







 本文介绍了Python爬虫的基础知识,包括环境搭建、模块导入、for循环、try-except和第三方库的使用。重点讲解了使用requests_html和beautifulsoup爬取电商平台热卖榜,解决动态加载和反爬问题。同时,介绍了自动化测试框架playwright,如何通过它获取动态加载的数据。
本文介绍了Python爬虫的基础知识,包括环境搭建、模块导入、for循环、try-except和第三方库的使用。重点讲解了使用requests_html和beautifulsoup爬取电商平台热卖榜,解决动态加载和反爬问题。同时,介绍了自动化测试框架playwright,如何通过它获取动态加载的数据。
目录
二、爬虫requests_html和beautiful soup使用
3.定义get_code(page_num)函数获取网页源码
前言
本文是作者自学python的总结性文章,如有不严谨的地方,请各位不吝赐教,共同进步!
一、python基础知识
1.环境搭建
选择anaconda+pycharm,原因是anaconda自带python,所以无需单独再安装python,并且anaconda里面已经自带了常用的第三方库,省去了额外下载第三方库的大量时间,python由于经常需要安装第三方库(可以用python写代码用到第三方库就跟平时喝水一样常见),所以采用anaconda+pycharm最适合。
关于安装anaconda和pycharm网上很多教程,都挺简单的,这里就不讲了。
2.模块导入
用python写代码,一般第一件事就是导入相关模块了,比如你想写个爬虫代码,需要导入模块,你想开发一个小程序,要先导入模块,你想写个代码对excel表格里的数据进行处理,也得先导入模块,总之,无论你用python做什么,都要先导入模块(所以用anaconda真的很方便,无需经常安装模块)
导入的方法也很简单,一般常用2种,第一种就是import 这里是你要导入的模块名,第二种是from这里是你要导入的模块名 import 你要使用的类
代码如下(示例):
#直接导入
import requests_html
#从bs4里只导入BeautifulSoup进行使用
from bs4 import BeautifulSoup3.for循环
学会导入模块之后,接下来学习一些在python里常用的语法。
for循环的使用也较为简单,主要用于我们要重复完成同一件事情的时候,就可以采用for循环,演示代码如下,我做了详细的备注:
z=0#首先定义z为0
a=list(range(0,20))#然后用range生成从0到19总共20个数字,并用list函数将其转为列表
for i in a:#用for循环遍历0到19,i即对应0到19那20个数字,每循环一次,就换下一个数字进行循环,直到最后一个数字19
z+=i#每遍历一次z都加上i
print(z)#最后打印z,结果为1904.try except的使用
这个一般是用来规避错误,让代码接着往下跑的,如果没有这个,当代码遇到bug时,就会报错,而有这个,当代码遇到bug时,则会去执行except后的代码。
5.第三方库的使用
用python完成不同任务时,需要使用不同的库
爬虫应用:requests_html(和requests一样,但功能更丰富)、beautifulful soup
数据分析:pandas、matplotlib
开发应用程序:pyqt5
自动化测试:playwright(和selenium同类型)
二、爬虫requests_html和beautiful soup使用
这里以爬取国际电商平台为例子,这是那个国际电商平台
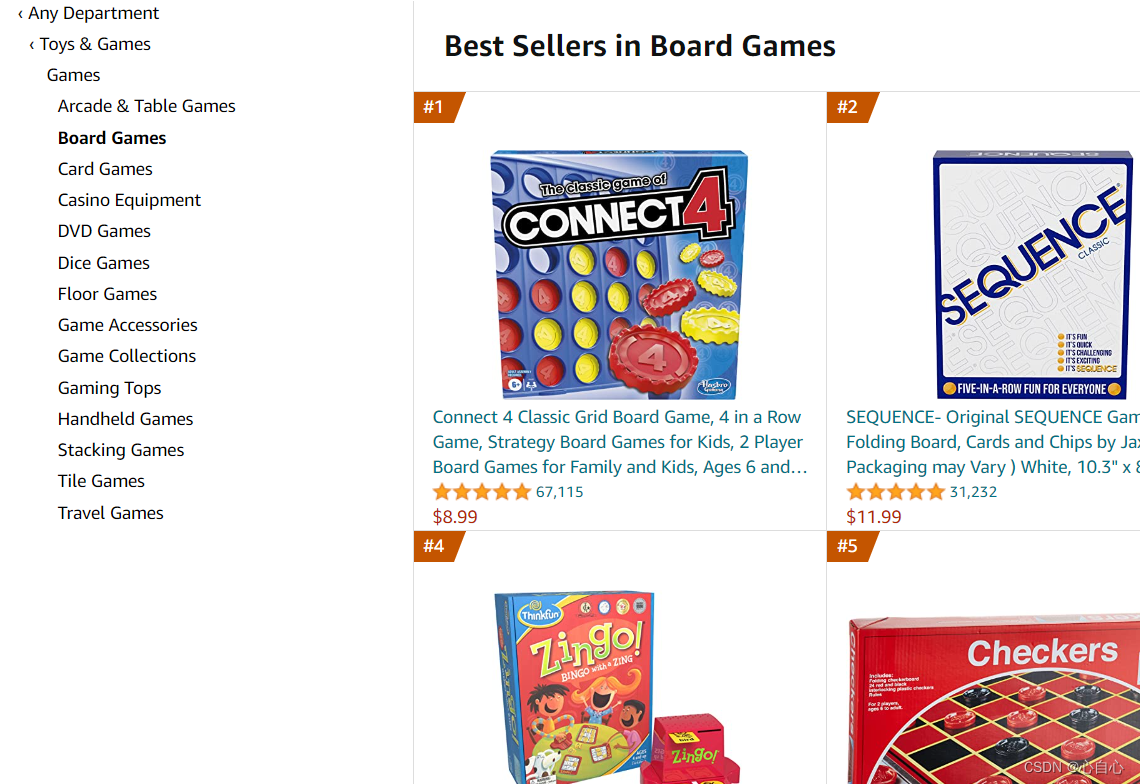
1.引入库
第一步,导入要使用的requests_html和beautiful soup库,代码如下(示例):
"""第一步,导入爬虫应用库"""
from requests_html import HTMLSession,UserAgent
from bs4 import BeautifulSoup2.定义一个获取网页源码的get_code函数
第二步,我们定义一个获取网页源码的函数,主要用到上面导入进来的requests_html函数,在这一步,先创建一个session,后基于这个session发布网络请求get请求。
接着是伪装浏览器,需要创建一个随机ua,即随机请求头,然后把伪装信息全部封装在headers字典里,作为后面发送get请求的一个参数。
接下来是把发送请求得到的响应信息源码保存下来,并返回函数入口,供下面解析步骤使用
代码如下(示例):
"""第二步,拿到网页源码,可以理解一次性拿到所有货物"""
def get_code(page):#定义一个函数,这个函数以页面为参数
session 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











