






 Pod是Kubernetes中最基本的资源单元,用于运行一个或多个紧密耦合的容器。Pod内的容器共享网络和存储空间,通过标签进行组织和选择。Pod不能单独扩展,只能通过控制器如ReplicaSet或Deployment来管理。命名空间提供了一种资源隔离的方式,允许多个用户或项目共享集群。标签选择器用于选择和操作具有特定标签的Pod,而删除Pod时,可以按名称、标签选择器或整个命名空间进行操作。
Pod是Kubernetes中最基本的资源单元,用于运行一个或多个紧密耦合的容器。Pod内的容器共享网络和存储空间,通过标签进行组织和选择。Pod不能单独扩展,只能通过控制器如ReplicaSet或Deployment来管理。命名空间提供了一种资源隔离的方式,允许多个用户或项目共享集群。标签选择器用于选择和操作具有特定标签的Pod,而删除Pod时,可以按名称、标签选择器或整个命名空间进行操作。
Pod介绍
概念:Pod是kubernetes中最小的资源管理组件,Pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。kubernetes中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行的rcc和Deployment等控制器对象。
当一个 pod 包含多个容器时,这些容器总是运行于同一个工作节点上——一个 pod 绝不会跨越多个工作节点;一个Pod的所有容器都运行在同一个节点上。
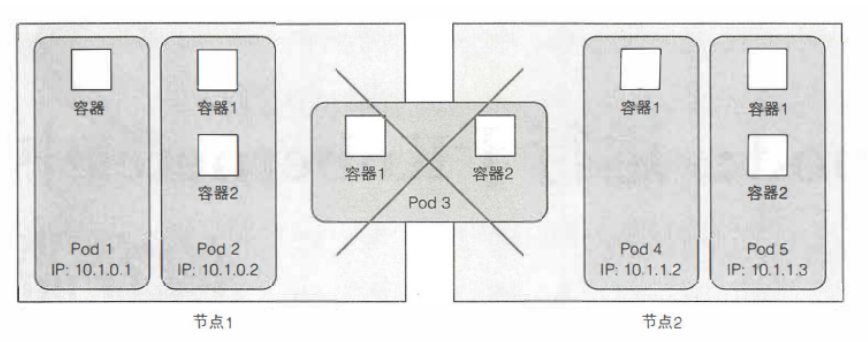
why Pod
①多个容器比单个容器有多个进程要好:https://www.cnblogs.com/yzgblogs/p/16068352.html
②多个提供密切相关进程的容器绑定在一起,可以共享存储(Volumes)、网络(IP)。K8s通过配置Docker,使得一个 pod 内的所有容器共享相同的 Linux 命名空间(共享Network 和UTS 命名空间)。在默认情况下,每个容器的文件系统与其他容器完全隔离。但我们可以使用名为 Volumes的 Kubernetes 资源来共享文件目录。
-
同一个Pod中的容器不能绑定相同的端口
-
同一个Pod内的容器可以通过localhost与其他容器进行通信
-
每个Pod都有独立的端口空间,不同Pod的容器不会出现端口冲突的情况
Pod间的扁平化网络:
Kubernetes 集群中的所有 pod 都在同一个共享网络地址空间中,每个 pod 都可以通过其他 pod 的 IP 地址来实现相互访问,即这些 pod 之间没有 NAT (网络地址转换)网关。当两个 pod 彼此之间发送网络数据包时,它们都会将对方的实际 IP 地址看作数据包中的源 IP。
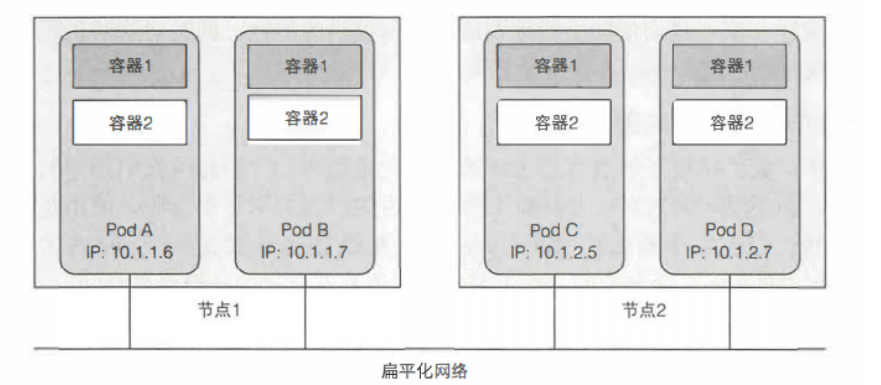
通过Pod管理容器
K8s不能扩缩一个Pod内的单个容器,只能扩缩整个Pod。
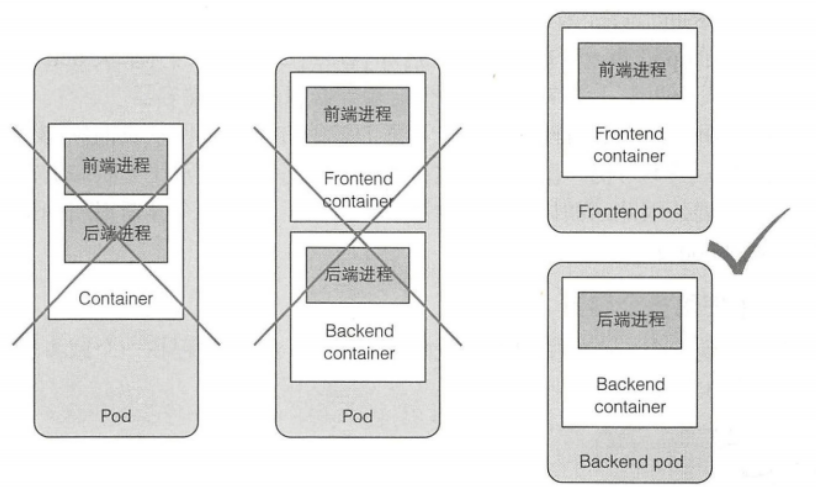
将多层应用分散到多个Pod中断,例如:web服务器和数据库可以分开在不同的Pod,提高对KK8s集群资源的利用
紧密耦合到容器组可以添加到同一个 pod 中:通常为一个主容器和若干个支持容器。例如:主容器是一个仅仅服务于某个目录中的文件的WEB服务器,而辅容器为从定期下载内容并存储在web服务器目录中,日志收集器、数据处理器、通讯适配器等。
多个容器是否可以在一个Pod中的判断标准:
-
它们需要一起运行还是可以在不同的主机上运行?
-
它们代表的是一个整体还是相互独立的组件?
-
它们必须一起进行扩缩容还是可以分别进行?
通过YAML/json描述文件创建pod
pod或其他K8s资源通常通过调用k8s的rest api + ymal/json文件来创建的 。通过 YAML 文件定义所有的 Kubernetes 对象之后,还可以将它们存储在版本控制系统中,充分利用版本控制所带来的便利性。
检查现有 pod 的 YAML 描述文件
命令可以查看指定 pod 的完整 YAML 定义
kubectl get pod -o yaml <pod-name>介绍 pod 定义的主要部分
-
YAML 中使用的 Kubernetes API 版本和YAML 描述的资源类型
-
metadata: 包括名称、命名空间、标签和关于该容器的其他信息
-
spec: 包含 pod 内容的实际说明,例如 pod 的容器、卷和其他数据
-
status: 包含运行中的 pod 的当前信息,例如 pod 所处的条件、每个容器的描述和状态,以及内部 IP 和其他基本信息
status 包含只读的运行时数据,该数据展示了给定时刻的资源状态。在创建新的 pod 时, status 部分不需要提供
apiVersion: v1 -----# 遵循 v1 版本的 Kubernetes API
kind: Pod -----# 资源类型为 Pod
metadata:
name: kubia-manual -----# pod 的名称
spec:
containers:
# 创建容器所使用的镜像
- image: idealism/kubia
# 容器的名称
name: kubia
ports:
# 应用监听的端口
- containerPort: 8080
protocol: TCP使用 kubectl explain 发现可用的 API 对象字段, kubectl explain pod 可以查看 pod 的 各个属性,然后通过选择对应的属性 (kubectl explain pod.spec) 深入了解每个属性的更多信息
使用 kubectl create 来创建 pod
可以通过kubectl create -f 命令用来给yaml、json文件创建任何资源(不只是pod资源)
kubectl create -f <yaml_file_name>使用kubectl get pods 可以获得默认命名空间内的所有Pod名称与状态。若要查看特定命名空间的Pod名称,可以使用命令 kubectl get pods -n <namespace_name>
kubectl get pods -n ranoss使用kubectl get pod <pod_name> -n <namespace_name> -o yaml命令可以查看指定租户下,指定pod的yaml文件信息。
查看应用程序的日志
容器化的应用程序通常会将日志记录到标准输出和标准错误流,而不是写入文件,这就允许用户可以通过简单、标准的方式查看不同应用程序的日志。
docker logs <container> 允许我们查看主机上指定容器的日志
kubectl logs -n <namespace_name> <pod_name> -c <container> 允许我们查看指定 pod 中指定容器的日志,如果该 pod 只包含一个容器,那么 -c <container> 可以省略
当一个 pod 被删除时,它的日志也会被删除。如果希望在 pod 删除之后仍然可以获取其日志,我们需要设置中心化的、集群范围的日志系统,将所有日志存储到中央存储中
标签组织Pod
通过标签来组织Pod和所有其他K8s对象。标签是附加在资源的任意键值对,用以选择具有该标签的资源(通过标签选择器完成)。只要标签在资源内是唯一的,一个资源就可以拥有多个标签。
可以在创建资源的时候将标签附加到资源上,也可以在资源已经创建的前提下,添加其他标签或者修改现有标签的值。
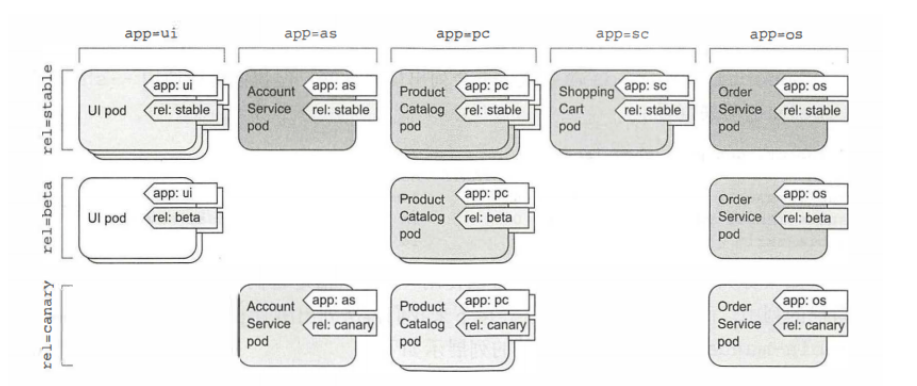
app: 基于应用的横向纬度,指定 pod 属于哪一个应用、组件或微服务
rel: 基于版本的纵向纬度,显示在 pod 中运行的应用程序版本 (stable----稳定的版本, beta----测试版本, canary----体验版本)
在创建资源时附加标签,可以在yaml文件中的metadata.labels 定义。例如:
# 遵循 v1 版本的 Kubernetes API
apiVersion: v1
# 资源类型为 Pod
kind: Pod
metadata:
# pod 的名称
name: kubia-manual-v2
# pod 的标签
labels:
creation_method: manual
env: prod
spec:
containers:
# 创建容器所使用的镜像
- image: idealism/kubia
# 容器的名称
name: kubia
ports:
# 应用监听的端口
- containerPort: 8080
protocol: TCP在如上的yaml文件中,定义Pod名称为kubia-manual-v2的所属标签为 creation_method: manual,env: prod。
使用 --show-labels 参数,可以查看资源的标签信息。若只想查看某个标签,可以使用 参数 -L 进行筛选
标签可以在现有资源上进行添加或修改。
使用 kubectl label pod <pod_name> <label_key=label_value> 可以对pod新增标签。
使用 kubectl label pod <pod_name> <label_key=label_value> --overwrite 可以对pod已有标签进行修改。
标签选择器
标签选择器允许我们选择标记有特定标签的 pod 子集,并对这些 pod 执行操作,它可以根据资源的以下条件来选择资源:
-
包含(或不包含)使用特定键的标签
-
包含具有特定键和值的标签
-
包含具有特定键的标签,但其值与我们指定但不同
使用标签选择器列出
kubectl get pods -l creation_method=manual : 列出包含 creation_method=manual 标签的所有 pod
kubectl get pods -l env : 列出有 env 标签的所有 pod ,无论其值为如何
kubectl get pods -l '!env' : 列出没有 env 标签的所有 pod
kubectl get pods -l creation_method!=manual : 列出有 creation_method 标签但其值不等于 manual 的所有 pod
kubectl get pods -l 'env in (debug, prod)' : 列出有 env 标签并且其值为 debug 或 prod 的所有 pod
kubectl get pods -l 'env notin (debug, prod)' : 列出没有 env 标签,或者有 env 标签并且其值不为 debug 和 prod 的所有 pod
另外,在包含多个逗号分割的情况下,可以在标签选择器中同时使用多个条件,此时资源只有全部匹配才算成功。
使用标签选择器和标签调度Pod
某些情况下,我们希望对将 pod 调度到何处持有一定发言权,例如:硬件基础设施不同质。
-
某些工作节点使用机械硬盘,其他节点使用固态硬盘。可能想将一些 pod 调度到一组节点,同时将其他 pod 调度到另一组节点
-
将执行 GPU 密集型运算的 pod 调度到实际提供 GPU 加速到节点上
K8s希望屏蔽应用程序和基础架构耦合,但是又想保持对Pod调度到哪个节点拥有发言权,这种情况下,我们应该用某种方式描述对节点的需求,使 Kubernetes 选择一个符合这些需求的节点,这恰好可以通过节点标签和节点标签选择器完成。
使用标签分类工作节点
通过附加标签来对节点进行分类,这些标签指定节点提供对硬件类型,或者任何调度 pod 时能提供便利对其他信息。例如,若某个节点包含了用于GPU计算的GPU,可以给这个节点打上标签gpu=true
#列出所有节点
kubectl get nodes
#给节点打上标签 kubectl label node <node_name> <label_key=label_value>
kubectl label node 21.5.10.101 gpu=true
##展示节点的所有标签
kubectl get nodes --show-labels
#展示包含某个标签的节点 kubectl get nodes -l <label_key=label_value>
kubectl get nodes -l gpu=true将 pod 调度到特定节点
基于 kubia-manual-gpu.yaml 创建一个新的描述文件 kubia-manual-gpu.yaml ,并添加 spec.nodeSelector 属性,指定选择的标签为 gpu=true 。这样当我们创建该 pod 时,调度器将只在包含标签 gpu=true 的节点中选择。
# 遵循 v1 版本的 Kubernetes API
apiVersion: v1
# 资源类型为 Pod
kind: Pod
metadata:
# pod 的名称
name: kubia-manual-gpu
# pod 的标签
labels:
creation_method: manual
env: prod
spec:
# 节点选择器
nodeSelector:
# 选择的标签
gpu: "true"我们也可以将 pod 调度到某个确定的节点,由于每个节点都有一个唯一标签 kubernetes.io/hostname ,值为该节点的实际主机名,因此我们也可以将 pod 调度到某个确定的节点。但如果节点处于离线状态,那么可能会导致 pod 不可调度。我们绝不应该考虑单个节点,而是应该通过标签选择器考虑符合特定标准但逻辑节点组。
使用命名空间对资源进行分组
Kubernetes 命名空间简单地为对象名称提供了一个作用域。此时我们并不会将所有资源都放在同一个命名空间中,而是将它们组织到多个命名空间中,这样可以允许我们多次使用相同的资源名称(跨不同的命名空间)。
了解对命名空间的需求
在使用多个命名空间的前提下,我们可以将包含大量组件的复杂系统拆分成更小的不同组,这些不同组也可以用于在多租户环境中分配资源,将资源分配为生产、开发和 QA 环境,或者以其他任何需要的方式分配资源。资源名称只需要在命名空间内保持唯一即可,因此两个不同的命名空间可以包含同名的资源。
大多数类型的资源都与命名空间相关,但仍有一些与它们无关,其中之一便是全局且未被约束于单一命名空间但节点资源。
发现其他命名空间及其 pod
kubectl get namespaces: 列出集群中的所有命名空间
kubectl get pods -n kube-system: 列出 kube-system 命名空间下的所有 pod
命名空间的优点
可以隔离资源,将不属于一组的资源分到不重叠的组中,避免无意中修改或删除其他用户的资源,也无须关心名称冲突
可用于仅允许某些用户访问某些特定的资源,甚至限制单个用户可用的计算资源数量
创建一个命名空间
命名空间是一种和其他资源一样的 Kubernetes 资源,因此可以通过 YAML 文件提交到 Kubernetes API 服务器来创建该资源。
从 YAML 文件创建命名空间
# 遵循 v1 版本的 Kubernetes API
apiVersion: v1
# 资源类型为 Namespace
kind: Namespace
metadata:
# 命名空间的名称
name: custom-namespacekubectl create -f custom-namespace.yaml 可以通过 YAML 文件创建命名空间。
Kubernetes 中的所有内容都是一个 API 对象,可以通过向 API 服务器提交 YAML 文件来实现创建、读取、更新和删除。
使用 kubectl create namespace 命令创建命名空间
kubectl create namespace <namespace-name>: 创建一个指定名称的命名空间
管理其他命名空间中的对象
kubectl create -n custom-namespace -f kubia-manual.yaml: 在 kubia-manual 命名空间中通过指定的 YAML 文件创建一个资源。
如果不指定命名空间, kubectl 将在当前上下文中配置的默认命名空间中执行操作。而当前上下文的命名空间和当前上下文本身都可以通过 kubectl config 命令进行更改。
命名空间提供的隔离
尽管命名空间将对象分隔到不同更多组,只允许你对属于特定命名空间的对象进行操作,但实际上命名空间之间并不提供对正在运行对对象对任何隔离。例如,若K8s集群中的网络解决方案中不提供网络隔离时,不同命名空间间仍然可以通过pod的IP进行通信。
停止和移除 pod
按名称删除 pod
kubectl delete pod -n <namespace-name> <pod-name-1> [<pod-name-2> ...]: 删除指定命名空间下的指定 pod 。
在删除 pod 的过程中,实际上我们在指示 Kubernetes 终止该 pod 中的所有容器。 Kubernetes 向进程发送一个 SIGTERM 信号并等待一定的秒数(默认为 30 秒),使其正常关闭,如果它没有即使关闭,则通过 SIGKILL 终止该进程。因此,为了确保你的进程总是正常关闭,进程需要正确处理 SIGTERM 信号。
使用标签选择器删除 pod
kubectl delete pod -n <namespace-name> -l <label-key>=<label-value>: 删除指定命名空间下含有指定标签的所有 pod 。
在微服务示例中,通过指定 rel=canary 标签选择器,可以一次删除所有金丝雀 pod 。
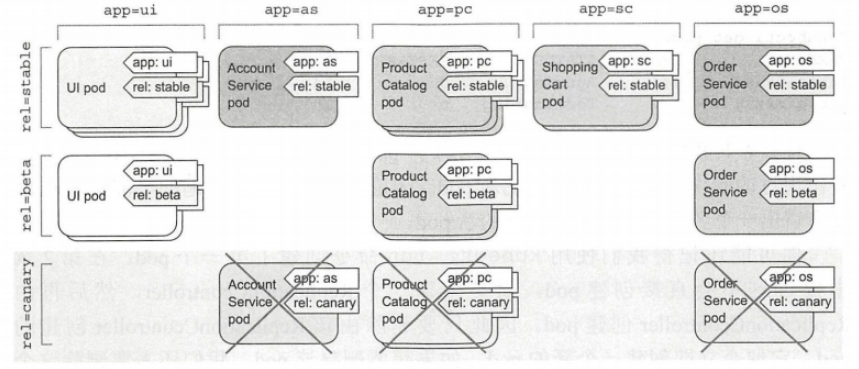
通过删除整个命名空间来删除 pod
kubectl delete namespace custom-namespace: 删除整个 custom-namespace 命名空间( pod 将会随命名空间自动删除)
删除命名空间中的所有 pod ,但保留命名空间
kubectl delete pod -n <namespace-name> --all: 删除指定命名空间中的所有 pod 。
若在该命名空间内,使用kubectl run命令创建了pod。则可能出现执行上面删除命名空间的所有pod后,仍然在该命名空间中出现pod的情况,这个是因为当删除了由ReplicationCcontroller(kubectl run命令不会直接创建pod,而是创建一个ReplicationCcontroller,再由ReplicationCcontroller创建一个pod)创建的pod后,他会重新创建一个新的pod。
删除命名空间中的(几乎)所有资源
kubectl delete all -n <namespace-name> --all: 删除指定命名空间中的所有资源。 all 指定删除所有资源类型, --all 选项指定删除所有资源实例。
注意:使用 all 关键字并不会真的完全删除所有内容。一些资源会被保留下来,并且需要被明确指定删除。如:Secret
注意:该命令也会删除名为 kubernetes 的 Service ,但它会在几分钟后自动重新创建。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









