






虚拟机设置及Hadoop安装配置启动HDFS
文章目录
1. 虚拟机安装
利用上面的下载链接下载安装完毕Vmware之后配置默认虚拟机存放位置
首先找到工作区左上角找到编辑–>首选项:

之后打开首选项找到工作区这一选项卡
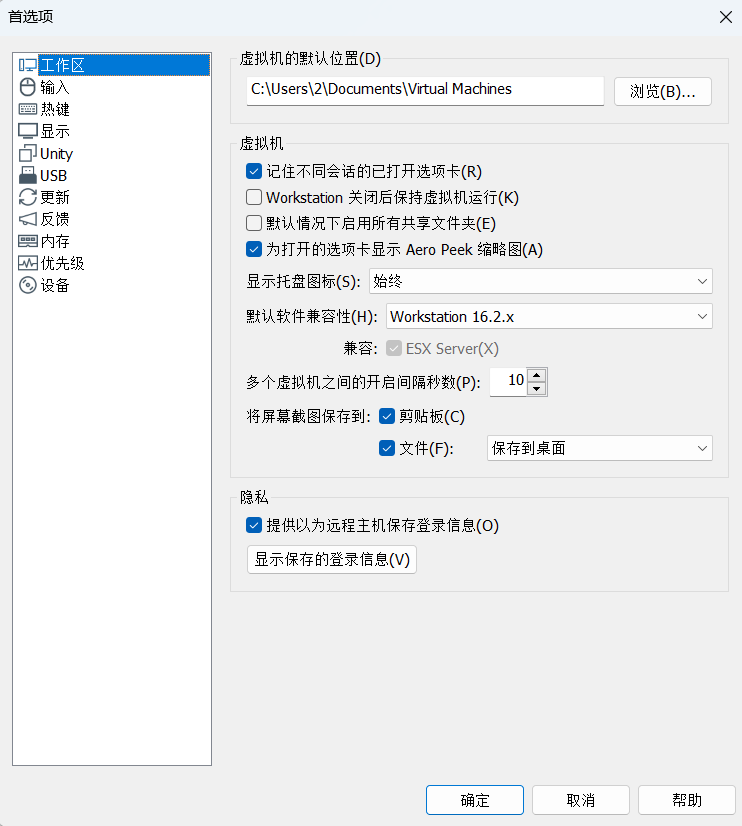
打开浏览并找好需要的文件夹之后保存即可

2. Ubuntu22.04安装
在左上角导航栏找到并点击文件–>新建虚拟机
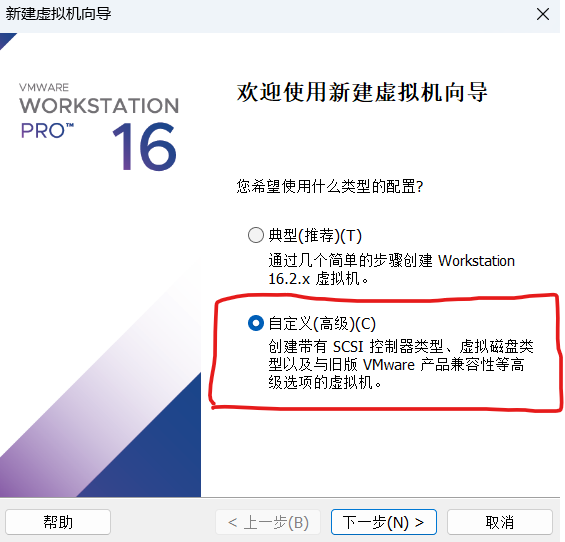
选择自定义高级并点击下一步
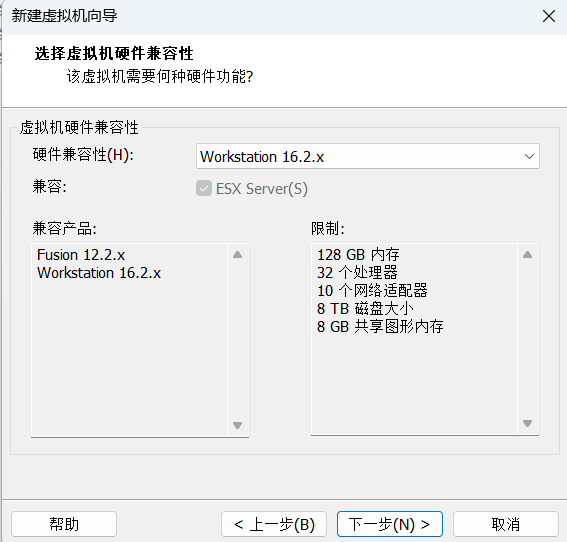
再次点击下一步
这里选择稍后安装操作系统并点击下一步
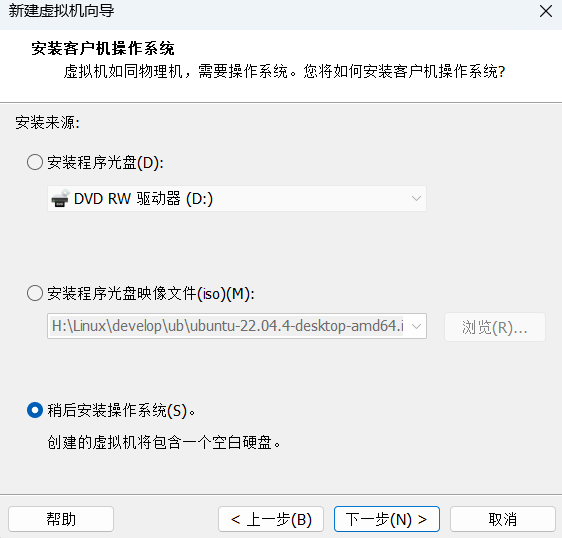
接下来的配置如下,配置好之后进行下一步
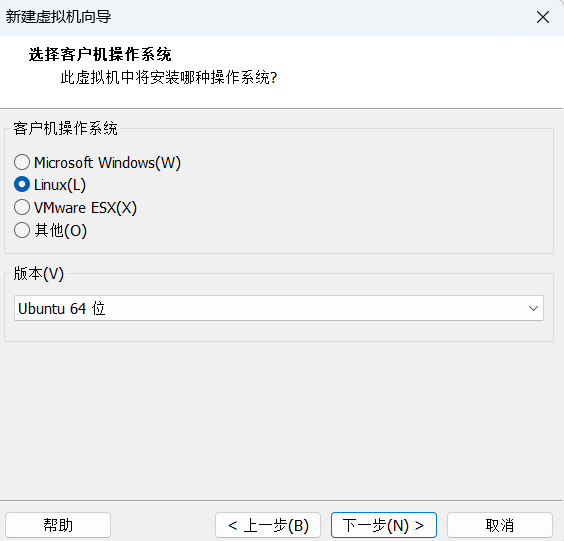
起一个合适且直观的名字和选择存放位置并进行下一步
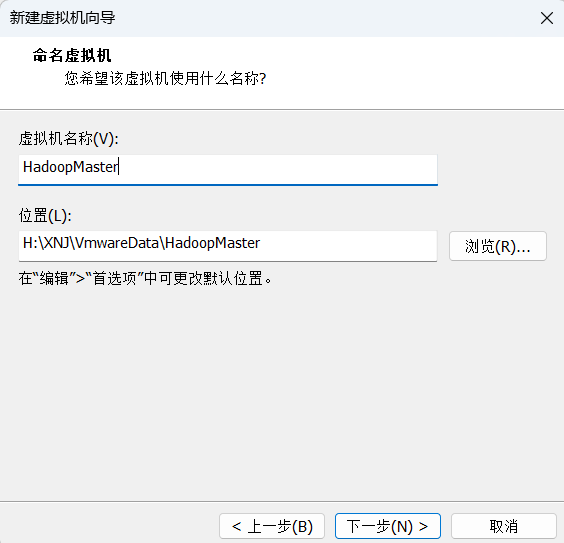
下面就是要选择虚拟机配置了,我们先来看一下官方给的推荐配置。
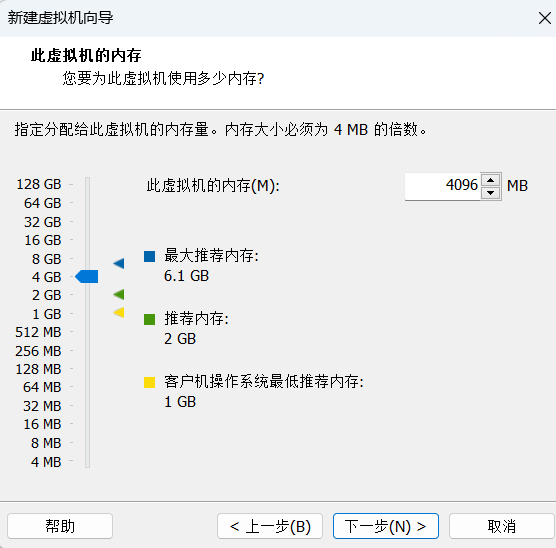
官方建议是双核2 GHz处理器或更高、4 GB系统内存、25 GB磁盘存储空间。我的配置如下.
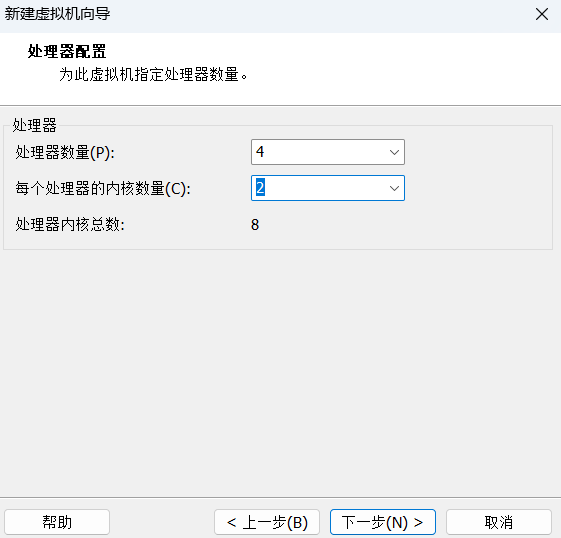
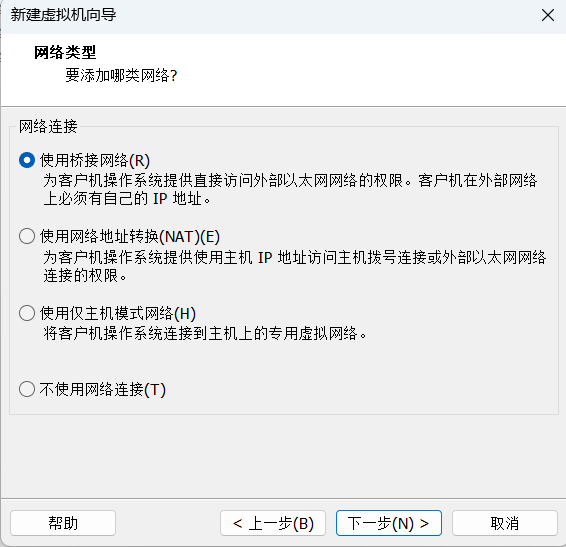
因为Hadoop集群需要,这里选择桥接网络
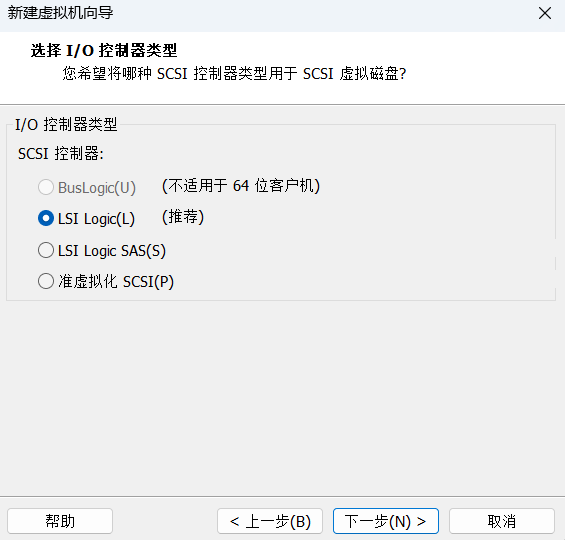
接下来依次点击下一步,具体设置如下图

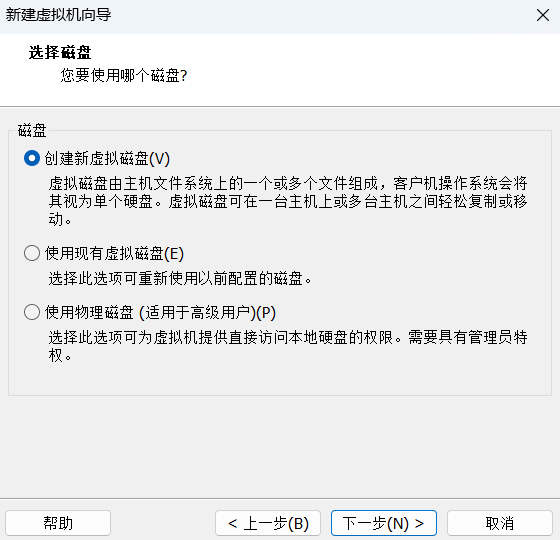
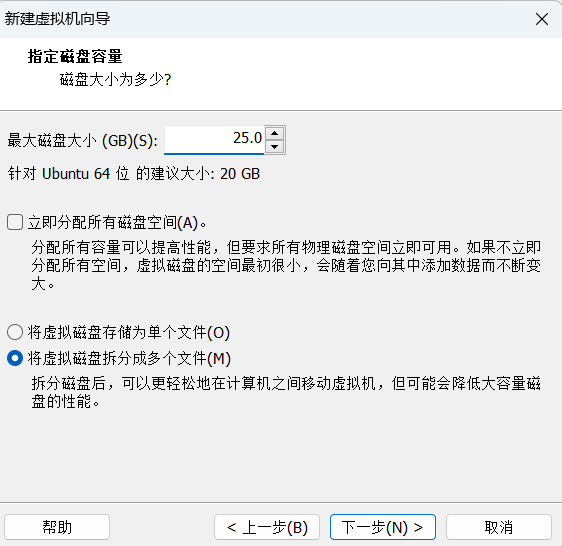
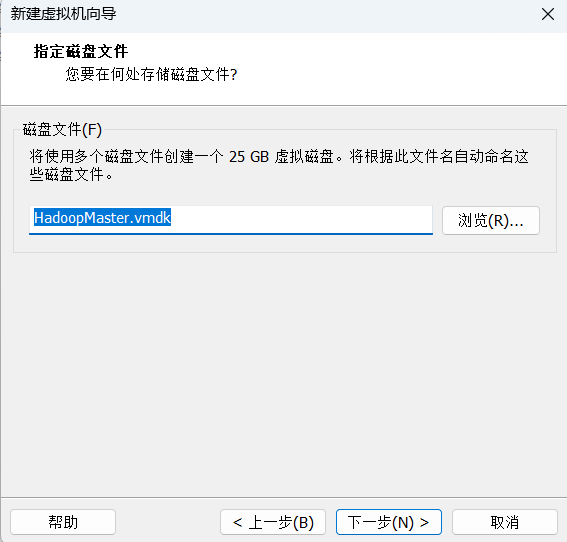
至此已经配置完毕,点击完成即可.
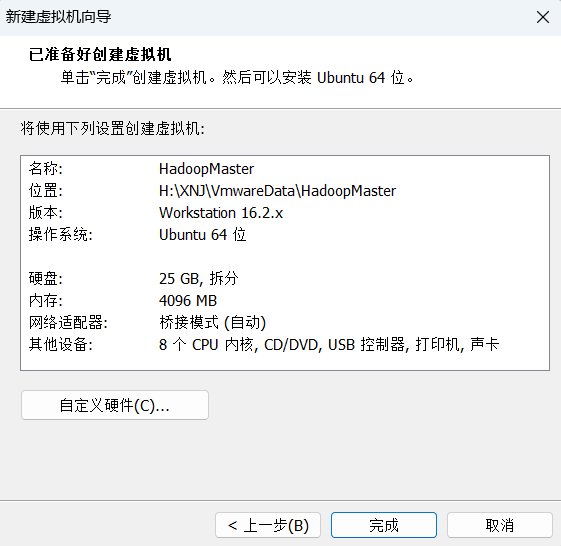
在主页找到刚才配置的虚拟机,并点击编辑虚拟机设置.

找到链接提供的Ubuntu22.04.ISO映像文件并添加之后点击确认
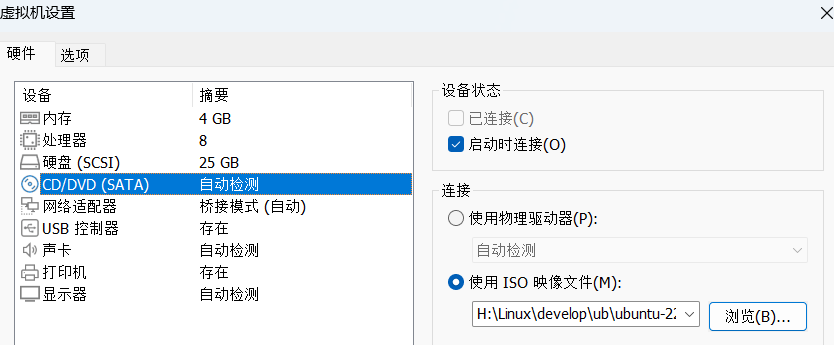
选择第一个并回车
接下来点击Install Ubuntu,选择英语是为了学习,这里也可以选择中文的.
接下来跟着点击就可以了
注意这里是选择时区,选择上海即可
用户名以及密码设置,黄色的圈选第一个自动登录.
耐心等待安装完毕即可
安装完成,重启即可
安装完毕
3. 安装hadoop
3.1 准备工作
3.1.1 创建hadoop用户
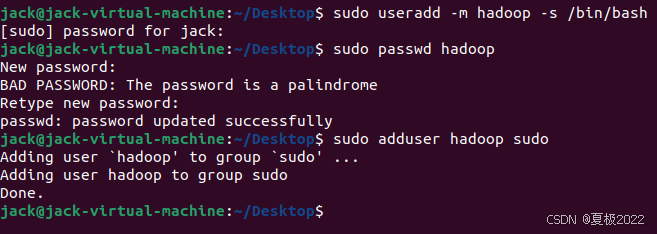
首先按下ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,可简单设置为 1,按提示输入两次密码:
sudo passwd hadoop
为 hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo
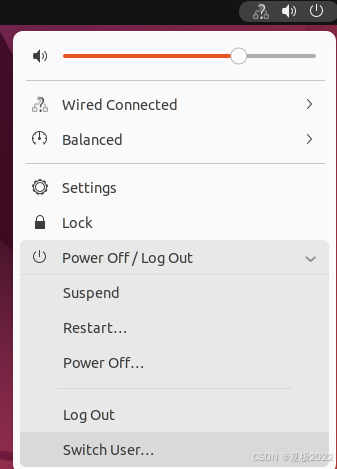
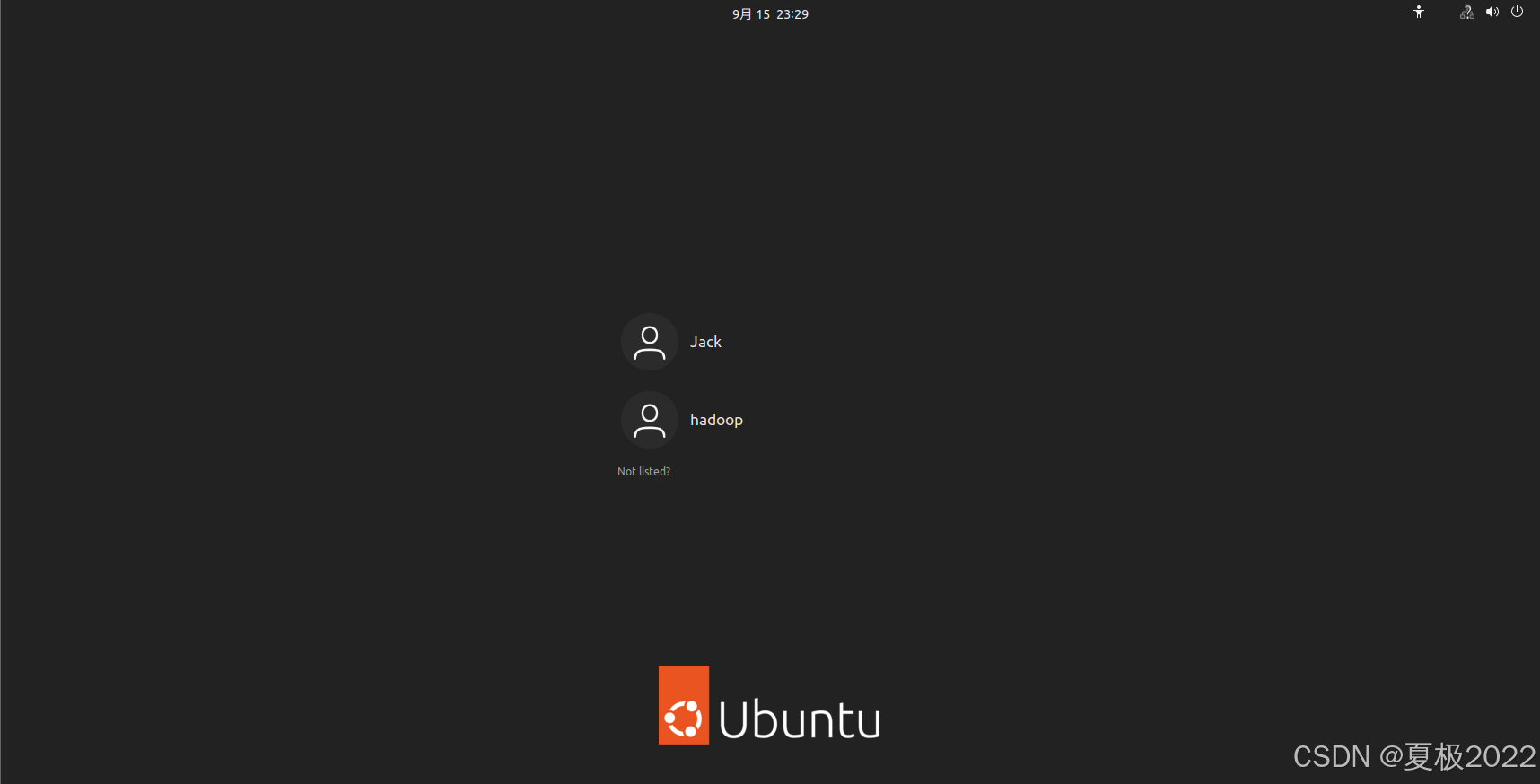
最后注销当前用户点击屏幕右上角,选择Log Out(注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
3.1.2 更换下载源
首先备份文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
编辑文件/etc/apt/sources.list
sudo nano /etc/apt/sources.list
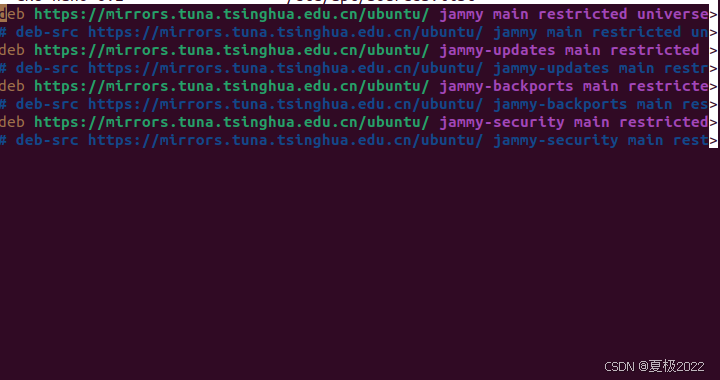
之后Ctrl+o保存,遇到这种情况直接回车之后再Ctrl+x退出

最后运行以下命令更新软件包列表:
sudo apt update
3.1.3 配置ssh及免密登录
Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
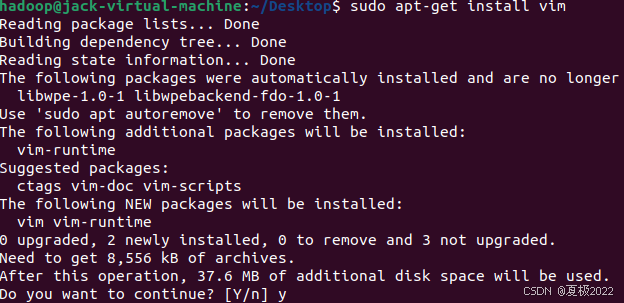
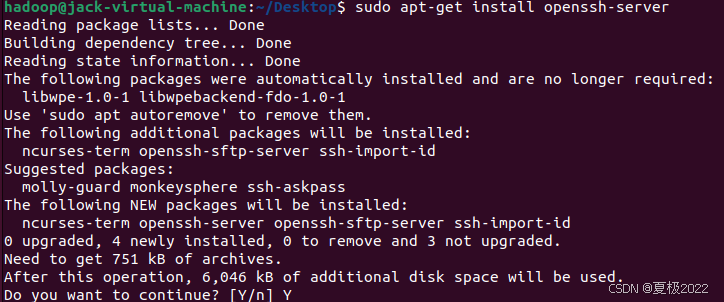
sudo apt-get install openssh-server
遇到询问输入Y即可
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
ssh设置到此结束
3.1.4 设置共享文件夹
右键虚拟机名称并打开设置
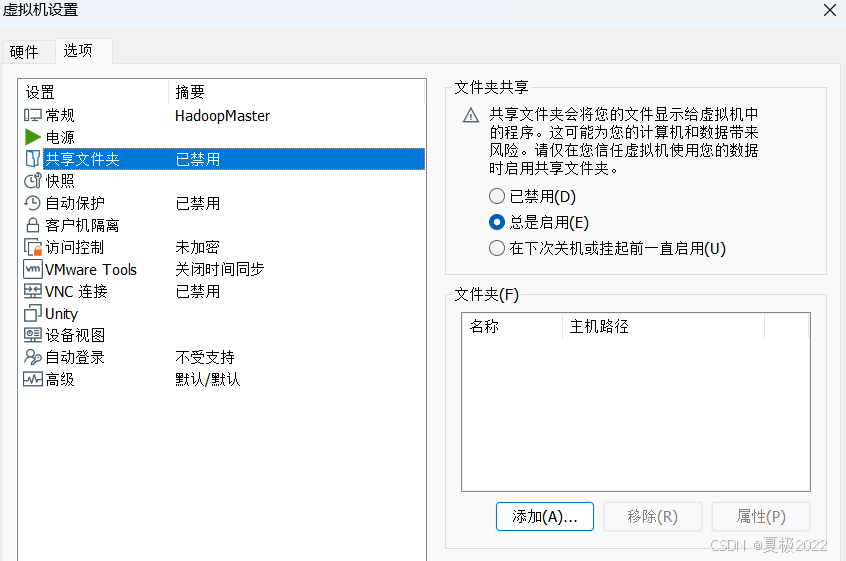
在虚拟机设置中打开选项并找到共享文件夹,且勾选总是启用,之后找到下方添加
选择好自己的共享文件夹之后点击确定并退出
操作完上述步骤以后,在虚拟机中打开终端并输入
vmware-hgfsclient
挂载目录
sudo mkdir /mnt/hgfs
挂载共享目录
sudo /usr/bin/vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other -o uid=1000 -o gid=1000 -o umask=022
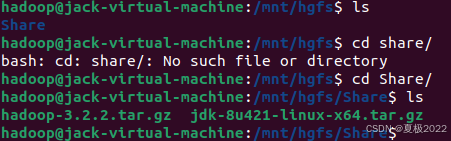
然后在 Ubuntu 中看下能不能看到这个文件,首先我们切换到我们创建的挂载目录:
cd /mnt/hgfs
然后输入 ls,查看是否出现我们一开始创建的共享文件夹,如果出现其实就是成功了
[JDK下载位置](Java Downloads | Oracle 中国)
[Hadoop下载位置](Index of /apache/hadoop/common/ (tencent.com))
将window中下载好的jdk和hadoop放在共享文件夹下之后进行下一步
最后我们切换到我们一开始创建的共享文件夹,输入 ls,看下我们刚刚在 Windows 中放的文件是不是可以看到了:
3.2 配置Java环境
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd /mnt/hgfs/Share #进入hadoop用户的主目录
sudo tar -zxvf ./jdk-8u421-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
打开文件后输入i,在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_421
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
首先按下Esc然后shift+:之后输入wq,保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version

这种情况就是配置成功
3.3 安装Hadoop3.2.2
安装指令如下,前提是Hadoop已经保存在共享文件夹中
sudo tar -zxf /mnt/hgfs/Share/hadoop-3.2.2.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.2.2/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
情况如图

3.4 Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将该文件中的<configuration></configuration>标签覆盖成如下配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格

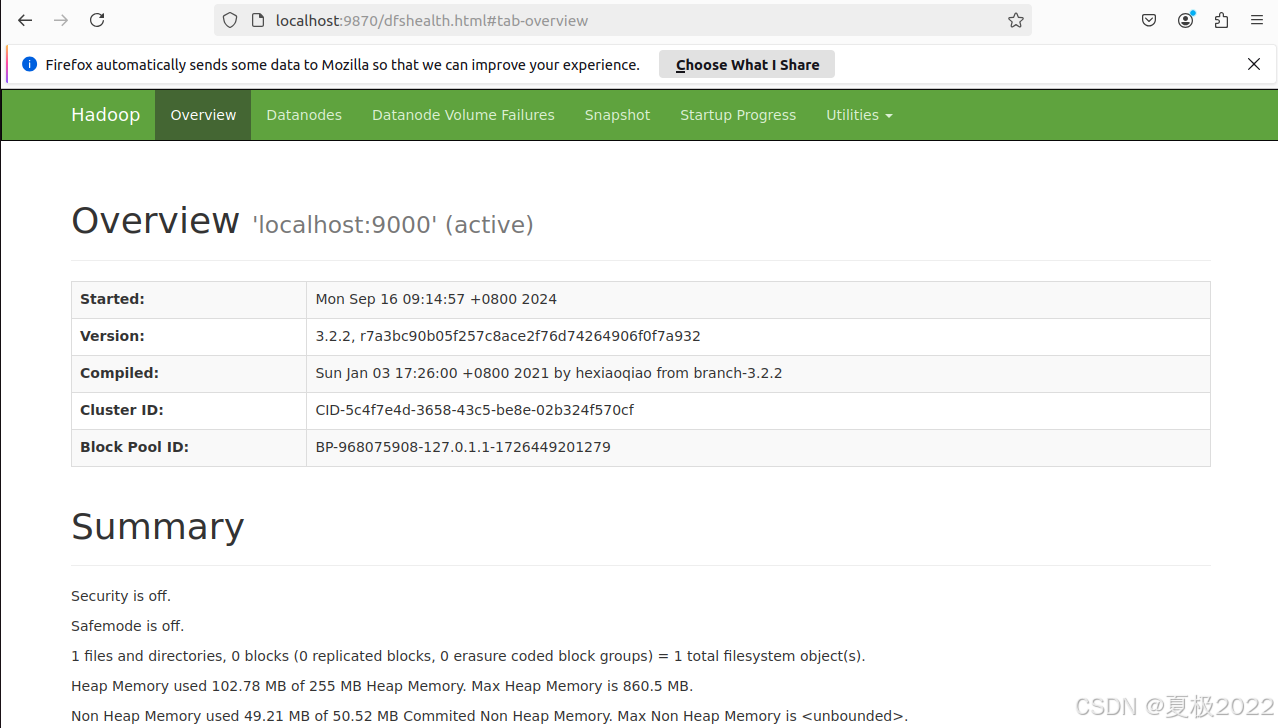
成功启动后,可以在Ubuntu的火狐浏览器中访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
3.5 运行Hadoop伪分布式实例
要使用 HDFS,首先需要在 HDFS 中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
进行一个简单的实验
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
查看结果
./bin/hdfs dfs -cat output/*

将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
运行程序时,输出目录不能存在: 运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
Configuration conf = new Configuration();
Job job = new Job(conf);
/* 删除输出目录 */
Path outputPath = new Path(args[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
运行程序时,输出目录不能存在: 运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
Configuration conf = new Configuration();
Job job = new Job(conf);
/* 删除输出目录 */
Path outputPath = new Path(args[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









