






对于初学者来说,刚接触到人工智能(AI)、机器学习(ML)和深度学习(DL)可能会分不清,不知道它们的联系,或者不知道它们是什么概念,也不知道它们能做什么。
本文旨在帮大家系统地理清概念,了解技术上面的差异,可以更有目标的去学习及应用。
概念及定义
通俗来说,人工智能就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。
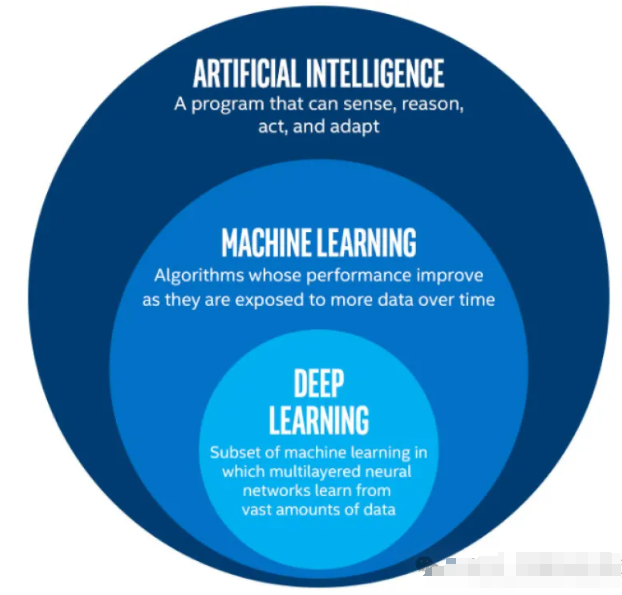
具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、深度学习是人工智能的重要组成。

机器学习是让计算机通过算法自动从数据中学习规律和模式,机器学习常见的任务有分类任务(如通过逻辑回归模型判断邮件是否为垃圾邮件类)、回归预测任务(线性回归模型预测股价)等等。
深度学习是机器学习的一个子方向,是当下的热门,它实现的功能和机器学习差不多,区别在于深度学习是通过搭建深层的神经网络模型以处理任务,主要任务有如深度神经网络模型回归预测股价 、 CNN做图像分类的任务,以及最近特别火爆的大模型内容生成。
综上,人工智能从技术层面上约等于机器学习,而深度学习只是机器学习的一部分(子类),深度学习可以看做是一种用上神经网络的比较“新” 及热门的技术。
接下来我们具体介绍下机器学习与深度学习的区别及联系!
学习方法
机器学习:基于数据和算法,通过训练数据来调整模型参数,从而实现预测和分类等功能。常见的机器学习算法包括线性回归、决策树、支持向量机等。
深度学习:使用神经网络模型,通过反向传播算法和梯度下降优化技术来调整网络权重和参数。常见的深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等。
数据需求
机器学习:需要足够的数据来训练模型,但并不一定需要全部数据。可以通过特征选择、降维等技术来处理大规模数据集。
深度学习:需要大量的数据进行训练,尤其是对于复杂的任务和模型。通常需要使用无监督学习进行预训练,以减少对大规模数据集的需求。
模型的复杂性
机器学习:模型通常较为简单,主要是线性模型和统计模型等。模型的复杂度取决于所选择的算法和特征工程。
深度学习:模型通常非常复杂,具有大量的神经元和层数。通过逐层传递信息,深度学习模型能够自动提取和抽象出有用的特征。
优缺点
机器学习:优点在于其预测准确度高,适用于各种类型的数据和任务;缺点是需要足够的数据和特征工程,对于复杂任务的建模能力有限。
深度学习:优点在于其强大的表示能力和泛化能力,能够处理复杂的非线性问题;缺点是计算量大、训练时间长,对于大规模数据集的需求较高。
应用领域
机器学习:应用领域包括推荐系统、数据挖掘等。例如,使用支持向量机进行文本分类或使用决策树进行预测。
深度学习:应用领域主要为图像识别、语音识别、自然语言处理等。例如,使用卷积神经网络进行图像分类或使用循环神经网络进行文本生成。
两者区别(总结)
模型层面:
机器学习是基于传统模型(统计学习模型、KNN等等);
深度学习则使用神经网络模型进行学习和预测。
应用方面:
机器学习适用于各种类型的数据和任务;
深度学习则更适用于处理复杂的非线性问题。
复杂度:
深度学习的模型通常比机器学习模型更加复杂,需要更多的计算资源和训练时间。
可解释性:
机器学习:模型通常较为简单,因此具有一定的可解释性。例如,决策树和线性回归模型可以通过规则和系数来解释。
深度学习:由于模型的复杂性和黑箱性质,通常难以解释。这使得深度学习在某些需要解释的场景中受到限制。
鲁棒性:
机器学习:一些传统的机器学习算法可能对噪声和异常值敏感。
深度学习:通过强大的表示能力和鲁棒的网络结构,大数据加持的深度学习模型通常具有较好的鲁棒性,能够更好地处理噪声和异常值。
数据标注需求:
机器学习:许多传统的有监督机器学习算法需要一些标注数据,主要视模型复杂度具体来看,一些简单模型样本需求并不高,几百个也可以支持。
深度学习:深度学习模型通常需要大量的标注数据,尤其是对于复杂的任务。然而,深度学习无监督学习和其他技术也可以减少对大量标注数据的需求。
代码示例
1、机器学习分类预测项目
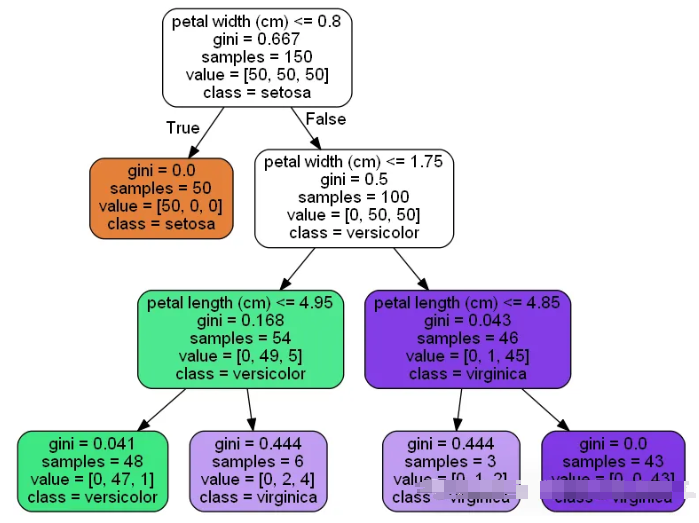
## 机器学习做iris植物的分类任务
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型并训练
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
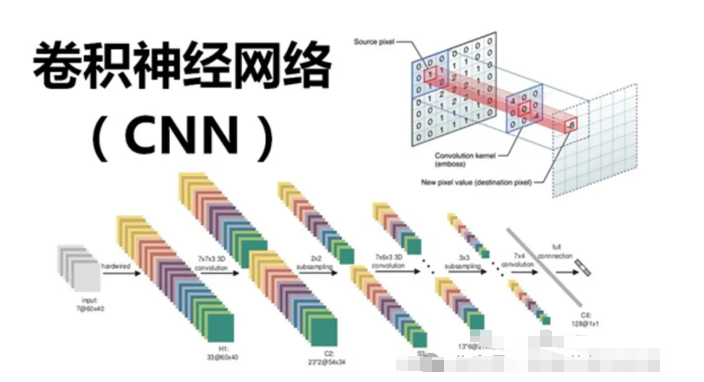
2、深度学习图像识别分类项目
"""
深度学习图像分类:
首先加载MNIST数据集并进行预处理,然后将数据集转换为适合深度学习模型
使用的格式。接下来,创建一个序贯模型并添加两个全连接层(密集层)。
第一层有128个节点并使用ReLU激活函数,第二层有10个节点
并使用softmax激活函数进行分类。
然后,使用Adam优化器和交叉熵损失函数编译模型。
最后,用训练数据对模型进行训练.
"""
# 导入所需库 import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.optimizers import Adam
from keras.utils import to_categorical
# 加载数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train / 255.0 # 归一化数据范围至[0,1]之间
x_test = x_test / 255.0 # 归一化数据范围至[0,1]之间
y_train = to_categorical(y_train) # 对目标变量进行分类编码(one-hot encoding)
y_test = to_categorical(y_test) # 对目标变量进行分类编码(one-hot encoding)
input_shape = x_train[0].shape # 获取输入的形状(例如:28x28)并指定为模型的输入维度
x_train = x_train.reshape(-1, input_shape[0] * input_shape[1]) # 将数据展平为一维数组,例如:784x28000(784为每个像素点的维度)
x_test = x_test.reshape(-1, input_shape[0] * input_shape[1]) # 将数据展平为一维数组,例如:784x10000(784为每个像素点的维度)
# 创建模型并训练
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(input_shape[0],))) # 添加一个全连接层,节点数为128,激活函数为ReLU函数,输入维度为特征的数量
model.add(Dropout(0.2)) # 添加一个dropout层,丢弃率为0.2,用于防止过拟合
model.add(Dense(10, activation='softmax')) # 添加一个全连接层,节点数为类别数量,激活函数为softmax函数,用于多分类问题输出概率分布
model.compile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型,优化器使用Adam,损失函数使用交叉熵损失函数,评估指标使用准确率
model.fit(x_train, y_train, batch_size=64, epochs=10, validation_data=(x_test, y_test))
# 训练模型,使用测试集进行验证
model.predict(x_test)
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
如何学习AI大模型? 零基础入门到精通,收藏这一篇就够了
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









