








🌟 嗨,我是Lethehong!🌟
🌍 立志在坚不欲说,成功在久不在速🌍
🚀 欢迎关注:👍点赞⬆️留言收藏🚀
🍀欢迎使用:小智初学计算机网页IT深度知识智能体
🍀欢迎使用:深探助手deepGuide网页deepseek智能体
目录
前言
1、如何使用蓝耘的容器实例
第一步:点击蓝耘元生代智算云平台进行注册
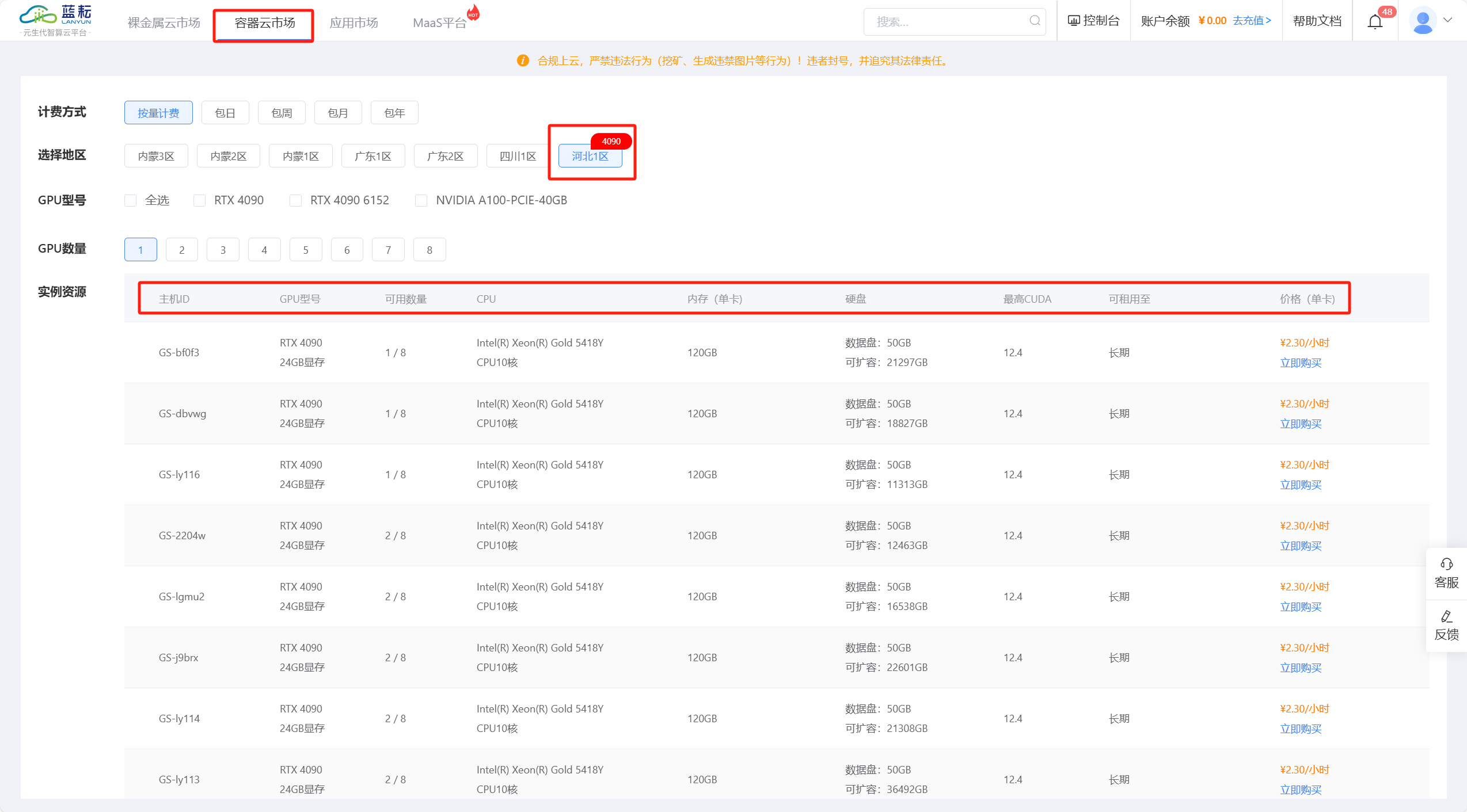
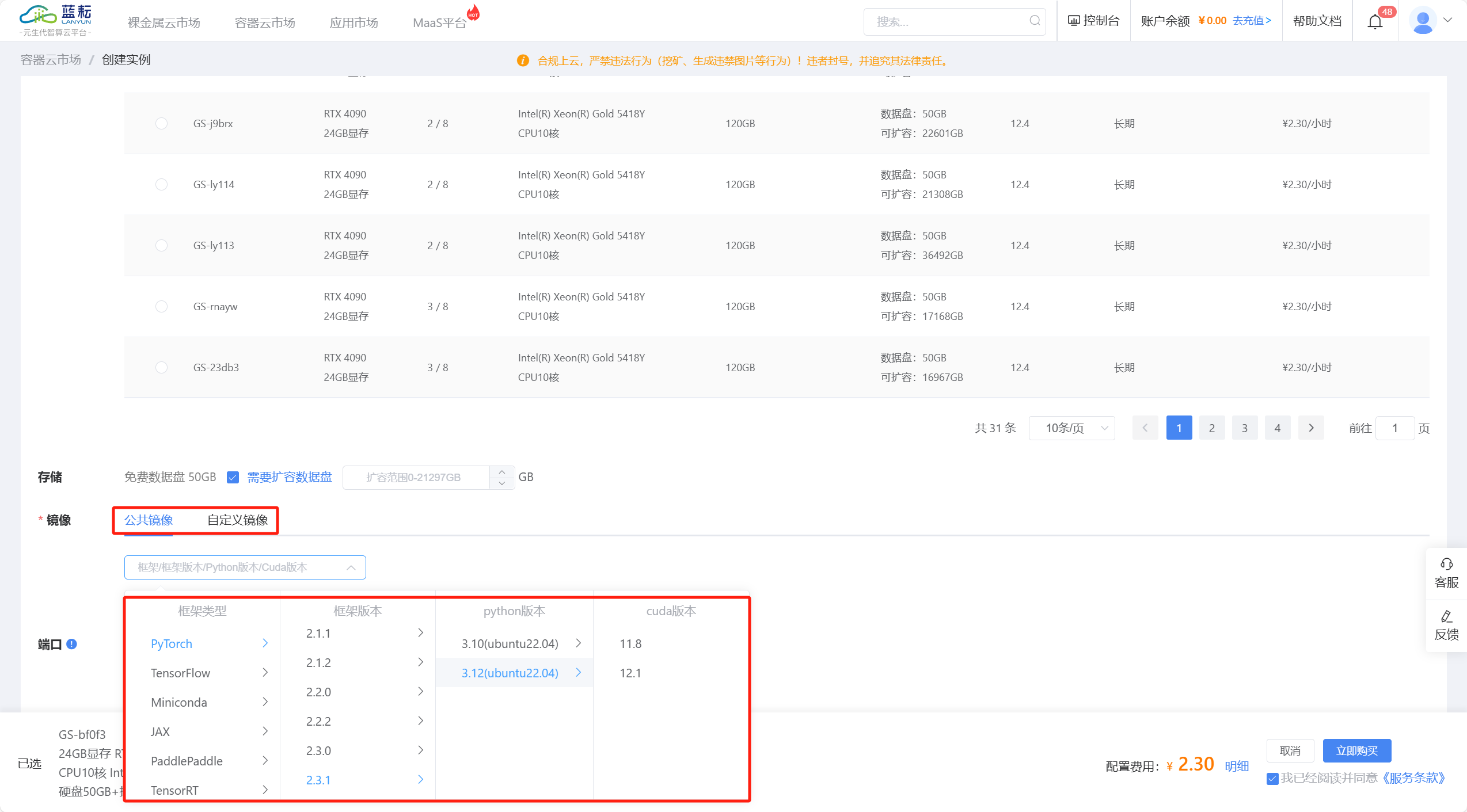
第二步:注册之后,我们点击“容器云市场”,这里可以看到有很多不同的GPU型号,本次实验采用“河北一区的GPU:RTX 4090 24GB 显存,CPU:Intel(R) Xeon(R) Gold 5418Y CPU10核”的实例资源;选择之后选择自己需要的镜像框架类型以及里面的版本号等,输入端口号即可启动,PyTorch 是一个强大的深度学习框架,以其动态计算图和灵活性著称,看过我文章的宝子,都知道我经常写python,今天就在给大家写一份。
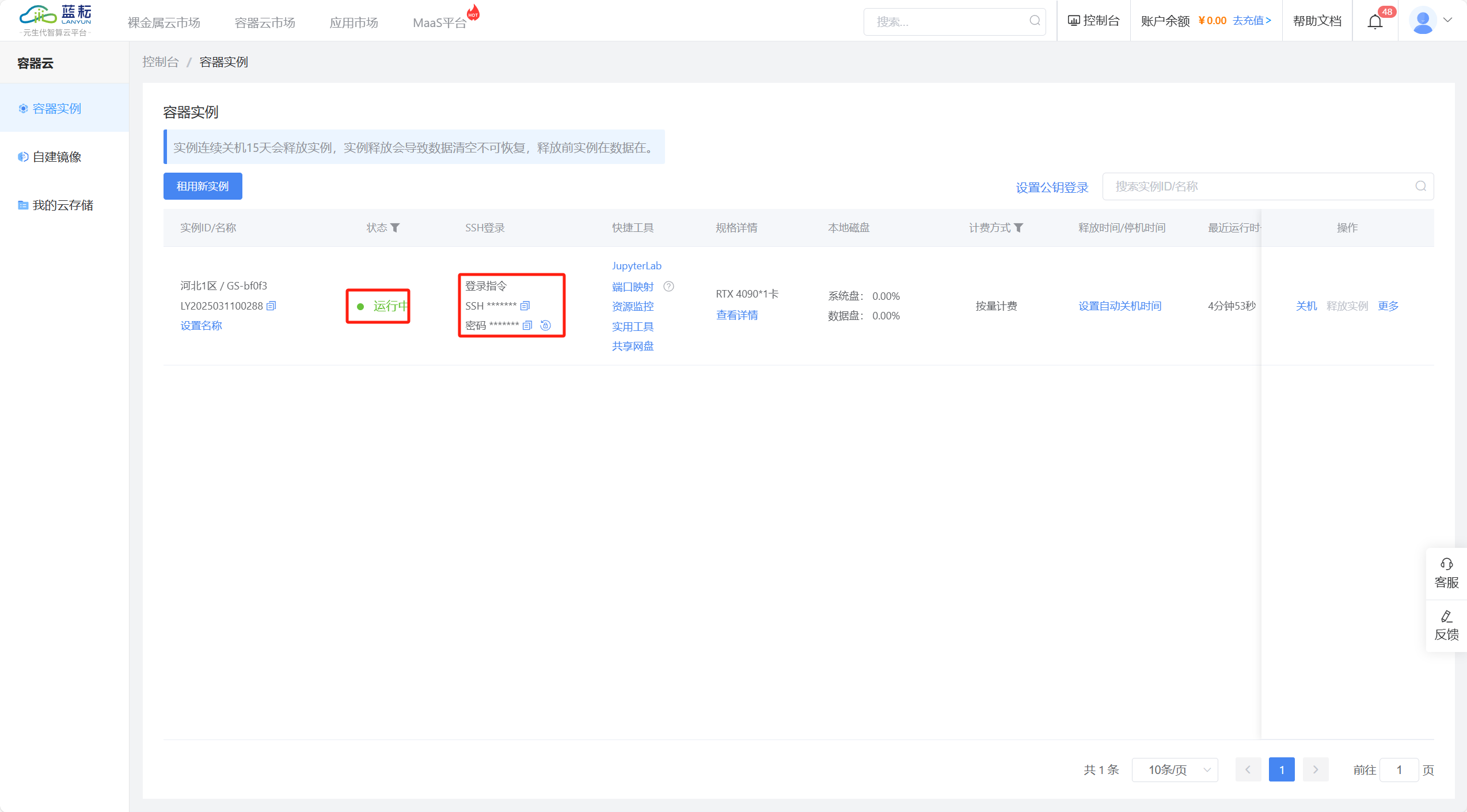
第三步:购买之后会跳转到下图界面,等待状态变成运行中即可使用。然后我们打开电脑的cmd界面,复制第一行的登录指令,然后在复制密码进行登录即可。就让我带着大家体验一遍吧!
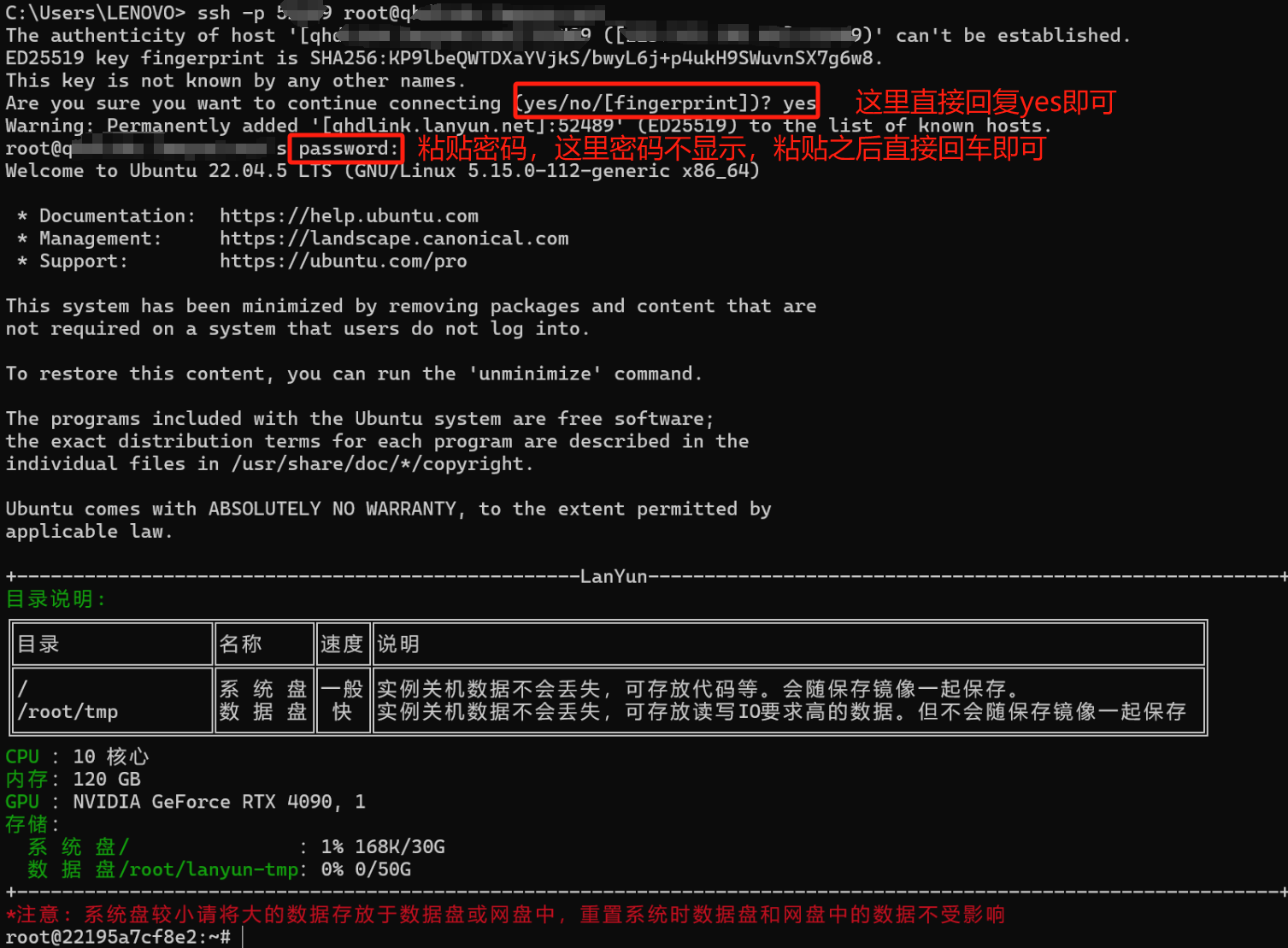
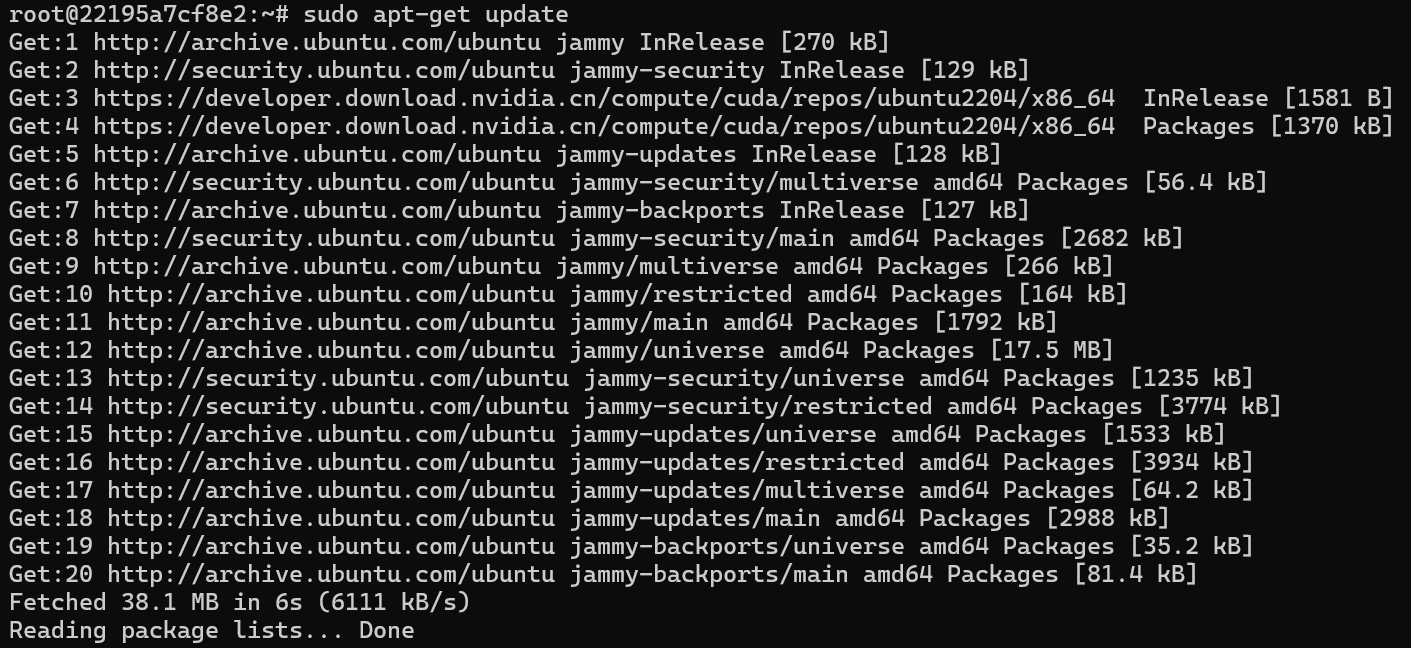
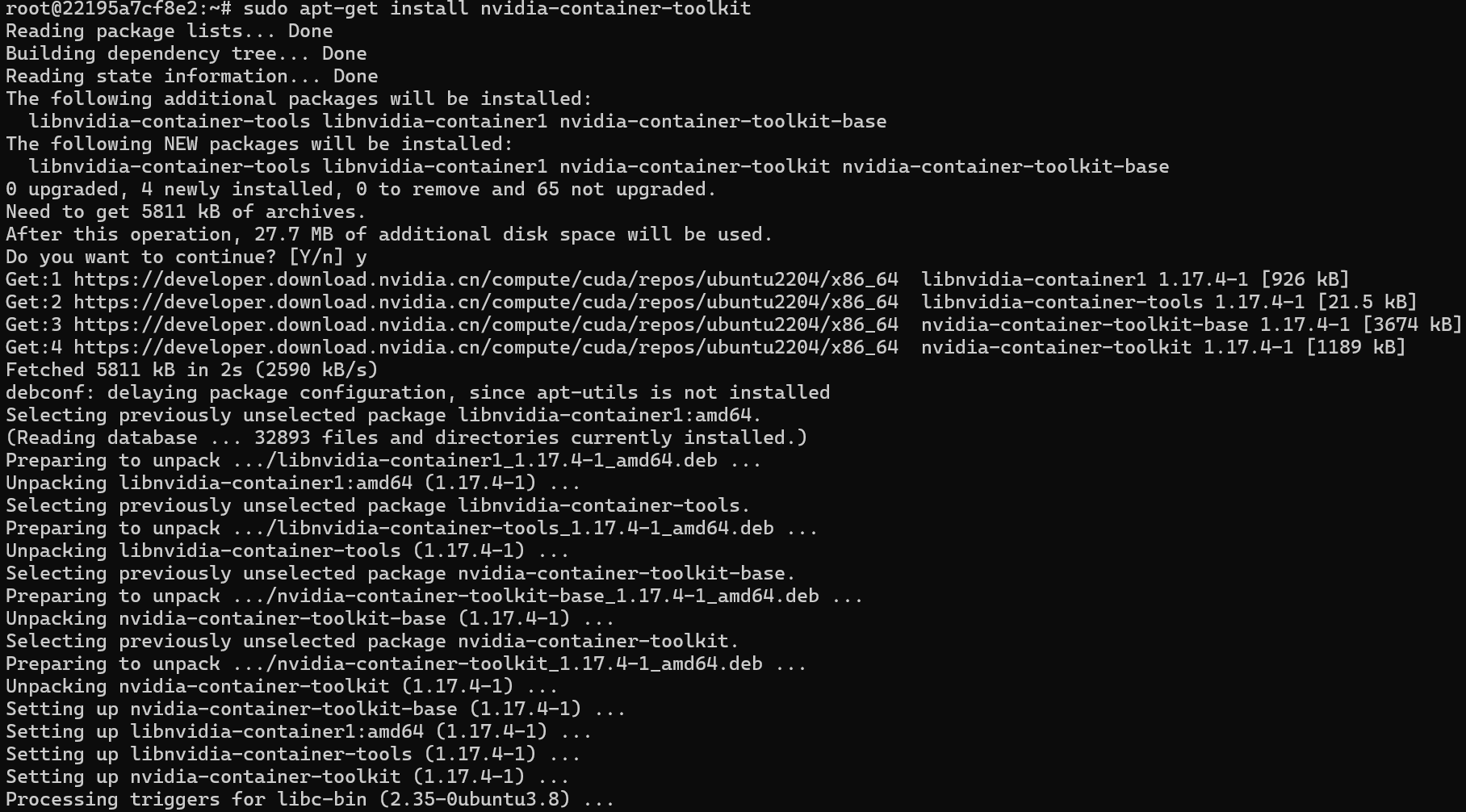
第四步:到这里我们就可以去进行使用了,这里直接安装使用NVIDIA进行启动了,将就看看吧
import torch
# 创建张量
x = torch.tensor([1, 2, 3]) # 从列表创建
y = torch.rand(3, 3) # 随机 3x3 矩阵
z = torch.zeros(2, 2) # 全零矩阵
# 张量运算
a = x + 2 # 逐元素加法
b = torch.matmul(y, z) # 矩阵乘法
# 移动到 GPU(如果可用)
device = "cuda" if torch.cuda.is_available() else "cpu"
y_gpu = y.to(device)
#requires_grad=True 跟踪张量操作,自动计算梯度
x = torch.tensor(2.0, requires_grad=True)
y = x**2 + 3*x + 1
y.backward() # 计算梯度
print(x.grad) # 输出 dy/dx = 2x + 3 → 7.0
#nn.Module 定义网络结构
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128) # 输入层到隐藏层
self.fc2 = nn.Linear(128, 10) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = Net().to(device) # 将模型移动到 GPU
#Dataset 和 DataLoader 管理数据
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class CustomDataset(Dataset):
def __init__(self, data, transform=None):
self.data = data
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
if self.transform:
sample = self.transform(sample)
return sample
# 示例:MNIST 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = MNIST(root='data/', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
#定义损失函数和优化器,编写训练循环
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for batch in dataloader:
inputs, labels = batch
inputs = inputs.to(device) # 数据移至 GPU
labels = labels.to(device)
# 前向传播
outputs = model(inputs.view(-1, 784)) # 展平输入
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
#保存模型参数
torch.save(model.state_dict(), "model.pth")
#加载模型参数
model.load_state_dict(torch.load("model.pth"))
model.eval() # 切换到评估模式(关闭 dropout 等)
2、以下是常用的 Docker 客户端命令:
| 命令 | 功能 | 示例 |
|---|---|---|
docker run | 启动一个新的容器并运行命令 | docker run -d ubuntu |
docker ps | 列出当前正在运行的容器 | docker ps |
docker ps -a | 列出所有容器(包括已停止的容器) | docker ps -a |
docker build | 使用 Dockerfile 构建镜像 | docker build -t my-image . |
docker images | 列出本地存储的所有镜像 | docker images |
docker pull | 从 Docker 仓库拉取镜像 | docker pull ubuntu |
docker push | 将镜像推送到 Docker 仓库 | docker push my-image |
docker exec | 在运行的容器中执行命令 | docker exec -it container_name bash |
docker stop | 停止一个或多个容器 | docker stop container_name |
docker start | 启动已停止的容器 | docker start container_name |
docker restart | 重启一个容器 | docker restart container_name |
docker rm | 删除一个或多个容器 | docker rm container_name |
docker rmi | 删除一个或多个镜像 | docker rmi my-image |
docker logs | 查看容器的日志 | docker logs container_name |
docker inspect | 获取容器或镜像的详细信息 | docker inspect container_name |
docker exec -it | 进入容器的交互式终端 | docker exec -it container_name /bin/bash |
docker network ls | 列出所有 Docker 网络 | docker network ls |
docker volume ls | 列出所有 Docker 卷 | docker volume ls |
docker-compose up | 启动多容器应用(从 docker-compose.yml 文件) | docker-compose up |
docker-compose down | 停止并删除由 docker-compose 启动的容器、网络等 | docker-compose down |
docker info | 显示 Docker 系统的详细信息 | docker info |
docker version | 显示 Docker 客户端和守护进程的版本信息 | docker version |
docker stats | 显示容器的实时资源使用情况 | docker stats |
docker login | 登录 Docker 仓库 | docker login |
docker logout | 登出 Docker 仓库 | docker logout |
常用选项说明:
-d:后台运行容器,例如docker run -d ubuntu。-it:以交互式终端运行容器,例如docker exec -it container_name bash。-t:为镜像指定标签,例如docker build -t my-image .。
第一部分:蓝耘容器概述
1.1 核心特性
- 轻量化内核:基于RISC-V指令集优化,单容器启动时间<50ms。
- 异构计算支持:无缝调用GPU/FPGA/NPU资源,适用于AI推理、边缘计算。
- 混合云调度:支持跨公有云、私有云及边缘节点的统一编排。
1.2 架构设计
蓝耘采用「控制面-数据面」分离架构:
- 控制面(Control Plane):负责容器调度、服务发现(基于ETCD集群)。
- 数据面(Data Plane):通过轻量级Hypervisor实现硬件级隔离。
第二部分:环境部署
2.1 多节点集群搭建
2.1.1 硬件要求
| 角色 | CPU | 内存 | 存储 | 网络 |
|---|---|---|---|---|
| 控制节点 | 4核+ | 8GB+ | 50GB SSD | 1Gbps双网卡 |
| 工作节点 | 8核+ | 16GB+ | 100GB NVMe | 10Gbps RDMA |
2.1.2 使用Ansible自动化部署
# inventory.yml
[control]
ctrl01 ansible_host=192.168.1.10
[worker]
worker01 ansible_host=192.168.1.11
worker02 ansible_host=192.168.1.12
[all:vars]
ansible_user=root
lantern_version=2.4.1
# 执行部署
ansible-playbook -i inventory.yml lantern-cluster-deploy.yml
2.2 GPU加速环境配置
# 安装NVIDIA容器工具链
lcctl gpu install-driver --type=nvidia --version=525.60.13
# 验证GPU透传
lcctl run --gpus all -it lanterncloud/cuda-test nvidia-smi
第三部分:容器全生命周期管理
3.1 镜像构建优化
3.1.1 多阶段构建模板
# 构建阶段
FROM lanterncloud/builder:1.18 AS build
COPY . /app
RUN make -j8
# 运行阶段
FROM lanterncloud/runtime:2.4
COPY --from=build /app/bin /opt/service
CMD ["/opt/service/start.sh"]
3.1.2 镜像安全扫描
lcctl image scan myapp:latest --output=json > scan-report.json
3.2 高级编排策略
3.2.1 基于标签的调度
# deployment.yml
apiVersion: apps.lantern/v1
kind: Deployment
metadata:
name: ai-inference
spec:
replicas: 8
selector:
matchLabels:
app: ai
template:
metadata:
labels:
app: ai
priority: high
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu.type
operator: In
values: [a100, v100]
3.2.2 弹性伸缩配置
# 创建HPA策略
lcctl autoscale create --target=deployment/ai-inference \
--min=4 --max=16 --cpu-percent=70
第四部分:网络与存储实战
4.1 高性能网络方案
4.1.1 SR-IOV网络加速
# 启用SR-IOV网卡
lcctl network create sriov-net \
--driver=sriov \
--physical-interface=enp6s0f0 \
--vlan=100
# 部署应用
lcctl run -d --name high-perf-app \
--network sriov-net \
--network-param sriov_vf=2 \
myapp:latest
4.1.2 Service Mesh集成
# sidecar注入配置
apiVersion: networking.lantern/v1alpha3
kind: Sidecar
metadata:
name: default-sidecar
spec:
workloadSelector:
labels:
app: critical-service
ingress:
- port: 9080
protocol: HTTP
hosts:
- "*"
4.2 持久化存储方案
4.2.1 CSI驱动对接Ceph
# storage-class.yml
apiVersion: storage.lantern/v1
kind: StorageClass
metadata:
name: ceph-rbd
provisioner: lantern-csi-ceph
parameters:
clusterID: ceph-cluster
pool: lantern_pool
imageFormat: "2"
imageFeatures: layering
4.2.2 分布式缓存加速
# 创建Memcache集群
lcctl cache create --type=memcached --nodes=3 --memory=16G
第五部分:监控与安全
5.1 全链路监控
5.1.1 Prometheus集成
# prometheus-config.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'lantern-containers'
lantern_sd_configs:
- endpoint: https://control-plane:9090
basic_auth:
username: admin
password: $PROM_PWD
5.1.2 自定义指标采集
# metrics-exporter.py
from lantern.metrics import Collector
class CustomCollector(Collector):
def collect(self):
yield self.Gauge(
name='app_requests_pending',
value=get_pending_requests(),
labels={'service': 'payment-gateway'}
)
5.2 零信任安全模型
5.2.1 策略即代码
# security-policy.rego
package lantern.security
default allow = false
allow {
input.request.kind == "ContainerCreate"
input.request.user == "ci-system"
input.request.image.registry == "secure-registry.lantern.cloud"
}
5.2.2 运行时防护
# 启用行为监控
lcctl security profile create app-protect \
--allowed-syscalls=read,write,open \
--max-file-size=10MB
第六部分:进阶场景
6.1 边缘AI推理
# edge-deployment.yml
apiVersion: edge.lantern/v1
kind: EdgeApp
metadata:
name: face-recognition
spec:
selector:
edgeNodes:
labelSelector:
region: ap-southeast
template:
containers:
- name: inference
image: lanterncloud/face-rec:v2.1
resources:
npu: 2
telemetry:
reportInterval: 30s
metrics: [cpu_temp, gpu_util]
6.2 混合云灾备
# 创建跨云复制策略
lcctl disaster-recovery create myapp-dr \
--source=aws:us-east-1 \
--target=alibaba:cn-hangzhou \
--schedule="0 3 * * *" \
--retention=7
第七部分:性能调优手册
7.1 容器启动优化
| 参数 | 推荐值 | 作用 |
|---|---|---|
| kernel.shmall | 4294967296 | 共享内存页总数 |
| vm.swappiness | 10 | 减少交换分区使用 |
| fs.file-max | 2097152 | 最大文件描述符数 |
# 应用优化参数
lcctl node tune --sysctl \
kernel.shmall=4294967296,\
vm.swappiness=10,\
fs.file-max=2097152
7.2 网络性能基准测试
# 启动iPerf服务端
lcctl run -d --name iperf-server -p 5201:5201 lanterncloud/iperf3 -s
# 运行客户端测试
lcctl exec iperf-server iperf3 -c 10.0.0.12 -t 60 -P 8
第八部分:故障排查大全
8.1 常见问题处理
8.1.1 容器启动失败
# 查看事件日志
lcctl events --object=pod/myapp --since=5m
# 检查内核日志
lcctl node ssh worker01 journalctl -k -b | grep lantern
8.1.2 网络不通
# 流量抓包分析
lcctl debug capture -p myapp -o capture.pcap
# 检查网络策略
lcctl network policy verify --src=frontend --dst=database
第九部分:总结
1、架构特性
1.1 轻量化内核
- 基于RISC-V指令集优化,容器启动时间<50ms
- Hypervisor级隔离,单节点支持1000+容器实例
1.2 异构计算支持
- 集成GPU/NPU/FPGA驱动栈,支持CUDA/OpenCL标准
- 通过
--gpus all参数实现硬件资源透传
1.3 混合云调度
- 控制面基于ETCD实现跨云元数据同步
- 支持AWS/Aliyun等公有云与边缘节点统一编排
2、核心操作体系
| 模块 | 关键技术 | 工具/命令 |
|---|---|---|
| 集群部署 | Ansible自动化安装、RDMA网络配置 | lcctl cluster init |
| 镜像管理 | 多阶段构建、CVE漏洞扫描 | lcctl image scan --output=json |
| 网络加速 | SR-IOV直通、Service Mesh流量管控 | lcctl network create --driver=sriov |
| 存储方案 | CSI驱动对接Ceph/RBD | lcctl storage-class create |
| 安全防护 | Rego策略引擎、运行时行为监控 | lcctl security profile create |
3、典型场景实现
3.1 AI推理优化
- 节点标签调度:定向部署到含A100/V100 GPU的工作节点
- 弹性伸缩:基于QPS指标自动扩展推理服务副本
3.2 边缘计算
- 边缘节点限定部署:通过
region: ap-southeast标签选择地理位置 - 低带宽适应:内置差分OTA更新机制
3.3 混合云灾备
- 跨云镜像同步:每日凌晨3点AWS到阿里云数据复制
- 故障切换:基于BGP Anycast实现IP层无缝迁移
4、性能调优参数
| 指标 | 推荐值 | 调节命令 |
|---|---|---|
| 容器启动并发数 | 50/节点 | lcctl daemon --max-concurrent=50 |
| 内存分配策略 | 静态预留+动态回收 | --memory-reservation=4G |
| 网络包处理 | XDP加速模式 | --net-accel=xdp |
5、故障排查矩阵
| 现象 | 诊断命令 | 解决方案 |
|---|---|---|
| 容器启动卡顿 | lcctl debug checkpoint <container> | 检查/proc/sys/fs/file-nr值 |
| GPU设备未识别 | lcctl gpu validate --driver-version | 更新NVIDIA vGPU许可证 |
| 跨节点网络延迟 | lcctl netperf --target 10.0.2.15 | 启用RDMA RoCEv2协议栈 |
6、扩展能力
- 生态集成
支持Prometheus/Grafana监控数据对接,兼容Istio 1.18+服务网格 - 定制开发
提供LLVM-based插件框架,支持自定义调度算法注入





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











