






应用迁移介绍
应用迁移与适配技术是指将一个应用程序从一个平台迁移到另一个平台,并确保它在新平台上的正常运行。这个过程需要考虑到不同平台之间的差异,包括硬件和操作系统等方面的差异。以下是应用迁移与适配技术的一些课程知识介绍:
- 迁移和适配的基本概念:介绍应用迁移和适配的基本概念,包括迁移和适配的区别、迁移和适配的目标和重点等。
- 迁移和适配的策略:介绍应用迁移和适配的策略,包括重写、重新编译、跨平台框架、虚拟化等。
- 平台差异分析:介绍不同平台之间的差异,包括硬件架构、操作系统、网络和安全等方面的差异,并分析这些差异对应用迁移和适配的影响。
- 应用程序迁移:介绍应用程序迁移的过程,包括需求分析、代码修改、编译调试、测试等。
- 应用程序适配:介绍应用程序适配的过程,包括接口适配、数据格式转换、功能扩展等。
应用迁移背景
国产化历程
XC:信息技术应用创新产业
863计划:1986年3月启动实施的“高技术研究发展计划(863计划)” ,旨在提高我国自主创新能力,坚持战略性、前沿性和前瞻性,以前沿技术研究发展为重点,统筹部署高技术的集成应用和产业化示范,充分发挥高技术引领未来发展的先导作用。
核高基:是对核心电子器件、高端通用芯片及基础软件产品的简称,是2006年国务院发布的《国家中长期科学和技术发展规划纲要(2006-2020年)》中与载人航天、探月工程并列的16个重大科技专项之一。
AK:面向党政的具备安全可靠特性的国产化替代项目,信息技术应用创新的前身。
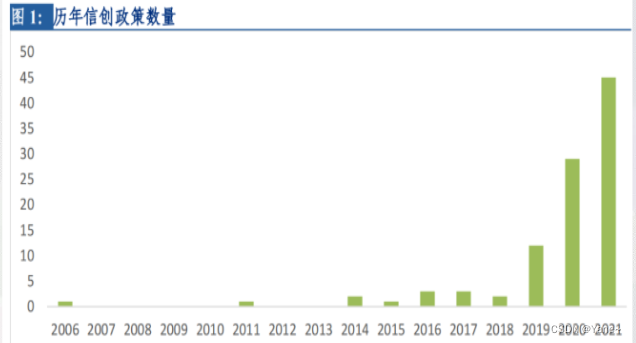
2016年3月4日,24家专业从事软硬件关键技术研究及应用的国内单位,共同发起成立了一个非营利性社会组织,并将其命名为“信息技术应用创新工作委员会”。 这个委员会简称ITAIC,这就是“信创”这个词的最早由来。工委会成立后不久,全国各地相继又成立了大量的信创产业联盟。这些联盟共同催生了庞大的信息技术应用创新产业,也被称为“信创产业”,简称“信创”。
信创发展--内驱力
中国在信息技术底层标准、架构、生态掌控力等方面非常薄弱,已成为其信息产业发展的重要制约和阻碍;是中国在进军社会主义现代化强国征程中的绊脚石。
去IOE: I是指“IBM”,O是指“Oracle”,E是“EMC”。去IOE就是去掉IBM的小型机、Oracle数据库、EMC存储设备,代之在开源软件基础上开发的系统。
国家战略层面关注安全
企业关注效益,比如去ioe,比如aws的芯片定制 都离不开XC。“所以信创不是政治口号,也不是大运动,而是真真正正的需求。”
信创发展--国家意志
有关信创产业,近期国家又出台了新的政策。2022年9月底下发的79号文,全面指导国资信创产业发展和进度,要求所有央企+地方国企落实信创全替代。
未来的信创为持久化、常态化产业,在国家意志的大背景下各大国产化厂商持续发力,人才缺口呈井喷式增长。
信创发展--市场规模
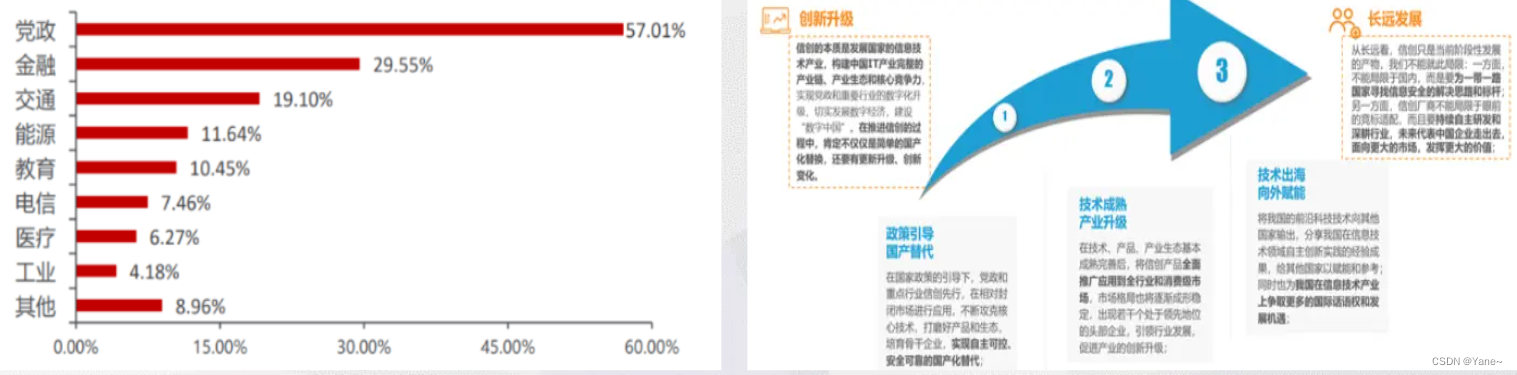
从信创产业整体市场来看,相关数据显示,2021年信创产业整体市场规模6886.3亿元,近五年复合增速达到35.7%,预计2025年市场规模将达到23354.6亿元。
信创发展--行业
国家此前制定的“2+8+N”的信创三步走战略。 “2”就是首先实现机关范围内的国产替代,同时顺带打磨产品、培育骨干企业。 “8”指的是金融、电信、电力、石油、交通、航空航天、教育、医疗8大关键行业。在产品相对好用、生态比较成熟后,信创将由党政系统扩大到8大关键行业。 “N”就是其他行业,最终将信创产品扩展到全行业。
信创会逐渐影响到每一个人。

编译型语言应用移植
信创行业使用arm架构较多,需要进行应用程序相关适配移植,掌握程序移植标准化移植,便于在国产化项目中快速完成适配迁移。
编译型语言开发应用移植方案
作为编译型语言,必须经过编译编程可执行的机器码才能最终执行。
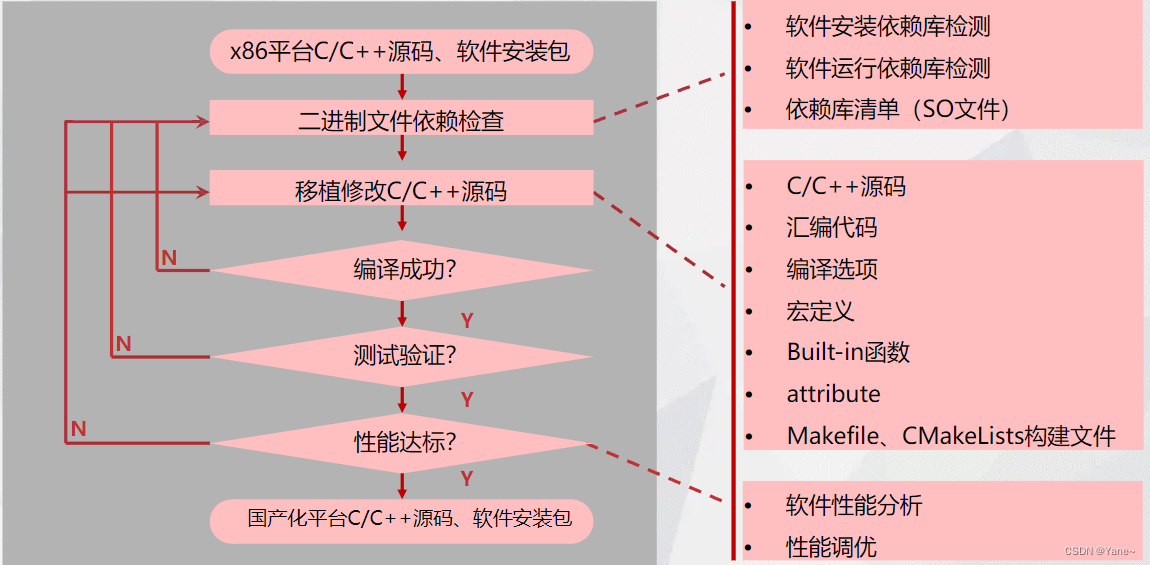
如果一款应用,之前由编译型语言c或者c++编写。现在要把它移植到xc环境,可以遵从上图所示的策略路径。
- 首先在信创环境中进行二进制文件依赖检查。 细节为第一步检查安装所需的依赖库是否存在并且存在,以保证应用能够正常安装, 第二步检查运行时所需的静态链接库、so库也就是动态链接库是否存在并且好用,以保证该应用能够正常运行。
- 再检查是否需要 修改C/C++源码,常见的检查点有源码中是否包含了汇编代码,如果包含了汇编代码,由于CPU技术路线的问题汇编代码都需要重新编写。 源码中是否使用了特殊的宏定义、built-in函数、attribute这些都需要针对xc环境进行修改才能保证编译通过。源码在编译执行时,是否需要添加特定的参数比如gcc 编译时加入 –f signed-char。如果整个工程的编译是通过makefile,cmakelists控制的,还要检查相关的构建文件。到此如果你做的不错就能保证编译通过了。
- 编译成功,不代表移植成功。还需要进行功能性测试、兼容性测试,以保证该应用在信创环境中能用。
- 测试验证通过后只能保证该应用在信创环境中能用,但是否好用呢?还要进行性能测试。比如一个oa系统的请假功能,在xc环境中经过以上步骤可以请假了,但是一旦10个人同时使用此功能,系统就会响应慢,甚至崩溃。这当然也是不行的,我们必须通过软件性能分析、性能调优以保证该应用不但能用,还要好用。
- 最后如果通过了所有的测试,就可以把源码重新打包发布了。
编译型语言应用移植案例
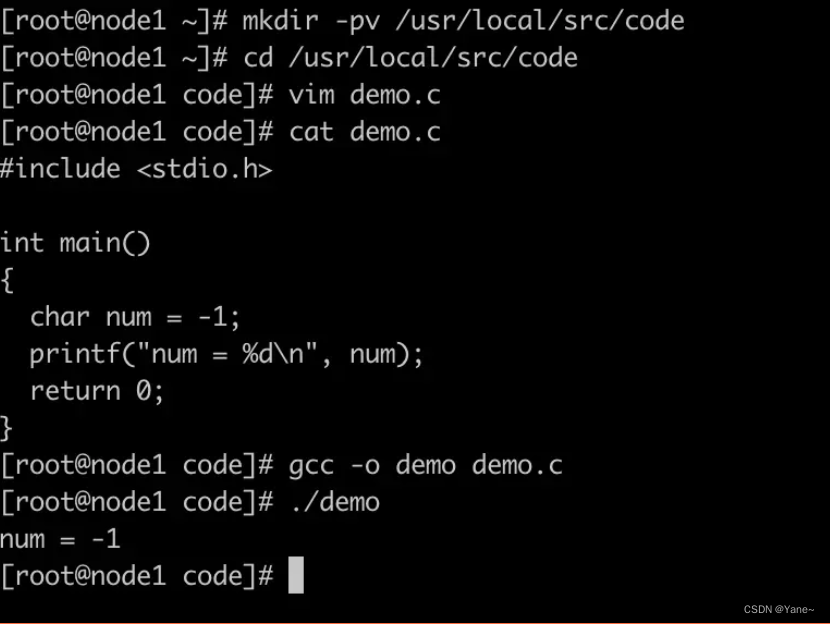
准备文件demo.c 文件内容如下:
#include <stdio.h> int main() { char num = -1; printf("num = %d\n", num); return 0; }
我们观察到在x86环境编译执行后,结果为 -1
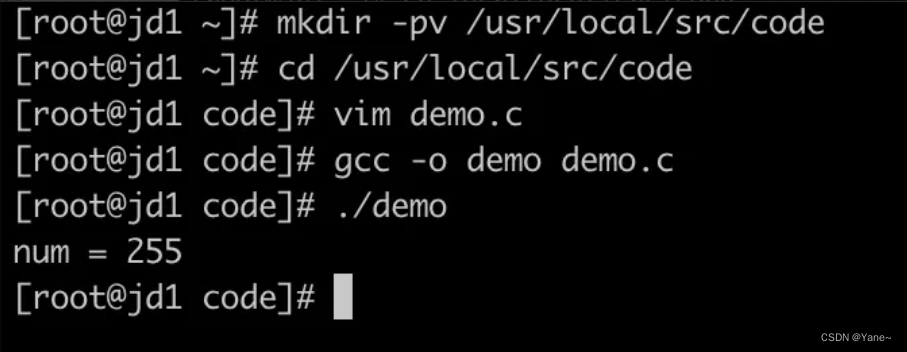
同样的代码我们拿到鲲鹏920芯片的麒麟系统中执行,结果为255
原因分析
-1的二进制原码是10000001,它的补码是除了符号外取反加 1,最后补码就是11111111。在x86架构下,char默认是有符号的,所以打印的时候正常打印-1,
但是在鲲鹏架构下char默认是无符号的,这个二进制的11111111正好就是无符号的255。
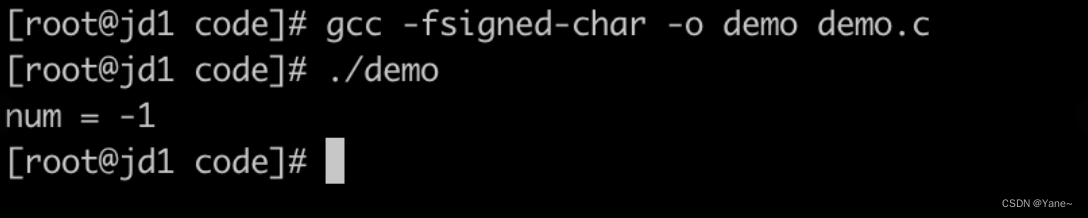
所以,出现这种情况的原因就是x86架构和鲲鹏架构对于char的 默认处理不一样,一个是默认有符号,另一个是默认无符号。修改编译参数
对于这种情况,有两种处理方式:
一种就是在编译时指定参数,把默认无符号型 改成默认为有符号型。编译-fsigned-char
一种是修改源代码,把数据类 型指定为有符号型; (后面有例子)修改源代码
#include <stdio.h> int main() { signed char num = -1; printf("num = %d\n", num); return 0; }需要注意的是,刚才的方法,通过修改编译选项会把源代码中所有的char类型变量都当作 有符号类型,如果只是更改其中部分char变量,这种方式就不合适了。
此时可以通过修改源代码的方式,直接编译即可。这种方式需要对源码有足够的理解。两种方式可以依据应用场景,区分使用。技术要点
源代码修改 对于源代码修改的场景,主要分为以下几种:
- 对内嵌的汇编指令的修改
- char数据类型的修改,把char数据类型更改为signed char。
- 双精度浮点型转整型溢出处理的修改
编译选项修改:
- char数据类型默认无符号
- 指定编译64位应用
- 目标指令集
- 编译宏
应用移植makefile
我们在开发一个大型项目中,需要使用make工具简化整体项目编译的工作量,是每一个程序员必备的技能。
Makefile概述:
Makefile 文件描述了整个工程的编译、连接等规则。
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。 只有这样源代码才能变成可执行文件,在操作系统上变为进程开始执行。
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile就像一个Shell脚本一样,也可以执行操作系统的命令。
Linux 环境下的程序员如果不会使用GNU make来构建和管理自己的工程,应该不能算是一个合格的专业程序员,至少不能称得上是 Unix程序员。在 Linux(unix )环境下使用GNU 的make工具能够比较容易的构建一个属于你自己的工程,整个工程的编译只需要一个命令就可以完成编译、连接以至于最后的执行。不过这需要我们投入一些时间去完成一个或者多个称之为Makefile 文件的编写。所要完成的Makefile 文件描述了整个工程的编译、连接等规则。其中包括:工程中的哪些源文件需要编译以及如何编译、需要创建哪些库文件以及如何创建这些库文件、如何最后产生我们想要的可执行文件。尽管看起来可能是很复杂的事情,但是为工程编写Makefile 的好处是能够使用一行命令来完成“自动化编译”,一旦提供一个(通常对于一个工程来说会是多个)正确的 Makefile。编译整个工程你所要做的事就是在shell 提示符下输入make命令。整个工程完全自动编译,极大提高了效率。
make是一个命令工具,它解释Makefile 中的指令。在Makefile文件中描述了整个工程所有文件的编译顺序、编译规则。Makefile 有自己的书写格式、关键字、函数。像C 语言有自己的格式、关键字和函数一样。而且在Makefile 中可以使用系统shell所提供的任何命令来完成想要的工作。Makefile在绝大多数的IDE 开发环境中都在使用,已经成为一种工程的编译方法。
Makefile实操:hellomake.c内容如下
#include "hellomake.h" int main() { myPrintHelloMake(); return 0; }hellofunc.c 内容如下
#include <stdio.h> void myPrintHelloMake() { printf("Hello makefiles!\n"); return; }hellomake.h 内容如下
void myPrintHelloMake();首先在同一个目录下创建文件hellomake.c, hellofunc.c, hellomake.h
我们的主程序入口main定义在hellomake.c 文件中,通过语句#include “hellomake.h” 引用定义好的函数myPrintHelloMake(); 函数的具体定义写在hellofunc.c中编译并执行
[root@jd1 make_demo]# gcc -o hellomake hellomake.c hellofunc.c -I . [root@jd1 make_demo]# ./hellomake Hello makefiles!#vim Makefile
target ... : prerequisites ... commandhellomake: hellomake.c hellofunc.c gcc -o hellomake hellomake.c hellofunc.c -I. clean: rm hellomaketarget
可以是一个object file(目标文件),也可以是一个执行文件,还可以是一个标签(label)。
如果大家对什么是label不清楚也没关系,先跳过。
prerequisites
生成该target所依赖的文件
command
该target要执行的命令(任意的shell命令)
这是一个文件的依赖关系,也就是说,target这一个或多个的目标文件依赖于prerequisites中的文件,其生成规则定义在command中。说白一点就是说:
prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。
这就是makefile的规则,也就是makefile中最核心的内容。
hellomake: hellomake.c hellofunc.c ##hellomake 就是gcc –o要生成的目标文件 ,: hellomake.c hellofunc.c 生成目标文件所需的依赖
gcc -o hellomake hellomake.c hellofunc.c -I. ##具体执行的指令
clean: ##就是执行make clean ,就是执行下面的指令,清除编译产生物
rm hellomake执行make 生成hellomake
[root@jd1 make_demo]# ./hellomake Hello makefiles! [root@jd1 make_demo]#之前我们通过gcc -o hellomake hellomake.c hellofunc.c -I . 才能编译生成hellomake
现在只需要把编译规则定义好在Makefile中,直接一条make命令就搞定了。执行make clean 观察效果
[root@jd1 make_demo]# pwd /usr/local/src/code/make_demo [root@jd1 make_demo]# ls hellofunc.c hellomake hellomake.c hellomake.h Makefile [root@jd1 make_demo]# make clean rm hellomake [root@jd1 make_demo]# ls hellofunc.c hellomake.c hellomake.h Makefile [root@jd1 make_demo]可见,Makefile不仅仅能定义编译的规则,还能定义其他规则。
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile就像一个Shell脚本一样,也可以执行操作系统的命令。
Makefile 与 应用迁移适配
Makefile 文件描述了整个工程的编译、连接等规则。其中包括:工程中的哪些源文件需要编译以及如何编译、需要创建哪些库文件以及如何创建这些库文件、如何最后产生我们想要的可执行文件。尽管看起来可能是很复杂的事情,但是为工程编写Makefile 的好处是能够使用一行命令来完成“自动化编译”,一旦提供一个(通常对于一个工程来说会是多个)正确的 Makefile。编译整个工程你所要做的事就是在shell 提示符下输入make命令。整个工程完全自动编译,极大提高了效率。
在迁移适配工作中由于同样一份源码要在不同的芯片架构下进行编译,如果手动控制每一条编译指令,难免出现问题,并且不高效。
所以掌握好Makefile的编写规则,能帮你大大提升应用迁移适配的效率。Make tools 是包含一系列指令
Make tools 按照makefile中定义好的规则,去编译源码文件
在移植应用程序的过程中,可能需要修改makefile以适应新的目标平台。以下是一些在移植过程中可能需要修改的常见makefile指令。
- CC和CFLAGS:CC指定C编译器,CFLAGS指定编译选项。在新的平台上,可能需要指定新的编译器和特定的选项。修改CC和CFLAGS以适应新的平台。
- LDFLAGS和LIBS:LDFLAGS指定链接选项,LIBS指定链接的库。在新的平台上,可能需要指定新的链接选项和特定的库。修改LDFLAGS和LIBS以适应新的平台。
- OBJS:OBJS列出需要编译的源文件。在新的平台上,可能需要添加或删除一些源文件。修改OBJS以包含或排除新的源文件。
- TARGET:TARGET指定生成的可执行文件名。在新的平台上,可能需要修改可执行文件名。修改TARGET以适应新的平台。
- clean:clean指令用于清理生成的文件。在新的平台上,可能需要修改clean指令以删除新的文件。修改clean指令以适应新的平台。
- install:install指令用于安装生成的可执行文件。在新的平台上,可能需要修改install指以将可执行文件安装到新的位置。修改install指令以适应新的平台。
- 其他平台相关的指令:根据具体情况,可能需要根据新的平台修改其他makefile指令。例如,如果在新的平台上有特定的编译器选项或库路径,需要相应地修改makefile。
需要注意的是,在修改makefile之前,需要了解新的平台的编译器、链接器和库的配置情况,以正确地修改makefile指令。另外,移植应用程序时可能还需要修改源代码以适应新的平台。
rpm打包
rpm包概述
What&Why:RPM有五种基本的操作功能:安装、卸载、升级、查询和验证。 有时候为了方便源码包的安装,我们有自己订制软件包的需求,我们会把一些源码包按照我们的需求来做成rpm包。
源码编译产生的可执行文件,在提供给最终用户使用时,通常以rpm包的方式进行发布,类似windows下的安装包。
RPM有五种基本的操作功能:安装、卸载、升级、查询和验证。
linux软件包分为两大类:
- 二进制类包,包括rpm安装包(一般分为i386和x86等几种)
- 源码类包,源码包和开发包应该归位此类(.src.rpm)。
有时候为了方便源码包的安装,和我们自己订制软件包的需求,我们会把一些源码包按照我们的需求来做成rpm包,当有了源码包就可以直接编译得到二进制安装包和其他任意包。
spec file是制作rpm包最核心的部分,rpm包的制作就是根据spec file来实现的。rpm包实操
RPMbuild环境准备
#yum install rpm-build rpmdevtools rpmlint -y
RPMbuild环境准备 #yum install rpm-build rpmdevtools rpmlint -y步骤1 执行rpmdev-setuptree ,创建rpmbuild目录
#rpmdev-setuptree步骤2 创建Demo软件包
#mkdir rpmbuild-1.0 #vim rpmbuild-1.0/rpmbuild_hello.sh #cat rpmbuild-1.0/rpmbuild_hello.sh #!/usr/bin/env bash echo "Hello rpmbuild" #chmod +x rpmbuild-1.0/rpmbuild_hello.sh步骤3 打包
#tar czvf rpmbuild/SOURCES/rpmbuild-1.0.tar.gz .步骤4 创建与编辑SPECFILE
rpmdev-newspec rpmbuild/SPECS/rpmbuild.spec执行编辑指令
#vim rpmbuild/SPECS/rpmbuild.spec
##Version: 1.0 ,Release: 1 会拼凑在一起够成整体rpm名称的一部分
通常specs文件需要修改时一下几项Name: 用来设定名称
Version: 用来设定版本
Release: 用来设定发行版
Summary: 用一句话概括改软件包的信息
License: 软件授权方式,通常是GPL或者GPLv2,BSD
Source:软件包的名字如name-0.0.1.tar.gz
URL: 软件的主页
BuildRequires: 制作过程中用到的软件包,构建依赖
Requires: 安装时锁需要软件包
%description: 软件包详细说明,可写步骤5 生成rpm包在多行上
#rpmbuild -bb rpmbuild/SPECS/rpmbuild.spec #ls rpmbuild/RPMS/aarch64/ rpmbuild/RPMS/aarch64/rpmbuild-1.0-1.ky10.aarch64.rpm该指令会按照之前编写好的spec文件生成rpm软件包
该rpm包生成在rpmbuild/RPMS/aarch64/目录下,这里的aarch64会根据你的芯片技术架构自动产生步骤6 安装rpm包并测试
rpm包与应用迁移适配
RPM 是 Linux 下常用的软件包类型。RPM 包移植时本质上是移植一些二进制文件,将 x86 依赖的文件替换为信创平台的。
移植时首先寻找有没有对应信创平台的 RPM 包,从以下渠道尝试获取:
操作系统的本地源;操作系统的远端源;
国内厂商社区(比如华为,阿里)所有途径都失败,则下载源码重新编译。RPM 包重构时
首先找出 x86 依赖项,依赖项有对应的文件能直接替换的就直接替换,否则就用源码编译。之后替换打包再做验证。




















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











