







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
注意: 除了SQL标准之外,大部分SQL数据库程序都拥有自己的专属扩展。
2.SQL语法
介绍:
- 一个数据库通常包含一个或多个表,每个表都有表名(标识符)来区分,每个表通常包含数据的记录(行)。
注意:
- SQL对大小写不敏感,SELECT和select是一样。但是SQL引擎通常会把语句都转换为大写字符来执行。
- 某些数据库系统要求每条SQL语句的末端使用分号,有些不要求。
3.SQL select 语句
作用:
- select 语句用于从数据库中选取数据,结果被存储在一个结果表中。
语法:
select column_name,column_name
from table_name;
或者
select * from table_name;
实例:
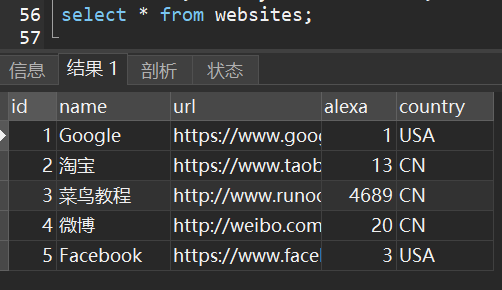
1)从websites 表中提取name和country字段。
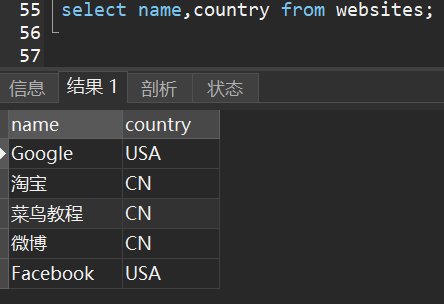
2)从websites 表中提取全部字段。
4.SQL select distinct 语句
作用:
- 在表中,一个列可能包含多个重复值,有时我们希望列出不同的值,dintinct关键字返回唯一不同的值。
语法:
select distinct column_name,column_name
from table_name;
实例:
1)选取websites表中的country字段。
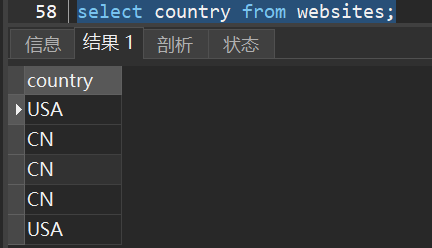
2)选取websites表中的不含重复值的country字段。

5.SQL where 子句
作用:
- where 子句用于提取那些满足指定条件的记录。
语法:
SELECT column_name,column_name
FROM table_name
WHERE column_name operator value;
注意:
SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值字段,请不要使用引号。
可以的where子句中使用的运算符以下9种:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。**注释:**在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
演示:
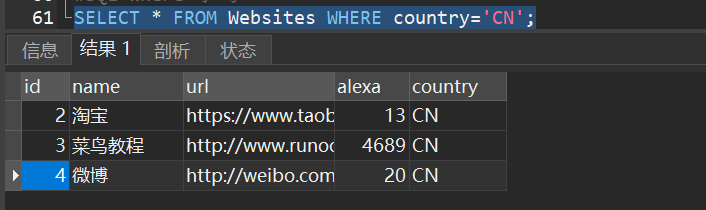
1)从 “Websites” 表中选取国家为 “CN” 的所有网站:
6.SQL and&or 运算符
作用:
- and和or运算符用于基于一个以上的条件对记录进行过滤。
- 如果第一个条件和第二个条件都成立,则 and运算符显示一条记录。
- 如果第一个条件和第二个条件中只要有一个成立,则 or运算符显示一条记录。
演示:
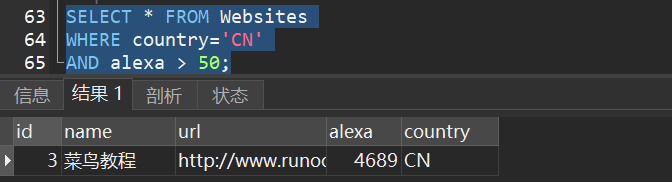
1)从 “Websites” 表中选取国家为 “CN” 且alexa排名大于 “50” 的所有网站:
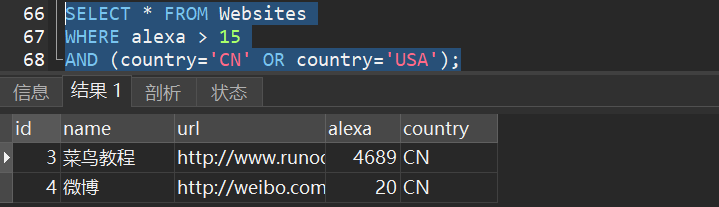
2)从 “Websites” 表中选取 alexa 排名大于 “15” 且国家为 “CN” 或 “USA” 的所有网站:
7.SQL order by 关键字
作用:
- order by 主要对结果表进行排序。
- oder by关键字用于对结果集按照一个列或者多个列进行排序。
- oder by关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 dese 关键字。
语法:
SELECT column_name,column_name
FROM table_name
ORDER BY column_name,column_name ASC|DESC;
演示:
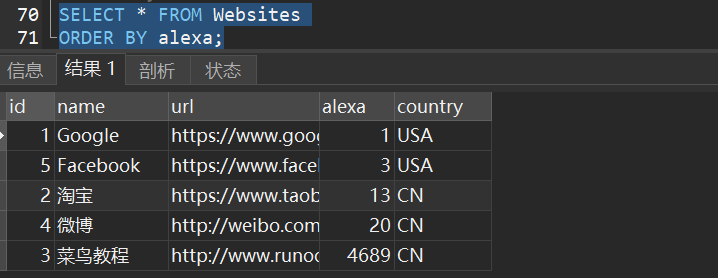
1)从 “Websites” 表中选取所有网站,并按照 “alexa” 列排序:
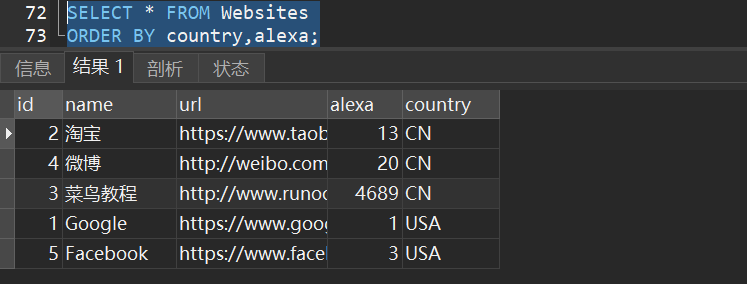
2)从 “Websites” 表中选取所有网站,并按照 “country” 和 “alexa” 列排序:
8.SQL insert into 语句
作用:
- insert into 语句用于向表中插入新记录。
语法:
1)第一种形式需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
2)第二种形式要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
演示:
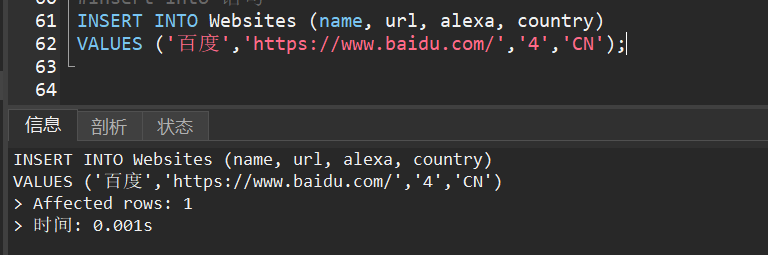
1)向 “Websites” 表中插入一个新行。
9.SQL update 语句
作用:
- update语句用于更新表中的记录。
语法:
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
注意:
where子句规定哪条记录或者哪些记录需要更新。如果您省略了 where子句,所有的记录都将被更新!
演示:
1)我们要把 Websites表中的 "菜鸟教程"的alexa 排名更新为 5000,country 改为 USA。
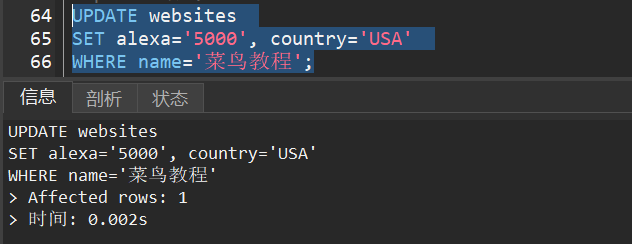
9.SQL delete 语句
作用:
- delete删除表中的记录
语法:
DELETE FROM table_name
WHERE some_column=some_value;
注意:
where子句规定哪条记录或者哪些记录需要删除。如果您省略了 where 子句,所有的记录都将被删除!
演示:
1)从 “Websites” 表中删除网站名为 “Facebook” 且国家为 USA 的网站。
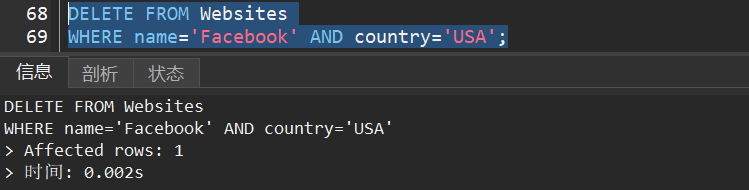
10.SQL group by 语句
作用:
- GROUP BY 语句可结合一些聚合函数来使用
- GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
演示:
1)统计 access_log 各个 site_id 的访问量:
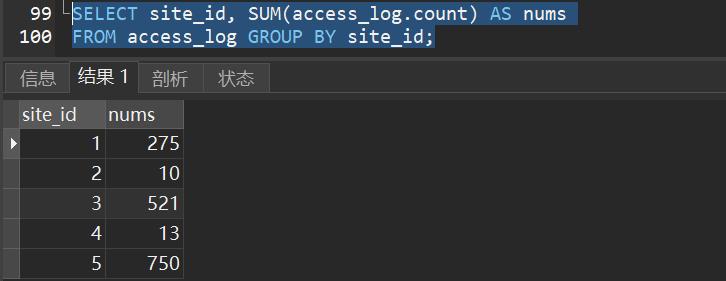
2)下面的 SQL 语句统计有记录的网站的记录数量:
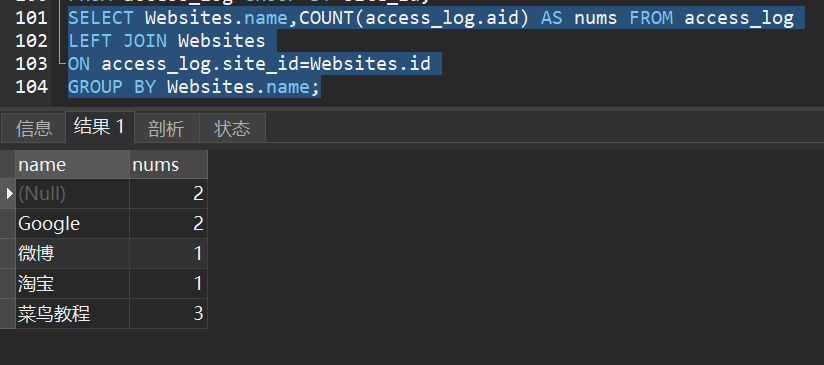
11.SQL having子句
作用:
- 在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
- HAVING 子句可以让我们筛选分组后的各组数据。
语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
演示:
1)查找总访问量大于 200 的网站。
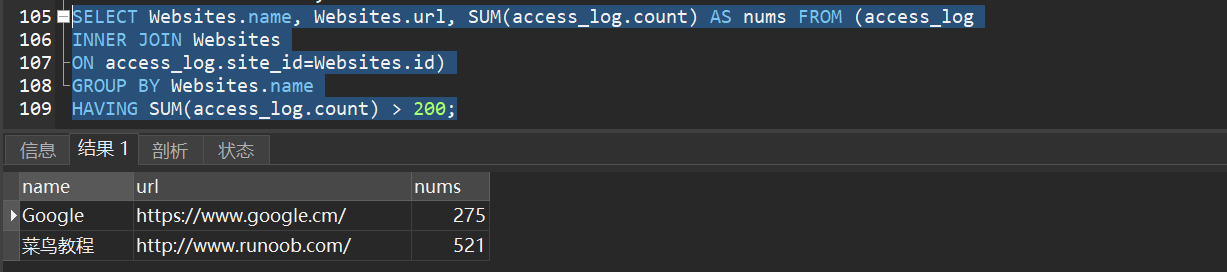
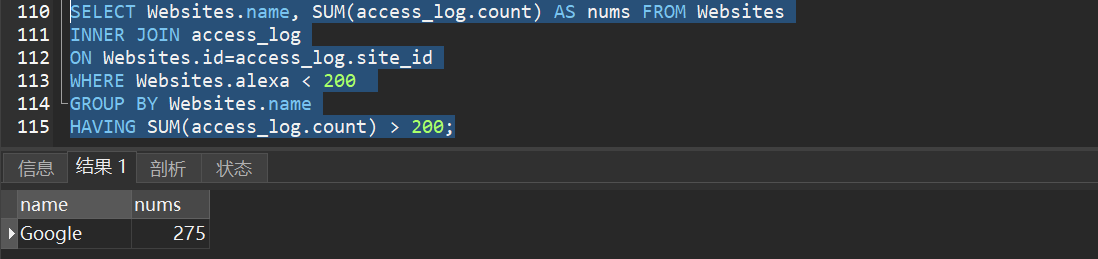
2)查找总访问量大于 200 的网站,并且 alexa 排名小于 200。
12.SQL exists 运算符
作用:
- EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
语法:
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);
演示:
1)查找总访问量(count 字段)大于 200 的网站是否存在。

第二章 SQL高级

1.SQL select top ,limit ,rownum 子句
作用:
- select top子句用于规定要返回的记录的数目。
- select top 子句对于拥有数千条记录的大型表来说,是非常有用的。
**注意:并非所有的数据库系统都支持 select top语句。 MySQL 支持 limit语句来选取指定的条数数据, Oracle 可以使用 rownum来选取。
语法:
SQL Server / MS Access 语法
SELECT TOP number|percent column_name(s)
FROM table_name;
Mysql语法
SELECT column_name(s)
FROM table_name
LIMIT number;
Oracle 语法
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;
演示:
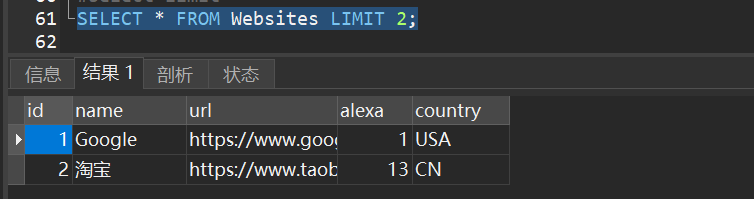
1)从 “Websites” 表中选取头两条记录:
2.SQL like 操作符
作用:
- like操作符用于在 where子句中搜索列中的指定模式。
语法:
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
演示:
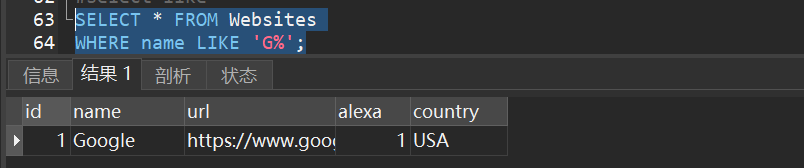
1)从websites表中选取 name 以字母 “G” 开始的所有客户
2)从websites表中选取 name 包含模式 “oo” 的所有客户

3)从websites表中选取 name 不包含模式 “oo” 的所有客户
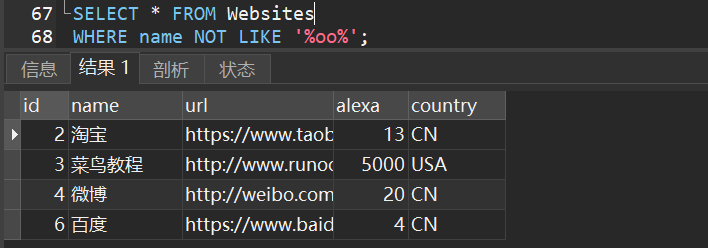
3.SQL 通配符
作用:
- 通配符可用于替代字符串中的任何其他字符。
- 在 sql中,通配符与 sql like 操作符一起使用。
- sql 通配符用于搜索表中的数据。
- 在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist] 或 [!charlist] | 不在字符列中的任何单一字符 |
演示:
1) websites表中选取 url 以字母 “https” 开始的所有网站:

4.SQL in 操作符
作用:
- in 操作符允许您在 WHERE 子句中规定多个值。
语法:
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1,value2,...);
演示:
1)websites表中选取 name 为 “Google” 或 “菜鸟教程” 的所有网站:
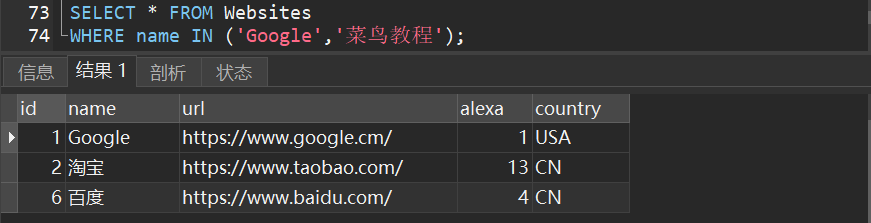
5.SQL between 操作符
作用:
- between操作符用于选取介于两个值之间的数据范围内的值。
- 这些值可以是数值、文本或者日期。
语法:
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
演示:
1)websites表中选取 alexa 介于 1 和 20 之间的所有网站:
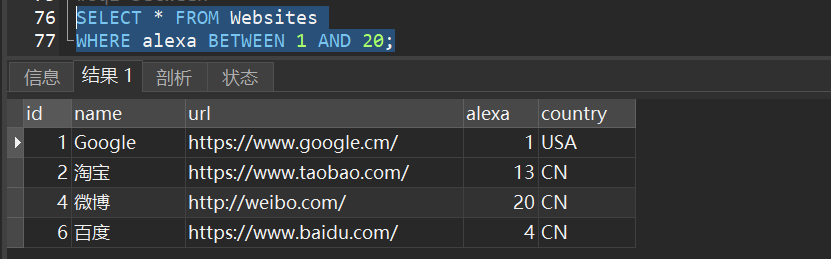
2)websites表中选取 alexa 不在介于 1 和 20 之间的所有网站:

6.SQL 别名(as)
作用:
- as 可以为表名称或列名称指定别名。
- 基本上,创建别名是为了让列名称的可读性更强。
语法:
--列的sql别名语法
SELECT column_name AS alias_name
FROM table_name;
--表的sql别名语法
SELECT column_name(s)
FROM table_name AS alias_name;
演示:
1)使用 “Websites” 和 “access_log” 表,并分别为它们指定表别名 “w” 和 “a”,选取 “淘宝” 的所有访问记录:
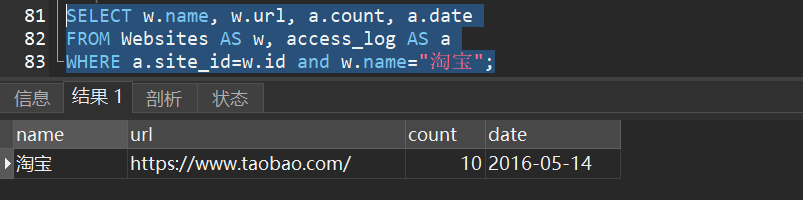
7.SQL join 链接
作用:
- SQL join 用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
- 下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
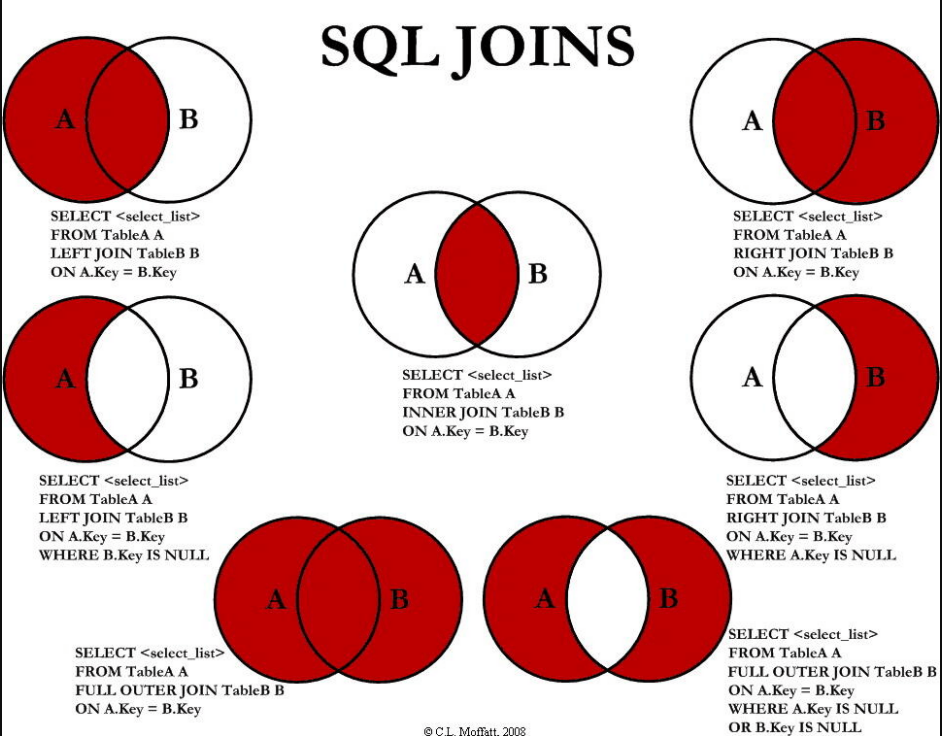
不同的sql join:
- INNER JOIN:如果表中有至少一个匹配,则返回行。
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行。
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行。
- FULL JOIN:只要其中一个表中存在匹配,则返回行。
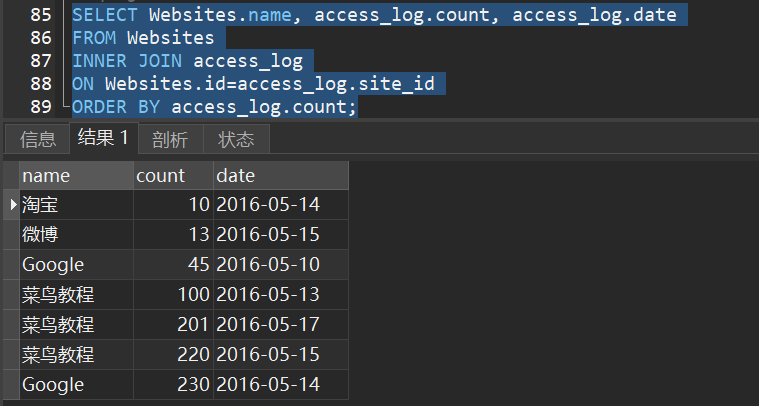
1)inner join
语法:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
--或
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;
演示:
1)返回所有网站的访问记录:
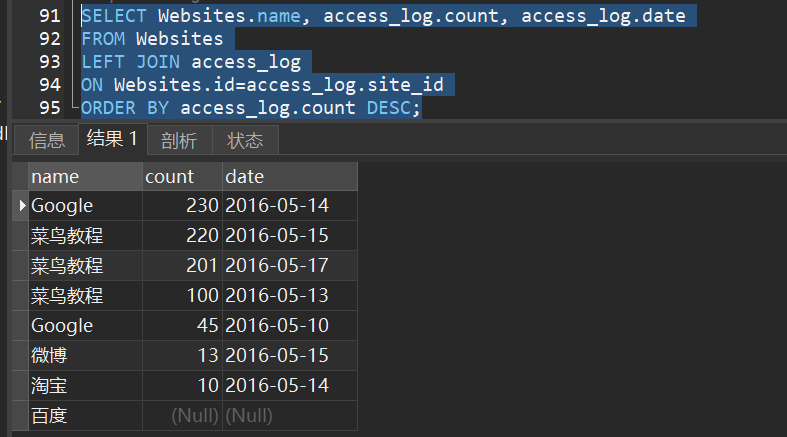
2)sql left join
语法:
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
--或
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
演示:
1)返回所有网站及他们的访问量(如果有的话):
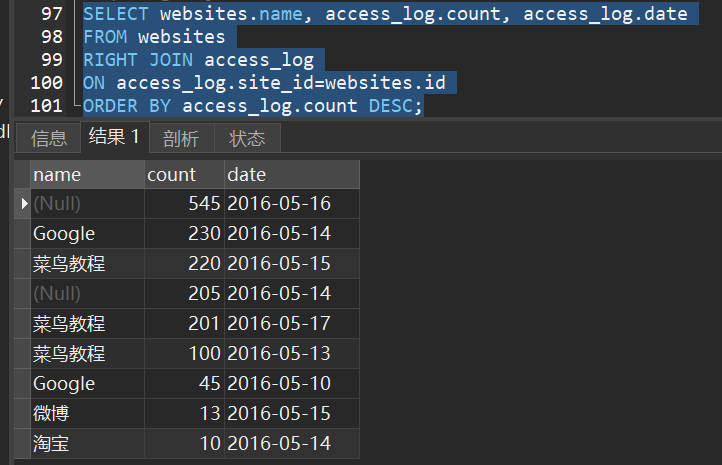
3)sql right join
语法:
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
--或
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
演示:
1)返回网站的访问记录:
4)sql full outer join
语法:
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
8.SQL union 操作符
作用:
- union 操作符合并两个或多个 SELECT 语句的结果。
- union内部的每个 select语句必须拥有相同数量的列。
- 列也必须拥有相似的数据类型。
- 同时,每个 select 语句中的列的顺序必须相同。
- union结果集中的列名总是等于 union中第一个select 语句中的列名。
语法:
---sql union ---选取不同的值
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
---sql union all---允许重复的值
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
演示:
1)从 “Websites” 和 “apps” 表中选取所有不同的country(只有不同的值)
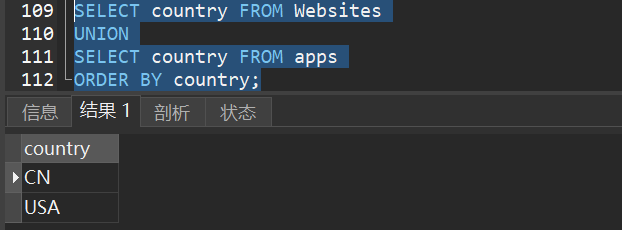
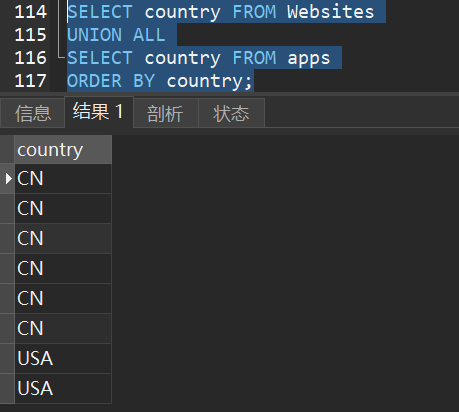
2)从 “Websites” 和 “apps” 表中选取所有的country(也有重复的值)
9.SQL select into 语句
作用:
- select into语句从一个表复制数据,然后把数据插入到另一个新表中。
语法:
---复制所有的列插入到新表中:
SELECT *
INTO newtable [IN externaldb]
FROM table1;
---只复制希望的列插入到新表中:
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;
实例:
--创建 Websites 的备份复件:
SELECT *
INTO WebsitesBackup2016
FROM Websites;
--只复制一些列插入到新表中:
SELECT name, url
INTO WebsitesBackup2016
FROM Websites;
--只复制中国的网站插入到新表中:
SELECT *
INTO WebsitesBackup2016
FROM Websites
WHERE country='CN';
--复制多个表中的数据插入到新表中:
SELECT Websites.name, access_log.count, access_log.date
INTO WebsitesBackup2016
FROM Websites
LEFT JOIN access_log
ON Websites.id=access_log.site_id;
10.SQL insert into select
作用:
- insert into select 语句从一个表复制数据,然后把数据插入到一个已存在的表中。
语法:
--一个表中复制所有的列插入到另一个已存在的表中:
INSERT INTO table2
SELECT * FROM table1;
--我们可以只复制希望的列插入到另一个已存在的表中:
INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;
演示:
1)复制 “apps” 中的数据插入到 “Websites” 中:

11.SQL create database 语句
作用:
- create database 语句用于创建数据库。
语法:
CREATE DATABASE dbname;
实例:
CREATE DATABASE my_db;
12.SQL create table 语句
作用:
- create table语句用于创建数据库中的表。
- 表由行和列组成,每个表都必须有个表名。
语法:
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);
实例:
--创建一个名为 "Persons" 的表,包含五列:PersonID、LastName、FirstName、Address 和 City。
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
13.SQL 约束
作用:
- SQL 约束用于规定表中的数据规则。
- 如果存在违反约束的数据行为,行为会被约束终止。
- 约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
语法:
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
1)not null 约束
作用:
- NOT NULL 约束强制列不接受 NULL 值。
- NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
实例:
1)创建表时添加not null约束:
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255) NOT NULL,
Age int
);
2)已创建的表添加not null 约束
ALTER TABLE Persons
MODIFY Age int NOT NULL;
3)已创建的表中删除not null约束
ALTER TABLE Persons
MODIFY Age int NULL;
2)unique 约束
作用:
- UNIQUE 约束唯一标识数据库表中的每条记录。
- UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
- PRIMARY KEY 约束拥有自动定义的 UNIQUE 约束。
- 每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
实例:
1)创建表时添加unique约束:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
UNIQUE (P_Id)
)
2)已创建的表添加unique约束
ALTER TABLE Persons
ADD UNIQUE (P_Id)
3)已创建的表中删除unique约束
ALTER TABLE Persons
DROP INDEX uc_PersonID
3)primary key 约束
作用:
- PRIMARY KEY 约束唯一标识数据库表中的每条记录。
- 主键必须包含唯一的值。
- 主键列不能包含 NULL 值。
- 每个表都应该有一个主键,并且每个表只能有一个主键。
实例:
1)创建表时添加primary key 约束:
--mysql
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
P_Id int NOT NULL PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2)已创建的表添加primary key 约束
ALTER TABLE Persons
ADD PRIMARY KEY (P_Id)
3)已创建的表中删除primary key 约束
ALTER TABLE Persons
DROP PRIMARY KEY
4)foreign key 约束
作用:
- 一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
- FOREIGN KEY 约束用于预防破坏表之间连接的行为。
- FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
实例:
“Persons” 表:
| P_Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
“Orders” 表:
| O_Id | OrderNo | P_Id |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 2 |
| 4 | 24562 | 1 |
- “Orders” 表中的 “P_Id” 列指向 “Persons” 表中的 “P_Id” 列。
- “Persons” 表中的 “P_Id” 列是 “Persons” 表中的 PRIMARY KEY。
- “Orders” 表中的 “P_Id” 列是 “Orders” 表中的 FOREIGN KEY。
1)创建表时添加foreign key 约束:
--mysql
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Orders
(
O_Id int NOT NULL PRIMARY KEY,
OrderNo int NOT NULL,
P_Id int FOREIGN KEY REFERENCES Persons(P_Id)
)
2)已创建的表添加foreign key 约束
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)
3)已创建的表中删除foreign key 约束
ALTER TABLE Orders
DROP FOREIGN KEY fk_PerOrders
5)check 约束
作用:
- CHECK 约束用于限制列中的值的范围。
- 如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
- 如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。
实例:
1)创建表时添加check 约束:
--mysql
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (P_Id>0)
)
--SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2)已创建的表添加check 约束
ALTER TABLE Persons
ADD CHECK (P_Id>0)
3)已创建的表中删除check 约束
ALTER TABLE Persons
DROP CHECK chk_Person
6)default 约束
作用:
- DEFAULT 约束用于向列中插入默认值。
- 如果没有规定其他的值,那么会将默认值添加到所有的新记录。
实例:
1)创建表时添加default 约束:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes'
)
2)已创建的表添加default 约束
ALTER TABLE Persons
ALTER City SET DEFAULT 'SANDNES'
3)已创建的表中删除default 约束
ALTER TABLE Persons
ALTER City DROP DEFAULT
14.create index 语句
作用:
- CREATE INDEX 语句用于在表中创建索引。
- 在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
- 可以在表中创建索引,以便更加快速高效地查询数据。
- 用户无法看到索引,它们只能被用来加速搜索/查询。
语法:
--在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
--在表上创建一个唯一的索引。不允许使用重复的值
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
实例:
1)在 “Persons” 表的 “LastName” 列上创建一个名为 “PIndex” 的索引:
CREATE INDEX PIndex
ON Persons (LastName)
2)如果您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PIndex
ON Persons (LastName, FirstName)
15.SQL drop
作用:
- 通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
语法:
-----DROP INDEX 语句用于删除表中的索引。
--MS Access
DROP INDEX index_name ON table_name
--DB2/Oracle
DROP INDEX index_name
-- MS SQL Server
DROP INDEX table_name.index_name
--MySQL
ALTER TABLE table_name DROP INDEX index_name
----DROP TABLE 语句用于删除表。
DROP TABLE table_name
----DROP DATABASE 语句用于删除数据库。
--DROP DATABASE database_name
----只删除表中的数据,不删除表本身
TRUNCATE TABLE table_name
16.SQL alter table 语句
作用:
- ALTER TABLE 语句用于在已有的表中添加、删除或修改列
语法:
--在表中添加列
ALTER TABLE table_name
**先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里**
**深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**





**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
实例:
1)在 “Persons” 表的 “LastName” 列上创建一个名为 “PIndex” 的索引:
CREATE INDEX PIndex
ON Persons (LastName)
2)如果您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PIndex
ON Persons (LastName, FirstName)
15.SQL drop
作用:
- 通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
语法:
-----DROP INDEX 语句用于删除表中的索引。
--MS Access
DROP INDEX index_name ON table_name
--DB2/Oracle
DROP INDEX index_name
-- MS SQL Server
DROP INDEX table_name.index_name
--MySQL
ALTER TABLE table_name DROP INDEX index_name
----DROP TABLE 语句用于删除表。
DROP TABLE table_name
----DROP DATABASE 语句用于删除数据库。
--DROP DATABASE database_name
----只删除表中的数据,不删除表本身
TRUNCATE TABLE table_name
16.SQL alter table 语句
作用:
- ALTER TABLE 语句用于在已有的表中添加、删除或修改列
语法:
--在表中添加列
ALTER TABLE table_name
**先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里**
**深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**
[外链图片转存中...(img-fR0rkUOM-1715250337164)]
[外链图片转存中...(img-ezWqYKHi-1715250337164)]
[外链图片转存中...(img-sDxU0iTP-1715250337164)]
[外链图片转存中...(img-0hXUEITp-1715250337165)]
[外链图片转存中...(img-MxJwXb0y-1715250337165)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**















 7057
7057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









