访问一次页面会产生多次请求)
###重要指标
注意:
1、统计的是一段时间内的完成的请求数
2、代表的是完成了的请求的数
公式: 完成处理的总请求数 / 时间段
案例: 我们预估一个网站每天有10w活跃用户,称之为10w日活,每人平均访问4个页面,每个页面平均衍生4个接口请求(80%的访问都是集中在20%的时间内)
100000*4*4=160w 160w*0.8 / (24*60*60)*0.2=......
TPS(Transactions Per Second)1s内完成的事务数
一个事务包含了多个操作,这多个操作是有可能跨越多个page的,必然涉及到多个请求
TPS体现了系统在单位时间内处理事务的能力
QPS与TPS------------一秒内完成购买了某个商品的动作,但是该动作内包含了一次查找商 品请求、一次添加购物车请求,一次支付请求,计为1个“TPS”,但 是记为3个“QPS”
RT(Response-time,代表响应时长)
指的是一个请求从发出到拿到响应一整过程所经历的时间
包含:
1、 一去一回的网络传输时间
2、服务器处理的时间
页面加载完成时间:
访问一个页面的url地址,到看到一整个页面所需要的时间:
注意:
页面加载完成时间包含有:
1、与该页面相关的所有的请求完成的时间
2、解析html、css、js代码的时间
并发量(Concurrency)
在某一时刻/时间点正在发生的请求
与qps的区别:
1、qps代表完成的请求数
2、qps是某一个时段的内完成的请求数
例如:
此刻系统有5个请求,但是每个请求都需要花费2s才能处理完成
问:
并发量是:5
qps是:5 / 2 = 2.5
总结:
极限qps----反映的是系统的最大处理效率
能抗住的并发量----反映系统能最大承受的压力
补充: DAV---日活 MAU----月活
如何预估集群规模:
1、问运营、产品同学预估出某段时间可以达到的pv总数
2、预估峰值QPS
计算方式一:80%的请求集中在20%的时间段内
( 3000000 * 10 * 0.8 ) / (86400 * 0.2 ) = 1388 (QPS)
计算方式二:
( 3000000 * 10 ) / 86400 = 347 (QPS)
347 (平均值)* 峰值因子 = 峰值qps
3、压测得到单台机器的峰值/极限qps------->不断增加并发数
4、计算机出需要多少机器来共同承载请求
预估的未来发生的峰值qps / 单机的极限qps = 需要多少台机器
5、此外还需考虑网络带宽(都是预估的)
带宽(bps)=总流量数(bit)/产生流量的时长(秒)=(PV*衍生请求数*每个请求的平均大小*8)/统计时间(秒) 1B=8bit
得到结果 * 峰值因子 = 峰值带宽
6、如何提升一套系统的整体处理速度
提升最慢那个点的速度(通常都是跟io有关系)
2、开始构建
架构师-----》将军
预估集群容量----》估算需要招募多少士兵
接下来指挥大家去打仗------》构建一套集群
需要注意的点
1、时间需要一致
2、网络通信畅通
2、集群需要分层(解耦合)---》对士兵角色进行划分
网页缓存层--->CDN--------静态(大部分)与动态数据分开存储
补充:
静态数据:相对不变的数据,例如图片、css文件、js文件
动态数据:需要后台服务端每次计算得到一个新的结果
每次请求得到结果都不固定,即动态的
负载均衡层---》饭店里的领班负责调度---分散请求的压力
web应用层(web服务+web应用)----》饭店里厨师----存在多个
文件服务器层--------------------》共享存储,相当于一块大网盘
数据库及数据的缓存层
五层架构推演
单机--》web层
问题:用户访问增加,单机硬件性能不足---》解决:把单机里的组件拆出来部署到单独的机器上--》诞生数据库及数据的缓存层
问题:用户访问量持续增加,web层只有一台机器扛不住压力--》解决:引入负载均衡层,代理多台web层服务器
问题:web层服务需要共享数据-----》解决:引入了文件服务器层,便于更新数据和防止数据冗余
问题:访问压力变大速度变慢---》解决:引入cdn网页缓存层(分离静态与动态数据存放)
问题:单点故障
每一层慢慢都会演变成一个小集群
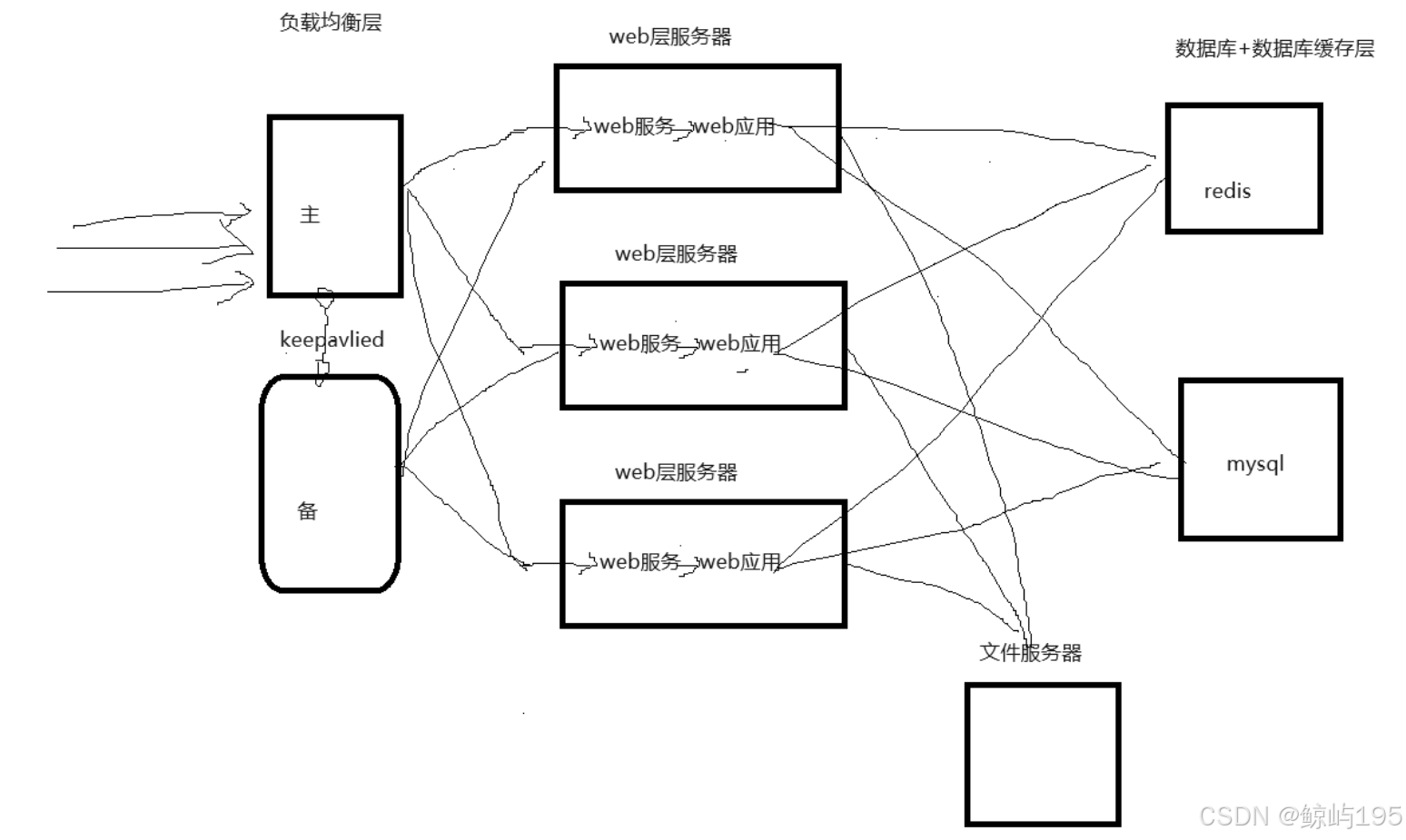
# 负载均衡层主备之间用keepavlied实现ip漂移进行主备切换(vip虚拟IP---存活检测)
# CDN网页缓存层通过将大部分静态数据分离至别处从而避免地域问题导致的高延迟,提升访问速率,减轻服务器访问压力
三、快速构建一套架构(******)
一套集群需要考虑的一些关键点:
1、性能
2、高可用性
每一层都要演变成一个小集群
集群五层概述
数据库与数据库缓存层(高压下最大的性能瓶颈)
数据库缓存(非关系型):redis、memcache
name="egon" # 数据彼此之间没有关联性
name1="tom"
age=18
age1=19
gender1="male"
gender="male"
特点:
1、数据库没有帮你组织好数据之间的关系
2、数据的存取都是在内存中
(也会定期开一个进程将数据写入硬盘)
优缺点:存容易取难
优点:
数据库本身的设计复杂度低+内存读写----》读写速度非常快
缺点:
应用程序开发的复杂度高(应用程序需要自己组织数据的关系)
数据库(关系型):mysql、 oracle、 db2、 sql server、 mariadb(从mysql分离出来的)
create table user(name varchar(15),age int,gender varchar(6)); # 存在关联
特点:
1、数据库帮你组织好数据之间的关系
2、数据的存取都是在硬盘
优缺点:
优点:
应用程序开发的复杂度低
缺点:
数据的存取速度相对慢一些
文件服务器层:
nfs共享存储:存在单点故障问题
单nfs+备份nfs innotify(监测变动)+rsync(同步变动 增量拷贝 || scp为全量拷贝)
主nfs挂掉需要人为的更改挂载到备份nfs,业务无法正常进行
DRBD+HeartBeat+NFS---不存在单点故障但是也存在压力过大的情况
分布式存储:ceph
分布式文件系统----MFS 、Glustr
web层----处理负载均衡层的网络缓存
服务:负责接收网络请求+解析协议
应用:负责处理业务逻辑、与数据库打交道
python
应用:自己用python开发、负责与数据库、数据库缓存通信
服务:uwsgi(支持http uwsgi协议)
java
应用:自己用java开发、负责与数据库、数据库缓存通信
服务:tomcat 、jboss、weblogic
php
应用:自己用php开发、负责与数据库、数据库缓存通信
服务:php-fpm
go
应用+服务---》编译在一个二进制文件里
web层的部署( 通常)
nginx----web服务----web应用 # nginx(套接字软件)本质也是web服务
最前面增加部署nginx的好处
1、缓冲压力,提升性能----nginx的性能十分强大
2、动静分离----分离动态与静态请求
3、安全防护-----设置规则进行匹配
4、日志管理
5、兼容各种协议,对外提供一种统一的协议HTTP,放行服务端所支持的协议
总结好处:
1、性能的提升
2、功能的增强
#增加一个nginx可以增加负载均衡层的灵活性,对外统一提供http协议负载均衡层也只用遵循http协议进行发送
负载均衡层:
软件:
haproxy:支持七层与四层
nginx:支持七层与四层
lvs:支持四层负载均衡
硬件负载均衡:F5
总结:
做四层转发(基于端口转发):
lvs
F5
做七层转发(基于HTTP协议转发):
nginx
haproxy
# haproxy不支持uwsgi协议,使用时需要在web层部署nginx
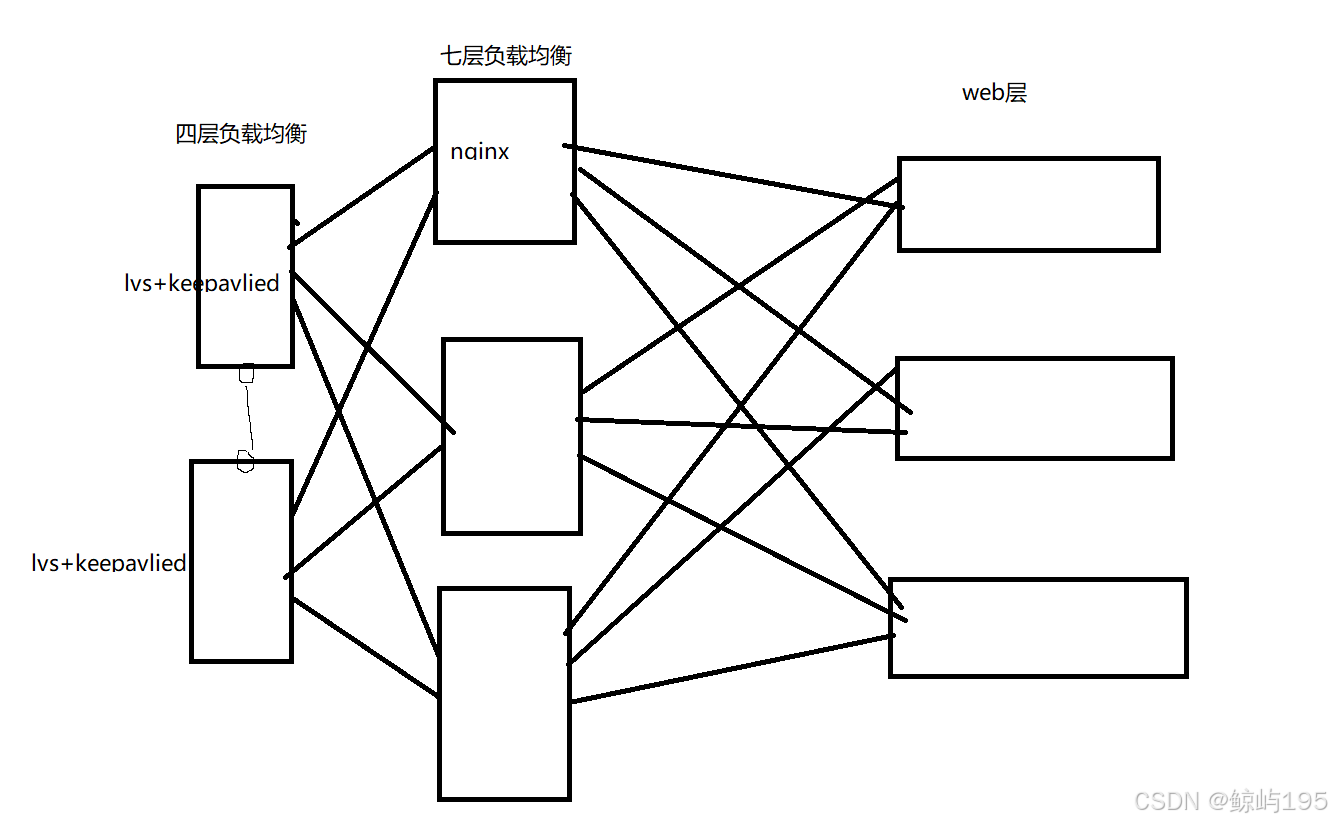
## 访问量增加,七层负载均衡顶不住加上四层负载均衡,同时将keepavlied移至四层,七层的每台服务器都投入使用
网页缓存层-CDN
后期管理
1、部署好监控与报警
nagios
cacti
ganglia
zabbix
promethus
2、连接机器进行管理:jumpserver(跳板机)、vpn
3、批量管理:ansible
4、自动发布流程
gitlab代码仓库(对于运维人员来讲这就是一块存放代码的大网盘)
公共:
github
gitee
jenkins(管理一系列流水线---将代码仓库中的代码取出并进行编译,将结果发布给web)
5、日志管理
ELK
EFK
6、k8s+容器技术
扩副本
自愈(发现故障、自动重启)
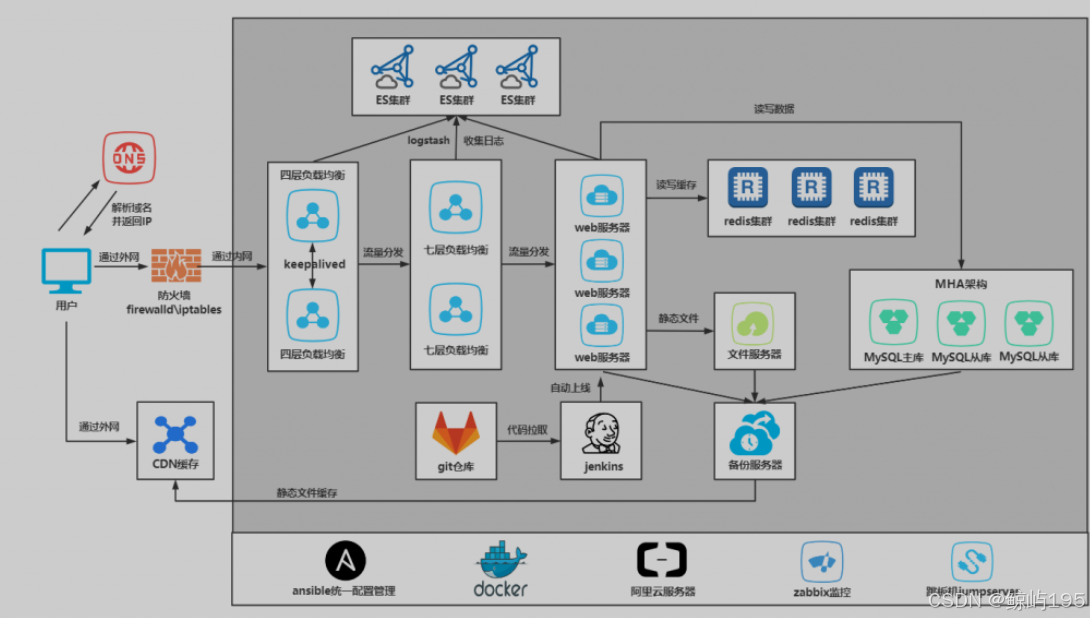
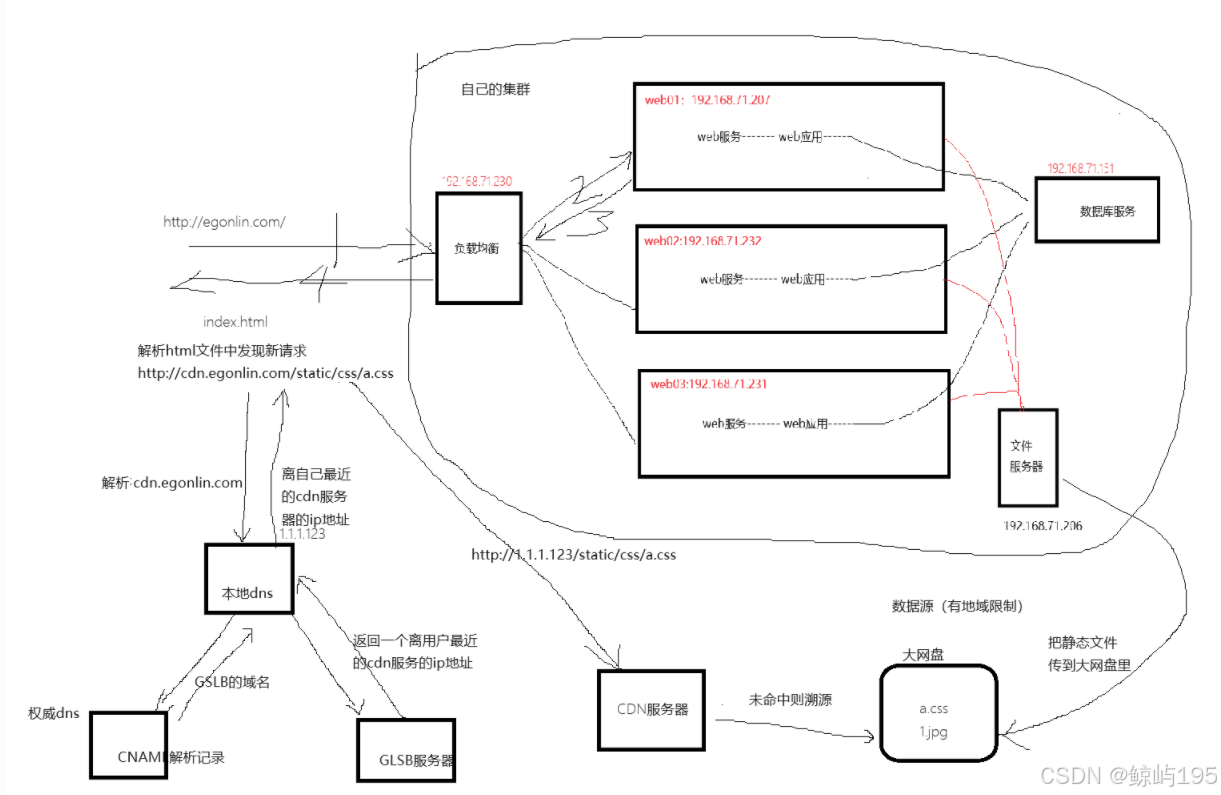
### 1、用户访问流程
1、用户在浏览器输入域名
2、浏览器拿着域名去DNS服务器解析
3、DNS服务器将解析后的IP返回给浏览器
4、浏览器根据IP去访问真实服务器
5、访问真实服务器的防火墙
6、请求通过防火墙后通过内网交换机传给负载均衡
7、负载均衡将请求平均分配给后端的web服务器
8、web服务器判断是静态请求还是动态请求
9、如果是静态请求,web服务器会去文件服务器获取数据
10、如果是动态请求,web服务器会去数据库或者缓存获取数据
11、数据从数据库或者NFS服务器返回给web服务器,web服务器将数据返回给负载均衡,负载均衡通过防火墙将数据传给浏览器
# 数据库:主要用于存储和管理结构化数据,如用户信息、订单数据、业务流程相关的数据等。
NFS 服务器:主要用于提供网络共享存储,以文件系统的形式将存储资源共享给集群中的多个 节点。它更适合存储非结构化数据,如文档、图片、视频等文件,或者作为应用 程序的共享配置文件、日志文件等的存储场所。
### 2、运维访问流程
1、管理人员连接跳板机或者vpn
2、通过跳板机或者vpn连接内网服务器
3、通过zabbix监控查看服务器状态
4、如果有问题则连接响应的机器解决问题
5、日常巡检,查看服务器配置
6、管理备份和备份数据
7、日志收集和整理展示
单机部署
1、环境准备
时间
网络-》静态ip
规范主机名-》添加到hosts
关selinux
关防火墙
setenforce 0 vim /etc/sysconfig/selinux
systemctl stop firewalld ( disable)
iptables -F
2、下载应用包、解压
方式一:
git clone xxx
方式二:
wget xxxx
3、准备好软件的运行环境
1、安装依赖包
# 1、下载gcc包
yum install gcc* glibc* -y # gcc--c /c++编译器 glibc--c程序依赖的基础库
# 2、依赖python环境
yum -y install python3 python3-devel python3-pip
#3、下载软件依赖的python库(由开发人员编写需求文档)
pip3 install flask -i https://mirrors.aliyun.com/pypi/simple/
pip3 install pymysql -i https://mirrors.aliyun.com/pypi/simple/
2、安装web服务---》uwsgi
4、准备数据库
yum install mariadb* -y
systemctl start mariadb
[root@localhost ~]# mysql -uroot -p # 执行下述命令
-- 创建账号xxx密码123,web应用链接的时候会用
grant all on testDB.* to 'xxx'@'127.0.0.1' identified by '123';
flush privileges; # 刷新权限
[root@localhost ~]# mysql -uroot -p # 执行下述命令
-- 创建库、表。项目中会用到
CREATE DATABASE testDB;
USE testDB;
create table messages(id int primary key auto_increment,text varchar(15)) charset=utf8mb4;
# 有时建库建表操作会给一个sql文件直接导入即可 mysql -uroot -p '密码' < abc.sql
5、修改软件的配置文件 # cat conf/settings.py 修改数据库链接信息
略
6、安装并配置web服务---》uwsgi
pip3 install uwsgi -i https://mirrors.aliyun.com/pypi/simple/
配置uwsgi拉起应用程序
uwsgi.ini-------------->自定义文件目录建立配置文件,一般就放入所安装的应用文件中 # 配置文件每一条后面不能跟任何符号
[uwsgi]
#1、监听的http协议端口
http = :8080
#2、启动后切换到该目录下作为项目根目录-----软件对应的目录
chdir = /soft/flask-web-app-main
#3、my_app对应项目根目录下的my_app.py文件(后端文件),冒号后的app--->文件内的实例名字(代码中的)
module = my_app:app
#4、启动的工作进程数量
processes = 4
#5、每个进程开启的线程数量
threads = 2
启动
uwsgi uwsgi.ini
# 打开网页----读取数据库数据----GET请求
# 写入数据----将数据写入数据库----POST请求
压力测试:
# uwsgi uwsgi.ini &>> /tmp/access.log & 后台运行并将结果写入日志进行分析
tail -f /tmp/access.log
单机极限qps:463.84----(测试记录)
先摸底:
1、先高并发去测试 10000
2、1000
3、500
4、400
5、300
6、200
7、100 ----》 失败数为0
再触底反弹一下
100每次加10,直到出现失败数
集群部署
准备6台机器:
负载均衡器
三台web服务器(压力测试计算所预估的数量)
文件服务器层
数据库层
预估规模(压力测试)---》三台web层服务器---》增加数据库服务器,对web服务器抽离出数据库层并指向数据库服务器---》加一个负载均衡服务器---》增加文件服务器,配置nfs服务
增加数据库层:
卸载掉三台web上的mariadb
systemctl stop mariadb
yum -y remove mariadb-server
找一个单独的机器做数据库服务器
setenforce 0
iptables -t filter -F
systemctl stop firewalld
yum install mariadb* -y
systemctl start mariadb
[root@localhost ~]# mysql -uroot -p # 执行下述命令
-- 1、创建库、表。项目中会用到
CREATE DATABASE testDB;
USE testDB;
create table messages(id int primary key auto_increment,text varchar(15)) charset=utf8mb4;
-- 2、创建账号xxx密码123,注意,此时需要创建的是远程账号,因此用%号
grant all on testDB.* to 'xxx'@'%' identified by '123';
flush privileges;
对于三台web
先停掉服务 pkill -9 uwsgi
修改配置文件将数据库指向刚刚建好的数据库服务器
vi /soft/flask-web-app-main/conf/settings.py
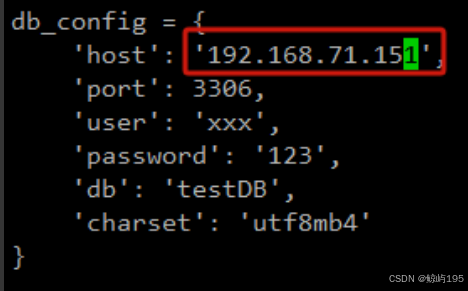
重启服务
uwsgi /soft/flask-web-app-main/uwsgi.ini
添加负载均衡
找一台机器做负载均衡服务器
setenforce 0
systemctl stop firewalld
iptables -F
yum install nginx -y
配置
mv /etc/nginx/nginx.conf /tmp/nginx.conf
cat > /etc/nginx/nginx.conf <<EOF
events {
worker_connections 1024;
}
http {
upstream web_app_servers {
server 192.168.71.207:8080 weight=1;
server 192.168.71.232:8080 weight=1;
server 192.168.71.231:8080 weight=1;
}
server {
listen 80;
location / {
proxy_pass http://web_app_servers;
# 注意:此处埋一颗雷,后面会炸
# 请求流程:客户端请求----》负载均衡-----》后端的web服务
# 问题点:后端的web服务拿到的访问者ip地址是负载均衡的地址,而不是客户端的,这会产生两方面影响
# 1、web服务器上的访问日志里看到的客户端ip都是负载均衡的、而不是真实客户端自己的,这个问题并不会导致程序运行出问题所以并不致命
# 2、web服务器上的程序可能需要根据客户端ip地址+协议来生成一些静态资源的url地址供给客户端二次请求,如果看不到真实的客户端ip,应用程序将会将地址拼接成http://web_app_servers/static/img/1.jpg的格式,导致访问失败
# 如何解决呢?如何能让web服务获取到的ip地址是真实的客户端ip而非负载均衡的呢?不着急,反正我们现在的应用程序都是测试程序、用不到真实的客户端ip,所以现在也并不致命,留着这颗雷,往后学吧。记住一点,带着真实的ip送给后端的web服务很重要就可以了,怎么做,后面再说
}
}
}
EOF
启动服务 systemctl restart nginx
增加文件系统层
增加一台文件系统服务器
# 1、初始化环境+安装
setenforce 0
systemctl stop firewalld
iptables -F
yum -y install nfs*
# 2、配置共享给外界哪个目录,并指定共享给哪个网段的机器用
vim /etc/exports
/data 192.168.71.0/24(rw,sync,all_squash)
# 3、导出
exportfs -a
# 3、创建共享目录
mkdir /data
# 4、把三台web中共享的代码放到/data里
[root@rockylinux ~]# ls /data/
flask-web-app-main
# 5、启动服务
systemctl start nfs-server # centos7中叫nfs
# 6、然后在三台web服务器必须先安装nfs支持,然后才能远程挂载过来
yum install nfs* -y
rm -rf /soft/*
mount -t nfs 192.168.71.206:/data /soft
# 7、重启启动
uwsgi /soft/flask-web-app-main/uwsgi.ini
# 8、访问负载均衡进行测试
# 9、
修改源代码后,如果不生效可以重启一下uwsgi
四、CDN层---网页缓存层详解
面对的问题:用户访问量暴增---》高并发的压力
1、网站的性能不足,访问慢(图片加载慢、网站响应慢)
2、数据量太大,资源占用过大
高并发优化思路
如何优化?---》如何应对高并发
高并发的问题总结下来就是两点问题:
1、高频读
解决思路-------让用户:少读、读缓存、就近读
少读:主要开发人员负责,
例如
1、雪碧图(降低网络io次数,将多次请求合并)
2、压缩数据(例如gzip压缩算法,降低io的数据量)
读缓存--相当于去自己最近的地方取
开发人员+运维人员
开发人员:控制redis作为mysql的缓存
运维人员:
配置响应头(与用户对接的负载均衡层)开启缓存(回复给浏览器让浏览器)把静态文件缓存到用户本地
就近读:
读本地:读用自己机器上的数据--》最近的
CDN:
2、高频写
解决思路------少写、漏斗写、buffer写---》多次合一次,减少io次数
CDN
CDN是什么--------------Content Distribution Network内容分发网络
内容:
网站的内容,可以分为两大类:
1、静态内容:在程序运行过程中,基本不变化
例如:图片、js、css、视频
2、动态的内容:在程序运行过程中,每次都是变化的、动态的(基本上都会与数据库交互)
例如:付费、转账
总结:
问题1:网站中静态内容多还是动态内容多?
egonlin.com ----> 静态的多
淘宝------------》静态、动态都很多
问题2:静态数据量大,还是动态数据量大?
静态数据量大
问题3:优化谁性价比最高
降低静态文件的访问压力,性价比最高
cdn主要帮我们优化静态数据的访问,但是cdn也可以优化动态数据
分发网络:指的是把内容发到离用户近的网络节点上
### 问题排查(无法访问)----->检查是否是客户端自己的问题,包是否能送给服务端 ping命令检测 (IP 网关 dns )--------->浏览器进行域名解析-------->检查服务端ip+端口号是否正常(三次握手是否建立成功)----------->服务端的内核防火墙是否阻拦--------->排查负载均衡服务器的nginx、端口(netstat/nginx配置文件)是否启用--------->检查是否能向web层发送数据(telnet)-------->检测web层(防火墙、访问检测)------->排查web层关联的文件服务器是否挂载,数据库是否能正常连接
为何用CDN
1、提升用户访问速度(就近读)
2、降低了集群的访问压力、资源使用量
注意:访问量很大的时候才能用cdn来加速,否则cdn会变成减速器(CDN会定期清理缓存,没有访问量用户需要不断地溯源,不如直接访问站点)
CDN服务器很少也会造成减速(用户需要去离自己很远的CDN服务器获取数据,距离可能会更长)
如何用CDN
储备知识:
1、本地dns:很多解析记录都是从别人那里拿过来缓存在本地---》不权威
2、权威dns/授权dns:存放的解析记录就来自于自己的本地文件配置着,不是从缓存拿的--》权威
本地DNS如果没有找到----递归、迭代向上查找至权威DNS
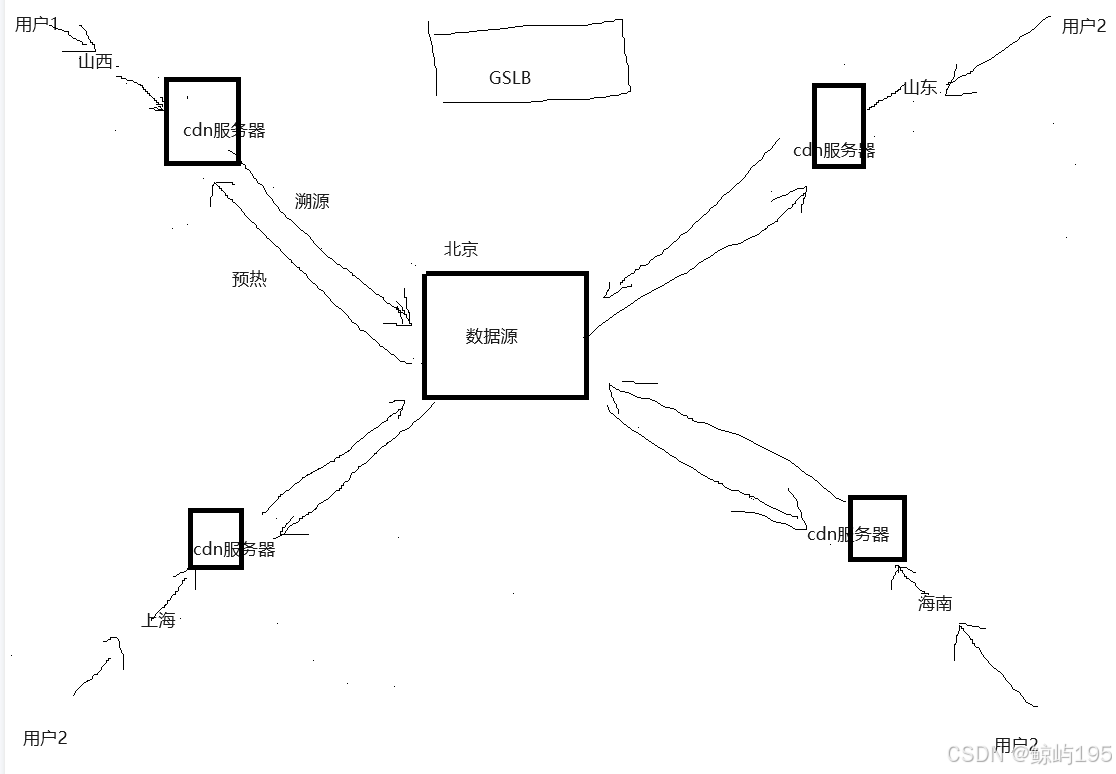
cdn运行原理---》cdn的核心组成部分:
1、GSLB(global server load balance全局负载均衡)
整个cdn的大脑
用户访问cdn时,先访问的是GSLB,然后GSLB会计算出
离用户最近那一台cdn服务,把该cdn服务器的ip地址返回给用户
用户拿着这个ip地址去访问
2、分布在全国/全世界各地的cdn服务器
负责具体干活的、响应用户的请求
3、数据源
可以有两种:
1、一块cdn服务器可以访问到大网盘
2、把你的站点整体当成一个数据源
4、配置权威dns
自己申请一个域名(cdn域名),作为所有静态请求的前缀:
cdn.egonlinhaifeng.com
接下来的目的就是:
控制域名cdn.egonlinhaifeng.com解析离用户最近那个dns的ip地址
然后为该域名添加解析
cdn.egonlinhaifeng.com -----》 GSLB(负载均衡) -----》算出一个离我最近的ip地址返回
在权威dns上添加一个CNAME的解析记录
从一个域名解析到另外一个域名
cdn.egonlinhaifeng.com---CNAME解析---->GSLB的域名(可对应多个cdn服务器IP)
## 用户发送第一个请求,负载均衡服务器拿到index.html,解析文件时,只有路径的请求默认在路径前加第一次请求使用的的ip和端口; 通过程序预留的cdn_url接口添加cdn域名从而修改文件服务器上的应用服务的配置文件templates/index.html, 在静态请求前添加新的ip地址(访问申请的CDN域名)可实现动态与静态请求分离,静态请求不会继续访问web层,转向对应的ip(CDN)去获取数据。
具体如何用?
可以分成两大类:
部分托管
域名解析
主域名:egonlin.com ---》集群的负载均衡ip地址
访问cdn的域名:cdn.egonlinhaifeng.com----CNAME解析----》GSLB的域名
数据源用什么-----------------一块大网盘(其中的数据可以自定义放入)
特点:
请求打到我们自己的负载均衡上,由我们自己的负载均衡做一个动静分离
针对静态请求被cdn分散压力
优点:
可定性强用一些,可以自己任意控制数据源中的数据
缺点:
访问大的情况,会对我们集群的负载均衡造成高压力
配置复杂
全站托管
域名解析
主域名:egonlin.com ------> CNAME解析----GSLB的域名
数据源用什么-------------你自己的整个站点
优点:
配置简单
抗压力性强
缺点:
可定制弱
都已经做完全站托管了,你自己的集群是否还需要做动静分离?
需要!
针对第一次访问cdn失败,溯源的场景,能走更短的路拿到数据(速度会更快),肯定也是有性能提升的
基于这一点:我们自己的集群还是要做一下动静分离----溯源的时候静态数据可以直接在负载均衡的服务器上取,速度更快
溯源:用户请求cdn服务器,命中数据失败,会请求数据源来获取数据,并在cdn中缓存
以备下次访问
预热:提前把数据源的数据推送到/上传到cdn服务器里
实验实现
实验思路:
实验步骤:
1、先准备好域名
主域名省略,一会直接拿着负载均衡的ip地址访问
申请好用于cdn转发的域名:
命名中最好带着cdn标识
域名必须要备案才能使用
如何申请域名:https://egonlin.com/?p=8894
域名备案:https://egonlin.com/?p=8966
2、数据源准备
1、申请一个大网盘-----》(阿里云oss)
2、往网盘里上传静态数据
static/img/1.jpg
static/css/a.css
结果-------------------------》得到一个数据源的域名:
egonlinhaifeng-bucket.oss-cn-beijing.aliyuncs.com
3、开通cdn,cdn的数据源配置为你的大网盘的域名
得到一个cdn的gslb的域名
xxxx.gslb.com
4、权威dns添加CNAME解析
egonlin.cn CNAME xxxx.gslb.com
实际:
egonlin.cn CNAME egonlin.cn.w.kunlunaq.com
5、配置我们自己的站点
### 修改应用的配置文件,指定cdn_url=http://cdn.egonlin.com(开发的任务)
如果程序没有留接口----需要去index.html中在静态请求前添加新的ip地址
也可以去负载均衡服务器上进行配置修改(速度相对较慢)----第一次请求拿到index.html后还要将请求再次发给集群的负载均衡服务器/etc/nginx/nginx.conf
## 网站访问量少,cdn服务器规模小有可能不增反降
cdn也可以发送动态内容
cdn客户--公司厂商 cdn用户--普通访问者
CDN衡量指标-----命中率(命中CDN缓存) 回源率(未命中资源出发回源动作)
CDN防盗刷---修改代码(开发)
提升命中率-----预热 合理设置缓存时间(静态更新周期长,动态短)
负载均衡 增加节点数量和覆盖范围
五、文件服务层详解
一、可用方案
NFS主----------rsync+inotify实时同步---------------NFS备
问题:解决了单点故障但是故障切换需要人为参与
DRBD+HeartBeat+NFS高可用文件服务器
特点:解决了单点故障、故障可以自动切换
问题:性能不足
兼顾:性能+高可用+数据安全性 ====》 分布式存储
ceph
MFS
Gluster
二、NFS
network file system:网络文件系统
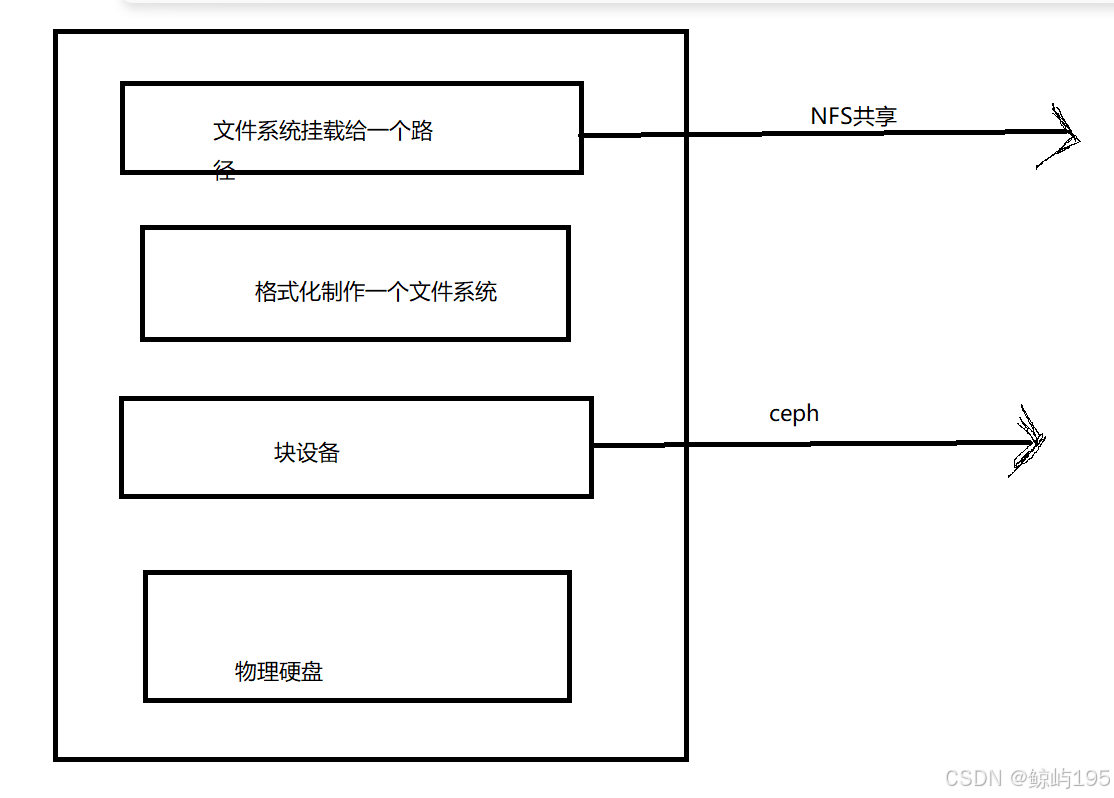
网络存储可以分为三大类:
1、文件存储:对外提供的文件 ----》NFS 拿到的是现成做好的文件系统
2、块存储:对外提供一个块设备(就是一块裸盘) 拿到的是硬盘,还需要自己制作文件系统
ceph可以提供块存储
# 相当于顺着网络给你的设备插上一个硬盘
3、对象存储:存储数据的单位是一个个的对象
### 文件存储和块存储底层都是一个个block块,用的都是文件
三、NFS架构图
CS架构
服务端:/etc/exports
/data 192.168.71.0/24(rw,all_squash,sync)
准备本地硬盘---》格式化制作文件系统---》挂载到一个文件夹---》nfs将文件夹对外共享
客户端:
mount -t nfs 服务端ip地址:/data /本地路径
# nfs基于TCP/IP连接服务端
客户端使用
读写数据------------》/本地路径 -----------------》nfs数据源
四、nfs使用详解
服务端
环境初始化
关selinux、防火墙
yum install nfs-utils rpcbind(centos7默认安装) -y
配置:/etc/exports
/data 192.168.71.0/24(rw,sync,all_squash)
重新导出/etc/exports文件里定义的所有NFS共享目录,一般在修改配置文件后使用使新的共享配置生效:
exportfs -a
创建目录
mkdir /data
启动服务
systemctl start nfs-server
验证配置
cat /var/lib/nfs/etab
客户端
# 客户端不用启动nfs
环境初始化
关selinux、防火墙
yum install nfs-utils rpcbind -y
showmount -e 服务端ip # 查看挂载点
mount -t nfs 服务端ip地址:/data /本地路径
df -h # 验证挂载
卸载的两种方式
umount /本地路径
umount 服务端ip地址:/data
强制取消挂载
umount -lf /backup
开机自动挂载
编辑fstab文件
vim /etc/fstab
服务端ip地址:/data /本地路径 nfs defaults 0 0
#验证fstab是否写正确
mount -a
# 文件夹可以比作水龙头,接到那个数据源就会展示哪个数据源的东西
# 客户端写入数据到nfs服务端文件中的两道枷锁-----nfs服务的权限,服务端文件夹的权限
all_squash----让所有远程连接的nfs客户端不受服务端文件权限的影响,统一映射为一个匿名的用户和用户组
sync----同时写入内存与硬盘
rw----赋予nfs服务读写权限
anonuid aningid ------指定NFS的用户uid和gid(所有主机都创建一份一模一样的用户便于管理) 文件服务器的共享目录也用 chown -R 重新设置成一样的
# 并行写入数据的冲突问题------应用程序应该考虑的问题
五、制作nfs的备份/镜像机
方案一:
rsync+inotify
inotify:帮们检测一个文件下的变动,一旦该文件夹下有变动,都可以检测到
rsync:帮我们把变动文件同步到远程的备份机上(对比增加,数据同步)
方案二:
sersync=rsync+inotify的封装
缺点:
故障切换要人手动完成
六:rsync的使用
yum install rsync -y
rsync命令即可以当客户端又可以当服务端------服务端和客户端需要同时安装,服务端不用启动
客户端:
优点:
1、rsync涵盖了scp、cp二者功能,即rsync同时支持本地拷贝与远程拷贝
2、scp与cp每次拷贝都是全量的,而rsync是增量的(io量小)
3、scp远程传输不支持断电续传,而rsync支持
4、灵活性、可配置性强
缺点:
1、命令行选项复杂
2、本身没有检测文本何时变化的能力
3、对cpu消耗比较大
服务端:
rsync --deamon # systemctl start rsyncd
对比:
scp ----------------ssh协议-----------------》sshd
rsync:
rsync----------------ssh协议-----------------》sshd(有泄露系统账号的风险)
本地--》远程:
rsync /a.txt 系统账号@1.1.1.111:/test ---用法和scp相同
远程--》本地:
rsync 系统账号@1.1.1.111:/test /a.txt
rsync----------------rsync协议-----------------》rsyncd
rsync /a.txt 虚拟账号@1.1.1.111::模块名 (在配置文件中规定模块名对应哪个文件)
# 用法同上
rsync--------------------ssh协议----------------------------->sshd服务
要求服务端必须开启sshd服务(默认都是开启的)
基于ssh协议通信的话:
1、使用的账号是系统账号
2、ssh协议支持密码登录、密钥登录
本地模式
cp命令只是本地复制,每次cp都会用源文件内容覆盖新文件,所以cp命令会修改文件时间属性
rsync可本地可远程,首次rsync与cp一样,后续rsync会对比两个文件的不同,只传输文件更新的部分,如果未更新,则rsync不会修改文件任何属性
[root@local ~]# rsync -r /etc/cron.d /test # 把文件夹cron.d拷贝到/test下
[root@local ~]# rsync -r /etc/cron.d/ /test # 把文件夹cron.d下的内容拷贝到/test下
[root@local ~]# rsync -r -R /src/./aaa/bbb/ccc /dst/ # 以点左侧为相对路径起始,拷贝其后目录
[root@local ~]# ls /dst/
aaa
#如果源文件与目标文件命名冲突, -backup防止被覆盖,目标位置下的同名文件会被重命名默认~结尾
# 可以使用"--suffix"指定备份后缀,例如
[root@remote ~]# rsync -r --backup --suffix=".bak" /egon111/ /egon222/
# rsync 拷贝的时候会先读取要拷贝的内容,然后读取目标文件内容并与其进行比对,拷贝不一样的内容
# 如果不确定 rsync 执行后会产生什么结果,可以先用`-n`或`--dry-run`参数模拟执行的结果,不真实执行
# 如果要使得目标目录成为源目录的镜像副本,则必须使用`--delete`参数,这将删除只存在于目标目录、不存在于源目录的文件
# rsync -av --include="[0-9].txt" --exclude='*' source/ destination 条件拷贝 --include必须在--exclude之前
# rsync -zavn --exclude={'1.txt','a/*'} /aaa/ /bbb/ 要拷贝例如/aaa/a/* (a文件夹下的所有内容) --exlucde里指定的路径只能是相对目录
远程模式
用法与scp非常像
#1、上传/推送push
scp -r /aaa root@192.168.71.115:/bbb
#2、下载/拉取pull
scp -r root@192.168.71.115:/bbb /aaa
#1、上传/推送push
rsync -avz /aaa root@192.168.71.115:/bbb
#2、下载/拉取pull
rsync -avz root@192.168.71.115:/bbb /aaa
指定端口
scp -r -P 2222 root@192.168.71.115:/bbb /aaa
rsync -avz -e 'ssh -p 2222' root@192.168.71.115:/bbb /aaa 一般情况下ssh的端口(22)都会改
# -p ssh指定端口 -P scp指定端口
注意点:
1、虽然服务端启动的服务是sshd而不是rsyncd,但也必须安装rsync
2、scp是全量传输(内部有优化机制),rsync都是增量传输
rsync--------------------rsync协议----------------------------->rsyncd服务(rsync --deamon)
与ssh协议的区别是,基于rsync协议传输采用的是虚拟用户,而不是系统用户
1、客户端与服务端都需要做
关selinux、防火墙
yum install rsync -y
2、配置服务端
配置文件 见博客
#可以限制用户所能操作的目录 设置模块例如[xxx]
#虚拟用户信息只是作为客户端登陆的验证手段,登陆完成后自动切换为配置中的用户身份进行操作(守护进程)-------安全性
3、做好准备工作(远程主机上----服务端)
useradd rsync -s /sbin/nologin -M 创建启动守护进程时的用户
[root@nfs ~]# cat /etc/rsync.passwd 配置虚拟用户
egon:123
[root@nfs ~]# chmod 600 /etc/rsync.passwd root用户可以查看
mkdir /egon_bak 为模块[xxx]创建真实的目录
chown -R rsync.rsync /egon_bak/
4、启动服务
systemctl start rsyncd 以root用户身份启动进程
虚拟用户egon-------------------》系统用户rsync-----------》操作xxx下的文件夹/egon_bak1
5、修改模块目录的属主与属组
chown rsync.rsync /egon_bak1
chown rsync.rsync /egon_bak2
6、测试使用
rsync -avz /aaa/1.txt egon@192.168.71.115::xxx/111.txt
rsync -avz /aaa/1.txt egon@192.168.71.115::yyy/111.txt
rsync -avz egon@192.168.71.115::yyy/111.txt /abc/1.txt
总结:
基于ssh认证: I:使用的是远程主机的系统账号与密码
II:通过ssh隧道进行传输
需要远程主机开启sshd服务
只需要双方安装rsync,不需要双方启动rsync,
类似于scp工具,同步操作不局限于rsync中定义的同步文件夹
基于守护进程rsync-daemon:
I:使用的是远程主机的虚拟账号,在rsync-daemon认证下,rsync可以 把密码写入到一个文件中。
II:在rsync-daemon认证方式下
只需要双方安装rsync,并且远程主机需要开启rsync进程,默认监听 tcp的873端口
同步操作只能同步到远程主机指定的目录下
三种备份思想:
全量:
特点:每次都是一次完整的“拷贝”
恢复:
只需要一个文件
差异:
特点:每次都是跟第一次全量备份比较,只备份差异部分
此刻目录内文件的变化:1.txt 2.txt 3.txt 4.txt 5.txt
第一次全量:1.txt 2.txt 3.txt
第二次备份:只备份了4.txt
第二次备份:备份4.txt、5.txt
恢复:只需要两个文件
先恢复全量,然后把你想恢复那个时间节点的备份文件恢复即可
增量:
特点:每次都是跟上一次备份比较,只备份差异部分
此刻目录内文件的变化:1.txt 2.txt 3.txt 4.txt 5.txt
第一次全量:1.txt 2.txt 3.txt
第二次备份:4.txt
第三次备份:5.txt
恢复:是一个链,沿途的备份文件都需要先恢复全量,再以此恢复沿途的增量备份,直到到达你想要恢复的时间点
综上,对比三种备份方案
1、占用空间:全量 > 差异 > 增量
2、恢复数据过程的复杂程度:增量 > 差异 > 全量

rsync的增量备份
rsync -a --delete --link-dest 上一次的备份 当前的状态 备份的目标位置
第一次全量:
rsync -a --delete /data/ /bak/111
第二次备份:(文件内容没变)
rsync -a --delete --link-dest /bak/111 /data/ /bak/222
/bak/222 文件中依然能看见第一次全量的数据---->rsync用的是增量备份的思想,但是为了方便它的备份在没有任何变动的情况下对之前没发生变化的文件做了硬链接,文件inode号未发生变化,所以在这次的备份中可以看到内容
------------> echo 3333 > /data/3.txt(增加内容)
第三次备份
rsync -a --delete --link-dest /bak/222 /data/ /bak/333
/bak/333中不但有增加的内容,还能看到原来的内容
------------> echo 1111 > /data/1.txt (修改现有的文件)
第四次备份
rsync -a --delete --link-dest /bak/333 /data/ /bak/444
1.txt属于“新文件”重新进行了拷贝,inode号发生变化
总结:与上一次一样会直接硬链接到上一次,不一样的才会创建新的,想要哪一天的数据就直接恢复到哪一天的(相当于全量但不占空间),大大降低了增量备份恢复的复杂度
总结rsync特点:
1、耗cpu、省io
2、不适合的应用场景(如数据库)
源目录频繁变动
不适合同步大文件
# rsync不支持远程到远程,scp支持
rsync原理----在拷贝数据的时候会现在目标服务器上建立一个隐藏文件进行拷贝,等拷贝完成的时候修改文件名完成对应拷贝; 如果拷贝过程被中断,再次拷贝时会再次拉起一个隐藏文件进行拷贝,之前拷贝的一部分依然存在,所以需要留有充足的存储空间。
NFS镜像站搭建:
rsync+inotify (rsync+crontab最小为分钟,无法实时同步)
# 选择使用rsync协议同步
1、搭建好一个主nfs,并编写监控并执行脚本(客户端)
共享文件夹/data
2、搭建好一个从nfs,与主nfs的配置一致(远程主机---服务端)
共享文件夹/data
# yum install epel-release* -y epel源上提供inotify-tools工具
yum install inotify-tools -y
依据走rsync协议的配置设置进行配置
#!/bin/bash
watch_dir=/data/ # 本地被监控目录
user="egon" # 虚拟用户
export RSYNC_PASSWORD=123 # 虚拟用户密码
module="xxx" # 远程模块名
ip=192.168.71.114 # 远程主机ip
# 先整体同步一次
rsync -azc --delete ${watch_dir} ${user}@${ip}::${module}
# 切换到被监控目录下,然后用inotifywait监控./目录,这样后期就可以用-R选项同步新增的子目录
cd $watch_dir
/usr/bin/inotifywait -mrq --timefmt '%Y-%m-%d %H:%M:%S' --format '%w%f:%Xe:%T' -e create,delete,modify,move,attrib,close_write ./ \
--exclude=".*.swp" | \
while read line
do
# $line的输出format为:文件路径:事件:时间
FILE=$(echo $line | awk -F: '{print $1}') # 获取文件的绝对路径
EVENT=$(echo $line | awk -F: '{print $2}') # 获取监控的事件
# 监控到对文件的下述行为后,只把文件同步到远端
if [[ $EVENT =~ 'CREATE' ]] || [[ $EVENT =~ 'MODIFY' ]] || [[ $EVENT =~ 'CLOSE_WRITE' ]] || [[ $EVENT =~ 'MOVED_TO' ]] || [[ $EVENT =~ 'ATTRIB' ]];then
rsync -azcR ${FILE} ${user}@${ip}::${module}
fi
# 监控到涉及到目录的改动,将目录同步到远端,例如用dirname ${FILE}获取目录
if [[ $EVENT =~ 'DELETE' ]] || [[ $EVENT =~ 'MOVED_FROM' ]];then
rsync -azcR --delete $(dirname ${FILE})/ ${user}@${ip}::${module} &>/dev/null
fi
done &
# 后台运行
# inotify用法详见博客 挂载参考nfs或linux详解--存储管理
# \ 换行符 | 管道符 read line 按行读
拓展:DRBD+HeartBeat+NFS高可用文件服务器
DRBD负责在主节点和备用节点之间实时同步数据块,确保两个节点的数据一致性;DRBD节点有 Primary(主)和 Secondary(从)两种角色。Primary 节点负责处理客户端的写入请求,并将数据复制到 Secondary 节点;Secondary 节点则接收并存储从 Primary 节点复制过来的数据。
HeartBeat负责管理和分配集群中的资源,并通过心跳机制监测节点状态,当主节点故障时会将 DRBD 设备在备用节点上设置为 Primary 角色,并将虚拟 IP 地址和 NFS 服务迁移到备用节点,实现故障的自动切换。
DRBD----块设备层面,监控磁盘设备上的块级数据变化
六、负载均衡层详解
引入负载均衡------大大提高了站点的抗高并发的能力,增加了灵活性与可靠性;可以做服务器的冗余备份,保障服务的正常运行
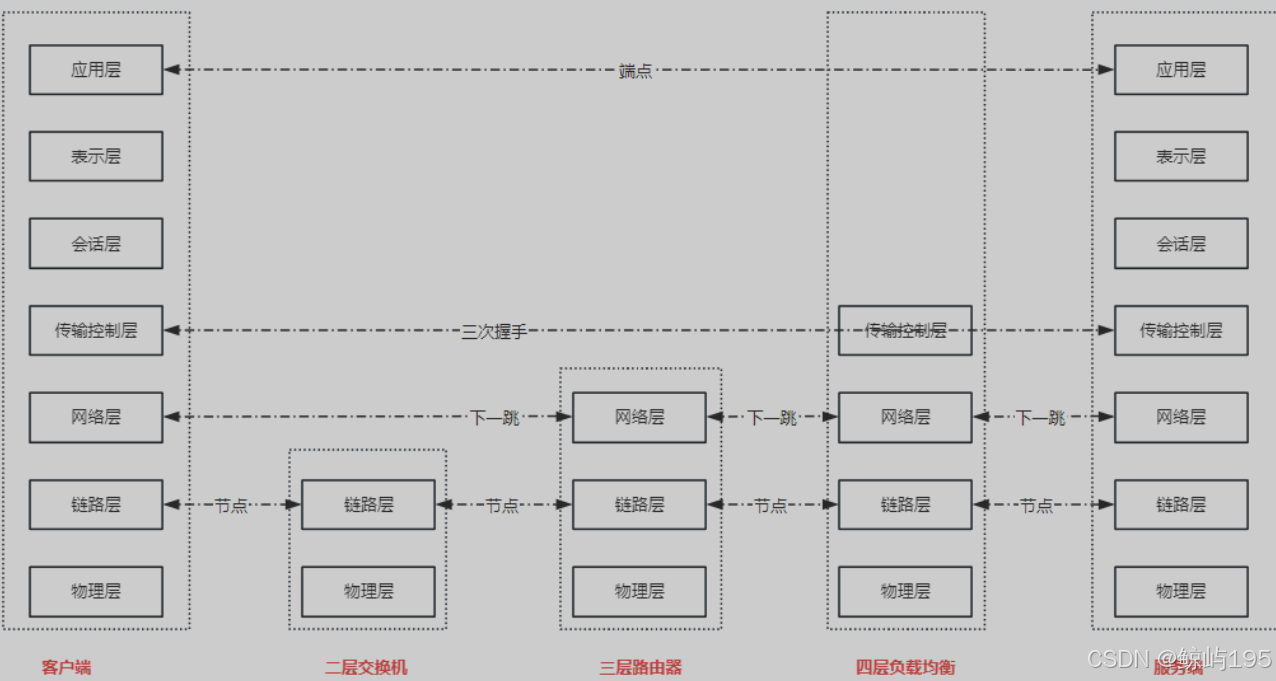
一、什么是四层与七层负载均衡
判定标准:osi七层协议,能解析到哪一层你就哪一层的设备
下定义:
1、客户端产生一个数据包,就好比是一个快递包,层层包裹七层
2、四层:解析到四层,看到的是tcp或udp协议,然后基于ip+port进行转发
3、七层:解析到七层,看到的是七层协议,例如http协议,然后url地址进行转发
### 四层负载均衡不能指定规则进行条件匹配,因为它无法访问到url地址,只有七层可以
强调:
1、一个完整的包,包含了七层,相当于一个快递被层层包裹了七层
2、为何要包这么多层?
为了让沿途帮忙转发的设备都能知道下一步该转发给谁
3、网络设备在解析包的时候,会读取某一层的内容,也可能会修改
但是该有几层还是几层
二、四层负载均衡的应用场景
用在要基于ip+port转发的场景
例如:
1、代理MySQL、redis (读写分离------------读写比例10:1)
2、四层代理七层来放大并发
### 四层也能直接代理web,但没必要
七层代理全部web
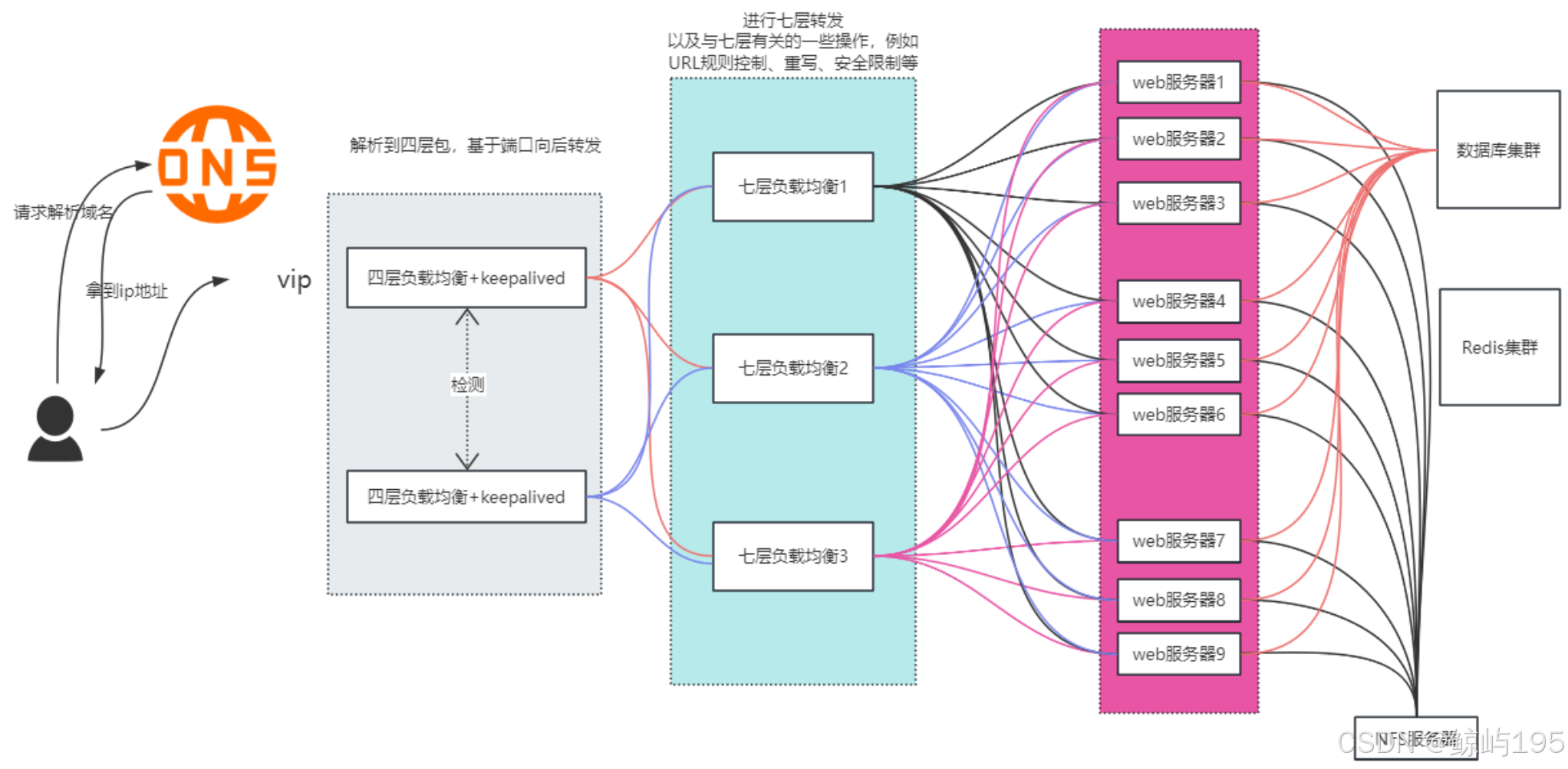
七层代理部分web
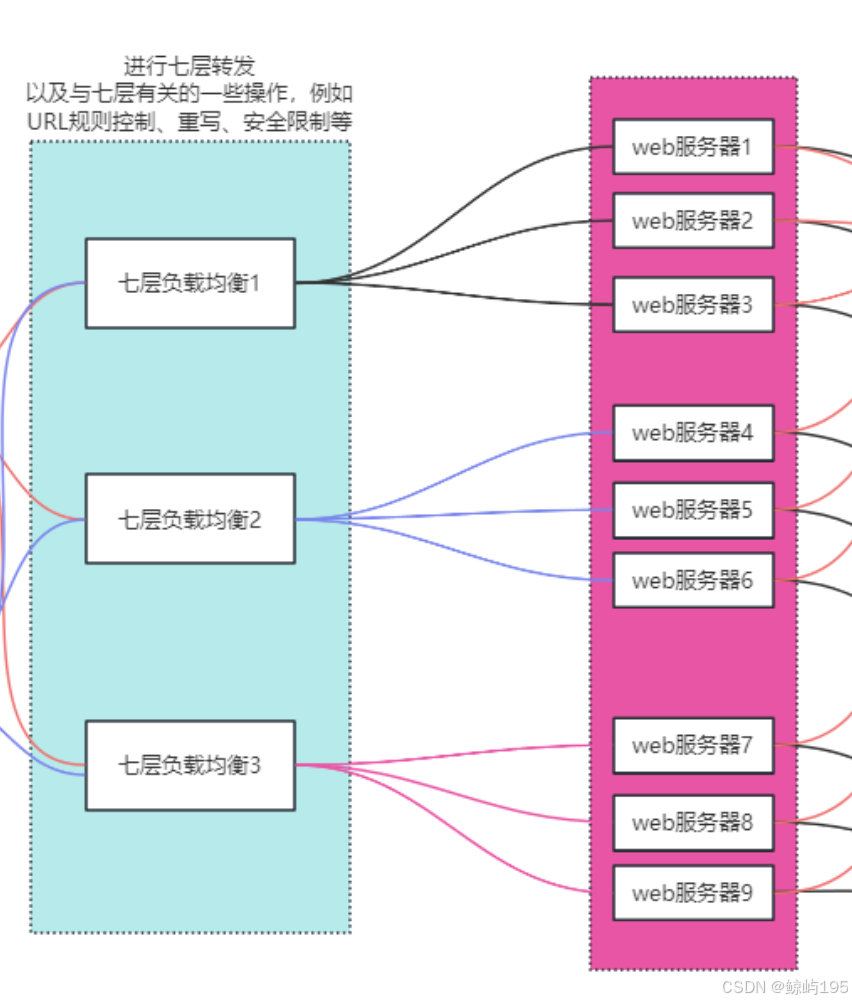
补充:
tcp:流式协议--》stream
udp:数据报协议
三、七层负载均衡的应用场景
用在要基于七层协议转发的场景
例如 BS架构的软件,应用层都是http协议
代理多台web服务器就需要用到七层负载均衡
四、负载均衡的软硬介绍
四层可选方案
1、F5(支持4层、7层)
2、LVS(支持4层,堪比F5)
七层可选方案
3、haproxy(4层、7层)
4、nginx(4层、7层、web服务)
五、配置与实现----nginx
七层配置
http {
……
upstream testserver {
ip_hash; # 负载均衡算法,后续会详细介绍,不写默认rr轮询(按照固定的顺序依次为每个请求或任务分配资源)
server 192.168.1.5:8080;
server 192.168.1.6:8080;
……
}
server {
…… #监听端口 负载均衡自己的端口号
location / { #匹配/下的请求==所有的请求路径 可指定规则进行条件匹配
……
proxy_pass http://testserver; #把请求代理到......
}
}
}
四层配置
stream { # stream----tcp
upstream my_servers {
least_conn; #调度算法
# 5s内出现3次错误,该服务器将被熔断5s(5s内不再给这台机器发)
server <IP_SERVER_1>:3306 max_fails=3 fail_timeout=5s;
server <IP_SERVER_2>:3306 max_fails=3 fail_timeout=5s;
server <IP_SERVER_3>:3306 max_fails=3 fail_timeout=5s;
}
server {
listen 3306; #负载均衡自己的端口号
proxy_connect_timeout 5s; # 与被代理服务器建立连接的超时时间为5s(三次握手)
proxy_timeout 10s; # 获取被代理服务器的响应最大超时时间为10s
proxy_next_upstream on; # 当被代理的服务器返回错误或超时时,将未返回响应的客户端连接请求传递给upstream中的下一个服务器
proxy_next_upstream_tries 3; # 转发尝试请求最多3次
proxy_next_upstream_timeout 10s; # 总尝试超时时间为10s
proxy_socket_keepalive on; # 开启SO_KEEPALIVE选项进行心跳检测--------保持长链接
proxy_pass my_servers;
}
}
注:如果你配置 steam 模块无效,请检查一下你使用的版本是否支持 stream,如果未内置该模块,你需要在编译的时候指定参数 --with-stream 进行编译使其支持stream代理。
查看nginx安装了哪些模块--------nginx -V # 注意用的是大写V,小写的v是查看nginx版本
yum install -y nginx-mod-stream # 只安装stream模块
yum install -y nginx-all-modules # 安装所有动态模块
编译安装: ./configure --prefix=/usr/local/nginx --with-openssl --with-stream # 启用/支持stream模块
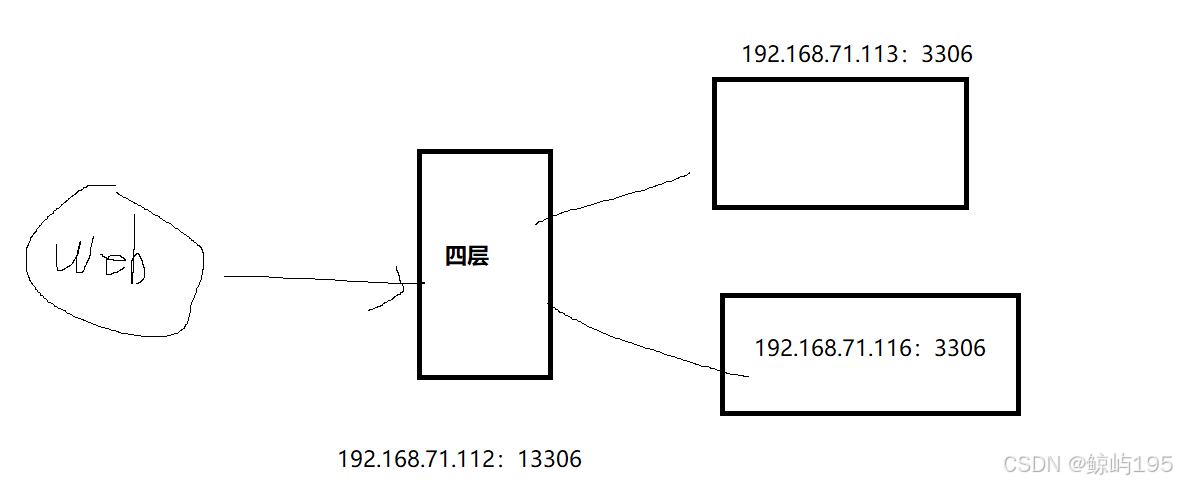
实验1:四层代理数据库(不完整的方案)
一、准备机器+环境
三台机器
关闭防火墙、selinux
配置静态ip
时间同步
二、机器规划
四层负载均衡:192.168.71.112 13306
数据库1: 192.168.71.113 3306
数据库2: 192.168.71.116 3306
三、先部署好数据库
准备好数据库1:
yum install mariadb* -y
systemctl start mariadb
systemctl enable mariadb
初始化数据:xxx.sql
# 示例:非交互方式执行sql
# mysql -uroot --password='' -e "show databases;"
# 导入sql
# mysql -uroot --password='' < xxx.sql (开发人员一般会给一个写了sql语句的文件)
# 非交互:mysql -uroot -p
(自己随便建一个)
create database testDB;
create table testDB.messages(id int(11),text varchar(15));
select * from testDB.messages;
准备一个远程账号
grant all on testDB.* to 'egon'@'%' identified by '123'; # %--->所有的IP都能登录
flush privileges;
准备数据库2:
同上一模一样的操作
四、准备四层负载均衡
yum install nginx -y
# nginx -V 验证是否开启了stream支持,--with-stream=dyamic
yum install -y nginx-mod-stream
# vim /etc/nginx/nginx.conf
worker_processes 4;
worker_rlimit_nofile 40000;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 8192;
}
stream {
upstream my_servers {
server 192.168.10.113:3306 max_fails=3 fail_timeout=5s;
server 192.168.10.116:3306 max_fails=3 fail_timeout=5s;
}
server {
listen 13306;
# proxy_pass后还是建议跟一个upstream,而不是直接只跟一个ip:port只代理一台机器(如proxy_pass 192.168.10.14:8080 这就只代理一个ip+port了,失去了负载均衡效果,负载均衡还是要搭配upstream一起用才对)
proxy_pass my_servers;
}
}
systemctl restart nginx
systemctl enable nginx
mysql -uegon -p123 -h 192.168.71.112 -P 13306 #远程连接测试
实验2:四层代理七层--》放大并发
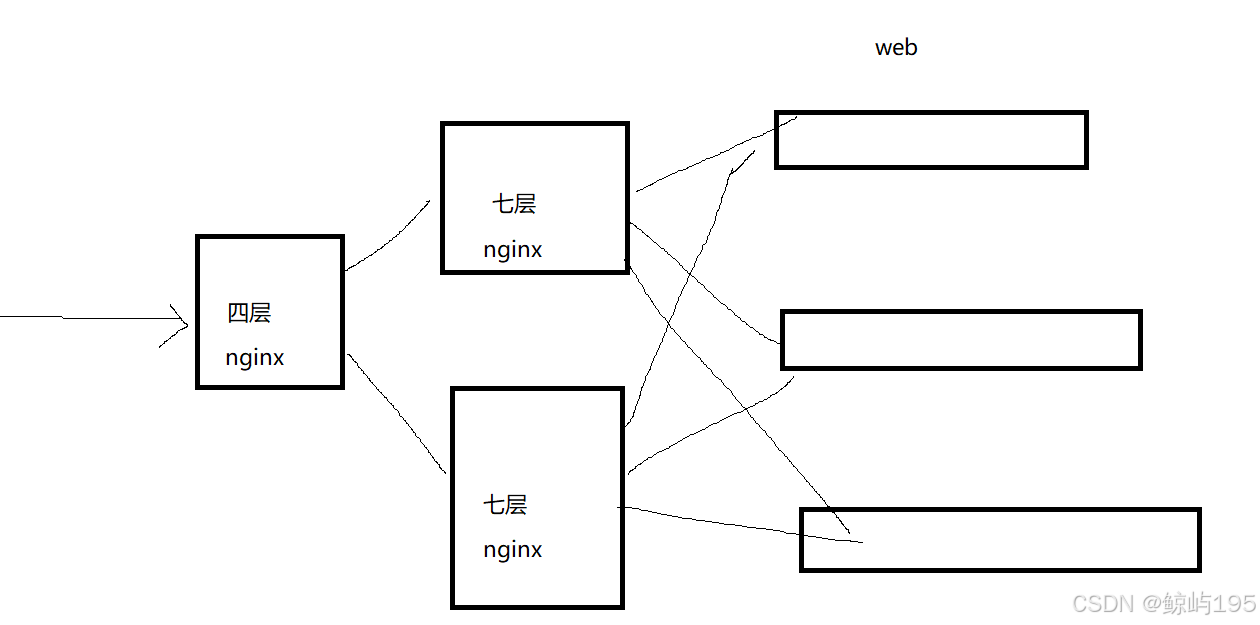
方案:
四层--》nginx
七层--》nginx
四层:192.168.71.115 9999
七层负载均衡01: 192.168.71.116 8081
七层负载均衡02: 192.168.71.111 8081
web01: 192.168.71.112 8080
web02: 192.168.71.113 8080
web03: 192.168.71.114 8080
一、初始化环境
所有机器
关闭防火墙、selinux
配置静态ip
时间同步
二、准备web服务器
web服务 + web应用(前端+后端)
web服务----》nginx
web应用----》前端:1.txt
web03:
yum install nginx -y
vim /etc/nginx/nginx.conf # 改listen 8080
echo "================web03" > /usr/share/nginx/html/1.txt
systemctl restart nginx
systemctl enable nginx
web02:
yum install nginx -y
vim /etc/nginx/nginx.conf # 改listen 8080
echo "================web02" > /usr/share/nginx/html/1.txt
systemctl restart nginx
systemctl enable nginx
web01:
yum install nginx -y
vim /etc/nginx/nginx.conf # 改listen 8080
echo "================web01" > /usr/share/nginx/html/1.txt
systemctl restart nginx
systemctl enable nginx
三、配置七层代理web服务器
七层负载均衡02
yum install nginx -y
[root@lb01 ~]# vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
http {
upstream web_app_servers {
server 192.168.71.112:8080 weight=1;
server 192.168.71.113:8080 weight=1;
server 192.168.71.114:8080 weight=1;
}
server {
listen 8081;
location / {
proxy_pass http://web_app_servers;
}
}
}
[root@lb01 ~]# systemctl restart nginx && systemctl enable nginx
七层负载均衡01
与上面完全一致
四、配置四层代理两台七层
yum install nginx -y
# nginx -V 验证是否开启了stream支持,--with-stream=dyamic
yum install -y nginx-mod-stream
# vim /etc/nginx/nginx.conf
worker_processes 4;
worker_rlimit_nofile 40000;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 8192;
}
stream {
upstream my_servers {
server 192.168.71.116:8081 max_fails=3 fail_timeout=5s;
server 192.168.71.111:8081 max_fails=3 fail_timeout=5s;
}
server {
listen 9999;
# proxy_pass后还是建议跟一个upstream,而不是直接只跟一个ip:port只代理一台机器(如proxy_pass 192.168.10.14:8080 这就只代理一个ip+port了,失去了负载均衡效果,负载均衡还是要搭配upstream一起用才对)
proxy_pass my_servers;
}
}
systemctl restart nginx
systemctl enable nginx
六、透传----nginx
1、查看一下沿途的网络情况
客户端(192.168.71.7)------》四层(115)-----》七层(116 111)----》web服务器(112 113 114)
192.168.71.7:53132 ------>192.168.71.115:9999--->.116--->.112
### 不进行透传日志记录只显示上一层的ip,不附带客户端真实ip
while true ;do netstat -tunalp |grep 8080 &>>/tmp/aaa.log; done #死循环抓取网络状态信息
2、自定义添加日志
tail -l /var/log/nginx/access.log 查询 # /etc/nginx/nginx.conf 配置文件包含日志格式
### 四层负载均衡是没有access的日志的,因为在nginx.conf的配置中,access的日志格式是配置在http下的,而四层负载均衡配置是在http以外的;如果需要日志则需要配置在stream下面
stream {
log_format proxy1 '$remote_addr $remote_port - [$time_local] $status $protocol '
'"$upstream_addr" "$upstream_bytes_sent" "$upstream_connect_time"';
access_log /var/log/nginx/proxy1.log proxy1;
upstream lb_servers {
server 192.168.71.12:9090 max_fails=3 fail_timeout=5s;
server 192.168.71.13:9090 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass lb_servers;
}
}
## 四层负载均衡日志----只能解析到第四层TCP协议的日志,建立连接后等连接断开才会出现
## web层与七层负载均衡的日志----可以解析到第七层,只要有请求出现就有日志出现
3、nginx透传真实的客户端ip
$remote_addr 代码里的处理逻辑是拿上游的ip底子
透传真实客户端ip两种方案:
1、改nginx的源代码
缺点:侵入源代码 、改造成本大
2、基于已经在用的公共协议,往里加入我们想要透传的数据
然后在需要拿到该数据的节点上,通过解析的模块从协议中取出来即可
### 因为web层的http协议是七层协议,所以到web层的时候客户端ip必须在七层中
X-Forward-For ------http协议为透传客户端ip预留的字段
基于七层协议透传
加入 七层负载均衡服务器-----/etc/nginx/nginx.conf
http { # 读取客户端ip并放入七层的http协议的字段中
upstream webserver {
server 192.168.71.14:8080;
server 192.168.71.15:8080;
server 192.168.71.16:8080;
}
server {
listen 9090;
location / {
proxy_pass http://webserver;
# -------------------》只加上下面这一段即可
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
#### upstream 和location可以写多个从而实现部分透传
}
取出 Web层服务器-----/etc/nginx/nginx.conf
直接从七层http协议的x-forward-for取出
展示-----在日志格式中加入对应字段(默认已存在)
基于四层协议透传
#读取三层(网络层)的客户端ip封装入四层传给七层负载均衡
四层-----》透传七层---》透传给web服务器
四层:把客户端真实的ip放到传输层
七层:从传输层里取出真正的客户端ip地址,放入http协议的x-forward-for
web服务:直接从http协议的x-forward-for取出
加入 四层负载均衡服务器-----/etc/nginx/nginx.conf
stream {
upstream lb_servers {
server 192.168.71.12:9090 max_fails=3 fail_timeout=5s;
server 192.168.71.13:9090 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass lb_servers;
proxy_protocol on; # ---------》新增这一条:代表开启proxy protocol 协议
}
}
取出又加入 七层负载均衡服务器------/etc/nginx/nginx.conf
server { # 读取四层负载均衡封装在四层的客户端ip并放入七层的http协议的字段中
listen 80 proxy_protocol; # 因为上游的四层开启了proxy协议,所以此处需要配合启用proxy_protocol的监听
set_real_ip_from 0.0.0.0/0; # 信任所有上游源,根据实际情况调整
# 如果设置成192.168.1.0/24,这样 Nginx 只会从 192.168.1.0/24 这个 IP 地址范围内的请求中提取真实 IP 地址,提高了安全性和日志的准确性-----定义可透传范围
real_ip_header proxy_protocol; # 将proxy_protocol获取的IP替换原$remote_addr值
location / {
proxy_pass http://web_app_servers;
# 增加下面一段
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
取出 Web层服务器-----/etc/nginx/nginx.conf
http {
log_format main '日志格式末尾增加两个段 "$http_x_forwarded_for" "$http_x_real_ip"';
access_log /var/log/nginx/access.log main;
server {
# 新增下面一段
set_real_ip_from 0.0.0.0/0; # 信任所有上游源,根据实际情况调整
real_ip_header X-Forwarded-For; # 将X-Forwarded-For字段包含的IP替换原$remote_addr值
#real_ip_header X-Real-IP; # 将X-Real-IP字段包含的IP替换原$remote_addr值
real_ip_recursive on;
......
}
七、haproxy
类比nginx的配置项
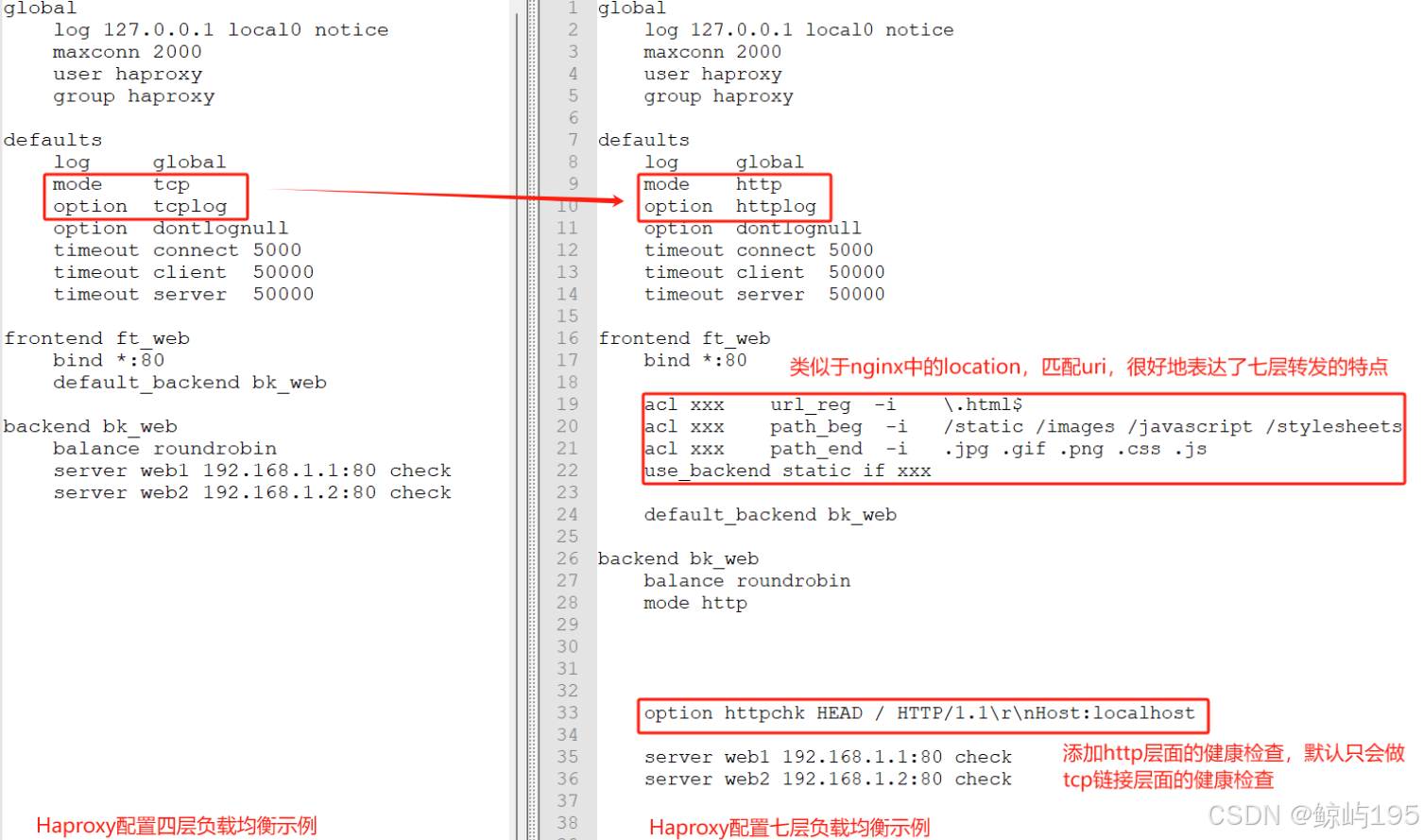
yum -y install haproxy
vim /etc/haproxy/haproxy.cfg
systemctl enable haproxy
systemctl start haproxy
systemctl status haproxy
netstat -tunlp |grep haproxy
负载均衡算法:

实现七层负载均衡
global # 全局参数
log 127.0.0.1 local2 info # 日志服务器
pidfile /var/run/haproxy.pid
maxconn 4000 #最大连接数(优先级低于后续的maxconn设置)
user haproxy
group haproxy
daemon #守护进程方式后台运行
nbproc 1 #工作进程数量 cpu内核是几就写几
defaults # 用于为其他配置段提供默认参数
mode http #工作模式是http (tcp 是 4 层,http是 7 层)
log global
retries 3 #健康检查。3次连接失败就认为服务器不可用,主要通过后面的check检查
option redispatch #服务不可用后重定向到其他健康服务器。
maxconn 4000 #优先级中
timeout connect 5000 #ha服务器与后端服务器连接超时时间,单位毫秒ms
timeout client 50000 #客户端超时
timeout server 50000 #后端服务器超时
listen stats # haproxy自带的状态监控服务
mode http
bind *:81
stats enable
stats uri /haproxy #使用浏览器访问 http://192.168.71.12:81/haproxy,可以看到服务器状态
stats auth egonlin:666 #用户认证
monitor-uri /monitoruri
frontend web # haproxy作为负载均衡的配置
mode http # 七层
bind *:80 # haproxy作为负载均衡对外暴漏的ip和端口--- * 任意ip
option httplog #日志类别 http 日志格式
### 实现根据指定规则进行条件匹配
acl xxx url_reg -i \.html$ #acl相当于nginx的location。url_reg定义自己的正则匹配url,-i忽略大小写,下同
acl xxx url_reg -i \/$ #针对访问末尾不加任何路径的情况例如http://xx.xx.xx
#acl xxx path_beg -i /static /images /javascript /stylesheets # path_beg匹配路径开头
#acl xxx path_end -i .jpg .gif .png .css .js # path_end匹配路径结尾
acl yyy path_end -i .css .js # path_end匹配路径结尾
use_backend static1 if xxx #如果满足acl xxx规则,则代理给后端服务器组static
use_backend static2 if yyy #如果满足acl yyy规则,则代理给httpservers组
default_backend httpservers #上述规则都匹配失败后默认的代理的组
backend static1
balance roundrobin
server static1_a 192.168.71.14:8080 check
backend static2
balance roundrobin
server static2_a 192.168.71.15:8080 check
backend httpservers
balance roundrobin
server myhttp1 192.168.71.16:8080 maxconn 2000 weight 1 check inter 1s rise 2 fall 2
#server myhttp2 192.168.71.17:8080 maxconn 2000 weight 1 check inter 1s rise 2 fall 2
# inter表示健康检查的间隔,单位为毫秒 可以用1s等,
# fall代表健康检查失败2回后放弃检查。rise代表连续健康检查成功2此后将认为服务器可用。
# 默认的,haproxy认为服务时永远可用的,除非加上check让haproxy确认服务是否真的可用。
实现四层负载均衡
global
log 127.0.0.1 local0 notice
maxconn 2000
user haproxy
group haproxy
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend ft_web # 四层负载均衡不能指定规则进行条件匹配,因为它无法访问到url地址
bind *:80 #任意ip+80端口均可访问
default_backend bk_web
backend bk_web
balance roundrobin
server web1 192.168.71.14:8080 check
server web1 192.168.71.15:8080 check
server web1 192.168.71.16:8080 check
haproxy的七层透传
加入
七层负载均衡服务器:
总体有效:
frontend web # haproxy作为负载均衡的配置
option forwardfor # ---------------------------> 加到这里就是对所有被代理的都有效
mode http # 七层
bind *:80 # haproxy作为负载均衡对外暴漏的ip和端口
option httplog #日志类别 http 日志格式
条件有效:
backend static1
#option forwardfor # ----------------------------> 加到这里就针对该backend下的服务器有效
#http-request set-header X-Forwarded-Port %{dst_port} # 这一行不是必须的
balance roundrobin
server static1_a 192.168.71.112:8080 check
取出 web层服务器------与nginx透传的配置方法相同
haproxy的四层透传
加入
四层负载均衡服务器:
frontend ft_web
bind *:8081
default_backend bk_web
backend bk_web
balance roundrobin
server web1 192.168.71.112:80 send-proxy # 将原始客户端IP透传到后端服务器
#server web2 192.168.71.113:80 send-proxy
取出
七层负载均衡服务器
frontend web # haproxy作为负载均衡的配置
bind *:80 accept-proxy # 启用Proxy Protocol
加入再取出-----同上的七层透传
haproxy的监控(七层)
根据七层的配置文件中对监控服务的配置---端口、路径、用户与密码
访问七层负载均衡服务器即可
八、haproxy(4)---nginx(7)---web层
只用修改端口进行对接即可
## 注意透传链路问题---要开启都开启,要关闭都关闭
### 四层负载均衡不能指定规则进行条件匹配,因为它无法访问到url地址,只有七层可以
九、LVS
一、架构方案
四层(haproxy)--------七层负载均衡(nginx、haproxy)------多台应用服务器
四层(lvs、硬件负载均衡)--------七层负载均衡(nginx、haproxy)------多台应用服务器
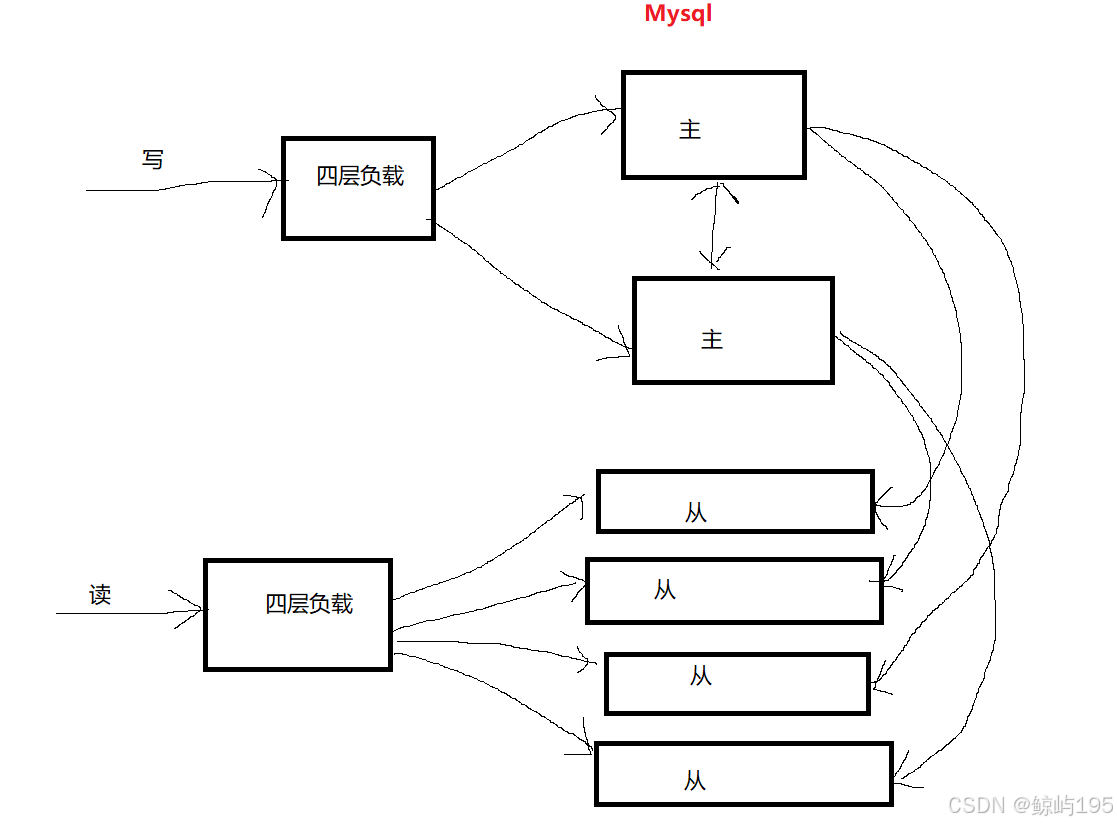
补充:数据库做集群
前提:
1、必须保证数据一致的(要做好主从)
2、而数据库的主从有多种方案
双主
双主+多从(每个主下挂多个从)
一主多从+MHA(一个主库挂掉后,MHA会帮你从所有从库里选举出一个新主,自动帮你从库都指向新主)
写操作------》主库
读操作------》从库
做好主从之后,下一件事就是要做:读写分离+负载均衡
lvs----》代理数据库
1、做负载均衡
负载多个主库----》提供一个写地址(lvs机器的地址)
负载多个从库----》提供一个读地址(lvs机器的地址)
2、应用软件
代码需要支持两个地址(读写操作要分开用不同的地址)
数据库中间件----》代理数据库
1、中间件会帮我们做好读写分离,即中间件对外只提供一个地址,同时也起四层负载均衡的作用
2、应用软件
代码只需支持一个地址就行(读写操作都用这一个地址)
--------------------------》分离
解决架构问题的一种重要的思想:分离(把问题细分出来,抽离成单独的层)不断地解耦合
二、lvs的构成
两部分:
ipvs(内核态):负责核心的转发工作,直接工作内核层的netfilter上
ipvsadm(用户态):是一个命令行工具,用添加ipvs规则-
只是在添加规则时用一下ipvsadm工具,
转发根本不会用到ipvsadm
特点:
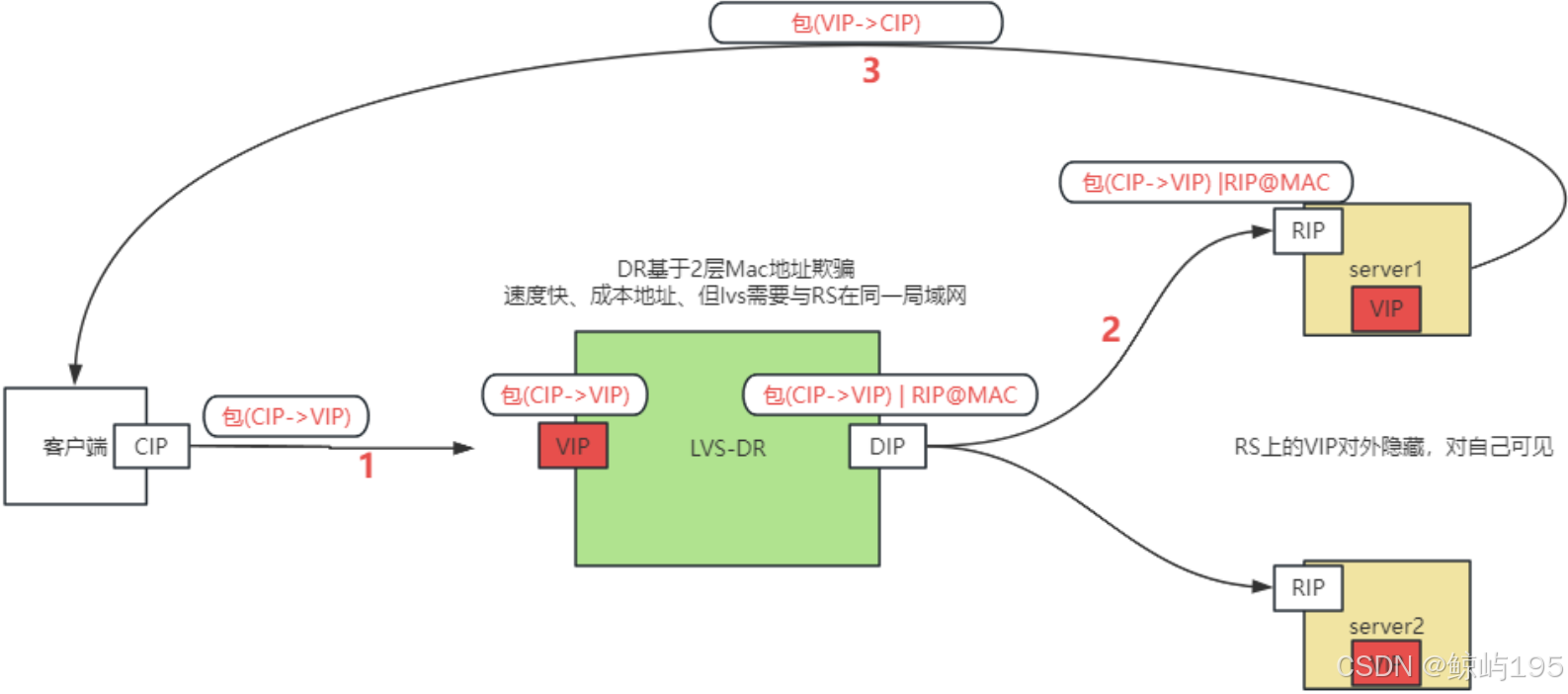
主要用lvs dr模式
1、dr是通过mac地址欺骗进行转发,mac地址是二层的概念,那为何将lvs称之为四层负载均衡?
转发是一个复杂的过程
数据来到lvs dr之后,怎么发出去是通过mac地址
但是在发之前,要计算出应该发给谁(负载均衡),计算发给要用负载均衡算法
负载均衡算法least_conn------》链接-----》ip+port---》传输层(四层)
2、lvs-dr
要求负载均衡与被代理的机器必须在同一个二层网络里
3、lvs为何快:
1、负责转发工作的ipvs是工作在内核态的,不需要经历频繁的用户态与内核态的切换
2、针对如果用lvs dr模式的话,请求包经过lvs,响应包不走lvs了,而是直接回给客户端
三、lvs的工作模式
DR模式
NAT
TUN:打破网络的限制
Full-NAT
储备专业术语:
CIP: 客户端的ip地址
VIP:virtual ip 虚拟的ip地址 --------------》(配置在负载均衡、后端被代理的服务器上)
只要不是固死给某一台机器配置的ip地址,那都可以叫VIP
DIP: 配置在负载均衡,负责与后端的被代理服务通信的地址
RIP:配置在被代理的服务器上
DS:director server,即LVS负载均衡器
BDS:即backup diretor server
RS:real server指的是被负载均衡代理的服务器
配置概述
负载均衡lvs
1、配置地址
负载均衡上的vip与dip都需要走网络流量,所以
VIP与DIP都需要配置在走网络流量的物理网卡,不能配置在lo上,但是VIP与DIP
是可以配置在一块走网络流量的网卡上的
2、用ipvsadm添加ipvs转发规则
被代理的机器rs
1、配置地址
rs机器上的RIP需要接收网络流量
rs机器上的VIP是不需要走网络流量的
RIP:应该配置在走网络流量的物理网卡上
VIP:应该配置在不走网络流量的物理网卡上---》lo网卡
2、关闭arp响应(针对vip冲突的解决方案)
LVS-DR模式的工作流程
前提:
VIP应该是公网ip还是私网ip-----私网
问:你的服务器上能不能配置上公网ip地址?
答:不能,你的机器上只能配置私网ip,公网ip
是在运营商的网络上的地址
问:既然你的机器上配置的都是私网ip,那外网的用户如何访问到你呢?
公网ip------------(映射)--------------私网ip
机器是托在在机房----》找机房帮你做
如果是云主机--------》每个机器都有自己的公网ip
外部的流程: 包抵达负载均衡之前做的事情
客户端来自于外网---》跨公网访问到我们的机器vip
客户端私有IP---->客户的公网ip(CIP)-----》集群对外暴漏的公网ip----》VIP
172.168.10.11---> 56.100.200.101---------> 202.200.191.111--------->192.168.71.200
总结:此时CIP是客户端公网ip
客户端来自于内网:
总结:此时CIP就是客户端的私网IP
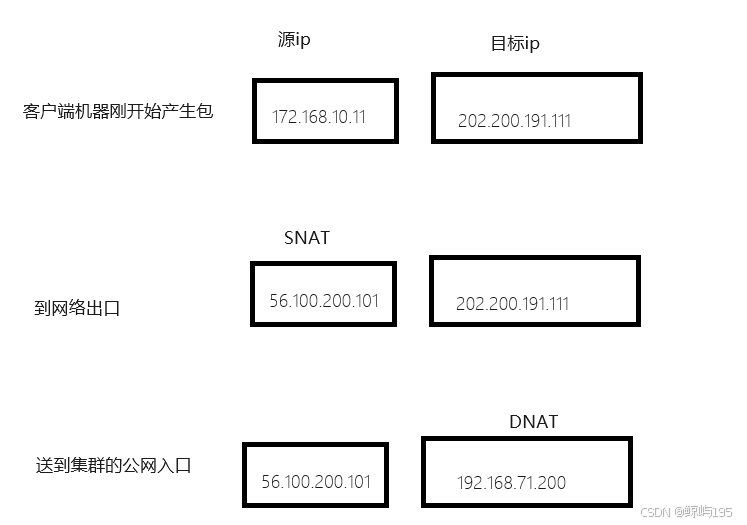
包抵达负载均衡后的处理流程:
1、收到包(CIP->VIP)
2、做负载均衡:
1、找出一台机器
根据配置的ipvs规则来选择机器
规则里包含:
1、调度算法
2、转发给哪些机器的iP+PORT
2、把包发过去
不改源ip与目标ip
而是 更改包的目标mac地址改成上算法挑选出的那台机器的mac地址
3、目标RS收到包之后
发现目标mac是自己,然后继续解析
解析到ip层(linux机器判断目标ip是否是自己,会从所有网卡里进行比对包括lo网卡,如果是就认为该包是我自己,否则就丢弃该包),
发现目标ip就是配置在自己机器上lo网卡上的vip地址,确定包就是给自己的(欺骗系统内核)
就开始回包---》当然是给源ip回了(源ip就是cip,始终没变过)
所以回包(VIP------》CIP)----包从RIP发送回去
## rs机器上的vip不走网络流量,关闭arp,仅仅只起欺骗作用
## lvs在去的时候依靠二层转发,回来的时候依靠三次握手的链接建立
## 集群内每台机器都必须有vip才行,但负载均衡上的vip是配在真网卡上的,rs服务器是本地回环lo
四、lvs的部署
场景1
lvs四层--------》被代理机器(例如数据库)
场景2:
lvs四层---------》七层负载均衡--------》web服务器(放大并发)
场景1:
1、环境准备(所有机器)
setenforce 0
systemctl stop firewalld
配置静态ip
配置时间同步
2、主机规划(所有机器必须在一个二层网络里)
VIP:192.168.71.200(走网络流量的)
DIP:192.168.71.115
web01(nginx+静态页面): 192.168.71.112:8080
web02(nginx+静态页面): 192.168.71.113:8080
web03(nginx+静态页面): 192.168.71.114:8080
2.1、部署好三台web服务器
web01部署
yum install nginx -y
vim /etc/nginx/nginx.conf
listen 8080;
systemctl restart nginx
为3个web准备应用程序:用1.txt
分别写入
echo "---------------------web01" > /usr/share/nginx/html/1.txt
echo "---------------------web02" > /usr/share/nginx/html/1.txt
echo "---------------------web03" > /usr/share/nginx/html/1.txt
测试访问:
curl http://192.168.71.112:8080/1.txt
curl http://192.168.71.113:8080/1.txt
curl http://192.168.71.114:8080/1.txt
3、lvs四层负载均衡部署(在192.168.71.115这台机器上部署)
1、安装并启用lvs
内核模块:ipvs
用户态的工具:ipvsadm
# 1、安装ipvsadm等相关工具
yum -y install ipvsadm ipset sysstat conntrack libseccomp
# 2、配置加载
cat > /etc/sysconfig/modules/ipvs.modules <<"EOF"
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules};
do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
2、配置VIP、DIP
#1、需要特别注意的是,虚拟ip(VIP)地址的广播地址是它本身,子网掩码是255.255.255.255
ifconfig ens36:0 192.168.71.200 broadcast 192.168.71.200 netmask 255.255.255.255 up
#2、添加路由规则
route add -host 192.168.71.200 dev ens36:0
#3、启用系统的包转发功能
echo "1" >/proc/sys/net/ipv4/ip_forward # 因为基于二层转发这个开不开不影响,建议习惯开着
3、添加负载均衡规则
# 强调强调强调:LVS本身不支持将请求的目标端口从一个端口转换到另一个端口,所以
# ipvsadm -a -t 192.168.71.200:6666 -r 192.168.71.112:8080 -g # 这种添加方法是错误的,必须端口一致
ipvsadm -C #清除内核虚拟服务器表中的所有记录
ipvsadm -A -t 192.168.71.200:8080 -s rr #添加端口 # -s rr表示采用轮询策略。
ipvsadm -a -t 192.168.71.200:8080 -r 192.168.71.112:8080 -g #添加服务器节点,-g表示指定LVS 的工作模式为直接路由模式
ipvsadm -a -t 192.168.71.200:8080 -r 192.168.71.113:8080 -g #添加服务器节点
ipvsadm -a -t 192.168.71.200:8080 -r 192.168.71.114:8080 -g #添加服务器节点
ipvsadm -Ln #查看节点状态,加个“-n”将以数字形式显示地址、端口信息
### 可以增加多个端口,写多组路由实现规则匹配-------注意前后端口一致性
4、配置RS服务器(三台web上做)
4.1 在本地回环网卡lo上配置vip(不接网络流量,只用于欺骗)
ifconfig lo:0 192.168.71.200 broadcast 192.168.71.200 netmask 255.255.255.255 up
route add -host 192.168.71.200 dev lo:0
4.2 关闭arp响应
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore #临时修改
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
cat >> /etc/sysctl.conf << EOF #永久修改
net.ipv4.ip_forward=1
net.ipv4.conf.lo.arp_ignore=1
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.lo.arp_announce=2
net.ipv4.conf.all.arp_announce=2
EOF
sysctl -p #使用修改生效
5、测试
只在做测试前做一件事:
把web服务器nginx服务的keepavlie_timeout设置为0(防止长链接影响刷新结果,生产环境不改) systemctl restart nginx
方式一:用浏览器访问测试
方式二:用curl命令(curl访问完立即关闭,不会有长链接)
curl http://192.168.71.200:8080/1.txt
场景2:
lvs四层------》七层负载均衡--------》web服务器
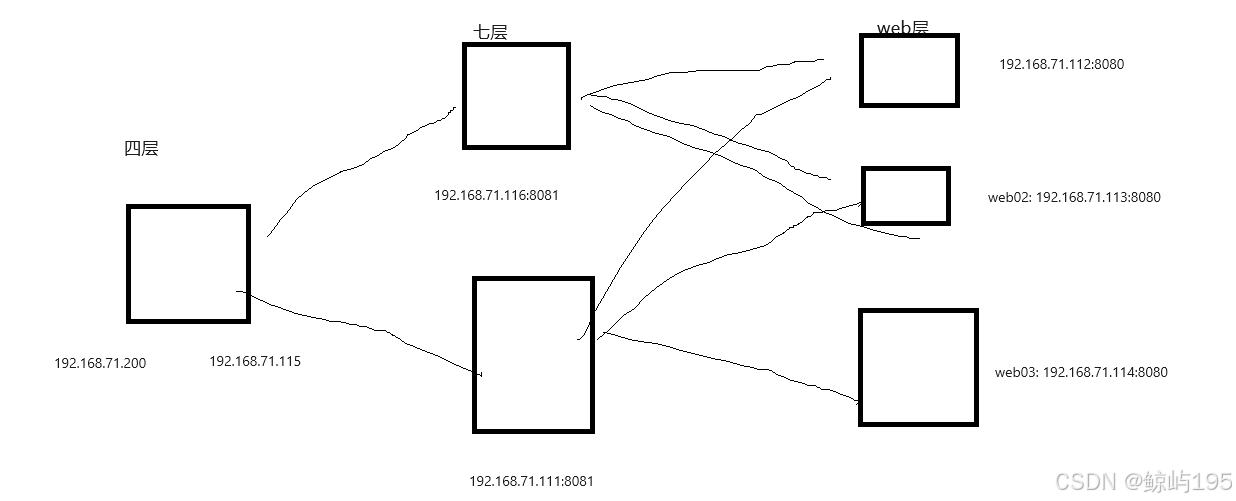
RS应该是谁?
答案:七层负载均衡
# 七层负载均衡做了RS和DS在一个二层网内,后面的web层网络随意
1、环境准备
关selinux、firewalld
配置静态ip
同步时间
2、主机规划
VIP: 192.168.71.200
四层(lvs-dr):192.168.71.115
七层负载均衡01: 192.168.71.116:8081
七层负载均衡02: 192.168.71.111:8081
三台web服务器
web01: 192.168.71.112:8080
web02: 192.168.71.113:8080
web03: 192.168.71.114:8080
2.1 配置三台web服务器----同上
2.2 部署两台七层负载均衡
七层负载均衡01
yum install nginx -y
配置
[root@lb01 ~]# cat /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
http {
upstream web_app_servers {
server 192.168.71.112:8080 weight=1;
server 192.168.71.113:8080 weight=1;
server 192.168.71.114:8080 weight=1;
}
server {
listen 8081; # 强调:这里个的配置直接就监听端口,我们之前的课程中在其末尾加的proxy_protocol一定要去掉
location / {
proxy_pass http://web_app_servers;
}
}
}
systemctl restart nginx
七层负载均衡02-----同上
2.3 部署四层负载均衡
1、安装ipvsadm并加载ipvs模块
2、配置vip、dip
3、添加负载均衡规则------端口必须一致
ipvsadm -C #清除内核虚拟服务器表中的所有记录
ipvsadm -A -t 192.168.71.200:8081 -s rr #添加端口 # -s rr表示采用轮询策略。
ipvsadm -a -t 192.168.71.200:8081 -r 192.168.71.116:8081 -g #添加服务器节点,-g表示指定LVS 的工作模式为直接路由模式
ipvsadm -a -t 192.168.71.200:8081 -r 192.168.71.111:8081 -g #添加服务器节点
ipvsadm -Ln #查看节点状态,加个“-n”将以数字形式显示地址、端口信息
### 可以增加多个端口,写多组路由实现规则匹配-------注意前后端口一致性
2.4 配置Real server(在七层负载均衡,而不是web)
七层负载均衡01
1、在本地lo网卡配置vip
ifconfig lo:0 192.168.71.200 broadcast 192.168.71.200 netmask 255.255.255.255 up
route add -host 192.168.71.200 dev lo:0
2、关闭arp响应
cat >> /etc/sysctl.conf << EOF
net.ipv4.ip_forward=1
net.ipv4.conf.lo.arp_ignore=1
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.lo.arp_announce=2
net.ipv4.conf.all.arp_announce=2
EOF
sysctl -p #使用修改生效
2.5 测试
curl http://192.168.71.200:8081/1.txt
五、LVS透传
四层直接代理-----无需任何配置,本身自带透传效果(源IP不会发生变化)
四层代理七层代理web层-----七层能拿到源IP,但七层代理到Web层会丢失客户端ip
### 增加基于七层协议的透传即可
十、总结
nginx的日志功能十分强大,haproxy对日志的支持不友好

负载均衡实现动静分离:
用户的请求发出之后,url有cdn域名(通过在程序预留的cdn_url端口添加cdn域名)的话直接打向cdn服务器(热点,访问频率高的静态请求),没有的话继续按负载均衡服务器(nginx、haproxy、lvs等)里写的规则进行匹配实现动静分离
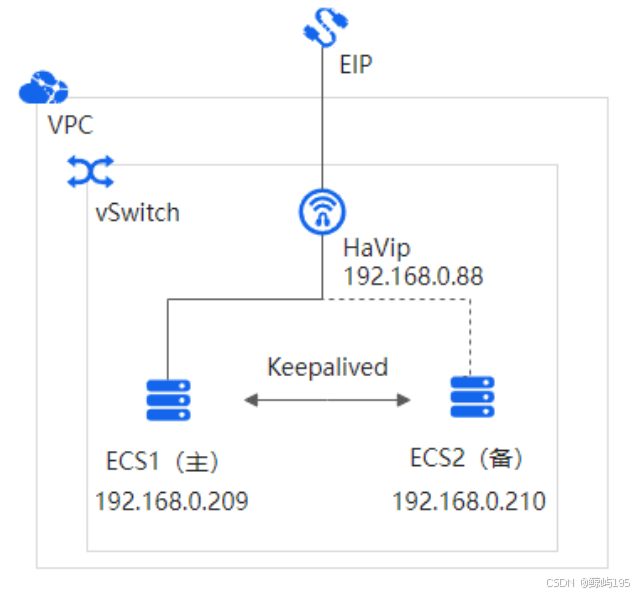
十一、keepalived
keepalived是什么?
是一个开源软件,用来解决集群中的单点故障问题,实现高可用
主+keeaplived
|
vip |
|
从+keepalived
vip:虚拟ip,只要不是固定死某台机器的ip,都可以叫vip
但是vip是配置在机器之上的ip地址
强调:
配置在机器上的ip地址能是公网ip吗?
不能,vip一定是私网ip然后配置自己的私有设备上的
外部想访问:
公网ip-------(映射)-------私有vip
keepalived的使用场景?
lvs负载均衡+keeaplived
nginx负载均衡+keeaplived
haproxy负载均衡+keeaplived
为何要用keepalived
解决单点故障(vip漂移)
keepalived的工作原理
keepalived是底层是基于vrrp协议工作的
1、vrrp(Virtual Router Redundancy Protocol),即虚拟路由冗余协议。
2、我们用vrrp协议管理服务器,那vrrp便会把多个服务器组成一个组
主+keeaplived
|
vip vrrp协议
|
从+keepalived
|
vrrp协议
|
从+keepalived
同一个组内维护的vip只能有一个
补充:如果是不同的组,那每个组内都有一个vip
3、在一个主机组里有两大类角色
(1)master
(2)backup
master节点会朝着自己所在的组发送vrrp协议通告(广播包)
该组内的多个backup如果收到了该vrrp包就认为master活着呢,就不会篡位
如果没有收到,keepalived就会认为master死掉了,就会从多个backup里找出一个作为新主(篡位)
篡位的同时,vip会漂移到新主上
补充:
抢占式(preempt):主挂掉后,vip漂到新主上,当旧主重新修复后会重新抢回vip-----两次切换
非抢占式(nopreempt推荐):主挂掉后,vip漂到新主上,当旧主重新修复后不重抢回vip,只会做一个从---1次切换 ----前提:所有服务器都指定为从,如果指定了主,优先级会高于非抢占式的设定,设置的主挂掉再恢复后会再次变为主
注意点:
1、VRRP协议依赖局域发送LAN(局域网)多播或广播包,所以要求被keepalived管理的机器必须处于同一个LAN内才行
### vlan----虚拟局域网,交换机通过识别数据帧中的 VLAN 标签来判断该数据帧属于哪个 VLAN从而判断是否转发或做其他处理,减小广播域 wlan----无线局域网
2、vvrp通告的消息是直接封装在网络层(三层)的IP包中发送,不需要用专门的网络设备来解析
3、不需要有专门的物理心跳线,在主、从之间相当于有一根虚拟的心跳线
# 对于云服务器:申请(阿里云)
部署(单主与多主)
3、单主(单组)keepalived部署
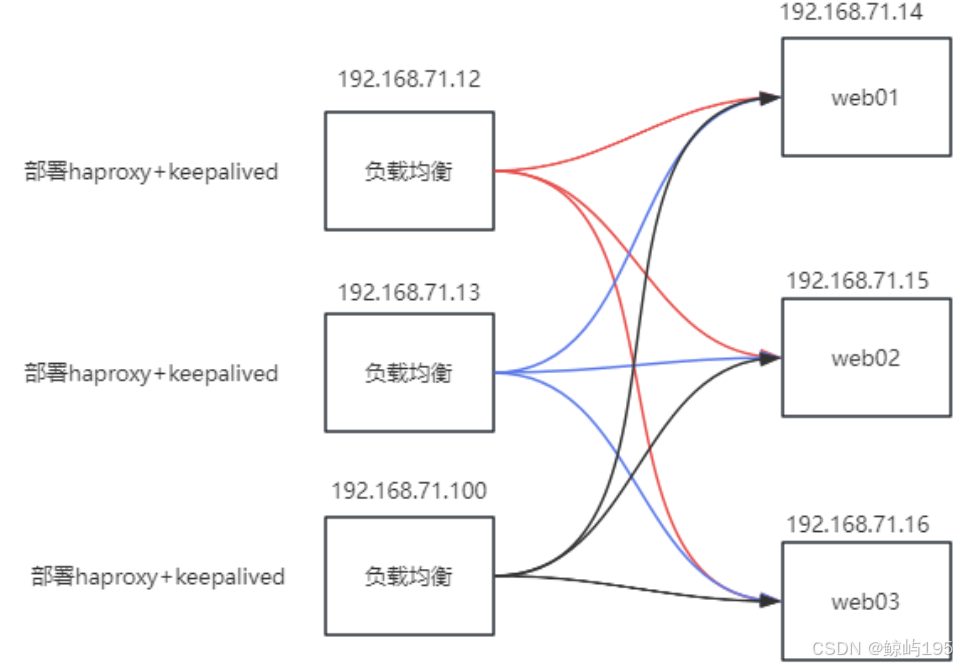
3.1 主机规划
三台web:
web01: 192.168.71.112:8080
web02: 192.168.71.113:8080
web03: 192.168.71.114:8080
七层负载均衡
负载均衡01:192.168.71.116:8081
负载均衡02:192.168.71.111:8081
负载均衡03:192.168.71.115:8081
3.2 初始化环境
关selinux
关firewalld
配置静态ip
配置时间同步
3.3 准备web
web01:
yum install nginx -y
vim /etc/nginx/nginx.conf
listen 8080;
echo '-----------web01' > /usr/share/nginx/html/1.txt
systemctl start nginx
3.4 准备七层负载均衡
负载均衡01
yum install nginx -y
[root@xxx ~]# cat /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
http {
upstream web_app_servers {
server 192.168.71.112:8080 weight=1;
server 192.168.71.113:8080 weight=1;
server 192.168.71.114:8080 weight=1;
}
server {
listen 8081;
location / {
proxy_pass http://web_app_servers;
}
}
}
[root@db ~]# systemctl restart nginx
3.5 解决我们集群架构中单点故障问题
在三个七层负载均衡上安装keepalived
yum install keepalived -y
修改三个七层负载机上的keepalived配置
注意容易出错的点:
1、优先级要设置的不同(按大小比较)
2、网卡名对应成自己机器上的
补充:
主挂掉的两种情况:
整个机器宕机:keepalived必然死掉了,必然不可能发出vrrp通告
机器没挂但工作的软件(nginx)挂掉:此时应该停掉keepalived,主动禁止发送vrrp通告
配置如下
cat > /etc/keepalived/keepalived.conf << EOF
! Configuration File for keepalived
global_defs {
script_user root
enable_script_security
}
vrrp_script chk_nginx { # 自定义的脚本
# 1、定时检测被高可用的服务的存活状态
script "/etc/keepalived/check_port.sh"
# 2、每隔3s运行一次上面的脚本
interval 3
# 3、如果脚本运行失败(双重保障),则降低权重-20,配置下面的设置的priority值基础上减
# 一旦priority发生变化,基于下述advert_int的设置1s内vrrp就能检测到然后完成主备切换
weight -20
}
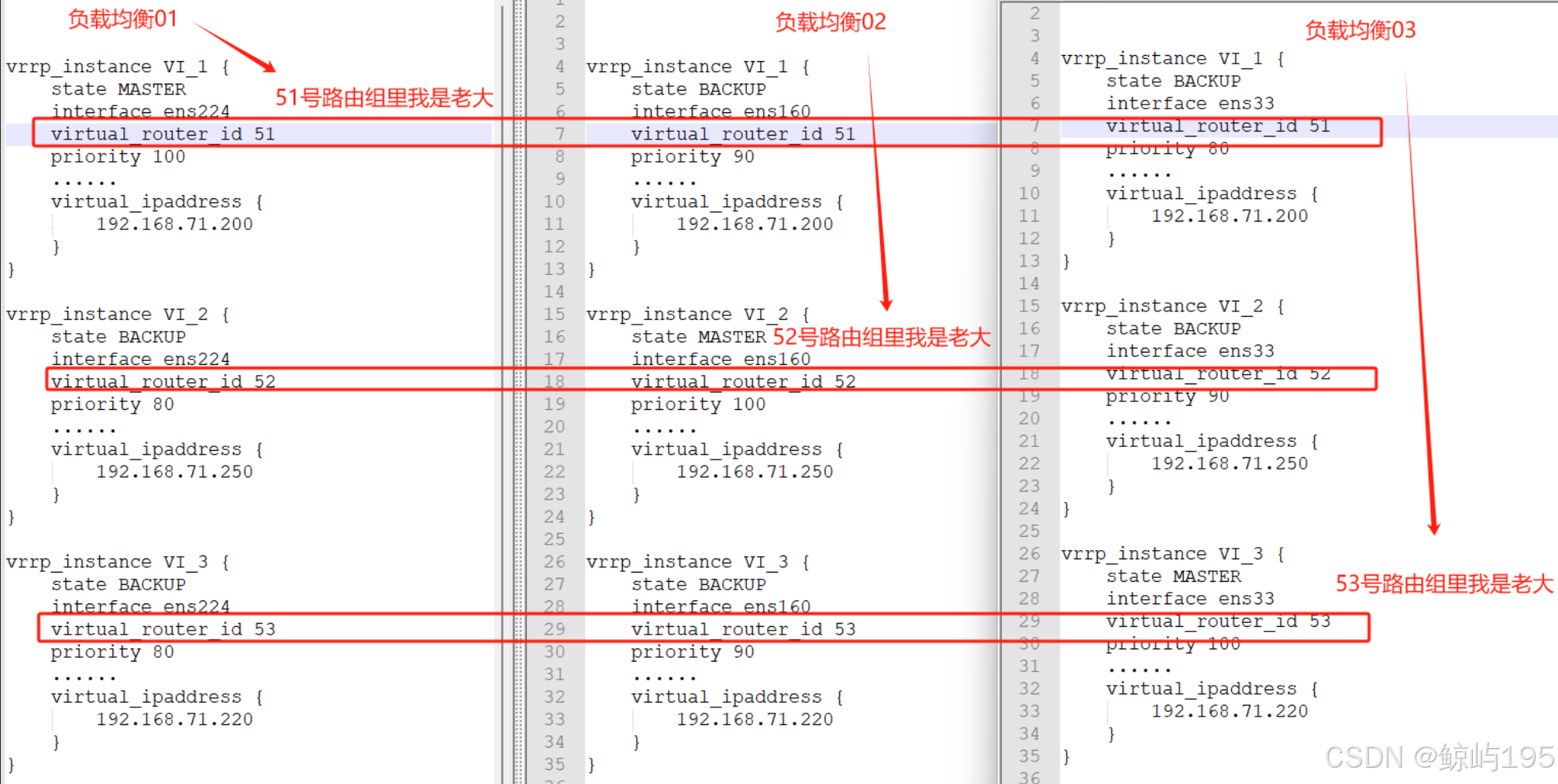
vrrp_instance VI_1 { # 单组只写一个,多组写多个
# 1、表示状态是MASTER主机还是备用机BACKUP,初始都设置为BACKUP,然后通过priority来高低来决定谁是主(搭配非抢占式)-------优先级大于 抢占式/非抢占式
state BACKUP
# 2、一定要与你的网卡对应上,否则错误
interface ens36
# 3、所有主备节点保持一致,代表在一个路由组里(组id号)
virtual_router_id 251
# 4、当前节点的优先级,数字越大,优先级越高,节点优先级,值范围0~254,MASTER>BACKUP
priority 100
# 5、设定VRRP设备发送广播消息的时间间隔为1s一次,以确定VRRP群组成员的状态同步,确保主挂掉后能够快速进行主备切换
advert_int 1
# 6、非抢占式,详解在下面
nopreempt
# 7、认证权限密码,防止非法节点进入
authentication {
auth_type PASS
auth_pass 11111111
}
# 8、健康检查脚本,在这个脚本里写检测逻辑,某个服务挂掉了,就停掉keepalived重新选出主,vip会飘过去
track_script {
chk_nginx #前面自定义的
}
# 9、虚拟出来的ip,可以有多个(vip)
virtual_ipaddress {
192.168.71.200
}
}
EOF
新增脚本 # 脚本运行时间超过了配置文件中的interval时间就会被kill -15杀掉
touch /etc/keepalived/check_port.sh
chmod +x /etc/keepalived/check_port.sh
vim /etc/keepalived/check_port.sh
#!/bin/bash ## 脚本实现可以减权重降为从,或者直接停掉keepalived,此处为直接停掉
count=$(ps -C haproxy --no-header|wc -l)
#1.判断 Nginx 是否存活,如果不存活则尝试启动 Nginx
if [ $count -eq 0 ];then
systemctl start haproxy &>/dev/null & # 放后台运行防止超时
sleep 1 # 不要sleep太久,超过了keepalived.conf中配置的interval时间就麻烦了
#2.等待 1 秒后再次获取一次 haproxy 状态#
count=$(ps -C haproxy --no-header|wc -l)
#3.再次进行判断, 如haproxy 还不存活则停止 Keepalived,让地址进行漂移,并退出脚本
if [ $count -eq 0 ];then
systemctl stop keepalived
fi
fi
启动keepalived
systemctl start keepalived
测试方式:
找一台机器
while true;do curl http://192.168.71.200:8081/1.txt;sleep 1; done
模拟挂掉
简单粗暴:直接把机器关机
也可以yum remove nginx -y
补充:vip能不漂就尽量别漂(使用非抢占式)
存在多台负载均衡,只使用一组keepalived的话只有一台在工作会造成浪费,通过设置多组keepalived实现最大利用
多主热备高可用(多组)keepalived部署+dns轮询

## 直接在配置文件中设置主从,优先级大于模式的设置
脑裂问题
同一个vip同时出现在多台负载均衡机器上
补充:只要涉及到vip要漂移,都会涉及到脑裂问题-----检测通告封装在IP包---网络层(三层)
为何会出现脑裂?(基本上都跟通信有关系--》依赖网络)
1、网络故障
2、防火墙屏蔽掉了
脑裂了会带来什么影响?
一个网络环境中出现了两台配置有一模一样的ip地址,会网络冲突
模拟脑裂:
systemctl start firewalld
如何处理脑裂
如果当前已经遇到脑裂了?
恢复业务是第一位,先kill一台,确保集群正常
停掉keepalived
停掉服务组件--》nginx
拆掉ip
如何预防脑裂?
1、做好监控
2、引入第三方检测机制
3、引入分布式协调服务如ZooKeeper等服务器,用于节点间的健康检查和领导选举
4、写脚本,运行脑裂之外的机器上,作为第三方的检测,写计划任务定期执行
检测命令:count=$(arping 192.168.71.200 -c3 |grep reply |awk '{print $(NF-1)}'|sort |uniq )
如果$count 大于 1(有多个不同的mac地址),就代表脑裂,就应该做
找一个节点:
停掉keepalived
停掉服务组件--》nginx
拆掉ip
DNS轮询
在dns添加A记录,让同一个域名解析成多个ip
一般加在负载均衡层的前面,轮询多个vip映射的公网IP(部署简单,例如:阿里云点点即可)
十二、集群扩容----负载均衡
使用lvs dr模式时,设备受到局域网限制,但性能更高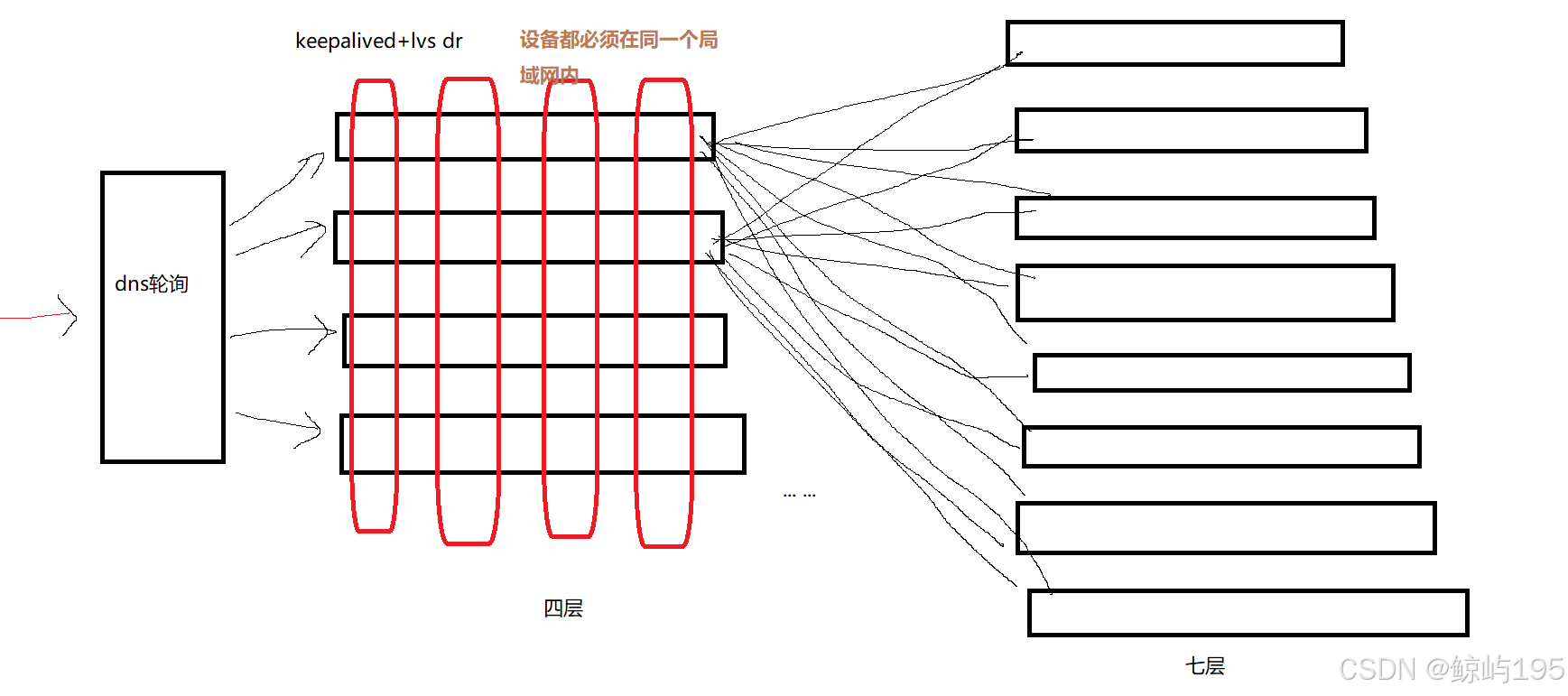
使用keepalived+haproxy/naginx时,设备可以在不同的局域网中,不受地域限制
七、Web应用层详解
问:如何看待一整套架构的上下游对接/通信?
上下游不用管具体是什么软件,只要通信协议能对上就可以
即上游用什么协议封装,下游就应该用什么协议解封
Web应用层程序部署
协议
http协议
cgi、fastcgi、php-fpm----》php语言体系
wsgi、uwsgi、agi-----》python语言体系
http协议----》java语言
http协议----》go语言
### 服务都要基于相应的语言编译环境运行,通过调用命令进行操作
部署 服务 + 应用
部署php: nginx---------php-fpm(php应用程序)---》mysql
部署python: nginx-------- uwsgi(python应用程序)----》mysql
部署java: nginx------tomcat(java应用程序)------》mysql
部署go: nginx------go二进制程序------》mysql
挡一个nginx----屏蔽掉web层不同软件不同协议对上游对接的影响,对上游暴露一个通用的http协议
http协议详解
1、为何要学http协议?
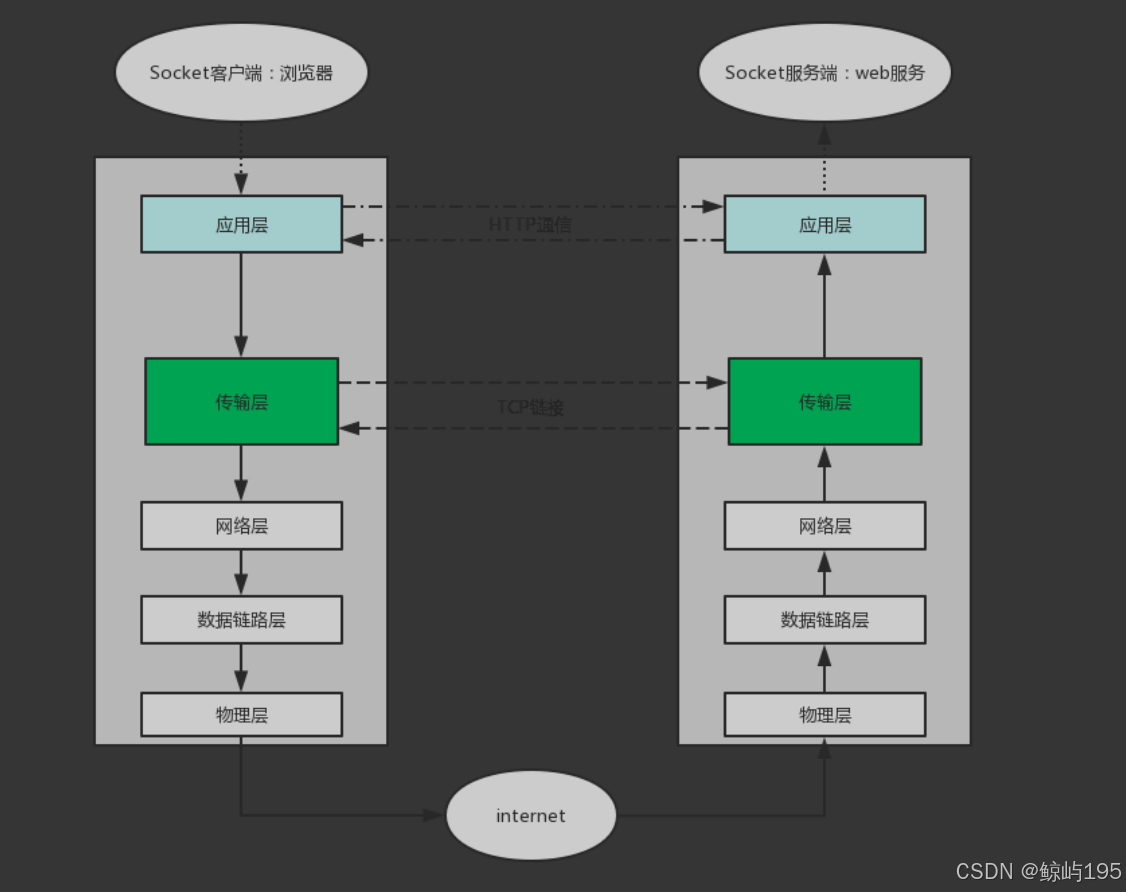
用户用浏览器访问网页,默认走的都是http协议,所以要深入研究web层,必须掌握http协议
2、什么是http协议
1、全称Hyper Text Transfer Protocol(超文本传输协议)
### 一个请求得到一个响应包
普通文本:文件内存放的是一些人类认识的文字符号(汉字、英语、阿拉伯数字)
超级文本:除了普通文本内容之外,还有视频、图片、语音、超链接
超文本包含:html文件、css、js、图片、视频、语音
http协议都能传输上述内容,所以说http协议是专用于传输超文本的协议
2、http主要用于B/S架构
3、http是基于tcp协议的
强调:基于http协议发包之前,必须先建立tcp协议的双向通路
应用层协议:依赖于 TCP/IP 协议来实现数据的传输,规定数据传输的格式----HTTP 协议主要用于在客户端(如浏览器)和服务器之间进行信息交互,规定了请求和响应消息的格式、内容以及交互的规则。
3、http协议的发展史
网景浏览器(万能客户端)------》各种各样的服务端
http0.9
请求方法:只支持GET方法
请求头:不支持
响应信息:只支持纯文本,不支持图片
无连接/短连接/非持久连接:利用完tcp连接之后会立即回收,所以无连接指的不是说没有连接,而是说没有持久连接/长连接
http协议通信,先建立tcp连接,然后客户端发请求包,服务端收到后发送响应包,服务端一旦发送完响应包之后,服务端会立即主动断开tcp连接,下次http通信还需要重新建立tcp连接
无状态:(一个http协议的请求无法标识自己的身份)
http无法保存状态,比如登录状态----登录之后再次发送的请求无法识别身份
总结:(0.9的时代,下面两个问题都不是问题)
无连接/短连接/非持久连接---->引发的问题
同一个用户在短期内访问多次服务端,那大量的时候都会消耗在重复创建tcp连接上
在高并发场景下,对服务端是非常大的消耗,客户端的访问速度也会非常的慢
无状态:一个http协议的请求无法标识自己的身份---》引发的问题
如果是登录状态的话,http协议无法保存,那意味着每次请求都需要重新输出一次账号 密码来认证
http1.0
请求方法:支持GET(查)、POST(改)、DELETE(删)、PUT(增)
请求头:支持
响应信息:支持超文本
支持缓存
无连接/短连接/非持久连接
问题:
同一个用户在短期内访问多次服务端,那大量的时候都会消耗在重复创建tcp连接上
在高并发场景下,对服务端是非常大的消耗,客户端的访问速度也会非常的慢
目标:
同一个用户在短期内访问多次服务端,不要重复建立tcp连接,而是能够共用一个tcp链接
解决方案:支持持久连接/长连接 keep-alive
前提:
发送完http响应包之后,服务端立即断tcp连接,这是服务端的默认行为
要改变这种默认行为,要客户端通知服务端才行
实现:
客户端在发送http的请求时,需要再请求头里带上connection: keep-alive这个参数
服务端的keepalive_timeout设置要大于0
服务端收到后读取该参数,服务端会保持与这一个客户端tcp连接一段时间,响应时也会响应头里放connection: keep-alive这个参数
该tcp会保持一段时间 直到达到服务端设置的keepalive_timeout时间
补充:
在http1.0协议例还需要你发请求时你自己加上connection: keep-alive这个参数
在http1.1协议里所有的请求都会自动加上connection: keep-alive,也就是说在http1.1客户端默认就开启了长连接支持
配套的服务端也要开启(服务端的keepalive_timeout设置要大于0,等于0相当于关掉)
----如果用的是nginx 修改/etc/nginx/nginx.conf
无状态
问题:
服务端无法标识一个http请求的唯一性(http协议本身就没有可以标识自身请求唯一性的字段或机制)会导致,例如用户登录状态无法保存,那么每次请求都需要重新输一遍账号密码
目标:
服务端要客户端有状态(让客户端每次发请求的时候都能标识自身的唯一性)
解决方案:cookie、session、jwt(详解见nginx详解--负载均衡会话保持)
cookie机制:
1、访问一个站点,服务端返回的响应头会设置set-cookie: k1=v1;k2=v2
2、浏览器收到后,会根据set-cookie来设置存入本地的cookie值
3、下次请求该网站,浏览器会从本地cookie里取出cookie值,放到http请求的cookie字段里,发往服务端
特点:
1、cookie是浏览器的功能,是放在客户端的
2、cookie内存放的内容是可以被客户端篡改的(因为是明文,所以在集群的场景下不存在共享问题,每台服务器都能识别)
cookie机制+session(会话)机制:
1、访问一个站点,输入自己的账号密码进程认证,服务端收到请求之后认证通过,会产生一些标识用身份的数据
这些数据---》value
把这些数据关联一个---》key
key:value
key给客户端,存入cookie
value放在服务端,称之为session
2、服务端会把key放入cookie放入set-cookie里,返回给客户端
3、客户端收到响应后,会把key存入本地的cookie
4、下次请求该网站,会带着该key去到目标站点,目标站点收到后,会根据key取出value,value里放着本次请求的身份
特点:
1、把保密数据放在服务端,称之为session数据,然后针对session数据生成一个key值存入客户端的cookie中,可以防止篡改
2、在集群的场景下,需要做会话共享(session存入共享的地方)不做共享的话session会存放在单台web层服务器上,负载均衡改变服务器session便会失效
通过会将session数据存入redis,但redis作为一个大家依赖的共享点,会影响集群的扩展性(都关联redis不便于扩展)
总结:
单用cookie来存放状态信息:
优点:服务端不需要做会话共享
缺点:客户端可以篡改状态信息,不安全
cookie+session
优点:状态信息即session数据是存放在服务端的,状态不会被篡改
缺点:服务端需要做会话共享,增加了集群的耦合性
jwt(json web token):既需要做会话共享、又能很安全
服务端会将状态信息进行加密,然后把加密数据放入客户的cookie中,这个加密的数据称之为token(令牌)----》篡改的问题解决了
下次请求会从cookie中取出token带上一起发送给服务端,服务端收到了会用加密算法解密------------》不需要再做会话共享/保持
追求:服务端不保存状态
优点:不需要做会话共享、又能很安全
缺点:最大的缺点就是一个token一旦下发之后,就只能等着该token,服务端无法做到主动废弃该token----》想要做到随时都能主动废弃掉某个token,就需要开发额外的代码来支持
如果token泄露,可以使用token登录任意一台web层服务器(加解密算法一样)
http1.1(主要)
1、默认所有请求都启用长连接,对应服务端需要设置keepalive_timeout大于0
2、Pipelining(请求流水线化/管道化)-----可以连续发送多个请求,但响应也必须按照顺序来
3、分块传输编码chunked----不使用分块传输:先告知规定大小,当数据包大小到达指定值后就能知道到这里一个包的内容就结束了
使用分块传输:允许服务器在不知道全部响应大小的情况,(比如由数据库动态产生的数据)通过多个小"块"的形式逐步发送HTTP响应给客户端的技术。除非使用了分块编码Transfer-Encoding: chunked,否则响应头首部必须使用Content-Length首部
http2.0(未来)
4、http协议的格式
储备知识:什么是URI、URL
URI:统一资源标识符
# Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的
URL:统一资源定位服务,是uri的一种具体实现
http://192.168.71.10:8080/a/b/1.txt?x=1&y=2&page=10#_label5
所有部分:
http:// 协议部分
不写协议,默认http协议
192.168.71.10:8080 ip+port部分
不写端口默认服务端的端口是80
/a/b/1.txt 路径部分
不写路径,默认加一个/结尾
?x=1&y=2&page=10 请求参数部分 通常用于get请求
#_label5 锚 直接跳转到页面的某个部分
一个url地址的路径部分也称之为uri路径
URN:也是uri的一种具体实现 例如:mailto:java-net@java.sun.com。
请求request
包含四部分:
请求首行
GET /a.txt HTTP/1.1
请求方法 请求的路径部分及后续部分 使用http协议版本
请求头
都是key:value格式,用来定制一些参数
空行 # 后面两部分浏览器不可查
请求体数据
请求方法:
GET(查)----------》请求的数据可以放在url地址的?号后
POST(改)---------》挟带请求体数据(存入重要数据) # 例如账户的登录
DELETE(删)
PUT(增)
HEAD:类似get请求,不一样的是不会获取响应的数据,但是会获取响应头,而响应头包含着状态码,状态码代表着本次访问是否成功,所以head主要用来检测某个资源是否可以正常访问
OPTIONS 一般用作预检请求,在发真正请求之前先发个options请求预检一下服务端支持哪些http方法、跨域检测等
最常用:
GET
POST
区别:
1、挟带数据的方式不同
2、挟带数据的话post更安全
3、传输数据大小
get与post这两个方法本身没有限制
但因为get方法的数据都放在url地址中,而url地址的长度在一些浏览器中是有限制
所以如果要传一些较大的数据,不能用get方法应该用post方法把数据放入请求里传输
# 在nginx的访问日志中(详情见nginx的基础配置),当浏览器发送一条请求后,在GET日志后往往会跟一个"GET /favicon.icn HTTP/..."的日志,这是浏览器在访问到一个网页后往往会要求在获得一个网站图标进行标识
响应response
四部分:
响应首行
HTTP/1.1 200 OK
协议 状态码
状态码-------------------->依赖nginx的return指令响应
2xx:代表访问成功
3xx:本次请求被重定向 301--永久重定向 302--临时重定向
4xx:客户端错误
404:客户端访问的资源不存在
403:客户端没有对目标资源的访问权限
5xx: 服务端错误
503服务端故障
响应头
set-cookie: 要求浏览器把cookie信息存入本地
cache-control: 要求浏览器把一些文件缓存到本地
connection: keep-alive 要求浏览器保持长链接
Content-Type: text/html 告诉浏览器本次返回内容的格式,浏览器会调取相应的功能对相应的内容进行特定格式的解析呈现
text/plain 告诉浏览器本次返回的内容格式是普通文本
空行
响应体
http协议完整的请求与响应流程
浏览器访问一个url地址:http://egonlin.com:80/a/b/1.html
1、浏览器会先问本地dns把域名egonlin.com解析为ip地址
2、浏览器作为客户端会与目标ip:port建立tcp三次握手
3、浏览器会基于http协议封装请求包(osi七层的封包流程)
4、服务端收到包(osi七层的解包流程),拿到一个http协议的请求包,按照http协议来解析请求
会拿到请求路径部分:/a/b/1.html
服务端会打开该文件(对应一个文件描述符)把文件内容从硬盘读入内存
然后服务端程序会基于http协议封装读入内存的数据,形成一个响应包,发给客户端浏览器
5、浏览器收到http协议的响应包之后
先解析响应头,看到响应的状态码,知道本次是否成功
在解析响应头,可以拿到Content-Type就知道该用什么方法来解析内容,如果值为text/html就会
按照html代码的方式来解析返回的内容
再读取内容部分,当成html代码来解析
6、在解析html代码的过程中,有可能遇到css、jss、图片、视频等资源,会发起二次、三次。。。请求
直到把整个页面都渲染完毕
补充:http1.1默认是开启长连接的---》(核心是请求与响应头里都带着connection:keep-alive)
lnmp(php)
lnmp架构:
linux
nginx
php程序 python程序
mysql
# lamp (apache--->httpd)
重要:
上游----------“协议”-------------下游
cgi(协议)、fastcgi(协议)、php-fpm(程序)---------》php编程语言编写的程序
wsgi(协议)、uwsgi(协议)、asgi(协议)
uwsgi(程序) dphane(程序)---------》python编程语言编写的程序
储备知识:
nginx作为上游:
nginx------------------------------------------------------->下游
http协议:
转发指令:proxy_pass http://地址:端口
fastcgi协议
转发指令:fastcgi_pass
uwsgi协议
转发指令:uwsgi_pass
## fastcgi协议、uwsgi协议等都是在http协议上的进一步封装(七层)
server {
listen 8080;
location / {
fastcgi_pass http://地址:端口
}
}
nginx作为下游
--------------------http、tcp协议--------------》nginx
lnmp-----先说结论:
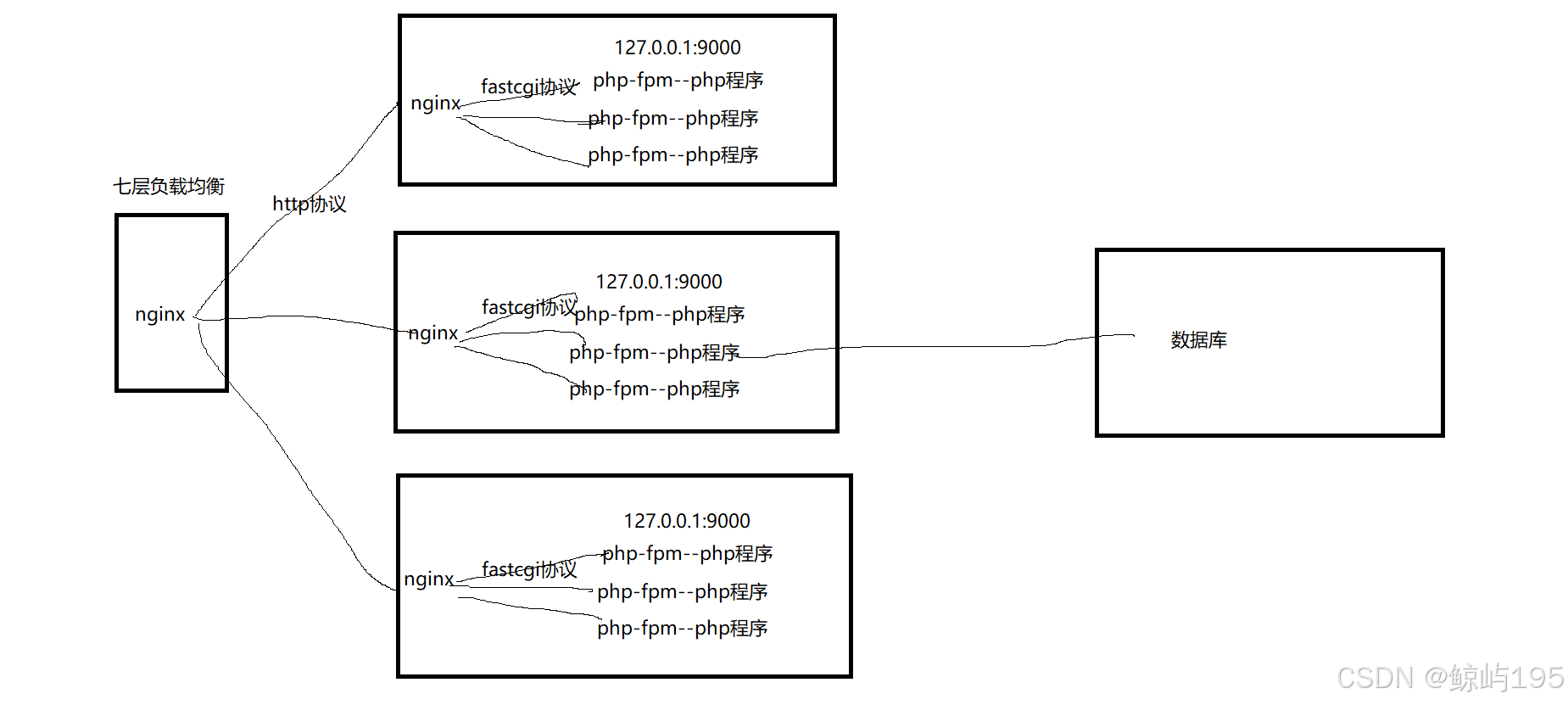
web层服务器(php应用程序):
-----http协议--------> ||nginx---------fastcgi协议----------》php-fpm服务(网络)+(php应用程序)||--->
# php-fpm服务与php应用程序之间本地直接进行调用(不代表所有都是本地调用)
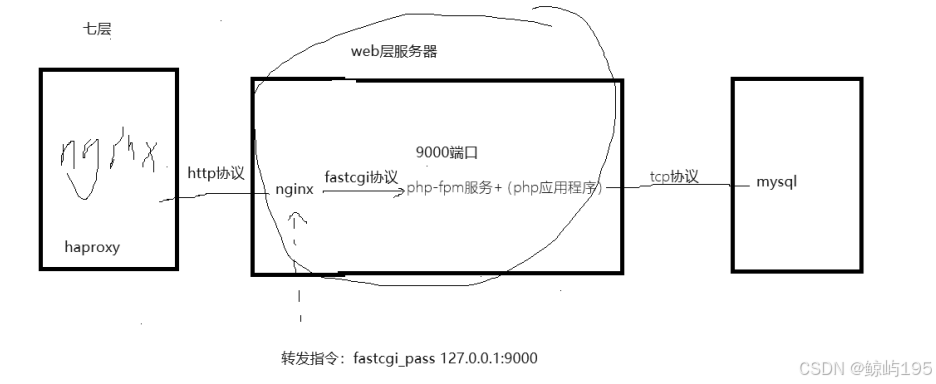
web上的nginx 抗并发能力强,起缓冲效果
转换协议,对上游暴漏通用的http,对下游调用适配下游的协议,增加了上游的可 选择性(基于本地转发)
cgi、fastcgi、php-fpm发展历程
储备知识:
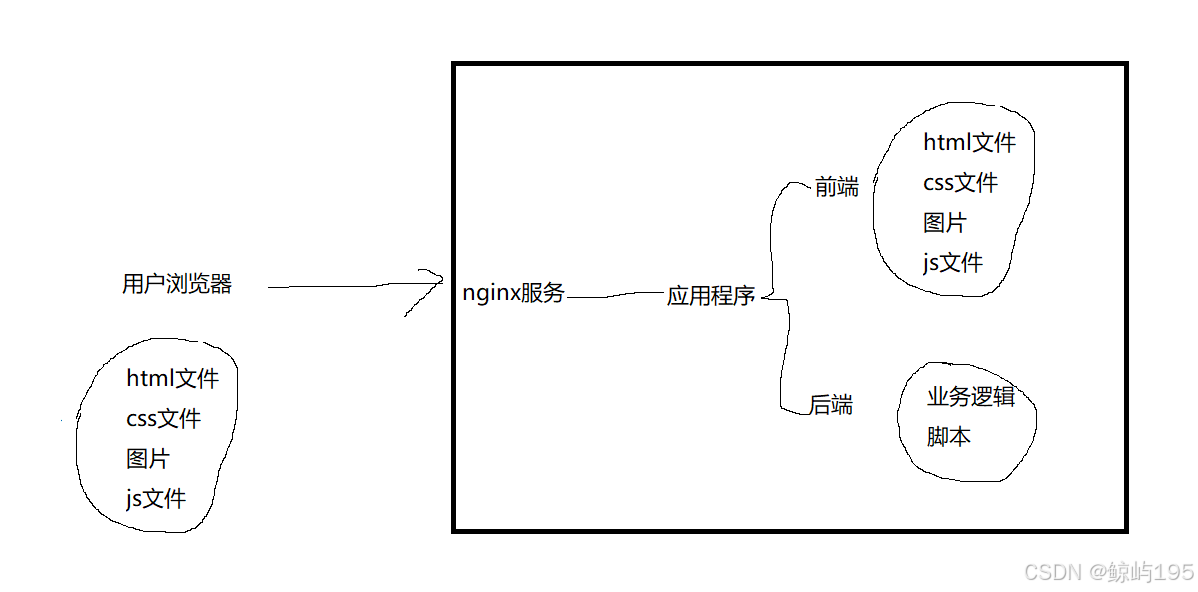
web程序由两部分构成:
web服务:负责网络通信(建连接,解析协议)
web应用:负责处理业务逻辑(与后台数据库打交道)
前端程序(放在服务端,但跑在客户端浏览器)
后端程序(放在服务端,也跑在服务端)
蛮荒时代:
没有互联网,内容的发布形式就是贴小广告(电线杆子)
小广告包含的内容:
1、文字
2、花花绿绿的颜色
3、图片
静态网页的时代:小广告搬到网上
准备工作:
买台电脑-------------》服务器
装个操作系统---------》linux
接入互联网
web程序:
应用程序:(只有前端---单纯打广告)
把小广告放到本地文件中
html文件
css文件
图片
部署一个服务
nginx
动态网页时代:线下实体店也不用来了,直接网上付款吧
诞生了js:实现网页的动态效果(朝后端发网络请求)
ajax-----一个功能模块
web程序:
应用程序
前端(放在服务端,跑在客户端)
html文件
css文件
图片
js文件(监听前端事件向后端发请求 / 执行前端的动态请求)
后端:(放在服务端,跑在服务端)一堆实现各种业务逻辑的小脚本
针对付款功能实现一个小脚本------------------》数据库
针对查询余额功能实现一个小脚本--------------》数据库
针对登录功能实现一个小脚本------------------》数据库
部署一个服务:
单纯接收tcp请求,不负责解析http协议
后端脚本的开发者需要自己解析http协议,然后才能编写业务逻辑
后端开发者:
解析协议
业务逻辑
问题:能不能让后端开发者专注于开发业务逻辑,不用接触复杂http协议
解决思路:
服务的开发者来处理,怎么处理的呢?
把http协议解开,提取里面的数据,然后按照一个更简单的协议规定
来组织好数据----》封装
http---解开、重新封装----》cgi
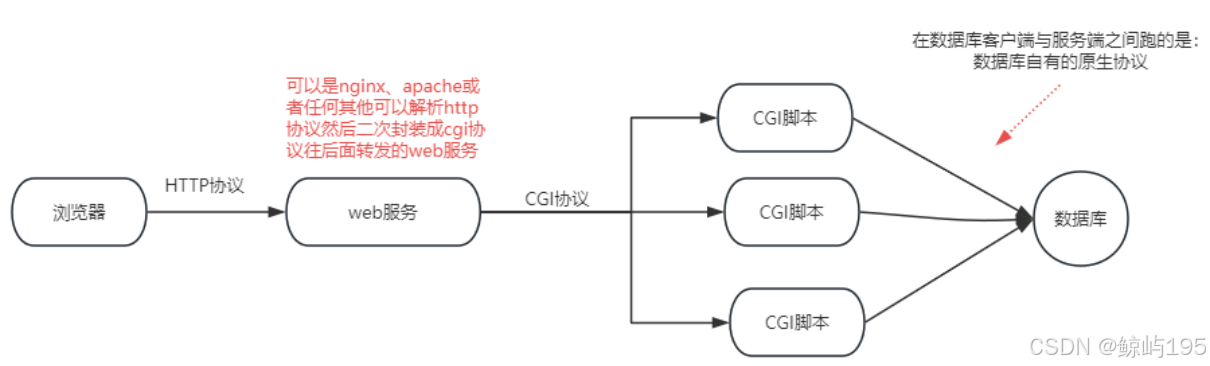
cgi 演进到了 fastcgi
fastcgi本身就是cgi协议
fastcgi特点:相当于一个常驻(long-live)型的CGI ,FastCGI协议规定:一个处理动态请求的进程处理完一个请求后不会关闭,而是可以继续处理下一个
为了使后端开发更为简单,出现php-fpm对fastcgi进行了进一步封装提供更简单的接口
php-fpm实现了解析fastcgi协议的功能,该软件启动起来后对外暴露一个fastcgi协议的端口
nginx-------------------fastcgi协议--------------》 php-fpm+(php程序)
php-fpm与php程序之间不走任何协议,直接是本地调用
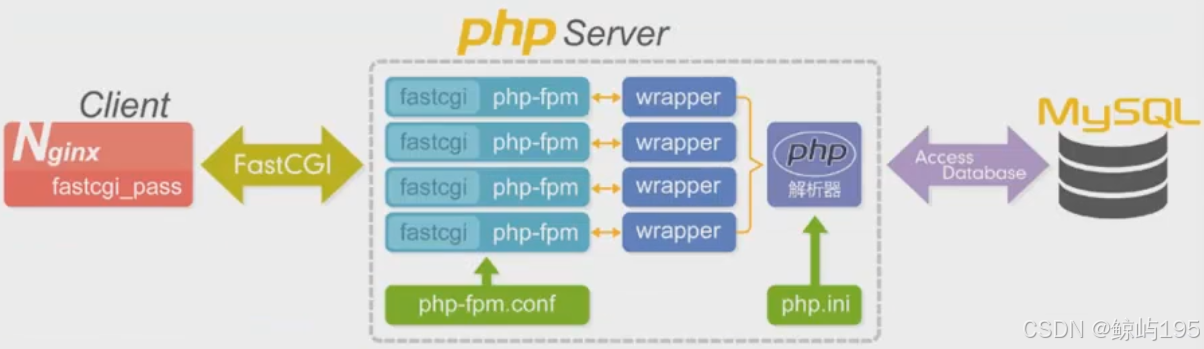
fastcgi_pass指令
# 官网:https://www.php.net/manual/zh/install.fpm.php
# This is the origin nginx conf.
location ~ \.php$ { # 单台
try_files $uri = 404;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
# You can replace it by # web内部代理多台
upstream php {
server 127.0.0.1:9000;
server 127.0.0.1:9001;
server 127.0.0.1:9002;
server 127.0.0.1:9003;
}
location ~ \.php$ {
try_files $uri = 404;
fastcgi_pass php;
fastcgi_index index.php;
include fastcgi.conf;
}
web框架:(针对开发业务逻辑时候有一些重复性的代码,提取出来形成的软件就叫web框架)
如果把开发业务逻辑的程序比喻为盖一座房子
web框架就帮你把房子的架子先搭起来
有了web框架的好处:
拿来主义,写代码之前上来先把框架的代码复制过来,我们的业务逻辑的前置的准备工作都完成了
构建LNMP环境
补充:lamp nginx--->apache 软件--->httpd
思路介绍:web层服务器
linux
Nginx
php-fpm(php程序)
mysql
1、准备环境
sed -ri 's/enforcing/disabled/g' /etc/sysconfig/selinux
systemctl stop firewalld
setenforce 0
iptables -t filter -F
配置静态ip
配置时间同步
2、先部署php-fpm
yum -y install epel-release
yum -y install http://rpms.remirepo.net/enterprise/remi-release-7.rpm
yum -y install yum-utils
yum -y install php74-php-gd php74-php-pdo php74-php-mbstring php74-php-cli php74-php-fpm php74-php-mysqlnd
检查版本:php74 -v
使用默认配置即可:cat /etc/opt/remi/php74/php-fpm.d/www.conf |grep -v '^;' |grep -v '^$'
# 配置信息(如果是centos9默认以socket方式启动,想用端口方式,需要改listen=127.0.0.1:9000)
systemctl start php74-php-fpm
systemctl enable php74-php-fpm
3、再部署nginx
准备nginx的repo文件放入/etc/yum.repos.d/下
yum install nginx -y
4、再配置nginx转发fastcgi协议给php-fpm
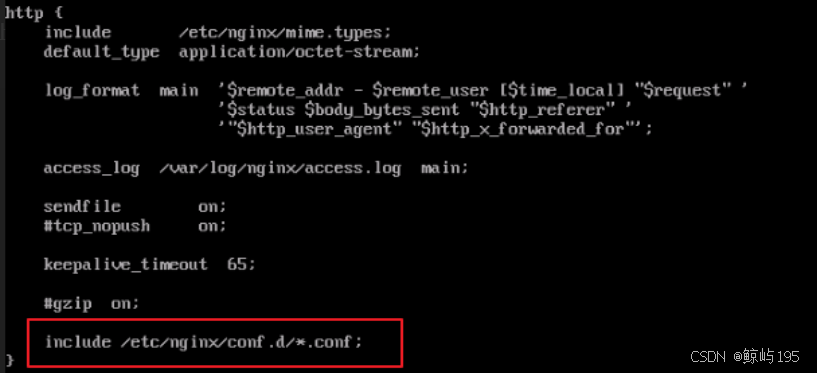
mkdir /etc/nginx/conf.d
vim /etc/nginx/conf.d/www.conf
[root@web03 ~]# cat /etc/nginx/conf.d/www.conf
server {
listen 80; # conf.d下的所有文件都包含在nginx的http服务中
server_name localhost;
#access_log /var/log/nginx/host.access.log main;
# 非.php结尾请求从root指定的目录里直接拿,例如/、/1.jpg、/a/b/2.css
location / {
root /usr/share/nginx/html;
index index.php index.html index.htm a.txt;
}
# 以.php结尾的请求,交给fastcgi程序处理,下面的配置没有一点是多余的
location ~ \.php$ { # ~代表使用正则
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME /usr/share/nginx/html$fastcgi_script_name;
include fastcgi_params; # 用于包含另一个文件中的配置文件,fastcgi的fastcgi_params文件中包含了http与fastcgi协议的数据的对应关系
# $fastcgi_script_name对应的参数为.php文件的uri
### FastCGI 服务器(比如 PHP-FPM)会在收到请求后查找 SCRIPT_FILENAME 参数对应的 PHP 文件路径,执行 PHP 代码并产生结果,然后再返回给 Nginx,最后 Nginx 再将这个结果返回给最初的请求者。
}
}
systemctl restart nginx
systemctl enable nginx
### index指令或try_files指令都会触发二次匹配------不指定路径/为默认路径时生效,存在指定具体的文件路径的时候直接去对应路径获取文件
所以当请求https://egonlin.com/(默认路径)时,匹配到location / 会执行index指令依次序查找文件,找到了一个文件叫index.php则使用/index.php发起内部重定向,就像从客户端再一次发起请求一样,Nginx会再一次搜索location,毫无疑问匹配到第二个~ \.php$, 然后交给FastCGI处理
说明:index.php内通常编写了php语言写的动态处理程序,该程序nginx本身时无法处理的,必须交给php-fpm处理
eg: 当url没有指定文件路径的时候,例如http://....../wordpress,按顺序添加文件补全路径,如上述优先级所示,增加为http://....../wordpress/index.php,增加完成后会触发location的二次匹配。存在指定具体的文件路径的时候直接去对应路径获取文件。
5、写一个php测试页面来验证nginx对接php-fpm
cat > /usr/share/nginx/html/index.php << EOF
<?php
phpinfo();
?>
EOF
6、部署mysql数据库
# 清理環境
yum remove mysql* -y
rm -rf /var/lib/mysql/*
# 重新安装
yum install mariadb* -y
systemctl start mariadb # /var/lib/mysql下生成一堆数据的文件
systemctl enable mariadb
7、初始化数据库,建立远程连接的账号
----------> mysql -uroot -p
CREATE DATABASE wordpress charset=utf8mb4;
grant all on wordpress.* to 'egon'@'%' identified by '123'; # %---->远程账号
grant all on wordpress.* to 'tom'@'localhost' identified by '123';
flush privileges;
# 强调:测试本地能否连上
mysql -utom -p123 -h localhost
8、至此lnmp环境已经完成,此时我们需要拿一个php程序扔到环境中,然后配置好连接数据的地址、账号等信息
wget https://wordpress.org/latest.zip (快速创建和管理网站内容)
unzip latest.zip -d /usr/share/nginx/html
cp wp-config-sample.php wp-config.php
-----》vim wp-config.php # 指定数据库
define( 'DB_NAME', 'wordpress' );
define( 'DB_USER', 'tom' );
define( 'DB_PASSWORD', '123' );
define( 'DB_HOST', 'localhost' );
lnmp(python)
1、nginx 作为上游,支持的协议有三种
proxy_pass http:// # 转发http协议
fastcgi_pass # 转发fastcgi协议
uwsgi_pass # 转发uwsgi协议
2、介绍python程序相关的协议
web程序的构成=服务+应用
服务与应用之间的协议:
wsgi
asgi(就是wsgi的异步版,性能更强,功能更多)
服务有两个:
uwsgi服务-----------》wsgi协议-----》app
daphne服务----------》asgi协议-----》app
服务的上游
------uwsgi协议-----》uwsgi服务-----------》wsgi协议-----》app(建议,效率更高)
------http协议------》uwsgi服务-----------》wsgi协议-----》app
------http协议------》dahpne服务----------》asgi协议-----》app
3、python语言体系的协议 VS php语言体系的协议
uwsgi服务:
对下游:wsgi协议
对上游:uwsgi协议或http协议(可以直接被浏览器访问)
dahpne服务
对下游:asgi协议
对上游:http协议
php-fpm服务
对下游:无协议
对上游:fastcgi协议,不支持http协议(不能直接用浏览器访问)
web服务器上,php-fpm的上游最好跟一个nginx,nginx对上游暴露http、tcp协议--->lnmp
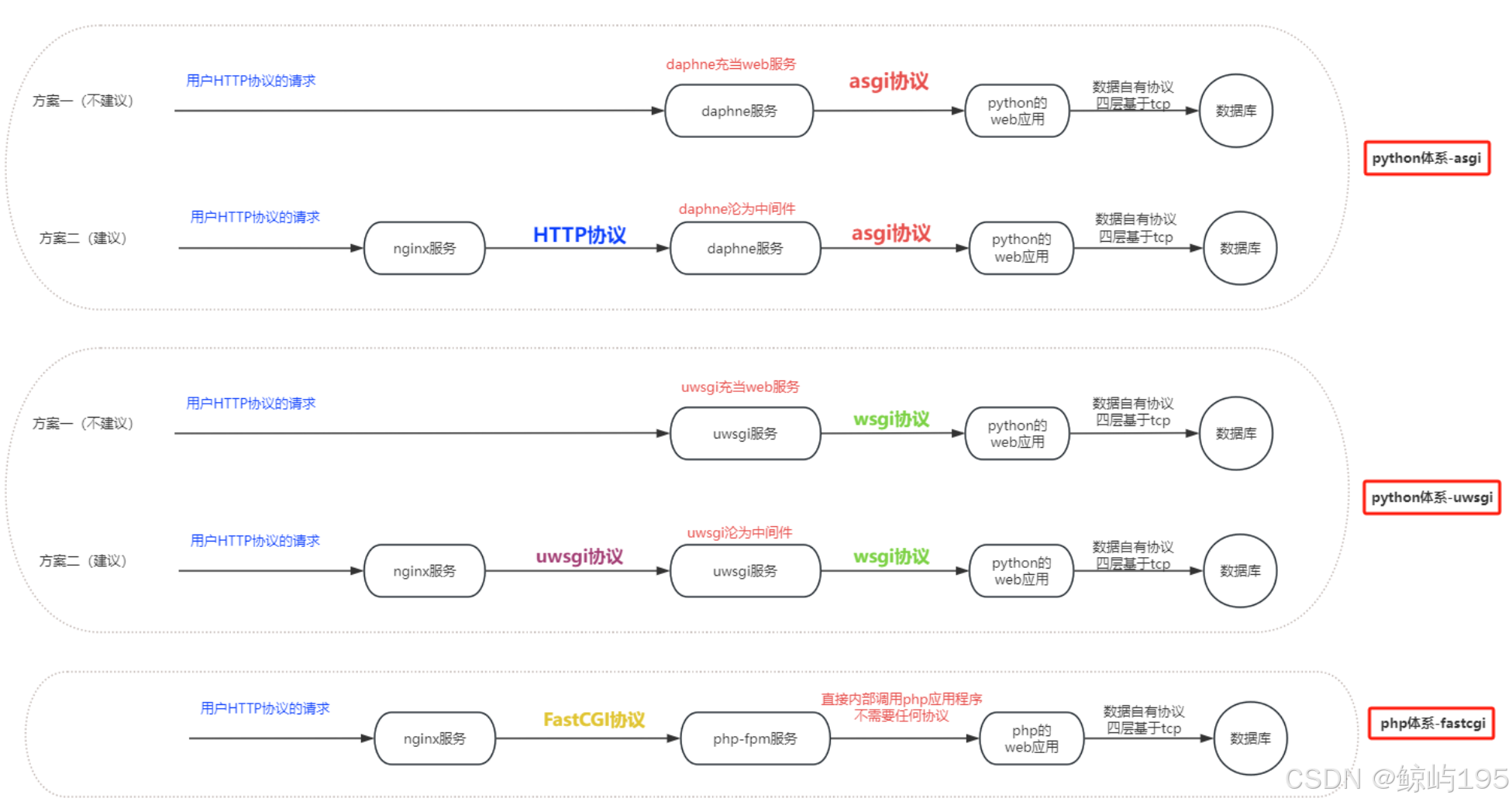
4、部署python web程序
建议方案 七层负载均衡------http协议---------》web层(nginx服务(uwsgi_pass)-----uwsgi协议--------》uwsgi服务(监听uwsgi协议)------wsgi协议------》python应用程序)

补充:如何控制uwsgi监听何种协议(针对上游)
uwsgi.ini定义:
http = :8080 代表uwsgi服务监听http协议端口
socket = :8080 代表uwsgi服务监听uwsgi协议的端口
针对前者,在nginx里需要用proxy_pass转发
针对后者,在nginx里需要用uwsgi_pass转发
====================》(1)准备环境
关selinux
关firewalld
配置静态ip
同步时间
====================》(2)安装官方的mysql
官网下载地址(找到对应的系统版本):https://dev.mysql.com/downloads/repo/yum/
得到一个rpm包,该包安装后会生成一个yum源,用于安装官网的mysql
注意:官网的下载速度慢,可以去这里找https://gitee.com/egonlin/djagon-uwsgi-deploy
rpm -ivh mysql80-community-release-el7-1.noarch.rpm #安装源
yum install mysql-devel mysql-server -y #安装包
# 修改时区设置:写入到配置文件/etc/my.cnf需要重启mysql实例:
[mysqld] # 配置文件没有的话就直接添加进去
。。。
default-time-zone=timezone
修改为
default-time-zone = '+8:00'
系统时区也要正确
date # 看一下
timedatectl set-timezone 'Asia/Shanghai' # 用这条命令设置
# 启服务
systemctl restart mysqld
# 初始化数据
cat /var/log/mysqld.log |grep -i pass ///grep 'temporary password' /var/log/mysqld.log
回显如下类似信息
2024-03-27T03:12:10.075896Z 1 [Note] A temporary password is generated for root@localhost: IsopfQucm2?u
mysql -uroot -p刚刚看到的密码
> ALTER USER 'root'@'localhost' IDENTIFIED BY 'egon@123Abc'; #直接使用本地帐号修改密码
> CREATE DATABASE djangoblog;
### 新建账号
用
SET PASSWORD FOR 'root'@'localhost' = 'new_password';
或者
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
mysql8创建新账户用一条命令会报错
grant all on *.* to root@'192.168.71.%' identified by '123';
需要拆分为三条命令执行才行
create user 'root'@'192.168.71.%';
alter user 'root'@'192.168.71.%' identified by '123';
grant all on *.* to 'root'@'192.168.71.%';
flush privileges;
====================》(3)部署应用程序
1、安装python解释器环境
wget https://www.openssl.org/source/openssl-1.1.1n.tar.gz --no-check-certificate
tar xf openssl-1.1.1n.tar.gz
cd openssl-1.1.1n
./config --prefix=/usr/local/openssl && make && make install
wget https://www.python.org/ftp/python/3.10.12/Python-3.10.12.tgz
tar xf Python-3.10.12.tgz
yum install libffi* libffi-devel* -y # 依赖
cd Python-3.10.12
./configure --prefix=/usr/local/python3.10.12 --with-openssl=/usr/local/openssl --with-openssl-rpath=auto
make && make install
vim /etc/profile 添加两行
PATH=/usr/local/python3.10.12/bin/:$PATH
export PATH
source /etc/profile #重载配置
2、下载python程序包
https://gitee.com/egonlin/djagon-uwsgi-deploy
下载完毕解压目录中有一个DjangoBlog-master.zip就是我们的程序包
mkdir /blog
unzip DjangoBlog-master.zip -d /blog
3、安装python程序的依赖包
cd /blog/DjangoBlog-master
mkdir ~/.pip
cat > ~/.pip/pip.conf << EOF
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
EOF
pip3.10 install -Ur requirements.txt
4、修改程序的配置文件:配置连接数据库
vim /blog/DjangoBlog-master/djangoblog/settings.py
链接数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'djangoblog',
'USER': 'root',
'PASSWORD': 'egon@123Abc',
'HOST': '127.0.0.1',
'PORT': 3306,
'OPTIONS': {
'charset': 'utf8mb4'},
}}
时区相关配置:
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = False
5、初始化数据库
cd /blog/DjangoBlog-master
python3.10 manage.py makemigrations # 将数据迁移到数据库
python3.10 manage.py migrate
创建后台管理账号: # 测试的时候使用
python3.10 manage.py createsuperuser
# 生成测试数据
python3.10 manage.py create_testdata
6、临时验一下
起一个测试服务:python3.10 manage.py runserver 0.0.0.0:9999
直接用浏览器访问
测试完毕后一定要关闭
7、安装与配置uwsgi
pip3.10 install uwsgi
cat > /blog/uwsgi.ini << EOF
[uwsgi]
# 监听uwsgi的端口
socket = :8080
# 监听的http协议端口:不需要监听http端口
# http = :8080
# 启动后切换到该目录下作为项目根目录,我们在3.2小节指定的项目目录/blog/DjangoBlog-master
#切换到python应用程序所在的目录文件,uswgi协议的配置存在于python应用程序
chdir = /blog/DjangoBlog-master/
# 完整查找路径:/blog/DjangoBlog-master/djangoblog/wsgi.py文件里的application对象
module = djangoblog.wsgi:application
# wsgi-file = djangoblog/wsgi.py # 与上面的配置等价
# 启动的工作进程数量
processes = 4
# 每个进程开启的线程数量
threads = 2
master=True
pidfile=/tmp/project-master.pid
vacuum=True
max-requests=5000
daemonize=/var/log/uwsgi.log #日志所在位置
EOF
cd /blog
uwsgi --ini uwsgi.ini #启动uwsgi服务
8、安装与配置nginx
yum install nginx -y
将配置文件中的server删掉(不删也行)并建立conf.d目录及其下的www.conf文件
如果conf.d已经存在就将其中的deault.conf删除再建自己的.conf配置文件
[root@web02 /etc/nginx/conf.d]# cat /etc/nginx/conf.d/www.conf
server {
listen 8111;
server_name localhost;
location / {
# 包含uwsgi的请求参数
include uwsgi_params;
# 转交请求给uwsgi
uwsgi_pass 127.0.0.1:8080; # uwsgi服务器的ip:port
}
}
systemctl restart nginx
部署go程序
go语言是一门编译型语言,编译型语言的程序必须要编译安装----》得到一个二进制命令
go二进制命令包含=服务+应用
但是一些静态文件(html、css、js、图片)还有配置文件肯定是分开放的,不能编译进入二进制命令里

(1)准备环境
略
(2)部署好编译环境(go环境)
原理剖析
C语言源码包-------编译环境/工具(gcc、glibc)-----》二进制指令
go语言源码包------编译环境/工具(go)-------------》二进制指令
wget https://go.dev/dl/go1.22.1.linux-amd64.tar.gz
tar xf go1.22.1.linux-amd64.tar.gz
mv go /usr/local/go # 习惯放于一个指定的目录下/usr/local
vim /etc/profile # 添加下述两行
PATH=/usr/local/go/bin:$PATH
export PATH
source /etc/profile # 重载
(3)下载源码包,用编译工具编译得到二进制
go env -w GOPROXY=https://goproxy.cn,direct #加速编译
去https://gitee.com/egonlin/go-pro下载源码包
unzip main.zip
mkdir /go_pro
unzip go-pro-main/chitchat-master.zip -d /go_pro
cd /go_pro/chitchat-master
rm -rf chitchat #删除原有的编译过的二进制指令
go build -o chitchat #在当前目录下重新编译
(4)修改配置文件---连接数据库
cd /go_pro/chitchat-master
vim config.json
(5)安装数据库
安装环节:略
创库
create database chitchat;
创建账号:
略:之前已经创建过滤
账号:root@localhost
密码:egon@123Abc
(6)为chitchat库初始化数据库
# 正常操作,导入sql:mysql -uroot -pegon@123Abc < all.sql
(7)启动服务
cd /go_pro/chitchat-master
./chitchat # 读取配置config.json
(8) 安装并配置nginx代理 go程序
yum install nginx -y
[root@web02 ~]# cat /etc/nginx/conf.d/www.conf
server {
listen 8111;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:8383; # uwsgi服务器的ip:port
}
}
#################################################
server {
listen 8111;
server_name chitchat.test www.chitchat.test; #域名
location /static {
root /go_pro/chitchat-master/public;
expires 1d; # 静态资源缓存一天
add_header Cache-Control public;
access_log off;
try_files $uri @goweb; # try_files指令会先查找路径/go_pro/chitchat-master/public/$uri是否存在,存在则返回,否则交给@goweb处理
}
location / {
try_files /_not_exists_ @goweb; # /_not_exists路径肯定不存在,使得所有请求都会转向名为@goweb的location块
}
location @goweb { # 定义一个名为@goweb的localtion块,用于处理动态请求
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Scheme $scheme;
proxy_redirect off;
proxy_pass http://127.0.0.1:8383;
}
### 单独写一个块,减少代码的重复量
error_log /var/log/nginx/chitchat_error.log;
access_log /var/log/nginx/chitchat_access.log;
}
[root@web02 ~]# systemctl restart nginx
supervisor
我们可以把我们的程序交给supervisor来管理,启动后变成supervisor的子进程
作用:
1、supervisor会把子进程放到后台运行(不需要再用nohup一类的方式把进程放入后台)
2、supervisor会监控子进程的状态,一旦子进程挂掉,操作系统会把子进程挂掉的信号
发给supervisor,supervisor会自动拉起子进程,实现了故障自动重启( 不需要自己写监控程序,配合计划任务定时监控,发现故障然后恢复)
vim /etc/supervisord.d/chitchat.ini
[program:chitchat]
process_name=%(program_name)s # 名称
directory=/go_pro/chitchat-master # 所在目录
command=/go_pro/chitchat-master/chitchat # 程序所在路径
autostart=true
autorestart=true
user=root # 用户
redirect_stderr=true
stdout_logfile=/go_pro/chitchat-master/logs/chitchat.log # 程序的日志文件
调用:
systemctl start supervisord
supervisorctl reread
supervisorctl update
supervisorctl start chitchat
部署java程序
储备知识:
1、打包和分发java应用程序的两种格式
一个java的源码包,需要打包后才能部署,包的两种格式
(1)jar包
jar包可以在任意支持java的平台上运行
java -jar xxx.jar # (服务+业务逻辑)
(2)war包
war包专用于java web应用程序
tomcat(服务) + xxx.war(业务逻辑)
2、传统部署 与 基于maven的springboot项目
传统部署:
导出war包:得到xxx.war
把xxx.war扔到tomcat的应用根目录下即可
例如: /usr/local/tomcat/webapps/xxx.war
由于springboot的start-web的jar包中集成了tomcat,
但是springboot的项目既可以导出为war包,也可以导出jar
jar 包是默认的导出格式,并且默认导出时内部就集成一个tomcat
如果你导出的是war包,那么部署方式还得用传统的方式(即搭配一个tomcat)
打包工具:mvn(maven)-----------(可以把项目导出为war包、也可以导出为jar)
3、用maven将springboot项目导出为jar包
目标:java -jar xxx.jar
(1) 准备工作
关闭seilnux
关闭firewalld
配置静态ip
配置时间同步
JDK >= 1.8 (推荐1.8版本)----》支持tomcat9.0版本 (java环境)
Mysql >= 5.7.0 (推荐5.7版本)
Maven >= 3.0 ----》 打包工具
---------安装jdk1.8
yum -y install java-1.8.0-openjdk*
find /usr/lib/jvm -name 'java-1.8.0-openjdk-1.8.0*'#输出/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64
# 注意:你上面find出来的结果可能跟我的不同,请以你find出来的为准,不要直接复制粘贴
vim /etc/profile # 添加
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH
source /etc/profile # 重加载
---------安装Maven >=3.0
wget https://dlcdn.apache.org/maven/maven-3/3.9.7/binaries/apache-maven-3.9.7-bin.tar.gz --no-check-certificate
tar xf apache-maven-3.9.7-bin.tar.gz -C /usr/local/ # 解压到对应目录
---->vim /etc/profile 添加环境变量
PATH=/usr/local/apache-maven-3.9.7/bin:$PATH
export PATH
source /etc/profile
---------安装mysql>=5.7.0
yum remove mysql* mariadb* -y
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql57-community-release-el7-10.noarch.rpm # 安装
yum -y install mysql-community-server --nogpgcheck
systemctl start mysqld
systemctl enable mysqld
systemctl status mysqld.service
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p'nsrhNkCZa0.j'
执行下述sql
alter user 'root'@'localhost' identified by 'egon@123Abc';
flush privileges;
# 如果mysql部署在远程主机,那么需要创建远程账号,sql如下
#create user 'root'@'192.168.71.%';
#alter user 'root'@'192.168.71.%' identified by '123';
#grant all on *.* to 'root'@'192.168.71.%';
#flush privileges;
(2) 把springboot项目的源代码拉到本地
yum install git -y
mkdir /my_soft
cd /my_soft
git clone https://gitee.com/y_project/RuoYi.git
# gitlab-----公司私有的代码仓库 公共仓库--------github(国外) gitee(国内)
(3)修改配置(连数据库、jar内部集成的服务自身监听的端口)
cd /my_soft/RuoYi/
find . -name 'application-druid.yml'
[root@web01 /my_soft/RuoYi]# vim /my_soft/RuoYi/ruoyi-admin/src/main/resources/application-druid.yml
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/ry?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: 'egon@123Abc'
[root@web01 /my_soft/RuoYi]# find . -name 'application.yml'
[root@web01 /my_soft/RuoYi]# vim /my_soft/RuoYi/ruoyi-admin/src/main/resources/application.yml
server:
# 服务器的HTTP端口,默认为80
port: 8686
servlet:
# 应用的访问路径
context-path: /
(4)往数据库内导入数据
[root@web01 /my_soft/RuoYi]# mysql -uroot -p'egon@123Abc'
create database ry charset=utf8mb4; ## 和前面配置文件中的数据库配置要保持一致
## 注入sql出现问题,修改字符编码解决
mysql -uroot -p'egon@123Abc' -B ry < /my_soft/RuoYi/sql/quartz.sql
mysql -uroot -p'egon@123Abc' -B ry < /my_soft/RuoYi/sql/ry_20240529.sql
(5)导出jar(包含tomcat服务+业务逻辑),默认的导出格式就是jar包
### 如何导出其实你cat /my_soft/RuoYi/bin/package.bat 可以看到导出命令就是下面这条
cd /my_soft/RuoYi
mvn clean package -Dmaven.test.skip=true
显示BUILD Success代表导出成功,最后得到jar包
ls /my_soft/RuoYi/ruoyi-admin/target/ruoyi-admin.jar
(6)启动
java -jar /my_soft/RuoYi/ruoyi-admin/target/ruoyi-admin.jar
(7)访问
192.168.71.112:8686
测试账号admin 密码:admin123
4、用maven将springboot项目导出为war包
目标:tomcat + xxx.war
(1) 准备工作
同上
(2) 把springboot项目的源代码拉到本地
同上
(3)修改配置(连数据库、jar内部集成的服务自身监听的端口)
要改数据库链接配置
不用设置端口(因为我们一会导出的war包内部不集成tomcat)
(4)往数据库内导入数据
同上
(5)导出war(不包含tomcat服务,只有业务逻辑),默认的导出格式就是jar包
修改配置/my_soft/RuoYi/ruoyi-admin/pom.xml控制导出包格式为war包
<packaging>war</packaging> #修改
<dependencies> #增加
<!-- 多模块排除内置tomcat,增加下面这段 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
cd /my_soft/RuoYi
mvn clean package -Dmaven.test.skip=true
显示BUILD Success代表导出成功,最后得到war包
[root@web01 /my_soft/RuoYi]# find . -name '*.war'
./ruoyi-admin/target/ruoyi-admin.war
(6)安装tomcat来拉起war包
tomcat------》服务
war包-------》应用
tomcat对下游的war是直接调用,没啥协议
tomcat本身对上游提供的是http协议
部署jdk1.8+tomcat9.0
wget https://dlcdn.apache.org/tomcat/tomcat-9/v9.0.89/bin/apache-tomcat-9.0.89.tar.gz --no-check-certificate #链接可能更新,自己去网站上找
tar xf apache-tomcat-9.0.89_\(1\).tar.gz -C /usr/local/
ln -s /usr/local/apache-tomcat-9.0.89 /usr/local/tomcat # 做链接
/usr/local/tomcat/bin/catalina.sh start # 启动
# catalina.sh start catalina.sh stop 没有restart指令
### 默认监听8080 端口 connector port=" xxx "
(7)把war放到tomcat 的网站应用根目录下:/usr/local/tomcat/webapps/
### /usr/local/tomcat/logs/ 日志路径
/usr/local/tomcat/webapps/ 应用路径
/usr/local/tomcat/conf/server.xml 配置文件
cp /my_soft/RuoYi/ruoyi-admin/target/ruoyi-admin.war /usr/local/tomcat/webapps/
(8)访问tomcat
http://192.168.71.112:8080/ruoyi-admin # 不加具体路径默认访问 ROOT
测试账号admin 密码:admin123
# http://192.168.71.112:8080/ROOT/ruoyi-admin (默认访问)
5、web层服务器配置nginx转发tomcat
nginx(proxy_pass)——-------------http协议------------》tomcat
yum install nginx -y
vim /etc/nginx/nginx.conf #删除自带的server,自己新建一个
[root@web01 /usr/local/tomcat/webapps]# cat /etc/nginx/conf.d/www.conf
server {
listen 9999;
server_name localhost;
location / {
# 把请求转发到上面定义的Tomcat服务器
proxy_pass http://127.0.0.1:8081;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
[root@web01 /usr/local/tomcat/webapps]# systemctl restart nginx
[root@web01 /usr/local/tomcat/webapps]#
访问:http://192.168.71.112:9999/ruoyi-admin/login
# http://192.168.71.112:9999/ROOT/ruoyi-admin/login(默认访问)
# 访问时依然要带具体uri,不带默认访问ROOT,所以依靠nginx的rewrite实现不带uri访问对应应用
6、tomcat的配置介绍
<server> ---> 可以监听一个端口,从此端口上可以远程向该实例发送shutdown关闭命令。
<service> ---> 是一个逻辑组件,用于绑定connector和container,有一个service就是一个服务
<connector PORT /> --->相当于nginx中的listen, 此处监听的端口才是对外暴露服务的端口,connector称之为连接器,它监听到的请求会交给engine具体处理处理
<engine>---> 接请求,按照分析的结果将相关参数传递给匹配出的虚拟主机
<host name=www.a.com appBase=/www/a > ----> 相当于nginx中的server_name
<context path="" docBase=/www/a /> ---> 相当于nginx中的localtion
<context path="/xuexi" docBase=/www/a/xuexi />
</host>
<host>
<context />
</host>
</engine>
</service>
</server>
#######################---------------------------------------->
server {
listen PORT; # 对应connetcor组件
server_name www.a.com; # 对应于<host name=www.a.com>
location / { # 对应于context path="",没错context就相当于nginx的localtion指令
root html; # 对应于docBase
}
location /xuexi { # 对应于context path="/xuexi"
root html/xuexi;
}
}
###### 实例:
访问路径 对应代码文件路径
www.egon1.com:8080/test_uri1/ --------->/test1/xxx/ (------->appBase+docBase)
www.egon1.com:8080/test_uri2/ --------->/test1/yyy/
www.egon1.com:8080/ ---------------------->/test1
www.egon2.com:8080/test_uri3/---------->/test2/zzz
www.egon2.com:8080/----------------------->/test2
curl www.egon1.com:8080/
curl www.egon1.com:8080/test_uri1/
curl www.egon1.com:8080/test_uri2/
curl www.egon2.com:8080/test_uri3/
curl www.egon2.com:8080/
# 一个tomcat、一个端口--------可以对应多个虚拟主机(域名)及其所对应的文件
八、Nginx详解
轻量级的高性能 Web 服务器、反向代理服务器及电子邮件(IMAP/POP3)代理服务器,同时也是一款轻量级的套接字服务
一 nginx特点
1.1 功能多、用途广
(1)如果是一些静态文件(html、css、js、图片)nginx可以直接返回
(2)在web层服务放一个nginx,可以为web服务器增加很多功能
--------》动静分离
--------》增强安全
--------》uri路径的rewrite
--------》控制一些静态文件缓存到访问者
--------》日志记录
fastcgi_pass #对接协议
proxy_pass
uwsgi_pass
(3)七层负载均衡
(4)四层负载均衡
1.2 性能强悍(epoll网络io模型)
(1)内存消耗少,启动极快
(2)采用异步非阻塞事件驱动模型(epoll网络IO模型),从而使其高并发能力极强,在互联网项目中广泛应用。
(3)开源软件,免费
(4)稳定性高,用于反向代理(负载均衡),宕机的概率微乎其微。
(5)支持热部署。在不间断服务的情况下,对软件版本升级。
二、安装nginx
1、yum 安装
安装最新stable版:从官网找源:https://nginx.org/en/linux_packages.html
其他的stable版,可以从其他源里找
例如epel
yum install epel -y
2、源码安装 可以定制化
yum install gcc* glibc* -y
yum install -y pcre pcre-devel
yum install -y zlib zlib-devel
yum install -y openssl openssl-devel
wget https://nginx.org/download/nginx-1.22.1.tar.gz
[root@localhost opt]# tar -zxvf /opt/nginx-1.12.2.tar.gz # 解压到当前目录
[root@localhost opt]# cd nginx-1.22.1/
# 配置参数(具体参数可以./configure --help命令查看)
[root@localhost nginx-1.22.1]# ./configure --prefix=/usr/local/nginx1.12.2 --with-http_stub_status_module --with-http_ssl_module
make # 编译
make install # 安装
[root@localhost nginx-1.22.1]# /usr/local/nginx1.12.2/sbin/nginx -v # 验证
nginx version: nginx/1.22.1
# 制作软连接:一般./configure指定的prefix目录都会具体到nginx的版本,这样方便区分,但是在用的时候一般都会做软连接,这样既方便用也方便后续升级
[root@localhost nginx-1.22.1]# ln -s /usr/local/nginx1.12.2 /usr/local/nginx
# 配置环境变量/etc/profile.d/nginx.sh
export PATH=$PATH:/usr/local/nginx/sbin #使指令全局有效
# system管理配置
#源码包安装后没有办法使用system管理,需要我们自己配置
[root@localhost /usr/lib/systemd/system]# vim /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginx - high performance web server
Documentation=http://nginx.org/en/docs/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s stop
[Install]
WantedBy=multi-user.target
[root@localhost ~]# systemctl daemon-reload #加载新的unit (*.service)配置文件
三、nginx相关文件介绍
以rpm包为例
主配置文件:
/etc/nginx/nginx.conf
补充:主配置文件里还会用include引入一些子配置到当前位置
include /etc/nginx/conf.d/*.conf
代理相关的配置:
/etc/nginx/fastcgi_params
/etc/nginx/uwsgi_params
编码相关:
/etc/nginx/mime.types # content-type与扩展名
管理命令
/usr/sbin/nginx
日志相关文件
/var/log/nginx
logrotate---->/etc/logrotate.d/nginx #nginx的日志切割配置
四、nginx常用命名参数
nginx -c /etc/nginx/nginx.conf #启动 Nginx 服务器并指定配置文件路径(源码安装下使用)
# 对于已经启动的nginx,我们可以用-s为该进程发信号
nginx -s reload # 不重启nginx的情况下重新加载配置文件
nginx -t # 检查配置是否有错误 syntax is ok代表正常
五、nginx平滑升级
ln -s /usr/local/nginx1.20.1 /usr/local/nginx
源码编译安装了一个新版本/usr/local/nginx1.22.0
rm -rf /usr/local/nginx # 删除旧的不会影响nginx进程运行因为已经加载至内存中
ln -s /usr/local/nginx1.22.0 /usr/local/nginx
改动配置后,reload重载
/usr/local/nginx/sbin/nginx -s reload
六、nginx的基础配置(含日志)
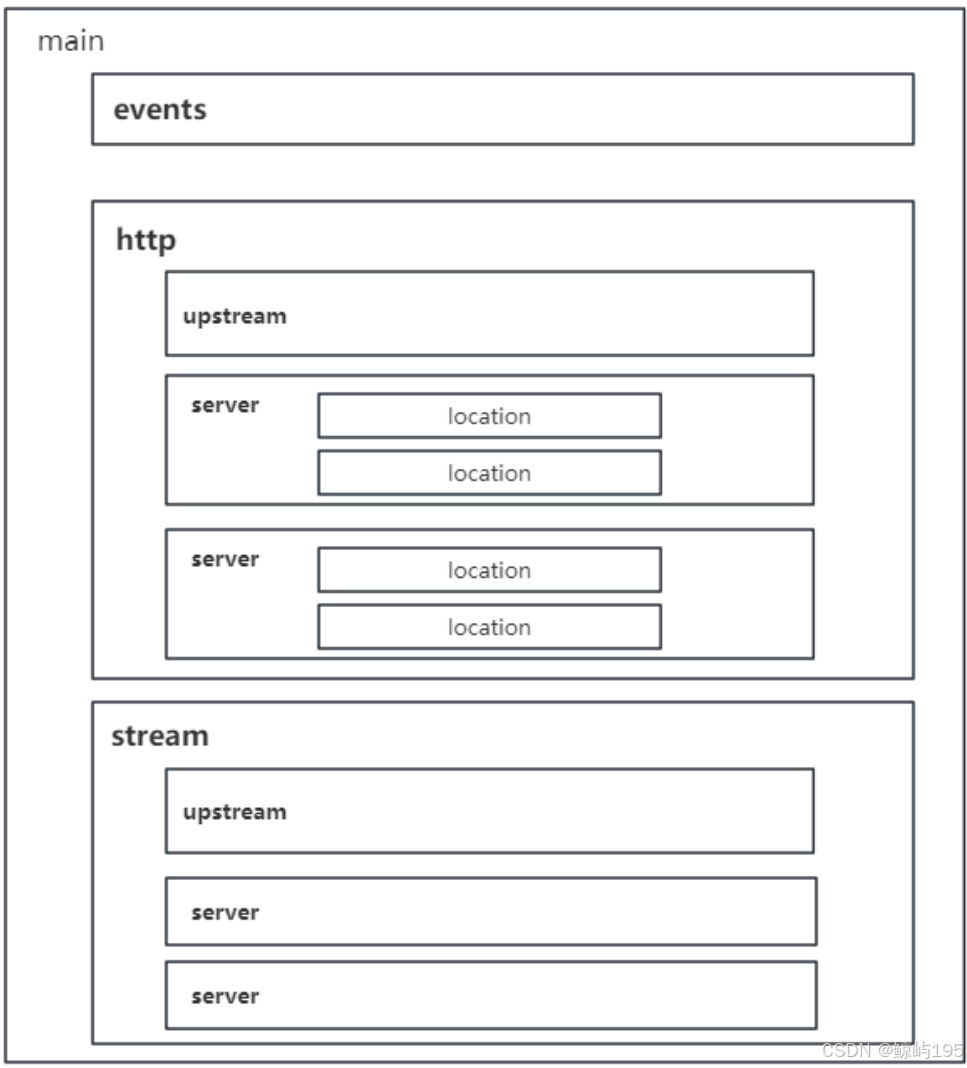
一些全局配置 # 1、全局配置
events { ... } # 2、事件驱动配置
http{ # 3、http模块配置
upstream {}
server{
location { ... }
}
}
stream{ # 4、stream模块配置
upstream {}
server{
location { ... }
}
}
main:全局配置,所有其他配置块都包含在其内部
events 块:控制Nginx处理连接的方式。
http 块:Nginx处理http请求的主要配置块。
upstream块:配置负载均衡
server块:Nginx中主机配置块,可用于配置多个虚拟主机。
localtion块:可以有多个,用于匹配uri路径
stream块:stream做四层负载均衡并不常用
upstream块:配置负载均衡
server块:四层的server块内部必然是不能写location匹配uri地址
补充:
1、http块与stream块内的upstream及server块均可以有多个
2、在 Nginx 配置文件中,每一条指令配置都必须以 “;” 分号结束
--------------------------------------------------------------------------------------------------------------------------------- ####### 内层定制的优先级高于外层,内层定制以内层为准,内层没有遵循外层 #######
全局配置:
# 1、运行用户(nginx子进程用户) nginx本身的进程用户身份取决于启动它的用户
user nobody;
# 2、工作的worker进程数,通过与cpu核数保持一致,设置为auto,nginx会自动配置为核数。
# 注意:nginx启动后还有一个master进程负责与用户交互响应会话,具体干活的是worker进程
worker_processes auto;
# 3、全局错误日志:日志级别有:debug、info、notice、warn、error、crit、alert
#error_log logs/error.log;
error_log logs/error.log notice;
error_log logs/error.log info;
# 4、PID文件
pid logs/nginx.pid;
# 5、include用来引入配置文件
# 下述指令的含义:nginx启动时会加载动态dynamic模块的所有配置,确保动态模块都加载 到nginx中
include /usr/share/nginx/modules/*.conf;
---------------------------------------------------------------------------------------------------------------------------------
events配置:
网络io模型:
epoll(最强)--------->nginx能抗住高并发的原因之一
每个网络io都捆绑自己的事件(回调函数)
一旦数据到达,就立即自己主动触发事件--》告知自己的数据已经抵达
nginx只需要去队列去现成的链接来处理即可(这些现成的链接共同的特点都是数据已经 放到你的操作系统里了)
select: 遍历网络链路看是否有请求到达
问题:链接越多,效率越低
poll
控制nginx支持的最大并发量:
worker_processes 4;
worker_connections 1024; # 单个worker(默认单线程)能处理的最大链接数
### 当前nginx服务器能处理的最大并发请求数=worker_processes*worker_connections
注意,配置的时候要注意(并不是越大越好):
1、结合硬件
2、结合文件描述符的设置,调大描述符也要调大
---------------------------------------------------------------------------------------------------------------------------------
http模块配置:
http {
#1、设定日志输出模板
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
#2、网络io优化参数(http)
sendfile on;
减少数据在操作系统的内核态和用户态之间的拷贝次数----从硬盘读取数据到操作系统用户态 缓冲区,再从用户态缓冲区发送至操作系统网络缓冲区(内核态),最后调用网卡发送数据 至网络;如果开启sedfile,内核会将数据直接从硬盘取出发送到网络中。
tcp_nopush on;
通常与sendfile一起用,当 tcp_nopush 设置为 on 时,Nginx 将尽可能发送较大的 TCP 数据 包,减少 TCP 报文的数量,提高传输效率。这对于减少网络传输中的 TCP 慢启动阶段,减 少网络延迟和提高网络吞吐量非常有用。这在传输大型文件或使用 HTTP/1.1 的 Keep-Alive 长连接时特别有效。
tcp_nodelay on;
数据不在缓冲区停留或等接受到ack才发出,这会减少延迟,但可能会造成网络利用率低。 这个选项在处理需要快速响应的短数据流(例如HTTP/1.1的keep-alive连接)时非常有用。
keepalive_timeout 65; #开启长连接
keepalive_requests 100; #每个长连接在关闭前能处理的最大请求数量
gzip on; #开启gzip压缩,节省带块加速网络传输
client_header_buffer_size 128k; #用于保存客户端请求头的缓冲区的大小,当客户端发 送的请求头超过这个大小时Nginx 将使用临时文件来 保存请求头。这可以防止恶意客户端发送大量数据来 消耗服务器资源
large_client_header_buffers 4 128k; #设置多个缓冲区来保存
include /etc/nginx/mime.types; #定义了nginx可以识别的网络资源类型,例如css、js、 jpg等从而加入标识到响应包中使浏览器能启用对应的 功能来解析数据
default_type application/octet-stream; #标识这种内容不会被浏览器解析,而是作为一个下 载文件来处理
### include /etc/nginx/conf.d/*.conf -------->将所有server写成 .conf文件放入对应目录中使主配置文件简洁美观
server {
#侦听80端口
listen 80;
listen [::]:80; # [::]: 这代表 IPv6 地址中的一个缩写,它等同于所有的 IPv6 地址,类似于 IPv4 中的 0.0.0.0
server_name www.nginx.cn; #定义使用 www.nginx.cn访问
root /usr/share/nginx/html; # 定义服务器的默认网站根目录位置强烈建议用绝对路径
access_log logs/nginx.access.log main; #设定本虚拟主机的访问日志
#默认请求(兜底)
location / {
root /a/b/c; # 优先级高于外部
index index.php index.html index.htm; #定义首页索引文件的名称(按顺序依次查找)
}
# 定义错误提示页面,出现以下状态码,uri定位到/50x.html,然后触发二次localtion匹配,直接对上location = /50x.html;不写location = /50x.html也可以,会依次对所有的location进行遍历匹配,最后匹配不到使用server层的默认路径大大增加了匹配所用的时间。
error_page 500 502 503 504 /50x.html;
location = /50x.html { # =号的匹配更精确,所以优先级更高
# 这里没有指定root目录,所以向外层查找,找到server层里定义的root,去该root指定的目录下找/50x.html
}
#静态文件,nginx自己处理
location ~ ^/(images|javascript|js|css|flash|media|static)/ {
#如果频繁更新,则可以设置得小一点。
expires 30d; #过期30天,静态文件不怎么更新,过期可以设大一点,
# 这里没有指定root,那去外层也就是server层定义的root指定的目录里找文件
} # ------->nginx返回给客户端浏览器的响应包里自动设置缓存时间
#PHP 脚本请求全部转发到 FastCGI处理. 使用FastCGI默认配置.
location ~ .php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
location ~ /.ht {
deny all; #禁止访问 .htxxx 文件
}
}
}
补充:nginx作为反向代理服务器
#与后端服务器建立长连接----增加keepalive设置(1.1.4或以上版本生效)
upstream backend {
server backend1.example.com;
server backend2.example.com;
keepalive 32;
}
# upstream与server属于同一层级,隶属于http模块,可以一同写写成 .conf文件放入对应目录中使主配置文件简洁美观
---------------------------------------------------------------------------------------------------------------------------------
日志模块配置:
# 一般在server层内使用日志,server内定义了日志访问路径和格式就以server内的为准,server没有定制的就以http层定义的日志访问格式和路径为准
# 每个server指定自己的日志文件,但需统一放到定义好的日志路径上
# 根据实际情况不记录日志(四层负载均衡)或者调整运行日志的级别可以优化nginx的运行-------减少io操作减轻nginx的压力
# 补充:日志写入涉及到io行为,所以并不是越多越好
日志定制的位置与优先级
全局
http层
server层
日志的种类:
访问日志
日志的格式------一般位于http块内
log_format 日志格式名 日志格式
日志的路径-------一般位于server块内
access_log 日志路径 日志格式名;
错误日志
不能定制日志的格式,但是可以定制日志级别
emerg (表示系统不可用)
alert (需要立即采取措施)
crit (更严重的错误)
error 错误
warn 警告
notice(默认)
info------->软件正运行(运行日志)
debug(调试时使用,记录大量详细信息)
#日志格式参数
$remote_addr # 记录客户端IP地址
$remote_user # 记录客户端用户名
$time_local # 记录通用的本地时间
$time_iso8601 # 记录ISO8601标准格式下的本地时间
$request # 记录请求的方法以及请求的http协议
$status # 记录请求状态码(用于定位错误信息)
$body_bytes_sent # 发送给客户端的资源字节数,不包括响应头的大小
$bytes_sent # 发送给客户端的总字节数
$msec # 日志写入时间。单位为秒,精度是毫秒。
$http_referer # 记录从哪个页面链接访问过来的(反爬的一种方法)
$http_user_agent # 记录客户端浏览器相关信息
$http_x_forwarded_for #记录经过的所有服务器的IP地址
$X-Real-IP #记录起始的客户端IP地址和上一层客户端的IP地址
$request_length # 请求的长度(包括请求行, 请求头和请求正文)。
$request_time # 请求花费的时间,单位为秒,精度毫秒
# 注:如果Nginx位于负载均衡器,nginx反向代理之后, web服务器无法直接获取到客 户端真实的IP地址。
# $remote_addr获取的是反向代理的IP地址。 反向代理服务器在转发请求的http头信息中,
# 增加X-Forwarded-For信息,用来记录客户端IP地址和客户端请求的服务器地址。
日志切割
logrotate-----由cron定时任务调度的一个程序,定时任务通常在/etc/cron.daily/目录下
应用程序如果是由rpm包安装会自动生成对应的logrotate配置文件
## cat /etc/logrotate.d/nginx
/var/log/nginx/*.log { # 指定要切割的日志
daily #每天切割日志
missingok #忽略日志丢失
rotate 52 #日志保留时间 52天
compress #日志压缩
delaycompress #延时压缩
not if empty #不切割空日志
create 640 nginx adm #切割好的日志权限
sharedscripts #开始执行脚本
postrotate #标注脚本内容
if [ -f /var/run/nginx.pid ]; then#判断nginx启动
kill -USR1 `cat /var/run/nginx.pid` #access.log不存在时,重新生成一个,存在则继续用已存在的不会产生新的access.log
fi
endscript #脚本执行完毕
}
# 同时,你可以使用下列命令来强制执行一次logrotate:
/usr/sbin/logrotate -f /etc/logrotate.conf
/usr/sbin/logrotate -f /etc/logrotate.d/nginx
七、如何应对高并发(TCP详解)
一、nginx的抗并发能力很强,能不能更强(******)
# 在使用网络io模型 epoll 的基础上
1.1 半连接队列与全连接队列
socket抽象层-------把传输层的tcp/udp协议封装成简单的功能供应用层应用程序调用
bind()----绑定ip+port(一个端口多个ip) listen()----开辟半连接池,监听半连接队列(SYN队列)
connect()----连接至服务端 accept()----取全连接队列(accepet队列)的连接进行收发消息
write()----基于连接写消息 read()----基于连接读消息 close()----关闭连接
### 底层依然是tcp的三次握手(操作系统的内核进行操作)
# 在建立好连接通道后双方通信还需基于规定的协议去交流,理解-------应用层协议(基于特定的协议规则去封装、解封装)
tcp----stream(流式协议)
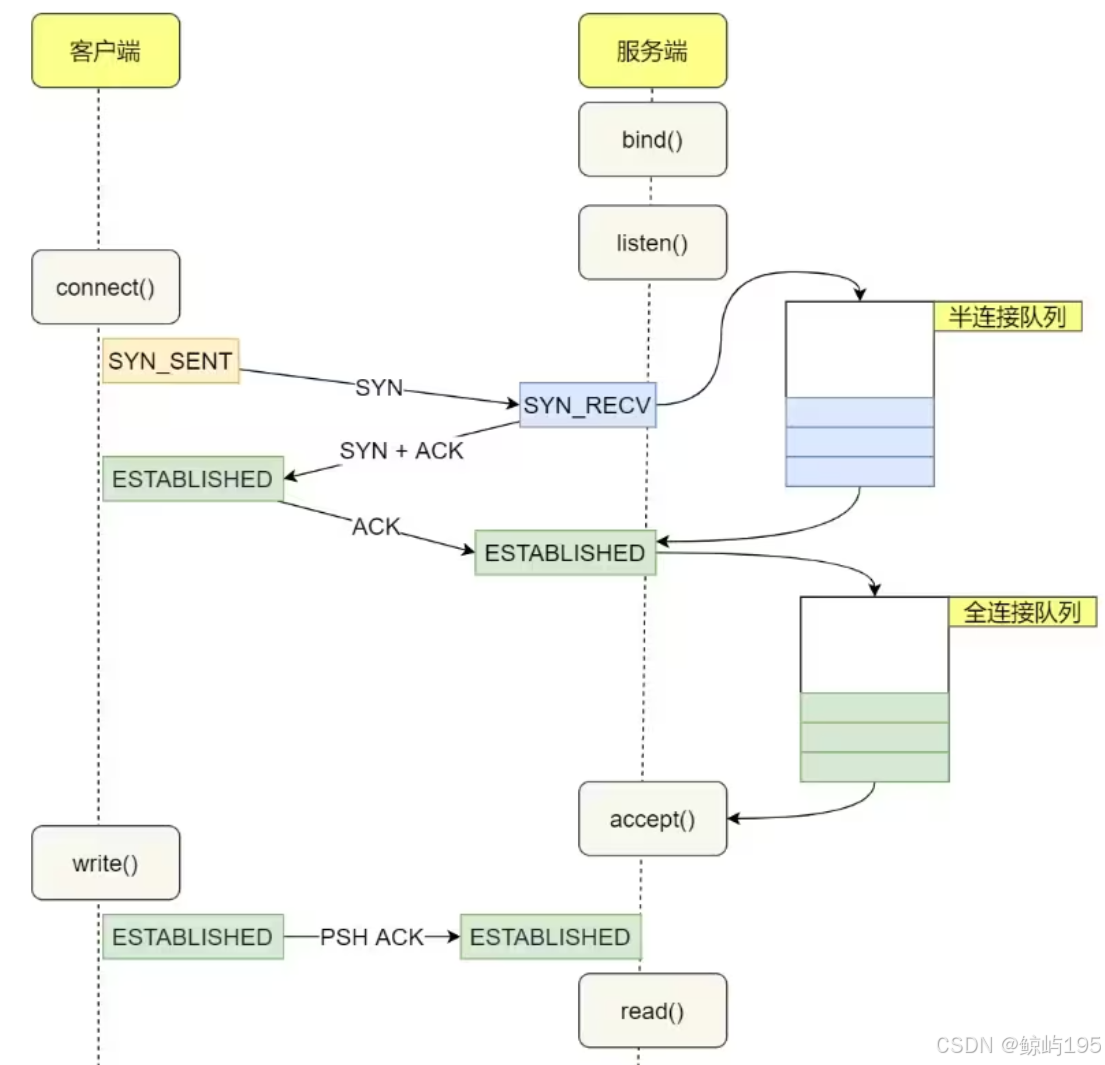 半连接队列(尚未完成三次握手)---->系统内核 全连接队列(完成三次握手)---->应用程序
半连接队列(尚未完成三次握手)---->系统内核 全连接队列(完成三次握手)---->应用程序
优化:
somaxconn tcp_max_syn_backlog 是 Linux 内核的参数,默认值都是 128
sysctl -w net.core.somaxconn=65530 # 设置全连接池大小
sysctl -w net.ipv4.tcp_max_syn_backlog=10240 # 设置半链接池大小
1.2 nginx有两种工作模式
两种工作模式,总的来说一样的地方:一个master管理多个worker进程
1、master进程:负责管理worker进程的生命周期,
发信号都是给master进程发
master进程是所有worker进程的爹
2、worker进程:负责具体工作
工作模式1(默认):所有worker进程共享同一个全连接队列
1、工作介绍
(1)master进程负责bind()、listen()之后,负责创建出多个worker进程
补充:listen就是通知操作系统开启一个半连接池、对应着也得开启一个全连接池
该全连接池是所有worker进程共享的
(2)所有worker进程,都会去同一个全连接队列里用accept()取走一个全连接
然后进行收发消息
补充:worker进程在取连接的时候无法预判该链接一会承载的请求是耗时还是不耗时
即woker进程是基于链接调度的,而不是请求
2、特点:所有worker进程共享一个全连接队列(都是由master的listen发起的)
3、优点:
某个worker进程拿到一个链接之后,该链接里发来的请求
是非常耗时的,此时该worker的处理能力在变弱--》从全连接队列里拿新链接来处理的能力变慢
此时不会影响其他worker的处理能力,因为大家的队列是共享的
总结:基于共享的方式,会平衡所有worker进程的压力
4、缺点:
全连接队里是共享的,而worker是并发/并行去队列里拿链接的
这涉及到争抢问题,需要加锁处理,会带来额外的损耗
工作模式2:每个worker进程独享自己单独的一个全连接队列
1、工作模式介绍
(1)还是由master进程发起listen监听端口
每个worker进程会重用reuse主进程的那个端口,即端口都一样
但是每个worker会单独开辟一个自己的全连接队列
(2)每个worker进程都处理自己独享的那一个全连接队列
其他worker进程无法看到你的这个队列
2、特点::每个worker进程都独享自己的listener全连接队列
3、优点:
不需要多个进程/线程竞争某个公共资源,减少竞争的资源消耗,处理效率自然提高了。
4、缺点:
当某个worker进程处理不过来,其他worker不能为其分摊压力
server {
listen 80 reuseport;
listen 443 ssl http2 reuseport;
server_name xxx.xxx.com;
charset utf-8;
# 同一个nginx实例下针对同一个ip+port,只需要其中一个设置了reuseport即可全部生效
ss -lnt |grep 8089 # 4个worker进程reuse了相同的端口
LISTEN 0 511 *:8089 *:*
LISTEN 0 511 *:8089 *:*
LISTEN 0 511 *:8089 *:*
LISTEN 0 511 *:8089 *:*
netstat -an |grep -w 8089
tcp 0 0 0.0.0.0:8089 0.0.0.0:* LISTEN
#因为是resuse重用的同一个端口,所以在系统层面netstat -an|grep 8089你当然只能看到一个端口
|
|
|
\/
线程的争抢问题加锁处理所消耗的cpu资源远远小于进程之间的争抢问题,所以基于进程独享全连接队列模式可以进行进一步优化
默认情况下nginx每个worker进程都是单线程的
为每个worker进程开始多线程
1、查看是否支持
[root@web01 ~]# nginx -V 2>&1 | sed "s/\s\+--/\n --/g" |grep threads
--with-threads # 支持
2、配置开启
[root@web01 ~]# cat /etc/nginx/nginx.conf
......
user egon;
worker_processes 4;
events {
use epoll;
worker_connections 1024;
}
thread_pool egon_pool threads=3 max_queue=1024; # 定义线程池(全局设置)
# threads 线程数 max_queue 最大队列大小
http {
#aio threads;
aio threads=egon_pool; # 启用线程池
# 启用线程池与reuseport并不冲突
server {
listen 8089 reuseport backlog=10240;
[root@web01 ~]# ps aux |grep nginx
root 7101 0.0 0.0 39352 2012 ? Ss 5月31 0:00 nginx: master process /usr/sbin/nginx
nginx 12813 0.0 0.0 39808 1936 ? S 10:50 0:00 nginx: worker process
nginx 12814 0.0 0.0 39808 1936 ? S 10:50 0:00 nginx: worker process
nginx 12815 0.0 0.0 39808 1936 ? S 10:50 0:00 nginx: worker process
nginx 12816 0.0 0.0 39808 1936 ? S 10:50 0:00 nginx: worker process
root 12953 0.0 0.0 112824 988 pts/0 R+ 11:07 0:00 grep --color=auto nginx
[root@web01 ~]# pstree 7101
nginx───4*[nginx]
[root@web01 ~]# pstree -p 7101
nginx(7101)─┬─nginx(12813)
├─nginx(12814)
├─nginx(12815)
└─nginx(12816)
[root@web01 ~]# nginx -s reload # 重载配置
[root@web01 ~]# ps aux |grep nginx
root 7101 0.0 0.0 39352 2012 ? Ss 5月31 0:00 nginx: master process /usr/sbin/nginx
nginx 12965 0.0 0.0 64380 1820 ? Sl 11:08 0:00 nginx: worker process
nginx 12966 0.0 0.0 64380 1820 ? Sl 11:08 0:00 nginx: worker process
nginx 12967 0.0 0.0 64380 1820 ? Sl 11:08 0:00 nginx: worker process
nginx 12968 0.0 0.0 64380 1820 ? Sl 11:08 0:00 nginx: worker process
root 12982 0.0 0.0 112824 988 pts/0 R+ 11:08 0:00 grep --color=auto nginx
[root@web01 ~]# pstree -p 7101
nginx(7101)─┬─nginx(12965)─┬─{nginx}(12972)
│ ├─{nginx}(12973)
│ └─{nginx}(12974)
├─nginx(12966)─┬─{nginx}(12975)
│ ├─{nginx}(12976)
│ └─{nginx}(12977)
├─nginx(12967)─┬─{nginx}(12978)
│ ├─{nginx}(12979)
│ └─{nginx}(12980)
└─nginx(12968)─┬─{nginx}(12969)
├─{nginx}(12970)
└─{nginx}(12971)
nginx应对高并发发总结:
1、开启了reuseport,让每个worker独享自己的全连接队列,减少了进程层面的资源争抢
2、为了解决worker进程繁忙的情况下无人帮其分摊的压力的问题,在worker进程内开启了多线程
好处:
1、缓解压力
2、让cpu的使用分配更加均匀
坏处:
1、又需要考虑资源争抢问题(虽然也需要考虑,但至少比进程之间的资源争抢要效率高)
2、增加了出bug风险,可能会因为某个线程的bug而引发整个进程挂掉
3、每个线程处理网络io问题的时候用的都是epoll模型
ingress-nginx:(并发能力强)------->进一步优化了上述的坏处
1、开启了reuseport
2、开启了线程池
重点:nginx worker进程调度是以连接为单位,不是以请求为单位,所以无法分别请求的耗时长短
八、虚拟主机
什么是虚拟主机?
访问一个站点,背后一定要有软件来支撑该访问
正常来讲,访问不同的站点,背后就应该启动不同的服务来支持
而虚拟主机指的是:
背后就一个软件,但是这个软件,可以承载不同站点的访问
相当于把这一个软件当成多个软件去用---》虚拟
基于域名(最常用)
### 请求头送给nginx后,nginx解包分析,根据不同的域名匹配下面不同的server name字段所以,如果你是本地测试,你必须在hosts文件里添加解析记录,用域名访问,让请求头里带着域名,nginx才能正常解析到
windows下hosts文件路径:C:Windows\System32\drivers\etc\hosts
### 不同的域名匹配各自对应的文件路径
192.168.71.15 www.egonlin.com bbs.egonlin.com blog.egonlin.com
[root@localhost conf]# vim nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name www.egonlin.com; # 可以跟多个域名(取别名)
location / {
root /usr/share/nginx/html/www;
index index.html index.htm;
}
}
server {
listen 80;
server_name bbs.egonlin.com;
location / {
root /usr/share/nginx/html/bbs;
index index.html index.htm;
}
}
server {
listen 80;
server_name blog.egonlin.com;
location / {
root /usr/share/nginx/html/blog;
index index.html index.htm;
}
}
基于端口
域名、IP相同,根据端口区分
基于ip(一个服务器上需要有多个IP)
九、location匹配url的路径部分
location是干什么用的
location是匹配url地址的路径部分
强调:只做匹配,匹配成功之后的查找资源与localtion无关
# 匹配到了之后,执行下面的跟的代码将请求的路径加到root路径后面进行查找,如果本层没有指定root就用上一层的root地址
例如:
nginx收到一个url请求http://192.168.71.15:8080/static/img/logo.jpg?user=john&width=100
location只负责匹配:/static/img/logo.jpg 路径部分(端口到问号),问号之后不管
location在哪里用
四层负载均衡不能用
只能用在七层,即只能放在http层的server层里
location的规则分类
请求http://192.168.71.15:8080/static/img/logo.jpg?user=john&width=100 的路径部分/static/img/logo.jpg
1、前缀匹配(强调强调:所有的匹配规则都必须以/开头)
location = /static/img/logo.jpg # 完全匹配,要求严丝合缝一字不落
location ^~ /static/im # 前缀匹配,^~ 后面跟着的全都普通字符,只要对上前缀就行
location /static/img # 前缀匹配,后面跟着的全都普通字符,只要对上前缀就行
后两种匹配没有优先级之分,两者都不能冲突,要谈优先级一定看谁更精准谁优先级高
区别到底在哪里?
^~的规则一旦对成功之后,就不会再走正则匹了
而不带^~的前缀匹配,在匹配成功之后,还会再去匹配正则,正则成功之后则正则,否则还是本条
2、正则匹配
location ~ 路径部分 # 区分大小写
location ~* 路径部分 # 不区分大小写
location的匹配流程或者说优先级
整体的逻辑:
先进行相对精准的------》前缀匹配
然后进行相对模糊的----》正则匹配
第一阶段:
先用localtion = 的规则去匹配请求路径,如果能对上直接结束,则不必进行后续阶段
### 对于需要频繁匹配的地址直接写location=规则立即完成匹配,大大缩短了匹配所用的时间,优化了nginx的性能
第二阶段:
在用两种前缀匹配来匹请求的路径
location ^~ 规则
location 规则 # 常规匹配
这两种本身没有优先级之分,他们的优先级看精准度,谁精准就用是谁
如果是 ^~ 此时更精准的匹配成功了,那么直接结束,不必进行后续阶段
如果是 常规的前缀 此时更精准的匹配成功了,那么不会结束,还需要仅需后续的正则匹配
第三阶段:
进行正则匹配,多个正则表达式自上而下匹配,但凡匹配成功一次,就立即结束不会再匹配后面的(正则匹配存在先后顺序)
如果正则也匹配失败了,需要分两种情况看
情况一:一与二两个阶段都是失败,那最终结果就是失败,返回上一层的ROOT路径(默认路径)中寻找
情况二:第二阶段的 常规前缀匹配 成功,而进入的正则匹配失败了,此时就用常规匹配
实例:
[root@web01 ~]# cat /etc/nginx/conf.d/www.conf
server {
listen 8081;
server_name www.egonlin.com;
# 1、前缀匹配三大类
location = /eGon/xxx {
default_type text/plain;
return 200 "1111111111111111111111111111111";
}
location ^~ /eGon/xxx/yy {
default_type text/plain;
return 200 "2222222222222222222222222222222";
}
location /eGon/xxx/yyy.txt {
default_type text/plain;
return 200 "3333333333333333333333333333333";
}
# 2、正则匹配两大类
#location ~* ^/eGon { # 注意写成^eGon可就是直接从e这个字符开始匹配了,而不是从uri路径的最开头左斜杠开始啊
# default_type text/plain;
# return 200 "4444444444444444444444444444444";
#}
location ~* \.Txt$ {
default_type text/plain;
return 200 "5555555555555555555555555555555";
}
location ~* \.TXT$ {
default_type text/plain;
return 200 "6666666666666666666666666666666";
}
location ~ \.txt$ {
default_type text/html;
return 200 "location ~ \.text";
}
}
十、return指令(状态码)
return----停止处理请求且后续指令不再执行,直接返回响应码或者重定向到其他url
常见状态码(code):
200:请求成功
301:永久转移到其他 URL 302:临时转移到其他 URL
403:客户端没有对目标资源的访问权限 404:请求资源不存在
400:客户端发送的请求存在语法错误(恶意请求----例如请求头过大-增大请求头缓冲区)
401:用于客户端的身份验证(nginx的访问认证模块)
500:内部服务器错误 503:服务端故障
502: 网关/代理服务器无法与上游服务器通信 504:网关/代理服务器链接上游服务器超时
301:永久重定向
第一次请求,会打到服务端,然后由服务端发起重定向,浏览器会缓存下来本次重定向
之后浏览器发起请求,就不会打到服务端,浏览器会自动帮你完成重定向
302:临时重定向
每次请求,都会打到服务端,然后由服务端发起重定向
### default_type------》对应http响应头里的content_type----让浏览器知道要调用什么模块去解析
location ^~ /return00 {
return 403; #直接返回状态码
}
location ^~ /return01 {
default_type text/plain; #必须告诉浏览器return内容的类型----纯文本格式
return 200 'request success';
}
location ^~ /return02 {
return 302 /hello; #uri部分的重定向
}
location ^~ /return03 {
return http://www.egonlin.com; #整个url地址的重定向 (不指定状态码默认为302)
}
location ^~ /return05 {
default_type application/octet-stream; #必须告诉浏览器return内容的类型--浏览器直接进行下载
return 200 'egon say hello';
}
location ^~ /return06 {
default_type text/html; #必须告诉浏览器return内容的类型----html文件
return 200 'xxx.html';
}
十一、root指令与alias指令 index指令
相同点:都是用来指定资源的查找路径的
不同点:
root指令是为当前location定义了访问的根目录,完整的资源路径=root指定的根目录+请求的uri路径
alias指令也规定了一个路径,但是该目录不是根目录,alias会把自己的路径替换为localtion规则匹配的路径
root:
192.168.71.112:9999/egon/xxx/yyy/zzz
root /var/www/html # 完整的路径:/var/www/html/egon/xxx/yyy/zzz
location /egon/xxx {
root /var/www/html;
index index.html a.txt b.txt;
}
用户请求:http://192.168.71.15/egon/xxx
nginx会去:/var/www/html/egon/xxx下依次查找index.html、a.txt、b.txt
# 如果本层没有root路径就去上一层找
alias:(结合location使用)
192.168.71.112:9999/egon/xxx/yyy/zzz
location /egon/xxx {
alias /a/b/c; # 完整的路径:/a/b/c/yyy/zzz
}
index
当客户端的请求为目录而非一个具体文件的时候,nginx会根据index所指定的文件列表在root路径下按序查找文件作为默认响应,若存在就返回该文件;
如果所有的都没查找到,返回403/404错误;如果开启了autoindex,则会返回目录列表
# index 指令依赖于 root 指令来确定查找索引文件的根目录
# 在部署静态网站时,通常会将 index.html 作为默认的索引文件。这样,当用户访问网站的根目录时,Nginx 会自动返回 index.html 页面。
### index指令或try_files指令都会触发二次匹配------不指定路径/为默认路径时生效,存在指定具体的文件路径的时候直接去对应路径获取文件
所以当请求https://egonlin.com/(默认路径)时,匹配到location / 会执行index指令依次序查找文件,找到了一个文件叫index.php则使用/index.php发起内部重定向,就像从客户端再一次发起请求一样,Nginx会再一次搜索location,毫无疑问匹配到第二个~ \.php$, 然后交给FastCGI处理
说明:index.php内通常编写了php语言写的动态处理程序,该程序nginx本身时无法处理的,必须交给有php-fpm服务的服务器处理
location / {
root /a/b/c;
index index.php index.html index.htm; #定义首页索引文件的名称(按顺序依次查找)
}
十二、代理指令
proxy_pass------http协议
fastcgi_pass------fastcgi协议
uwsgi_pass------uwsgi协议
代理:
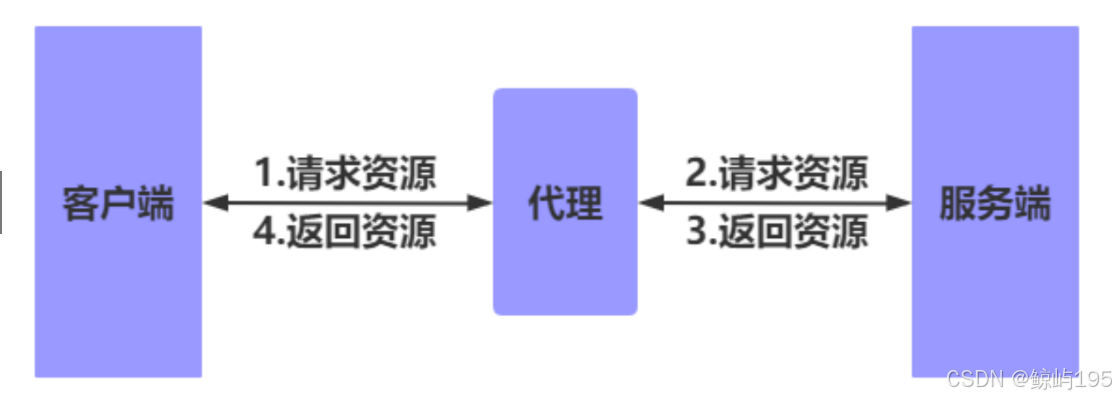
正向代理
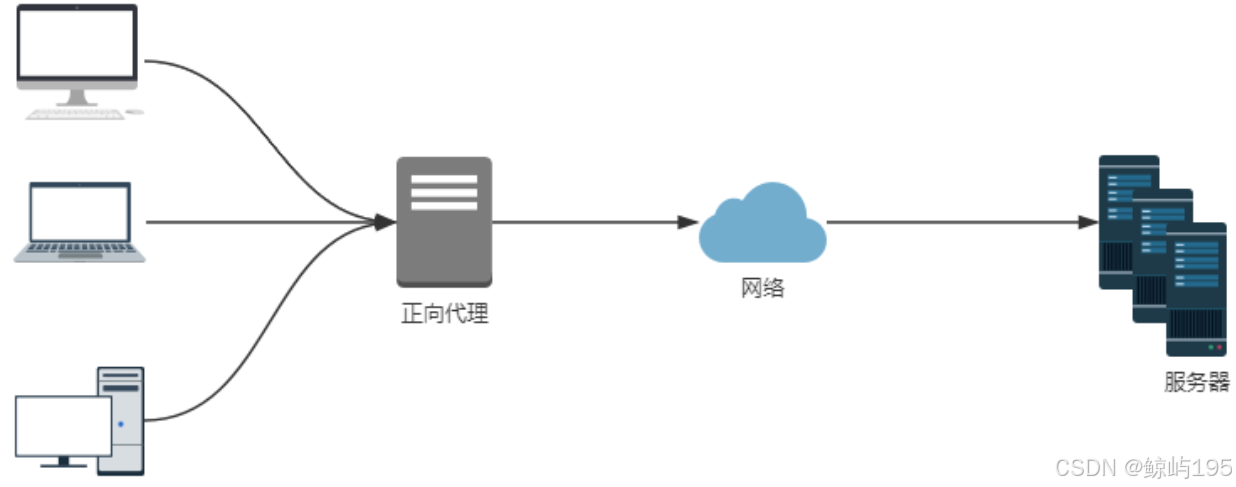
正向代理代理的是客户端的请求
特点:
可以放在内网,也可以放在外网
客户端使用时,需要设置自己的代理服务(squid、varnish)
可以通过代理服务器去访问外网 客户端访问软件服务器--->软件服务器识别请求,国内发给国内服务器,国外发给国外服务器----->通过国外服务器访问外网
透明代理
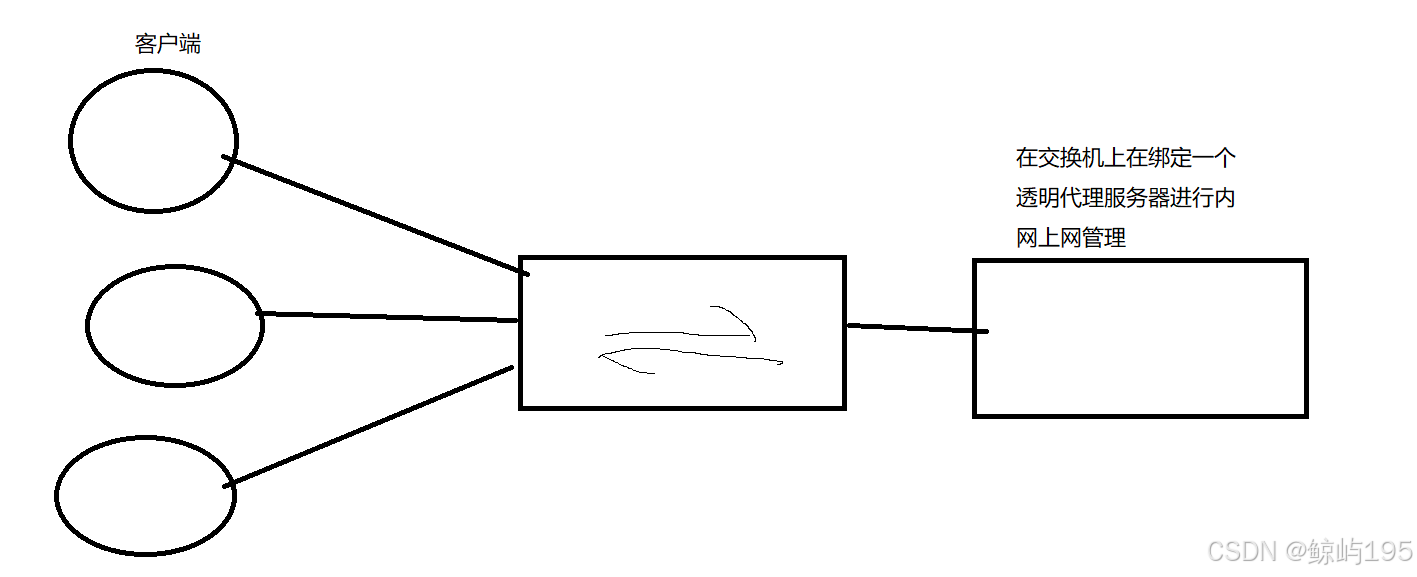
与正向代理一样,都是用来代理客户端的请求的
不一样的点:
1、透明代理意味着对客户端是完全透明的,即用户端
无需设置指向代理服务器
2、透明代理服务器必须跟客户端在同一个内网里
主要用做:用户上网行为分析、屏蔽
反向代理
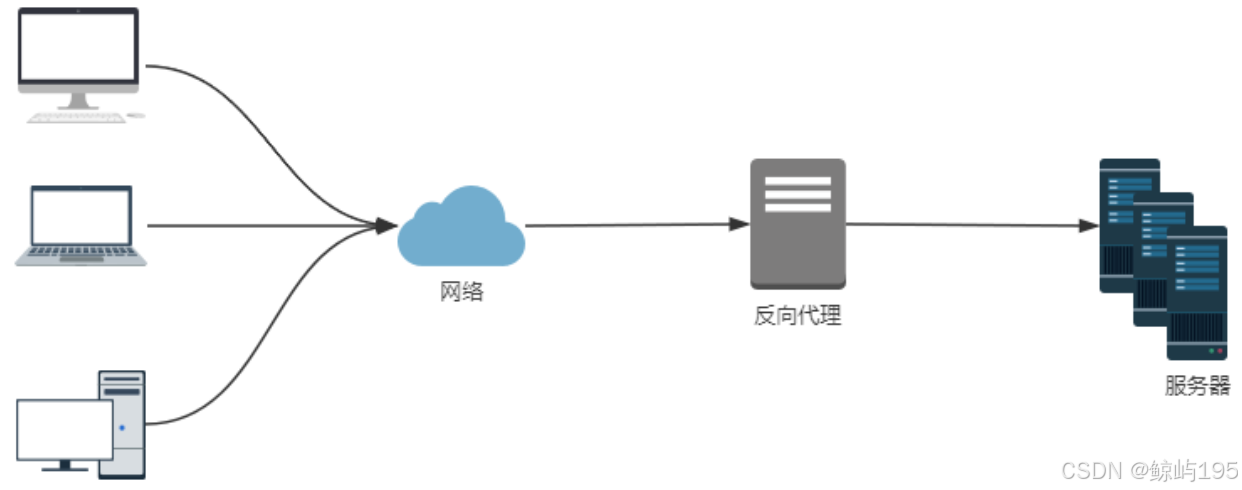
反向代理代理的是服务端(负载均衡)-----把反向代理服务器当成真正的服务器
十三、upstream模块
负载均衡
upstream可以包含多台主机,用于负载均衡
放置的地方:
http { #七层负载均衡
upstream xxx {
server 192.168.43.100:8080 max_fails=3 fail_timeout=5s;
server 192.168.43.101:8080 max_fails=3 fail_timeout=5s;
server 192.168.43.102:8080 backup;
server 192.168.43.103:8080 down;
}
server {}
}
stream { #四层负载均衡
upstream xxx {}
server {}
}

慢启动
如果正在经历高并发,瞬时并发量很高的情况下
如果直接新增一台机器,会到大量的流量瞬间流入新机器,导致连接池打满,用户无法访问
所以应该采用慢启动slow_start(仅nginx的商业版本nginx plus支持),慢启动指的是新上线的机器应该在一段时间内慢慢接受流量
慢慢的把该建立的链接都建立ok,才能正常提供服务,否则会一下子被打死(慢启动的时间根据实际情况合理定义)
对nginx开源版,本身不支持slow_start参数
实现类似慢启动的方案:
1、在在流量不高的情况,提前新增机器
2、手动控制,每隔一段时间加一点权重 weight
或者用haproxy:
提供了slow_start的功能
upstream模块的健康检查:
1、下述参数只能针对端口没有响应
server 192.168.43.100:8080 max_fails=3 fail_timeout=5s
2、而我们有可能遇到端口是可以正常响应,但是因为该端口对应的软件有bug
而导致有响应,但是是错误的响应,max_fails、fail_timeout无法检测出来
如何应对?
proxy_next_upstream error timeout http_500 http_502 http_503 http_504 http_403 http_404; #认为此台服务器挂掉,跳过此台服务器去下一台返回给客户端正常的响应
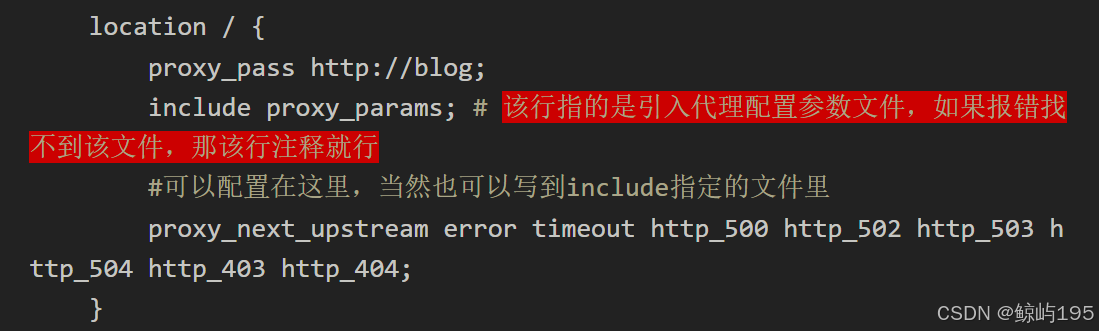
负载均衡调度算法
问题出现后的弥补措施
nginx原生------rr weight ip_hash least_conn
nginx本身不支持------url_hash fair
轮询(默认算法) 按时间按顺序逐一分配到不同的后端服务器(默认)
weight 加权轮询,weight值越大,分配到的概率越高
least_conn 最少链接数,哪个机器链接数少就往哪发(但每条链接的所用时间无法判断)
fair 公平调度算法----基于加载时间的长短进行负载均衡(比最小连接调度更智能)
ip_hash 保持客户端访问的web服务器不变,打破了负载均衡的功能,但是对于不启用共 享存储使用本地保存的会话session来说起到了保持会话的作用-------但基本不用
url_hash 与ip_hash相同,根据访问url的hash结果分配,每个url定向到同一个后端服务器
提前进行健康检查
负载均衡的健康检查(拓展,了解即可)------原生不支持
必须要源码安装对应版本的nginx,下载第三方模块,进入nginx目录打补丁,最后进行make&&make install
haproxy内部支持健康检查
十四、动静分离与资源分离
1、动静分离(*****)
区分动态与静态的前提:软件的版本尚未更新,软件处于正常运行状态
静态请求:
请求的结果基本不会变化,每个人来请求拿到的结果都一样
例如图片、js、css
动态请求
请求的结果会跟你提交的信息而发生变化,每个来请求结果都不一样
例如:转账、添加购物车、付款、登录
为何分离?
分离也好、分层也好,都是一种优化的思想
只要遇到一些集群中性能或者管理上的问题,解决思路:
1、能不能抽离出来
2、只要能抽离出来,就可以单独有针对性的进行优化
动静分离有三大类方案:
1、后端在返回前端代码时,静态文件就配置好了cdn地址
2、web服务器
nginx -------》php-fpm
===> 不是所有的静态请求都走cdn
一些静态请求还是会打到我们自己的web服务器上
此时web服务器上的动静分离依然是有收益的(cdn溯源的时候依然会在站点上用到动静分离)
更精细化的管理(缓存到本地,比cdn更快)
expires 30d;
安全加固
3、七层负载均衡
方案1:(不推荐)
静态文件也用共享存储挂载给七层负载均衡
七层负载均衡=负载均衡(只派活不干活)+静态资源服务器(响应静态请求) (响应部分指定的静态请求)
强调:最好是专业人干专业的事情,符合分层的思想
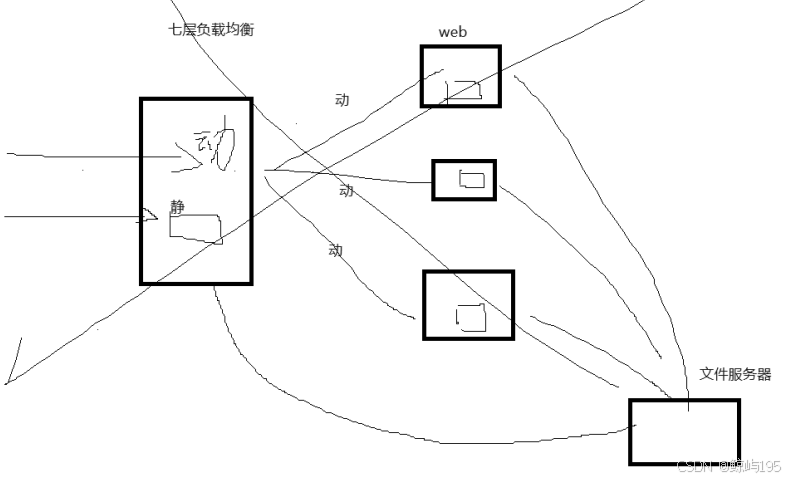
方案2:
动静抽离出不同的服务器集群
1、应用集群(动态请求)
2、静态资源服务器(静态请求)
七层负载均衡将动、静请求分发给不同的集群来处理
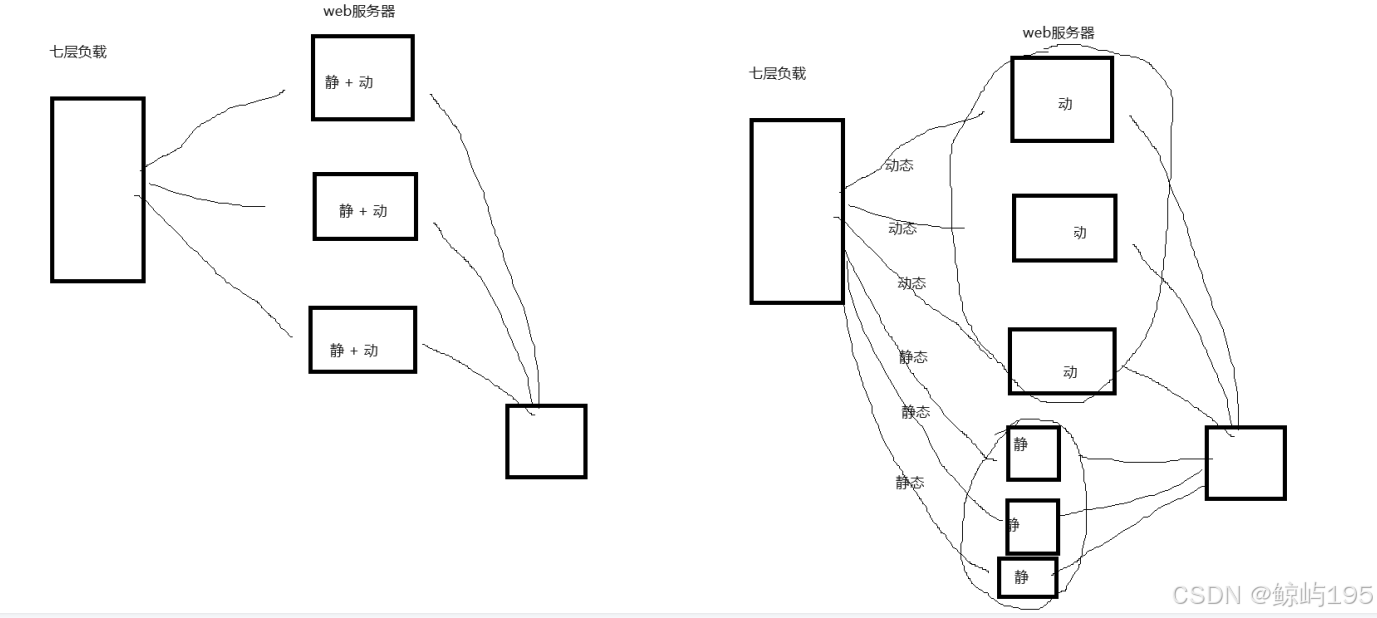
2、资源分离(****)
if判断:实现满足条件,发往特定的集群
负载均衡层
[root@lb01 ~]# vim /etc/nginx/conf.d/linux.sj.com.conf
upstream android {
server 10.0.0.7;
}
upstream iphone {
server 10.0.0.8;
}
upstream pc {
server 10.0.0.9;
}
server {
listen 80;
server_name linux.sj.com;
location / {
if ($http_user_agent ~* "Android") { #判断如果是安卓端
proxy_pass http://android; #代理到android虚拟主机池
}
if ($http_user_agent ~* "iPhone") { #判断如果是苹果端
proxy_pass http://iphone; #代理到iphone虚拟主机池
}
if ($http_user_agent ~* "WOW64") { #判断如果是IE浏览器
return 403; #直接返回403
}
proxy_pass http://pc; #如果没有匹配到以上内容,默认都代理到pc虚拟主机池
include proxy_params;
}
}
十五、重写rewrite(****)
定义
什么是重写:
rewrite是ngx_http_rewrite_module模块提供的一个功能
可以把请求url地址中的uri路径部分进行改写
http://egonlin.com/a/b/c?page=13 重写 https://egonlin.com/a/b/c/page/13
为何要用重写
1、伪静态,方便浏览器收录(最常用的场景)
2、协议或端口的更换
http协议来请求,重写为https
端口重写
3、网站换新域名后,让旧的域名的访问跳转到信息的域名上
如何用重写
强调重点:
1、重写指令是以配置的形式写入配置文件中的,它是配置而不是代码
2、代码是在nginx的进程内的,进程内有很多功能模块,负责重写功能的是重写模块
总结:
重写模块的代码会去配置文件中只读取与重写有关的规则配置来执行
其他功能的配置不归重写功能管理
配置文件不是代码,配置的文件没有执行顺序,配置的顺序无法完全代表代码的执行顺序
配置文件是代码运行的原材料
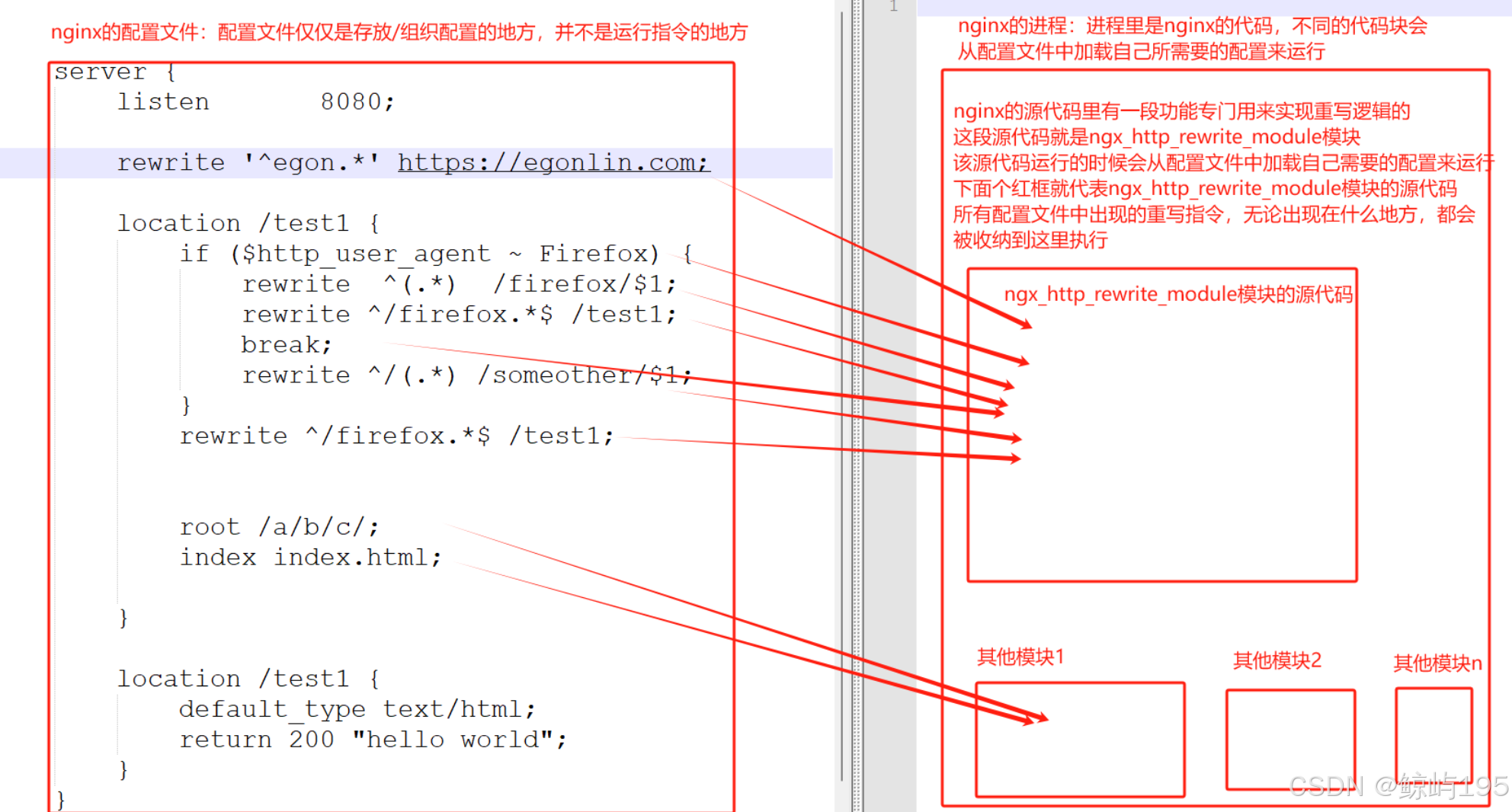
3、与重写有关的规则可以放在配置的哪些地方呢?
server块
location块
if块 if( ) { }
ngx_http_rewrite_module模块提供4种配置指令
break:终止重写逻辑的循环,所有与重写有关的指令都不会运行了,不影响其余模块运行
last(等同于continue):终止本次循环,直接进入下一次
if
return:整体结束
rewrite:把url路径重写为一个新路径(但凡重新成功,一定会触发新一轮的location匹配)
补充说明:
rewrite 正则 /test1 # 触发新一轮的location匹配
rewrite 正则 http://egonlin.com # 直接跳转到新网址
模块运行逻辑(伪代码)
ngx_http_rewrite_module(代码)模块的运行逻辑:
两大步骤:
1、从配置文件的三个地方server块、location块、if块读取重写规则到内存中
2、执行重写规则
(1)先执行server块中的重写规则 ,如果重写为一个完整的url地址带着域名,那会直接跳转
如果重写失败、或者重写为一个新路径,那进入下一个阶段
(2) 进入一个loop循环-----伪代码 (break停止的是整个循环)
### 综上,配置文件中无论何处出现的重写指令,最终都会被nginx收纳到ngx_http_rewrite_module这个模块的运行逻辑中去,这个模块内部的运行逻辑包含了一个大循环(最多循环十次)
先执行server块内的重写指令集
while True: # 再进入一个loop内
#第一个location
判断请求的uri路径 == location指定的:
if (条件) {
重写指令1
重写指令2
重写指令3
}
重写指令4
重写指令5
重写指令n
当前location内的所有重写指令执行完毕后会自动continue进入下一次loop
#第2个location
判断请求的uri路径 == location指定的:
if (条件) {
重写指令1
重写指令2
重写指令3
}
重写指令4
重写指令5
重写指令n
当前location内的所有重写指令执行完毕后会自动continue进入下一次loop
#第3个location
判断请求的uri路径 == location指定的:
if (条件) {
重写指令1
重写指令2
重写指令3
}
重写指令4
重写指令5
重写指令n
当前location内的所有重写指令执行完毕后会自动continue进入下一次loop
指令
break
break指令指的是跳出整个重写模块代码的循环loop,即会终止所有后续的ngx_http_rewrite_module模块相关的所有重写相关指令的执行,
注意是所有的,意味着任何块里任何位置的rewrite相关的指令都不会再执行,但是非重写相关指令不受影响
if
if (conditon) {
# 代表条件为真时的nginx操作,可以是反向代理,也可以是URL重写
}
可以在server、location内使用
# 如果要禁止掉一些访问,进行条件匹配后直接返回403状态码即可
return(详解见return指令)
可以在server、location、if内使用
rewrite
rewrite_log 仅在测试的时候开启,会增加日志的io量导致性能降低
通常在http、server、location中设置
server {
listen 80;
server_name domain.com;
rewrite_log on;
# Rest of the configuration
}
[root@web01 ~]# vim /etc/nginx/nginx.conf
... ...
error_log /var/log/nginx/error.log notice; # notice必须设置(日志等级)
... ...
http {
... ...
rewrite_log on;
... ...
}
语法
rewrite regex replacement [flag];
regex #用于匹配uri路径的正则表达式
replacement #替换的新路径
[flag]; #标记位,后面有详解案例
###
1、rewrite只能放在server{}, location{}, if{}中
2、regex正则部分只匹配uri路径部分
例如 http://seanlook.com/a/we/index.php?id=1&u=str 只对/a/we/index.php重写。
3、replacement可以是一个不带域名的uri路径(默认当前域名),也可以是一个带着新域名的完整url地址
# regex正则表达式的运用需要pcre库的支持----默认会安装(rpm -qa | grep pcre)
# flag标记
1、last: 相当于continue指令,会结束当前location内的重写指令,然后进入下一次loop
拿着改写后的新uri,从头开始匹配location,从第一次之后,即从第二次算起,最多不能超过10次loop
即不在rewrite指令所在的当前级别查找新的uri路径,而是从头开始在server块中查找location
2、break: break掉重写模块的loop,所有重写模块相关的指令整体结束掉无论你在何处,但肯定不会
影响其他模块,所以结论就是会在本location内继续执行其他非重写模块相关指令
3、redirect: 返回302临时重定向,浏览器地址会显示跳转后的URL地址.
4、permanent: 返回301永久重定向,浏览器地址会显示跳转后URL地址.
rewrite regex replacement [flag];
rewrite regex replacement break;
rewrite regex replacement last;
rewrite regex replacement redirect; # 302
rewrite regex replacement permanent; # 301
set
定义变量-----内层定义的覆盖外层定义的
server {
listen 8080;
set $my_name "linhaifeng"; # server块内定义
location / {
set $my_key "p"; # locatin块内定义
if ($http_user_agent ~* (MSIE|Opera|Google|Bing|Yahoo|Firefox)) {
set $my_page "7278389.html"; # if块内定义
rewrite .* https://www.cnblogs.com/$my_name/$my_key/$my_page;
}
}
}
案例
http------》https
#Nginx跳转配置
server {
listen 80;
server_name linux.rewrite.com; # 可用$server_name获取该域名
rewrite ^(.*) https://$server_name$1 redirect;
#return 302 https://$server_name$request_uri;
}
伪静态
------指将动态网页(一般为带有查询字符串的 URL)转化为看起来像静态网页的 URL 的技术
例如,将/product.php?id=123改写成/product-123.html。
为了对网站进行seo优化,提升站点在搜索引擎中的排名(搜索引擎更倾向于将统一且结构简单的静态 HTML 页面排在更高的位置),对前端代码进行修改动态地址伪装成静态地址,但是后端读不懂伪装的地址所以需要重写成以前后端能读懂的代码此外;
伪静态 URL 也更加具有可阅读性,让用户能够更好地理解页面的内容。
/product-123.html-----(重写)---->/product.php?id=123
server {
listen 80;
server_name www.example.com;
location / {
rewrite ^/product-([0-9]+)\.html$ /product.php?id=$1 last;
}
}
前端请求用的是静态地址/product-123.html,这个地址本质上是不可用的,是一个假的
伪装的地址,所以到后台后需要location匹配并用rewrite将其重写为真正的可以执行的
动态请求
十六、其他模块(***)
使用模块时先用 nginx -V 看是否有这个模块
目录索引
### 点击链接直接就能进行下载
ngx_http_autoindex_module
语法
Syntax: autoindex on | off;
Default: autoindex off;
Context: http, server, location
配置
[root@web01 ~]# cat /etc/nginx/conf.d/www.autoindex.com.conf
server {
listen 80;
server_name www.autoindex.com;
charset utf8;
location / {
root /code/autoindex;
index index.html;
}
location /download {
root /code/autoindex;
autoindex on;
autoindex_exact_size off;
#显示文件字节大小,默认是显示字节大小,配置为off之后,显示具体大小 M/G/K
autoindex_localtime on;
#显示文件的修改的具体时间,默认显示的时间与真实时间相差8小时,所以配置 on
}
}
实例
[root@web01 ~]# vim /etc/nginx/conf.d/www.autoindex.com.conf
server {
listen 80;
server_name www.autoindex.com;
charset utf8;
location / {
root /code/autoindex;
index index.html;
}
location /download {
root /code/autoindex;
autoindex on;
}
}
#创建站点目录
[root@web01 ~]# mkdir /code/autoindex/download -p #将数据放入此文件中提供下载
[root@web01 ~]# echo "测试autoindex模块" > /code/autoindex/index.html
#访问
http://www.autoindex.com/ 为主站
http://www.autoindex.com/download/ 为下载文件的目录
访问控制
# ngx_http_access_module
语法
#允许访问的语法
Syntax: allow address | all;
Default: —
Context: http, server, location, limit_except
#拒绝访问的语法
Syntax: deny address | all;
Default: —
Context: http, server, location, limit_except
#如果配置允许,则也要配置拒绝;配置拒绝可以单独配置
实例(继续上个模板的实例)
# 拒绝指定IP
location /download {
root /code/autoindex;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
deny 10.0.0.1;
allow all;
#只允许指定IP访问
location /download {
root /code/autoindex;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
allow 10.0.0.1;
#如果使用all,一定放在最后面
deny all;
#只允许指定IP访问拒绝该网段其他IP
allow 10.0.0.1;
#如果使用all,一定放在最后面
deny 10.0.0.0/24;
访问认证
#访问网页时要先输入账号密码才能进行访问
# ngx_http_auth_basic_module
实例
#创建密码文件需要用到 htpasswd
[root@web01 ~]# htpasswd -c /etc/nginx/auth_basic lhd # -c创建
New password:
Re-type new password:
Adding password for user lhd
#添加一个登录用户(追加)
[root@web01 ~]# htpasswd /etc/nginx/auth_basic egon # 不加-c即添加
New password:
Re-type new password:
Adding password for user egon
#密码文件内容
[root@web01 ~]# cat /etc/nginx/auth_basic
lhd:$apr1$A7d4BWYe$HzlIA7pjdMHBDJPuLBkvd/
egon:$apr1$psp0M3A5$601t7Am1BG3uINvuBVbFV0
#开启配置
location /download {
root /code/autoindex;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
auth_basic "egon say hello!"; # 用谷歌浏览器验证,不要用火狐抓不到401的包
auth_basic_user_file /etc/nginx/auth_basic; #拿到信息后会在文件中进行比对
}
}
状态监控
配置
location = /basic_status { # 直接添加
stub_status;
}
访问
#访问 http://www.autoindex.com/basic_status
#nginx七种状态
Active connections: 2
server accepts handled requests
4 4 21
Reading: 0 Writing: 1 Waiting: 1
# 累计值
Active connections #当前活跃的连接数
[root@web01 /usr/share/nginx/html]# netstat -ant |grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
tcp 0 0 192.168.71.112:80 192.168.71.7:65491 ESTABLISHED
tcp 0 0 192.168.71.112:80 192.168.71.7:65492 ESTABLISHED
accepts #nginx启动开始算,累计接收的TCP连接总数
handled #累计成功的TCP连接数
requests #累计成功的请求数
Reading #当前0个链接正在读请求
Writing #当前1个链接正在响应数据给客户端
Waiting #当前等待的请求数,即当前处于keep-alive状态的连接数
# 注意, 一次TCP的连接,可以发起多次http的请求, 如下参数可配置进行验证
keepalive_timeout 0; # 类似于关闭长连接
keepalive_timeout 65; # 65s没有活动则断开连接
连接限制
请求限制
十七、nginx的优化(******)
对于优化来说,主要是针对i/o的优化
1、整体的优化思路(******)
整套架构追求:高性能、高可用、高一致性,还有安全性
(1)先摸清楚情况
I: 了解整套架构的链路与分层---》画出架构图/链路图
II:了解整套架构承载的业务特点
电商----》峰值流量特别大
toB----->业务逻辑复杂性更高。代码bug率更高
(2)再发现瓶颈
针对慢的问题
用户请求-----》负载均衡-----》应用-----》数据库与数据库缓存层
-----》文件服务器层
排查方法:
1、有些慢可以直接计算出来
峰值qps/应用服务压测的qps = 需要几台机器
机器数不够就扩容
2、无法直接计算出来的
2.1、查看沿途的访问日志,例如mysql的慢查询日志
2.2、top命令、netstat、或或ngx_http_stub_status_module查看链接数
来确认资源使用情况,是否有超负载、内存用完、连接过多的情况
解决----更改权重,最小链接调度算法等
(3)有针对性的进行优化
2、架构维度优化方案
2.1、架构高性能优化思路
优化思路:(io优化)
(1)高频读:就少读、就近读、读缓存
(2)高频写:就少写、数据拆分、漏斗写,buffer写
优化步骤:
把问题细分---》分出单独的层---》单独处理
优化效果:例如动静分离、冷热分离,即分流了压力又做到了隔离保护,从而达到高性能的目的
架构维度,每一层该如何优化举例
1、io问题---》数据库层
数据库慢查询-----》优化sql、索引、引入数据库缓存层
2、web层:
web集群机器数不够用(峰值qps/单机极限qps=机器数)--》扩机器
查看web服务的负载、内存使用率 -----》降权重,比较闲的机器应该增加权重
3、负载均衡(内存、cpu)---》多级负载均衡,买硬件F5
4、文件服务器层
-----》分布式存储
5、网络问题
丢包、延迟-----》优化网络环境、升级网络设备
带宽不够-------》加带宽(网速)
访问距离远------》CDN、静态资源缓存在用户浏览器中
6、其他棘手的问题-----》 考虑分离出来,单独处理
动静分离
冷热分离(访问频率)
2.2、单机通用优化点
硬件
负载均衡(内存大一些,cpu核多一些)#对于lvs的情况,包的返回直接发送给客户端不经 lvs,所以对cpu的性能而言要求要更高
应用层:无特殊要求,因为有很多应用服务器,性能低可以设置的权重低一些
文件服务器:(普通文件服务器例如nfs,内存磁盘大一些)#如果是分布式存储,对cpu也 有性能要求
数据库: 内存、磁盘(可以考虑固态)
数据库缓存:内存
系统
内核优化参数:
(1)ipv4: /proc/sys/net/ipv4
(2)tcp连接池:半连接池、全连接池
软件
服务
nginx优化
应用
每个程序都有自己环境(编写语言)相关的优化参数
3、系统优化(******)
内核优化:
ulimit -u 3 #打开的最大进程数
ulimit -n 12 # 这个值默认最大可以设置为1048576,文件描述符
------临时生效
在/etc/security/limits.d/下放配置文件优先级更高,并且无需重启系统,退出当前终端重新进入即可生效
cat > /etc/security/limits.d/k8s.conf <<'EOF'
* soft nofile 65535
* hard nofile 131070
EOF
ulimit -Sn #查询文件描述符软限制数量
ulimit -Hn #硬限制
#设置
[root@egon ~]# cat >>/etc/sysctl.conf<<EOF
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1 #开启后用来防止syn洪水攻击
net.ipv4.tcp_keepalive_time = 600
net.ipv4.ip_local_port_range = 4000 65000
net.ipv4.tcp_max_syn_backlog = 16384----------半连接队列
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.core.somaxconn = 16384-----------全连接队列
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_orphans = 16384
net.ipv4.ip_forward = 1
EOF
#生效
[root@egon ~]# sysctl -p
4、nginx优化(*****)
### 系统内核优化与nginx优化配合调整
通用nginx优化
# 调大连接数-----提高并发,文件描述符也跟着调大
全局配置优化
worker_processes 4; # 通常设置为auto就行,有几个核就设置为几
worker_rlimit_nofile 65535; # 配合着要把文件描述符调大
events块
events {
use epoll; # 使用epoll网络io模型
worker_connections 1024; # 调大连接数
}
http块----详情见nginx基础配置
server块----线程池与独享全连接队列
# 全局新增
thread_pool egon_pool threads=3 max_queue=1024; # 定义线程池
http {
#aio threads;
aio threads=egon_pool; # 启用线程池
# 启用线程池与reuseport并不冲突
server {
listen 8089 reuseport backlog=10240;
nginx作为代理服务器的优化
负载均衡代理----web(长连接)
[root@lb01 ~]# vim /etc/nginx/conf.d/linux.keep.com.conf
upstream tomcat {
server 172.16.1.7:8080;
keepalive 8; #配置开启长连接
}
server {
listen 80;
server_name linux.keep.com;
location / {
proxy_pass http://tomcat;
proxy_http_version 1.1; #代理带后端的http版本
proxy_set_header Connection ""; #清除请求头字段
include proxy_params;
}
}
web代理----php(长连接)
[root@web01 ~]# vim /etc/nginx/conf.d/linux.wp.com.conf
upstream php_server {
server 127.0.0.1:9000;
}
server {
listen 80;
server_name linux.wp.com;
location / {
root /code/wordpress;
index index.php;
}
location ~* \.php$ {
fastcgi_pass php_server;
fastcgi_param SCRIPT_FILENAME /code/wordpress/$fastcgi_script_name;
fastcgi_param HTTPS on;
fastcgi_keep_conn on; # 开启长连接
include fastcgi_params;
}
}
代理优化配置
[root@lb01 ~]# cat /etc/nginx/proxy_params
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 60s;
proxy_read_timeout 60s;
proxy_send_timeout 60s;
proxy_buffering on;
proxy_buffer_size 8k;
proxy_buffers 8 8k;
proxy_next_upstream http_500 http_502 http_503 http_504;
然后在文件中引入
location / {
proxy_pass http://tomcat;
include proxy_params; # -----》引入上面的文件
}
5、静态资源
http响应头
cache_control #缓存控制
expires #资源过期时间
last-modified #标记资源最后被修改时间
etag #为资源提供的一个特定的标识符
http请求头
If-None-Match
If-Modified-Since
浏览器缓存流程(了解)
1、浏览器优先去查看响应头部的 cache-control
2、如果cache-control设置了缓存时间,并且未过期,则直接使用浏览器缓存的内容
3、如果cache-control设置为 no-cache,那么浏览器会继续去读取 expires
4.如果expires设置了,并且未达到过期时间,那么浏览器会读取缓存
5.如果 cache-control 和 expires 都没有设置
6.浏览器会去查看之前响应的 ETag值,然后放到请求头 If-None-Match中发往服务端进行验证,服务端比对之后
发现值相同,则代表资源未被修改,服务端将返回 304 Not Modified 状态码,浏览器随即从缓存中加载资源
注意:ETag 可以解决仅使用 Last-Modified 时因时间精度问题无法判断内容微小修改的问题,因此优先被检测
如果发现值不同,浏览器会读取之前响应的last-modified时间,放入请求头 If-Modified-Since 到服务端对比,如果值相同,那么走缓存
否则,需要重新到服务器上获取数据并返回
6、静态资源的访问优化
缓存到用户浏览器(本地硬盘)
expires 7d;
#配置
[root@web01 conf.d]# vim linux.cache.com.conf
server {
listen 80;
location ~* \.(png|jpg|gif)$ {
root /code/cache;
expires 7d;
}
}
配置不走缓存
1.使用无痕模式
2.开启浏览器上面的 Disable cache
3.配置nginx关闭缓存
[root@web01 conf.d]# vim linux.cache.com.conf
server {
listen 80;
location ~* \.(png|jpg|gif)$ {
root /code/cache;
etag off;
add_header Cache-Control no-cache;
if_modified_since off;
}
}
静态资源压缩
gzip on;
补充:压缩数据会提供io效率,但是压缩算法会消耗cpu
#压缩配置
[root@web01 cache]# vim /etc/nginx/conf.d/linux.gzip.com.conf
server {
listen 80;
server_name linux.gzip.com;
location ~* \.(png|jpg|gif)$ {
root /code/cache;
gzip on;
gzip_types image/jpeg image/gif image/png;
gzip_comp_level 9;
}
location ~* \.txt$ {
root /code/cache;
gzip on;
gzip_types text/plain;
gzip_comp_level 5;
}
}
十八、防盗链(功能)
"Referer"是HTTP请求头的一个字段,当你点击一个链接或者提交一个表单跳转到另一个页面时,
浏览器会自动添加这个Referer字段,用来告诉服务器你是从哪个页面跳转过来的。
valid_referers是Nginx中用于检查HTTP Referer请求头部字段的指令,主要用于防止资源被其他站点盗用(用于server,location)
配置防盗链
[root@web01 conf.d]# vim linux.beidaolian.com.conf
server {
listen 8080;
server_name linux.beidaolian.com 192.168.71.15;
location ~* \.(png|jpg|gif)$ {
root /usr/share/nginx/html/;
valid_referers none blocked server_names; # server_names默认只包含我们自己的域名
if ($invalid_referer) {
return 500;
}
}
}
补充: valid_referers none blocked server_names *.baidu.com; # 多加个*.baidu.com允许某些域名盗链
十九、cpu亲和(*****)----》面试
# 绑定每一个worker进程到一个具体的cpu核心
好处:
对于i/o密集型任务(对于cpu的消耗不高)
减少进程的切换开销
一个worker始终使用一个cpu,意味着可以有效率地利用cpu的缓存,减少内存的访问延迟
---》提升整体性能
坏处:
服务器运行着计算密集型的任务,会对某个cpu造成非常大的消耗与占用
此时因为绑定,会到某个worker进程长期得不到cpu,效率反而 会低
配置
[root@lb ~]# vi /etc/nginx/nginx.conf
worker_processes auto;
worker_cpu_affinity auto;
[root@lb ~]# systemctl restart nginx
查看
cat /etc/nginx/nginx.conf |grep -i work
ps -eo pid,args,psr | grep [n]ginx
补充说明:命令ps -eo pid,args,psr 是用来显示进程ID(pid)、命令行参数(args)以及进程运行的处理器ID(psr)
------------------------------------------------------------------》后续见nginx详解


















 9183
9183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









