







一、Apache Spark概述
(1)Spark定义
Apache Spark 是用于大规模数据(large-Scala data)处理的统一(unified)分析引擎。其特点是对任意类型的数据进行自定义计算,Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用python、Java、Scala、R以及SQL语言取开发程序计算数据。
(2)Hadoop与Spark的区别和优缺点
| Hadoop | Spark | |
| 类型 | 基础平台,包含计算、存储、调度 | 纯计算工具(分布式) |
| 场景 | 海量数据批处理(磁盘迭代计算) | 海量数据的批处理(内存迭代计算、交互式计算)、海量数据流计算 |
| 价格 | 对机器要求低 | 对内存有要求、相对较贵 |
| 编程范式 | Map+Redeuce,API较为底层,算法适应性差 | RDD组成DAG有向无环图,API较为顶层,方便使用 |
| 数据存储结构 | MapReduce中间计算结果在HDFS磁盘上,延迟大 | RDD中间运算结果在内存中,延迟小 |
| 运行方式 | Task以进程方式维护,任务启动慢 | Task以线程方式维护,任务启动快,可批量创建提高并行能力 |
Hadoop的基于进程的计算和Spark基于线程方式优缺点
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
(3)Spark的四大特点
①速度快:Spark处理数据时,可以将中间处理结果数据存储到内存中;Spark 提供了非常丰富的算子(API), 可以做到复杂任务在一个Spark 程序中完成。
②易于使用:支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。
③通用性强:在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。
④多运行方式:Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark2.3开始支持)上。
(4)Spark框架模块
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib。
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
(5)spark的运行模式
local模式:local模式就是以一个独立进程配合其内部线程来提供完成spark运行时环境,local模式可以提供spark-shell/pyspark/spark-submit等来启动。
Standalone模式:Standalone模式是spark自带的一种集群模式,不同于local模式启动多进程来模拟集群的环境,Standalone模式是真实的在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
spark on Yarn模式:这是一种很有前景的部署模式。但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。这是由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化,不过这个已经在YARN计划中了。 spark on yarn 的支持两种模式:
(1) yarn-cluster:适用于生产环境。
(2) yarn-client:适用于交互、调试,希望立即看到app的输出。
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
spark on mesos模式:这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考Andrew Xia的“Mesos Scheduling Mode on Spark”):
-
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
-
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
二、Saprk安装配置(local模式)
链接:https://pan.baidu.com/s/14NH-Zlo-b70C6Q8yalUBDw
提取码:1111
1.安装anaconda
(1)将anaconda文件上传,然后执行文件
命令:sh anaconda上传路径

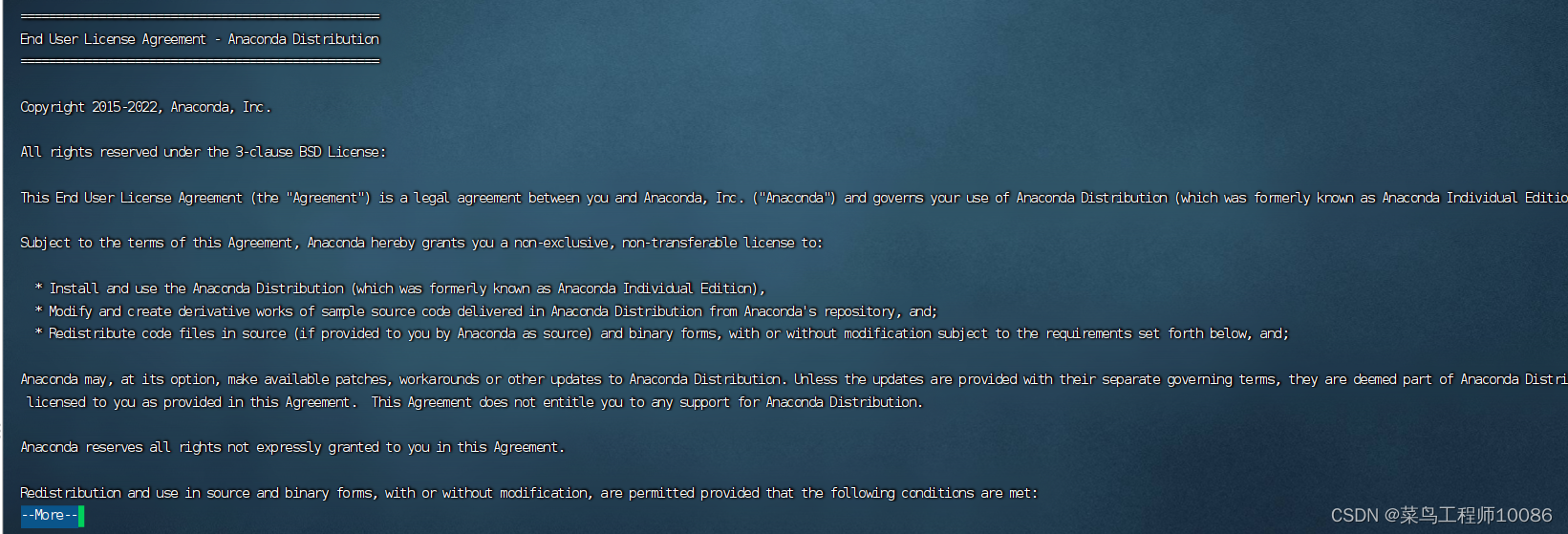
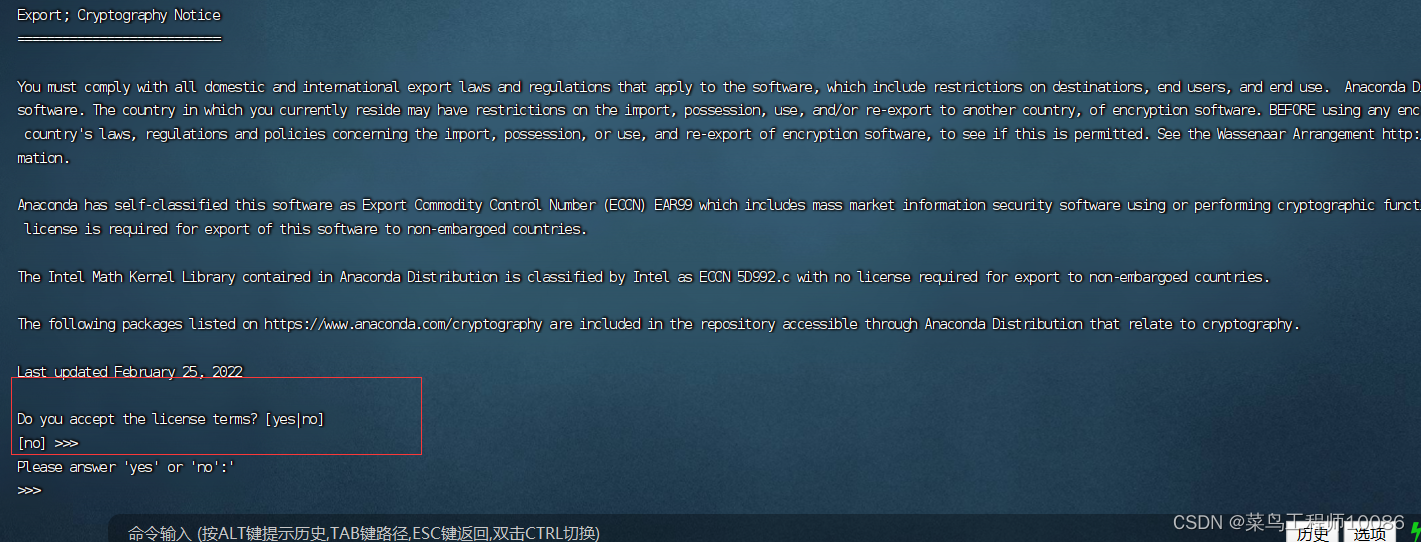
(2)一直点击回车,直到出现yes/no选项,然后输入yes
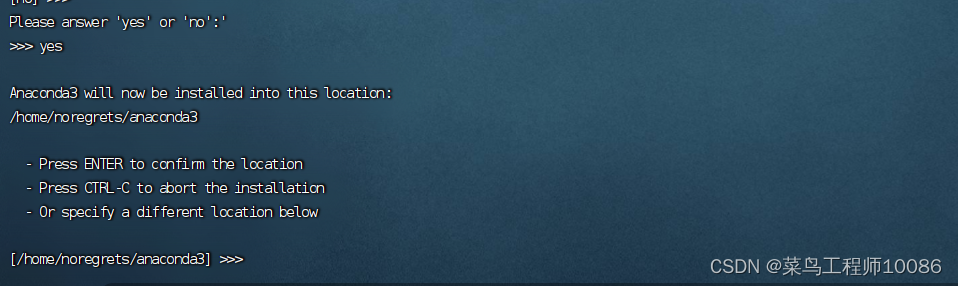
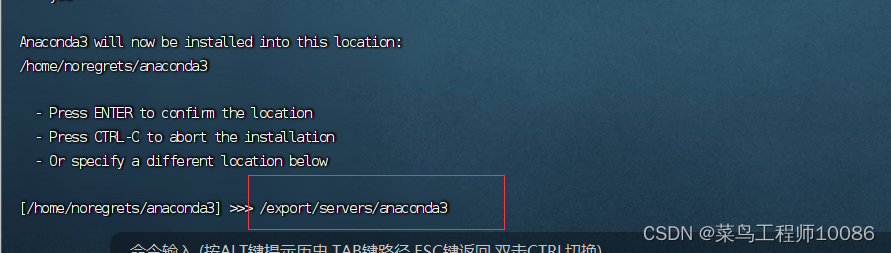
(3)确定安装路径,在此输入想要安装的路径,然后回车等待安装完成。
(4)初始化anaconda,在弹出选项输入yes

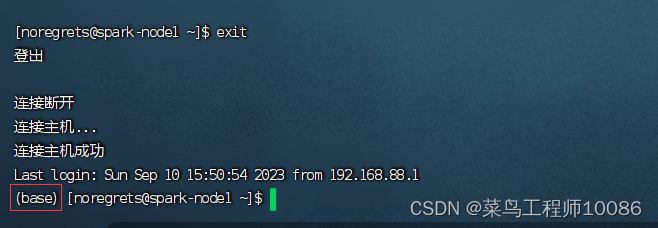
(5)初始化结束就安装完成了,退出终端连接,重新连接后出现base表示安装成功

(6)将anaconda下载源改为国内源
![]()
在新文件中添加
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud

(7)验证python能否使用
输入python
2.创建pyspark虚拟环境
(1)创建环境,将python版本设置为3.9
命令:conda create -n pyspark python=3.9

(2)切换到pyspark虚拟环境
conda activate pyspark

3.spark(local)环境部署
(1)上传安装包并解压
(2)构建软连接
命令:ln -s /export/servers/spark-3.2.0-bin-hadoop3.2/ /export/servers/spark

(3)配置spark文件
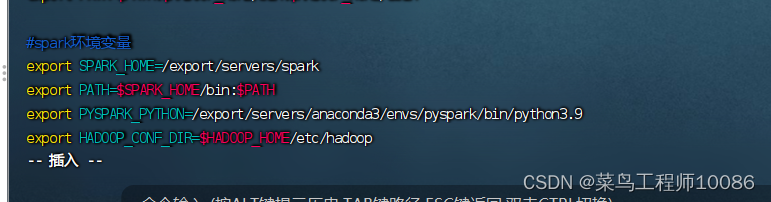
1.配置环境变量
#spark环境变量
export SPARK_HOME=/export/servers/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_PYTHON=/export/servers/anaconda3/envs/pyspark/bin/python3.9
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
2.配置.bashrc文件


3.测试pyspark
进入spark的bin目录,执行命令 ./pyspark
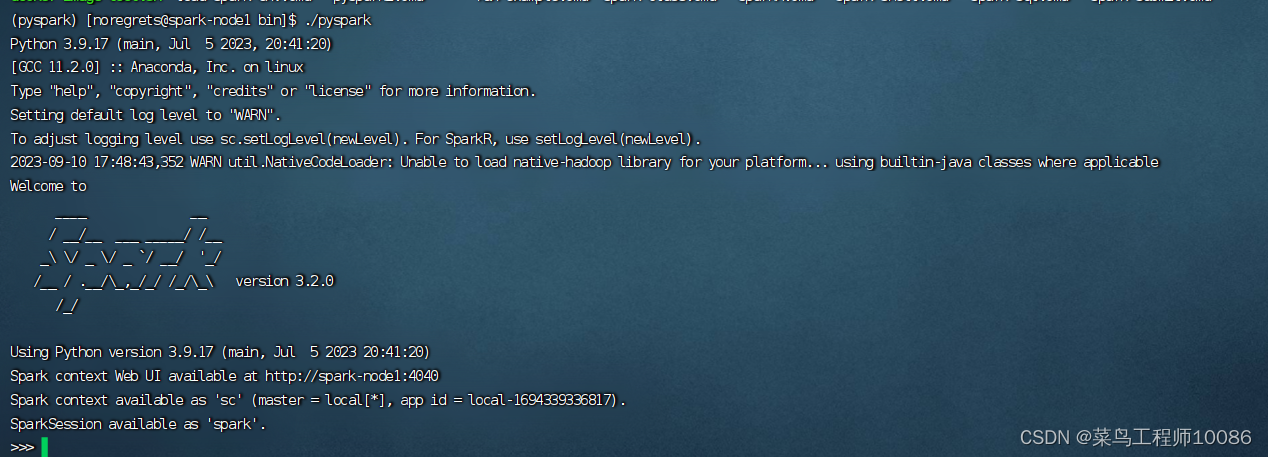
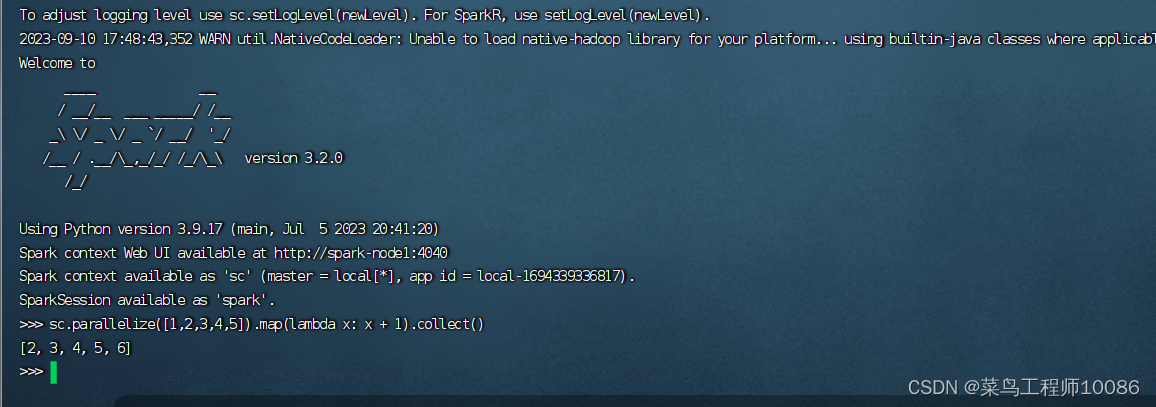
执行代码:sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
三、Spark安装配置(Stand alone模式)
1.安装anaconda并创建虚拟环境(所有机器)
(1)将anaconda文件上传,然后执行文件
命令:sh anaconda上传路径
(2)一直点击回车,直到出现yes/no选项,然后输入yes
(3)确定安装路径,在此输入想要安装的路径,然后回车等待安装完成。
(4)初始化anaconda,在弹出选项输入yes
(5)初始化结束就安装完成了,退出终端连接,重新连接后出现base表示安装成功
(6)将anaconda下载源改为国内源
![]()
在新文件中添加
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
(7)验证python能否使用
输入python
(8)创建pyspark虚拟环境
创建环境,将python版本设置为3.9
命令:conda create -n pyspark python=3.9
切换到pyspark虚拟环境
conda activate pyspark
2.配置环境变量(所有机器)
1.配置环境变量
#spark环境变量
export SPARK_HOME=/export/servers/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_PYTHON=/export/servers/anaconda3/envs/pyspark/bin/python3.9
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
2.配置.bashrc文件
3.配置文件(主节点)
配置文件路径:spark/conf
(1)配置workers.template文件
添加主机名称

(2)配置spark-env.sh.template文件
## 设置JAVA安装目录
JAVA_HOME=/export/servers/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
YARN_CONF_DIR=/export/servers/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=spark-node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark-node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"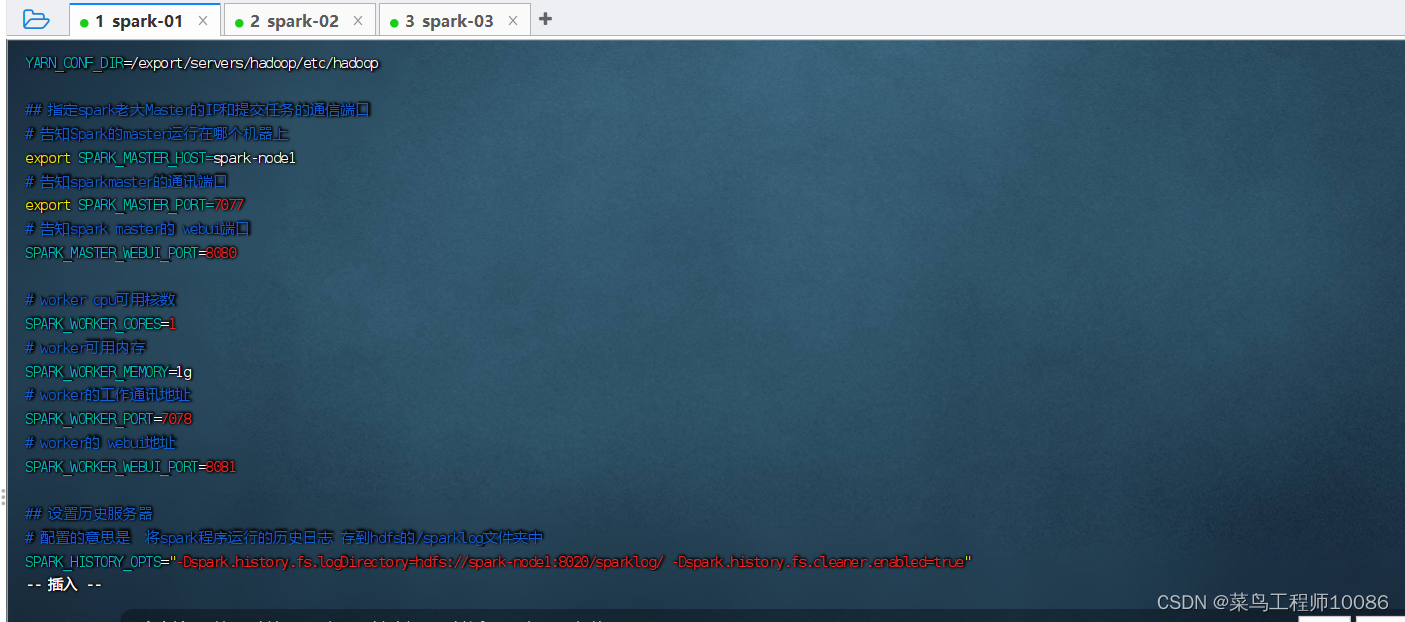
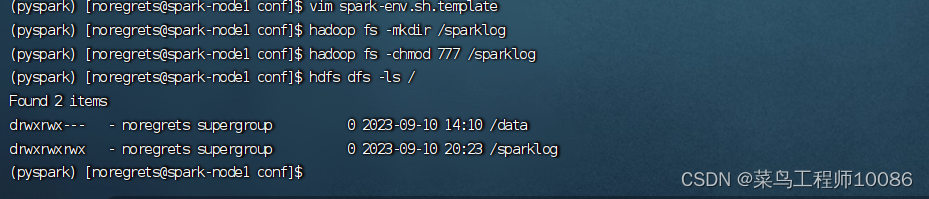
(3)在HDFS创建存放Spark日志文件夹
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
(4)配置 spark-defaults.conf.template文件
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true

(5)配置log4j.properties.template文件
(6)分发文件并构建软链接
scp -r /export/servers/spark-3.2.0-bin-hadoop3.2 spark-node2:/export/servers/
scp -r /export/servers/spark-3.2.0-bin-hadoop3.2 spark-node3:/export/servers/
ln -s spark-3.2.0-bin-hadoop3.2/ spark

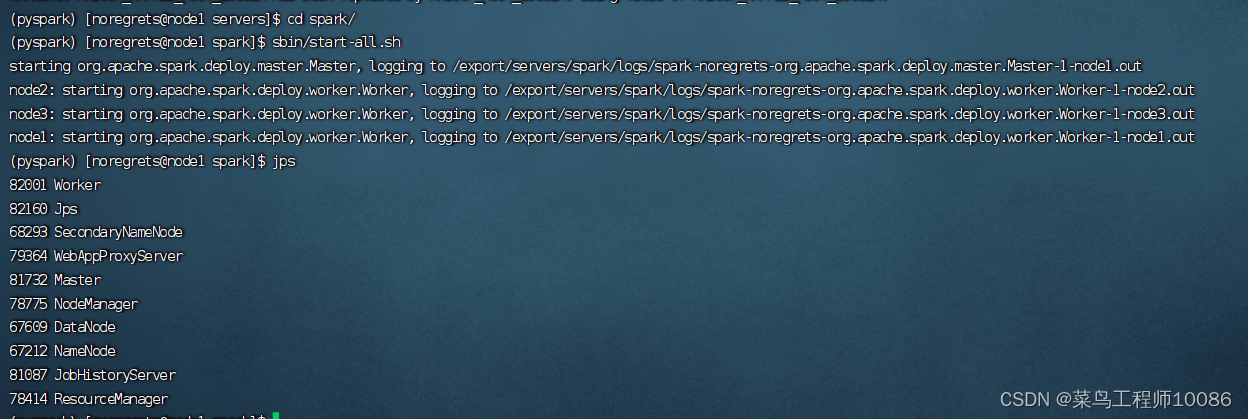
4.启动spark服务(在spark目录执行)
(1)启动历史服务器
sbin/start-history-server.sh

(2)启动spark集群
sbin/start-all.sh
















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











