






一.chromedriver最新版链接下载:https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.105/win64/chromedriver-win64.zip
二.将解压后的文件粘贴到anaconda3的Scripts中(找到自己的anacondas3的文件路径)
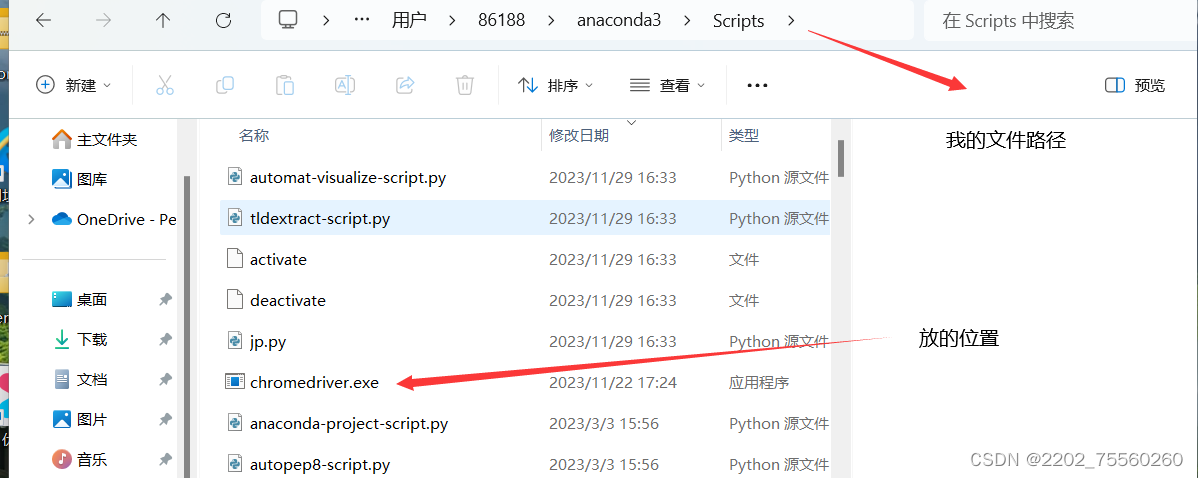
三.利用清华镜像安装selenium
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium如果安装不成功可能需要更新
pip install --upgrade pip更新后重新启动jupyter再次利用清华镜像安装selenium
之后就可以在jupyter中打代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element(By.ID,'kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from urllib.parse import quote
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 100)
KEYWORD = 'iphone'
def index_page(page):
print('正在爬取第',page, '页')
try:
url='https://search.jd.com/Search?keyword=' + quote(KEYWORD)
browser.get(url)
if page > 1:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > input')))
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > a')))
input.clear()
input.send_keys(page)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.curr').str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_goodsList > ur')))
get_products()
except TimeoutException:
index_page(page)
from pyquery import PyQuery as pq
def get_products():
html = browser.page_source
doc = pq(html)
items =doc( '#J_goodsList > ur > li').items()
for item in items:
product = {
'image': item.find('.p-img img').attr('src'),
'price':item.find('.p-price strong').text(),
'deal':item.find('.p-commit strong').text(),
'title':item.find('.p-name em').text(),
'shop':item.find('.J_im_icon a').text()
}
print(product)
MAX_PAGE = 30
if __name__ == '__main__':
for i in range(1,MAX_PAGE + 1):
index_page(i)














 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









