






目录
(2).然后我们再用pd.isna()判断a的每个元素是否为缺失值:
(3).然后再用sum()方法对每列求和,计算出每列缺失值的数量:
前言
如果将文本数据与图表数据相比较,人类的思维模式更适合于理解后者,原因在于图表数据更加直观且形象化,它对于人类视觉的冲击更强,这种使用图表来表示数据的方法被叫做数据可视化。
一、什么是数据探索?
在前面我们说到,所谓机器学习,就是用已知的数据通过算法去预测未来未知的数据。但是这个过程进行的前提就是要保证已知数据的完成性。所以数据探索,就是检查数据是否完整,是否有缺失值。
二、什么是可视化?
可视化就是将数据以图像的形式呈现出来,例如散点图、直方图、正态图等等,这些都是将单纯的数据以图像的形式呈现,从而可以起到更清晰有效地传达、沟通并辅助数据分析的作用。
1、缺失值处理:
数据缺失:指在数据采集、传输和处理等过程中,由于某些原因导致数据不完整的情况。
下面学习一下缺失值的处理方法
2、简单的缺失值处理方法:
在处理缺失值之前,我们肯定要有缺失值才能处理,所以我们第一步是去检查数据中有没有缺失值。
发现数据中的缺失值:在这里我们要用到一个数据集,通过这个数据集来介绍发现缺失值的方法。
(1).首先我们读取并查看这个数据集:


(2).然后我们再用pd.isna()判断a的每个元素是否为缺失值:


(3).然后再用sum()方法对每列求和,计算出每列缺失值的数量:

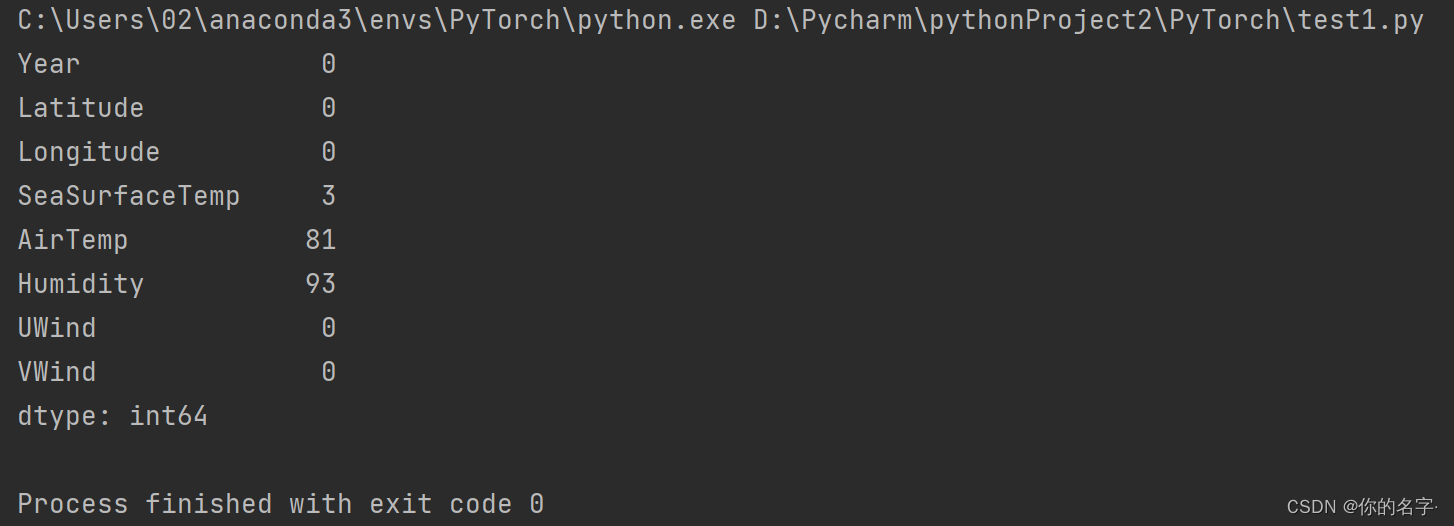
从结果中我们可以看到,SeaSurFaceTemp有3个缺失值,AirTemp有81个缺失值,Humidity有93个缺失值。
虽然我们已经知道了数据集中每列缺失值的数量,但是我们还不知道它们具体的分布情况(缺失值在哪一行)。
于是,我们可以使用mano.matrix()可视化出缺失值在数据中的分布情况。

3、 对缺失值进行插补:
首先我们要使用散点图可视化出剔除带有缺失值行后,AirTemp和Humidity变量的数据分布。

这里直接对原始数据可视化也可以,这是因为plt.scatter()函数会自动地不显示带有缺失值的点。

对缺失值填充,pandas库提供了数据表的fillna()方法,该方法可通过参数method设置缺失值的填充方式。method=“ffill”,使用缺失值前面的值进行填充;method=“bfill”,使用缺失值后面的值进行填充
(1)使用缺失值前面的值进行填充:

关于~index,我们知道index是缺失值所在的位置,那么~index就是非缺失值所在的位置。

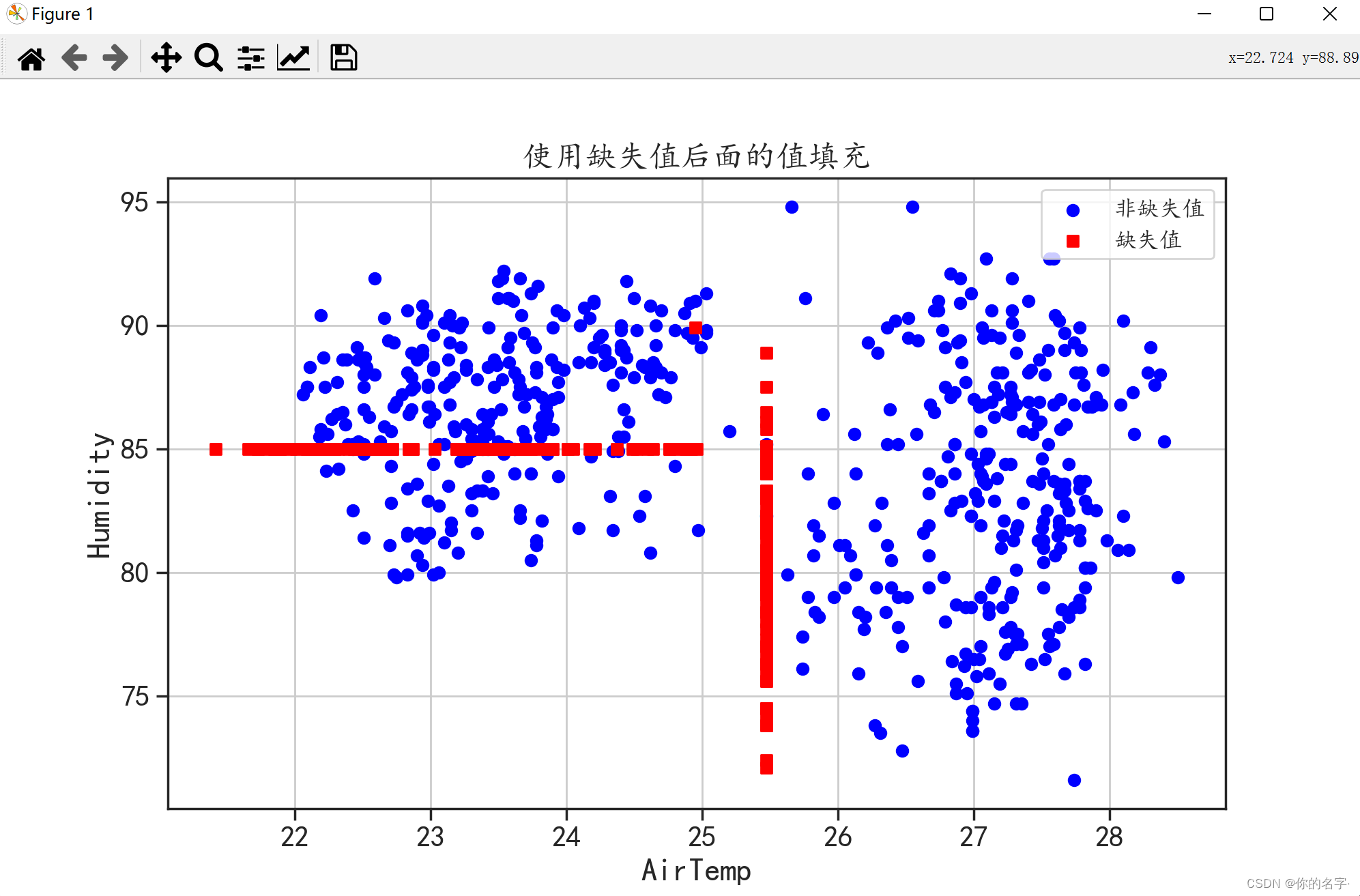
(2)使用缺失值后面的值进行填充:
我们只需将上面代码中参数“method”的值改成bfill就行了
(3)使用均值进行填充:
跟上面的代码也差不多,再对这两列求个均值就行了.

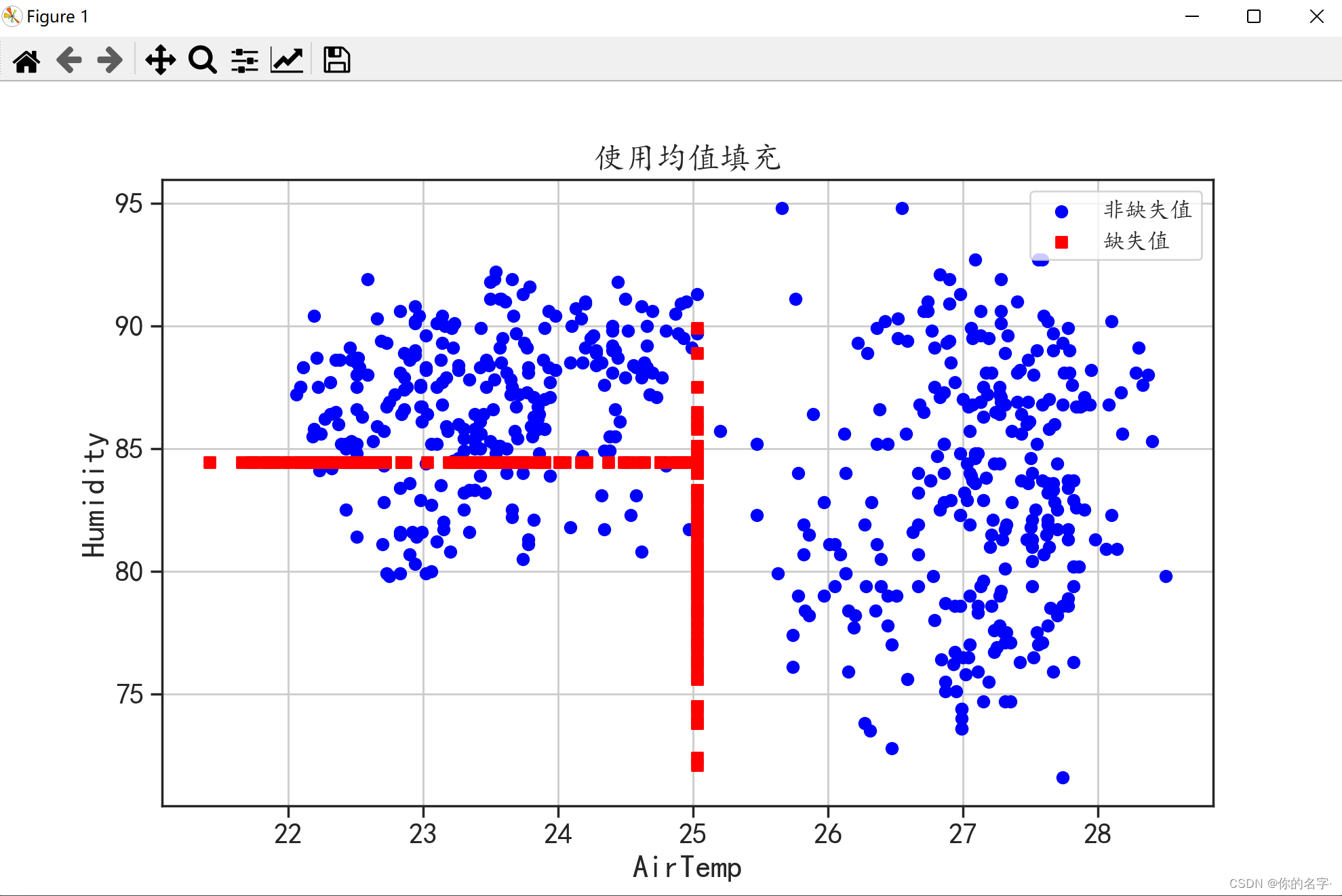
从上面三种简单的填充方式的结果图可以看出,红色并没有起到填充的作用(红色分布太规律了,并且很“单独”),这是因为这三种方法只是简单地分析一个变量,没有从整体出发。下面,我们来学习一下比较复杂的填充方法,它们都能考虑到数据的整体情况。
本篇文章链接:数据探索与可视化-CSDN博客















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











