







大模型的演变
1、人工智能:人工智能是一个广泛涉及计算机科学、数据分析、统计学、机器工程、语言学、神经科学、哲学和心理学等多个学科的领域。
2、生成式人工智能(AIGC):生成式人工智能又是深度学习中快速增长的子集,它们使用了大模型提供支持,在大量原始、未标记的数据基础上对深度学习模型进行预训练,使得机器能够"理解"语言甚至图像,并能够根据需要自动生成内容。
机器学习的分类:监督学习,无监督学习,强化学习。
如今的大模型逐渐向多模态发展,可处理文字、视频、图像等多种模态。
大模型的训练
整体上有三个阶段:预训练,SFT(监督微调),RLHF(基于人类反抗的强化学习)
1、预训练:学习各种不同种类的语料,训练模型底层的的通用能力。
2、SFT:某个方向进行精修,学习到非常专业的垂直领域知识,使其可以按照人类的意图去回答专业领域问题。
3、RLHF:针对某一问题回答多次,并获得反馈,从而训练使得回答更加符合人类偏好。
大模型的分类
1、大语言模型(LLM):
这类大模型专注于自然语言处理(NLP),旨在处理语言、文章、对话等自然语言文本。它们通常基于深度学习架构(如Transformer模型),经过大规模文本数据集训练而成,能够捕捉语言的复杂性,包括语法、语义、语境以及蕴含的文化和社会知识。语言大模型典型应用包括文本生成、问答系统、文本分类、机器翻译、对话系统等。
2、多模态大模型:
多模态大模型能够同时处理和理解来自不同感知通道(如文本、图像、音频、视频等)的数据,并在这些模态之间建立关联和交互。它们能够整合不同类型的输入信息,进行跨模态推理、生成和理解任务。多模态大模型的应用涵盖视觉问答、图像描述生成、跨模态检索、多媒体内容理解等领域。
大模型的工作流程
1、分词化与词表映射:
分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。
举个栗子~:
比如我们输入“I love you.”
为了让机器理解这个句子,对字符串执行分词化,将其分解为独立的单元。使用分词化,我们会得到这样的结果:
['l' ,'love' ,'you' '.']
将一个句子分解成更小的、独立的部分可以帮助计算机理解句子的各个部分,以及它们在上下文中的作用,这对于进行大量上下文的分析尤其重要。
分词化有不同的粒度分类:
- 词粒度(Word-Level Tokenization)分词化,如上文中例子所示,适用于大多数西方语言,如英语。
- 字符粒度(character-level)分词化,这是中文最直接的分词方法,它是以单个汉字为单位进行分词化。
- 子词粒度(Subword-Level)分词化,它将单词分解成更小的单位,比如词根、词缀等。这种方法对于处理新词(比如专有名词、网络用语等)特别有效,因为即使是新词,它的组成部分很可能已经存在于词表中了。每一个token都会通过预先设置好的词表,映射为一个token id,这是token的"身份证",一句话最终会被表示为一个元素为token id的列表,供计算机进行下一步处理。
2、大语言模型生成文本:
大语言模型的工作概括来说是根据给定的文本预测下一个token。对我们来说,看似像在对大模型提问,但实际上是给了大模型一串提示文本,让他可以对后续的文本进行推理。大模型的推理过程不是一步到位的,当大模型进行推理时,它会基于现有的token,根据概率最大原则预测出下一个最有可能的token,然后将该预测的token加入到输入序列中,并将更新后的输入序列继续输入大模型预测下一个token,这个过程叫做自回归。直到输出特殊token(如<EOS>,end of sentence,专门用来控制推理何时结束)或输出长度达到阈值。
再举个栗子~:
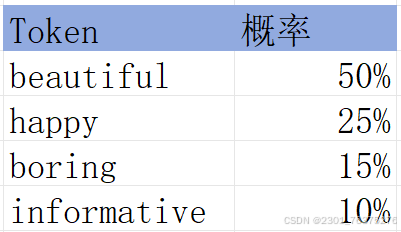
大模型得到“That girl is very”,他会基于现有的token判断后续最可能的字符。
↓
↓
此时beautiful为后续最有可能的字符,所以本句话生成“That girl is very beautiful”
本次学习内容主要为大模型的概况与整体了解,后续会学习平台界面搭建的相关技术和关于deepseek微调的相关技术~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









