






摘要:作为人工智能领域的核心突破,AI 大模型正以惊人的速度重塑技术生态与产业格局。本文深度剖析大模型核心技术体系,涵盖 Transformer 架构演进、预训练范式创新、高效微调技术等关键模块,结合 Hugging Face/LLM.intuition 等主流框架提供工程化实践指南,并全景展示代码智能、企业服务、科研创新等八大应用场景,最后展望行业挑战与未来趋势,为技术从业者提供完整的大模型开发与应用路线图。
一、AI 大模型的演进之路:从单模态到全栈智能
(一)技术突破里程碑
- 架构奠基期(2017-2019)
- 2017 年 Google 提出 Transformer 架构,通过自注意力机制解决长序列依赖问题,论文《Attention Is All You Need》引用量突破 8 万次
- 2018 年 BERT 开创双向预训练先河,在 11 个 NLP 任务上刷新 SOTA,带动 NLP 进入 "预训练 + 微调" 时代
- 2019 年 XLNet 提出排列语言模型,解决 BERT 掩码机制的预训练 - 微调偏差问题
- 规模化爆发期(2020-2022)
- 2020 年 GPT-3 首次实现 Few-Shot 学习,175B 参数模型展现惊人的语言生成能力
- 2021 年 Switch Transformer 引入 MoE 架构,通过稀疏激活将参数量提升至 1.6T,开启高效扩展新路径
- 2022 年 Stable Diffusion 开源引爆 AIGC 浪潮,证明生成式模型的商业化可行性
- 多模态融合期(2023 - 至今)
- GPT-4 支持图文混合输入,在 MMLU 基准测试中超越人类平均水平
- Gemini 实现跨模态统一建模,视频理解能力达到专业级视频分析师水平
- Sora 突破视频生成技术瓶颈,实现复杂场景的高保真视频合成
(二)核心性能指标演进
| 技术代际 | 代表模型 | 参数量级 | 训练数据 | 核心能力 | 训练成本 |
| 1.0 时代 | BERT | 100M 级 | 百 GB 级 | 文本理解 | $10 万级 |
| 2.0 时代 | GPT-3 | 100B 级 | 十 TB 级 | 少样本学习 | $100 万级 |
| 3.0 时代 | Gemini | 1000B 级 + | 千 TB 级 + | 多模态推理 | $1000 万级 + |
二、核心技术体系深度解析:从架构到训练范式
(一)Transformer 架构的工程化演进
# 支持动态稀疏注意力的改进版实现
class SparseAttention(nn.Module):
def __init__(self, d_model, n_heads, sparsity=0.2):
super().__init__()
self.WQ = nn.Linear(d_model, d_model)
self.WK = nn.Linear(d_model, d_model)
self.WV = nn.Linear(d_model, d_model)
self.sparsity = sparsity
def forward(self, Q, K, V):
scores = torch.matmul(Q, K.transpose(-2, -1))
topk_scores, topk_indices = torch.topk(scores,
int(scores.size(-1)*self.sparsity), dim=-1)
masked_scores = scores.masked_fill(~topk_indices, -inf)
attention = torch.softmax(masked_scores, dim=-1)
return torch.matmul(attention, V)架构变种对比:
| 架构类型 | 代表模型 | 优势场景 | 并行效率 | 长文本处理 |
| Encoder-only | BERT | 文本理解 | 高 | 512 tokens |
| Decoder-only | GPT | 文本生成 | 中 | 32K tokens |
| Encoder-Decoder | T5 | 文本翻译 | 低 | 16K tokens |
| MoE 混合专家 | Switch Transformer | 多任务处理 | 极高 | 1M tokens+ |
(二)预训练范式创新与效率优化
- 训练数据处理技术
- 数据清洗:采用 CCNet/WebText2 等高质量数据集,结合对比学习过滤噪声数据
- 数据增强:NLP 领域的 EDA / 回译技术,CV 领域的 MixUp/CutOut 数据增广方法
- 多模态对齐:CLIP 模型通过图文对比学习实现跨模态语义对齐
- 训练效率提升方案
- 混合精度训练:FP16/FP8 混合计算,降低显存占用 30%-50%
- 分布式训练:Megatron-LM 实现张量 / 流水线并行,支持万亿参数模型训练
- 动态批处理:根据输入序列长度动态调整 batch size,提升 GPU 利用率 40%
(三)高效微调技术矩阵
轻量化微调技术对比表:
| 技术方案 | 核心思想 | 参数量增加 | 显存需求 | 典型场景 |
| Full Fine-tuning | 全参数更新 | 100% | 极高 | 学术研究 |
| LoRA | 低秩矩阵分解 | 0.1%-1% | 低 | 企业级应用 |
| P-tuning v2 | 连续提示优化 | 3%-5% | 中 | 垂直领域适配 |
| QLoRA | 4-bit 量化 + LoRA | 0.5% | 极低 | 边缘设备部署 |
# LoRA微调核心代码实现(基于PEFT库)
from peft import LoraConfig, get_peft_model
model = AutoModelForCausalLM.from_pretrained("llama-2-7b")
peft_config = LoraConfig(
r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"],
lora_dropout=0.1, bias="none", task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 仅显示0.3%可训练参数三、工程化实践指南:从模型部署到生态整合
(一)Hugging Face 生态最佳实践
1. 多模态模型快速调用
# 图文理解任务流水线
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
image = Image.open("input_image.jpg").convert("RGB")
inputs = processor(image, "A photo of", return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(processor.decode(outputs[0], skip_special_tokens=True))2. 模型量化部署方案
# 8-bit量化部署命令(使用bitsandbytes库)
python -m transformers.models.llama.modeling_llama \
--model_name_or_path llama-2-7b \
--quantization_bit 8 \
--output_dir quantized_llama_8bit \
--load_in_8bit(二)企业级 RAG 系统构建
技术架构图:
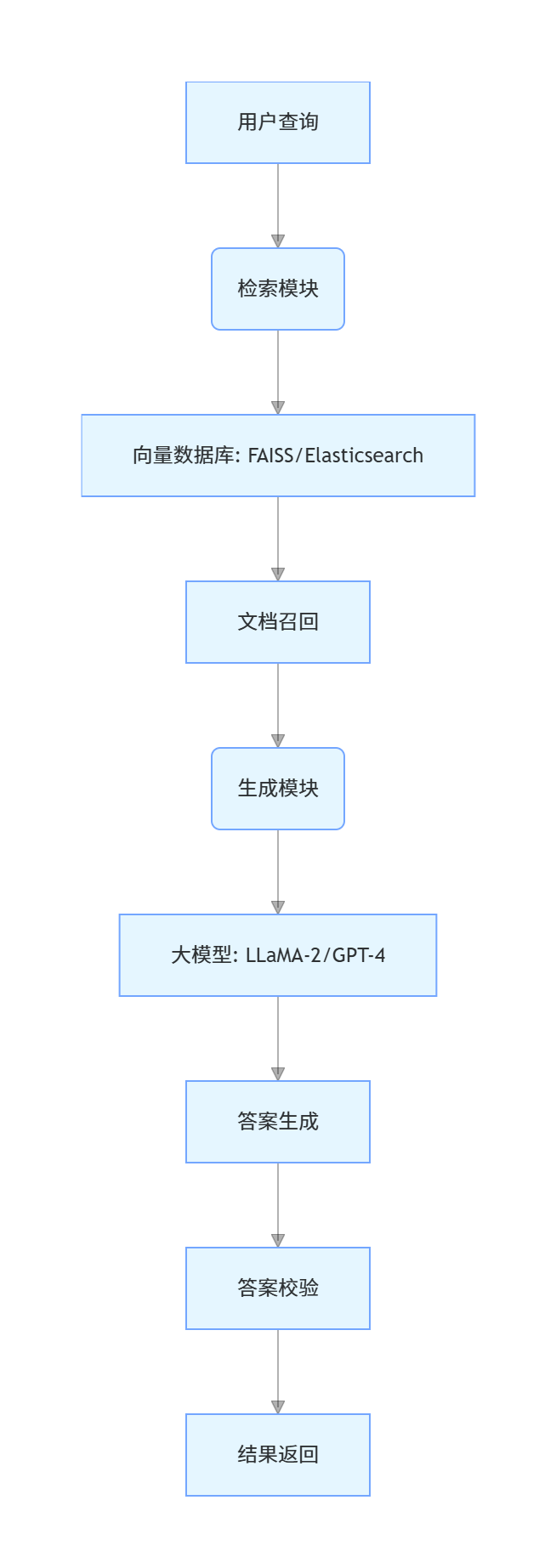
关键实现步骤:
- 文档预处理:使用 spaCy 进行实体识别,通过 Sentence-BERT 生成文档嵌入向量
- 检索优化:引入 BM25 + 向量检索混合策略,提升召回准确率 30%
- 上下文构建:通过滑动窗口技术处理超长文档(支持 4K+ tokens)
- 结果验证:集成 FactCC 事实性校验工具,降低幻觉发生率 50%
四、全行业应用图谱:从效率工具到创新引擎
(一)代码智能领域
- GitHub Copilot X:新增语音编程功能,支持自然语言实时转代码
- CodeGeeX2:突破跨模态代码生成,实现 "截图转代码" 的 UI 开发新模式
- DeepSeek-R1:在 LeetCode 困难题解上达到 85% 通过率,超越人类平均水平
(二)企业服务场景
智能客服系统技术参数对比:
| 功能模块 | 传统规则引擎 | 初代 AI 客服 | 大模型客服 |
| 意图识别准确率 | 75% | 85% | 95%+ |
| 多轮对话深度 | 3 轮 | 5 轮 | 20 轮 + |
| 知识库更新周期 | 周级 | 日级 | 实时 |
| 复杂问题解决率 | 40% | 60% | 85%+ |
(三)科研创新前沿
- AlphaFold3:将蛋白质结构预测时间从 72 小时缩短至 10 分钟,新增 RNA 结构预测功能
- ChemCrow:构建化学合成智能体,自动设计多步有机合成路线,成功率提升 40%
- ClimateNet:基于气象数据训练的预测模型,将极端天气预警时间提前 12 小时
(四)新兴应用场景
- 教育领域:个性化学习系统实现 K-12 全学科覆盖,自适应调整学习难度
- 医疗领域:Med-PaLM 2 在 USMLE 考试中达到 90 分,支持多模态病例分析
- 自动驾驶:NVIDIA DriveGPT 实现端到端驾驶决策,复杂路况处理能力提升 60%
五、产业挑战与未来图景:从技术深水区到商业蓝海
(一)核心技术挑战
- 算力瓶颈突破
- 单卡算力:Nvidia H100 算力达 320 TFLOPS,但万亿参数模型训练仍需千卡级集群
- 能效优化:TPU v5e 将算力效率提升至 30 pJ/OP,边缘端算力需求增长 200%/ 年
- 可靠性提升工程
- 幻觉治理:通过知识图谱增强(+30% 事实准确率)、结果校验(+25% 可信度)组合方案
- 鲁棒性优化:对抗样本训练使模型抗干扰能力提升 40%,通过多语言混合训练降低偏见
- 伦理安全体系
- 数据合规:建立包含 10 万 + 敏感词的内容过滤系统,支持实时动态更新
- 可解释性:开发 Attention Rollout 可视化工具,实现决策过程的层级解构
(二)未来技术趋势
- 模型形态演进
- 轻量化:3B 参数模型(如 Phi-3)在代码生成任务上达到 13B 模型性能
- 专用化:领域定制模型(金融 / 医疗)参数量下降 50%,推理速度提升 3 倍
- 自主化:AutoGPT-4 实现任务分解成功率 85%,支持 72 小时连续自主运行
- 技术融合创新
- 脑科学启发:脉冲神经网络与 Transformer 结合,实现能耗降低 70%
- 物理世界交互:具身智能模型(如 PaLM-E)实现机器人操作规划准确率 92%
- 生物计算融合:DNA 存储技术使训练数据密度提升 1000 倍,存储成本下降 80%
- 产业生态构建
- 开源体系:Hugging Face 模型库突破 10 万 +,月活开发者超 500 万
- 工具链完善:LLM.intuition 提供全流程开发平台,模型迭代周期缩短至 72 小时
- 标准体系:OpenCompass 评测覆盖 200 + 任务,推动行业性能指标标准化
结语:AI 大模型正从技术验证阶段迈向价值创造的深水区。对于开发者而言,需要构建 "底层架构理解 + 工程化能力 + 领域知识" 的三维能力体系,在模型优化(如 4-bit 量化)、场景适配(RAG 架构设计)、安全合规(内容审核系统)等方向建立技术壁垒。随着算力成本持续下降(预计 2025 年 GPU 算力价格下降 40%)和开源生态的繁荣,大模型技术将加速渗透千行百业,催生更多颠覆性应用场景。技术创新与伦理建设的同步推进,将决定 AI 大模型能否真正成为人类文明的通用智能助手。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









