







 本文详细介绍了Logi-KafkaManager在Kafka集群运维中的作用,包括集群列表管理、迁移任务执行(同集群数据迁移)以及手动迁移过程中的注意事项,如数据量减少、流量限制和副本同步。
本文详细介绍了Logi-KafkaManager在Kafka集群运维中的作用,包括集群列表管理、迁移任务执行(同集群数据迁移)以及手动迁移过程中的注意事项,如数据量减少、流量限制和副本同步。
文章目录
-
- 技术交流
-
运维管控
-
- 集群列表
-
集群运维
-
- 迁移任务
-
- 手动迁移过程实现
-
数据迁移的几个注意点
-
Logi-KafkaManager 实现数据迁移
-
集群任务
-
版本管理
-
平台管理
-
专栏文章列表
项目地址: didi/Logi-KafkaManager: 一站式Apache Kafka集群指标监控与运维管控平台
====================================================================
运维管控这个菜单栏目下面主要是供
运维人员来管理所有集群的;
Kafka的灵魂伴侣Logi-KafkaManger三之运维管控–集群列表
迁移任务
kafka的迁移场景, 一般有同集群数据迁移、跨集群数据迁移; 我们这里主要讲 同集群数据迁移;
同集群之间数据迁移,比如在已有的集群中新增了一个Broker节点,此时需要将原来集群中已有的Topic的数据迁移部分到新的集群中,缓解集群压力。
在了解KM的迁移功能之前,我们先了解一下正常情况下是怎么做迁移的;
手动迁移过程实现
分区重新分配工具可用于将一些Topic从当前的Broker节点中迁移到新添加的Broker中。这在扩展现有集群时通常很有用,因为将整个Topic移动到新的Broker变得更容易,而不是一次移动一个分区。当执行此操作时,用户需要提供已有的Broker节点的Topic列表,以及到新节点的Broker列表(源Broker到新Broker的映射关系)。然后,该工具在新的Broker中均匀分配给指定Topic列表的所有分区。在迁移过程中,Topic的复制因子保持不变。
现有如下实例,将Topic为ke01,ke02的所有分区从Broker1中移动到新增的Broker2和Broker3中。由于该工具接受Topic的输入列表作为JSON文件,因此需要明确迁移的Topic并创建json文件,如下所示:
cat topic-to-move.json
{“topics”: [{“topic”: “ke01”},
{“topic”: “ke02”}],
“version”:1
}
1 . 准备好JSON文件,然后使用分区重新分配工具生成候选分配,命令如下:
bin/kafka-reassign-partitions.sh --zookeeper dn1:2181 --topics-to-move-json-file topics-to-move.json --broker-list “1,2” --generate
执行完成命令之后,控制台出现如下信息:
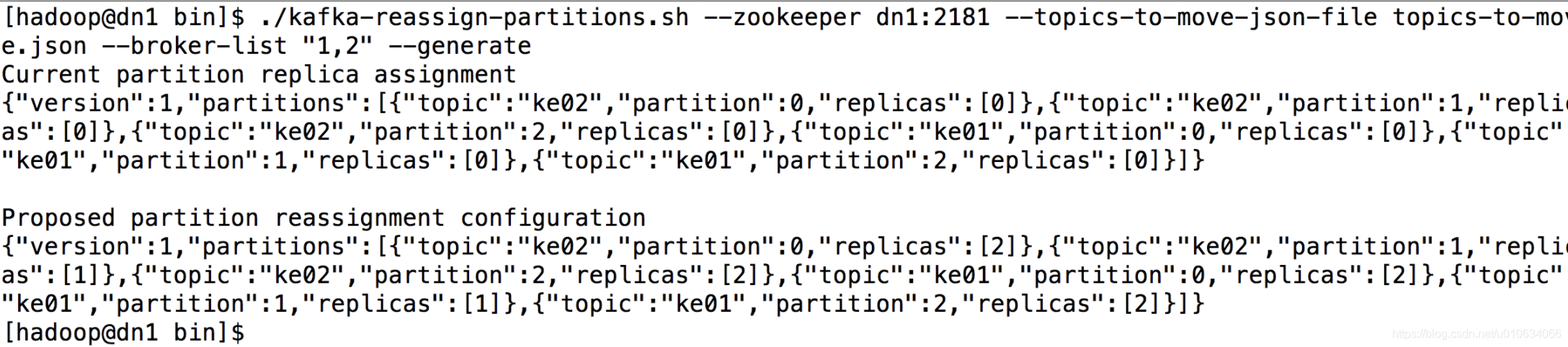
该工具生成一个候选分配,将所有分区从Topic ke01,ke02移动到Broker1和Broker2。需求注意的是,此时分区移动尚未开始,它只是告诉你当前的分配和建议。保存当前分配,以防你想要回滚它。新的赋值应保存在JSON文件(例如expand-cluster-reassignment.json)中,以使用–execute选项执行。JSON文件如下:
{“version”:1,“partitions”:[{“topic”:“ke02”,“partition”:0,“replicas”:[2]},{“topic”:“ke02”,“partition”:1,“replicas”:[1]},{“topic”:“ke02”,“partition”:2,“replicas”:[2]},{“topic”:“ke01”,“partition”:0,“replicas”:[2]},{“topic”:“ke01”,“partition”:1,“replicas”:[1]},{“topic”:“ke01”,“partition”:2,“replicas”:[2]}]}
2. 执行命令如下所示:
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
3. 最后,–verify选项可与该工具一起使用,以检查分区重新分配的状态。需要注意的是,相同的expand-cluster-reassignment.json(与–execute选项一起使用)应与–verify选项一起使用,执行命令如下:
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
执行结果如下图所示:

数据迁移的几个注意点
减少迁移的数据量: 如果要迁移的Topic 有大量数据(Topic 默认保留7天的数据),可以在迁移之前临时动态地调整retention.ms 来减少数据量,比如下面命令改成1小时; Kafka 会主动purge 掉1小时之前的数据;
bin/kafka-topics --zookeeper localhost:2181 --alter --topic sdk_counters --config retention.ms=3600000
不要要注意迁移完成后,恢复原先的设置
迁移过程注意流量陡增对集群的影响
Kafka提供一个broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限,当重新平衡集群,引导新broker,添加或移除broker时候,这是很有用的。因为它限制了这些密集型的数据操作从而保障了对用户的影响、
例如我们上面的迁移操作
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
在后面加上一个—throttle 50000000 参数, 那么执行移动分区的时候,会被限制流量在50000000 B/s
加上参数后你可以看到
The throttle limit was set to 50000000 B/s
Successfully started reassignment of partitions.
迁移过程限流不能过小,导致迁移失败
-throttle 是broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限; 但是你应该了解到正常情况下,副本直接也是有副本同步的流量的; 如果限制的低于正常副本同步的流量值,那么会导致副本同步异常,跟不上Leader的速率很快就被踢出ISR了;
迁移完成,注意要移除流量的限制:
如果我们加上了迁移这个操作, 需要使用参数--verify 来验证执行状态,同时流量限制也会被移除掉; 否则可能会导致定期复制操作的流量也受到限制。
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
详情请参考
Logi-KafkaManager 实现数据迁移
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
在面试前我整理归纳了一些面试学习资料,文中结合我的朋友同学面试美团滴滴这类大厂的资料及案例


由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
大家看完有什么不懂的可以在下方留言讨论也可以关注。
觉得文章对你有帮助的话记得关注我点个赞支持一下!
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
…(img-RNiDyKkQ-1712039627592)]
[外链图片转存中…(img-Iq9f3RSW-1712039627593)]
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
大家看完有什么不懂的可以在下方留言讨论也可以关注。
觉得文章对你有帮助的话记得关注我点个赞支持一下!
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!















 1844
1844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









