






前言
几周前,我介绍了检查点调优的基础知识,在那篇文章中,我还提到自动清理是第二个常见的性能问题来源(根据我们在邮件列表和客户那里看到的情况)。让我在这篇文章中继续介绍如何调优自动清理,以最大限度地降低性能问题的风险。在这篇文章中,我将简要解释我们为什么需要自动清理(死行、膨胀以及自动清理如何处理这些问题),然后转到这篇博文的重点 - 调优。我将介绍所有相关的配置选项,以及调优它们的一些基本规则。
注意:这是我 2016 年撰写的一篇博客文章的更新版本,更新后反映了 PostgreSQL 配置中的各种变化。除此之外,整体调整方法基本保持不变。
什么是死行?
在开始讨论调整 autovacuum 之前,我们首先需要了解什么是“死行”,以及为什么 autovacuum 执行清理实际上是需要的……
注意:有些资料说的是“死元组”而不是“死行”——这几乎只是同一事物的不同名称。术语“元组”来自关系代数(关系数据库的基础),因此更抽象,而“行”的含义通常更接近实现。但这些差异大多被忽略,并且这些术语可以互换使用。在这篇文章中,我将坚持使用“行”。
当您在 Postgres 中执行DELETE时,行(又名 row)不会立即从数据文件中删除。相反,它只是通过在标题中设置一个xmax字段来标记为已删除。对于UPDATE,在 Postgres 中,它基本上相当于DELETE + INSERT。
这是 Postgres 中 MVCC(多版本并发控制)的基本思想之一,允许不同的进程根据它们获取快照的时间查看行的不同子集。例如,在DELETE提交之前启动的SELECT进程应该看到旧行,而在DELETE提交之后启动的SELECT进程应该看到新版本(至少对于默认隔离级别READ COMMITTED而言)。
其他 MVCC 实现采用不同的方法,但 Postgres 会创建行的副本。此 MVCC 实现的缺点是,它会留下已删除的行,即使在可能看到这些版本的所有事务完成后也是如此。
因此,最后您将得到一个“标记”为已删除但仍占用数据文件空间的行。如果您更新了某一行 100 次,则该行将有 101 个副本。如果不清理,这些“死行”(实际上对任何未来事务都是不可见的)将永远保留在数据文件中,浪费磁盘空间。对于包含大量DELETEs 和/或UPDATEs 的表,死行可能很容易占据绝大多数磁盘空间。当然,这些死行仍从索引中引用,从而进一步增加了浪费的磁盘空间量。
这就是我们在 PostgreSQL 中所说的“膨胀”——与所需的最小空间量相比,表和索引都过于膨胀。当然,如果查询必须处理更多数据(即使其中 99% 的数据被立即丢弃为“不可见数据”),这也会对这些查询的性能产生影响。
VACUUM 和autovacuum
回收浪费的空间(死行占用)的最直接方法是手动运行VACUUM 命令。此维护命令将扫描表并从表和索引中删除死行。它不会将磁盘空间返回给操作系统/文件系统,而只会将其用于新行。例如,如果您有一个 10GB 的表,但其中 9GB 被死行使用,则将完成VACUUM清理,表仍将是 10GB。但接下来的 9GB 行将不需要扩展表 - 它将作为数据文件中的回收空间来使用。当然,这个例子有点极端 - 您不应该允许表中有 9GB 的死行。我们很快就会讲到这一点。
注意:VACUUM FULL将回收空间并将其返回给操作系统,但它有许多缺点。它会获取表上的独占锁,阻止所有操作(包括只读查询),并创建表的新副本,这可能会使使用的磁盘空间量增加一倍(因此,当您的磁盘空间已经用完时,它特别不切实际)。
手动运行VACUUM的问题在于:它只会在您决定运行它时发生,而不是在需要它时发生。如果您每 5 分钟在所有表上运行一次,则大多数运行实际上可能不会清理任何内容。它只会检查表,可能读取一些数据,但最终发现还没有任何可以清理的内容。因此,您只会浪费 CPU 和 I/O 资源。或者您可以选择降低运行频率,比如每天晚上运行一次,表可能会很容易积累比您想要的更多的死行。
换句话说,制定VACUUM正确的时间表非常困难,尤其是对于可能随时间变化的工作负载(由于数据/周期间用户活动的变化,或由于应用程序的变化)。唯一的例外是系统对批量数据加载有非常明确的时间表(例如,具有夜间批量加载的分析数据库)。
这引出了自动清理( autovacuum )- 一个负责及时触发清理的后台进程。通常足以控制浪费的空间量,但不要太频繁。诀窍在于数据库会跟踪随时间产生的死行数(每个事务都会报告更新/删除的行数),因此当表积累了一定数量的死行时,它可以触发清理。这意味着在繁忙时段,清理会更频繁地发生。
自动分析(autoanalyze)
清理死行并不是autovacuum进程的唯一职责,它还负责收集用于查询规划的数据分布统计信息。您可以使用手动ANALYZE收集这些数据,但它也面临与VACUUM类似的问题- 很难经常运行它,但又不能太频繁。解决方案也类似 - 数据库可以监视修改的行数,并在超过某个阈值时自动运行ANALYZE。
注意:对ANALYZE的负面影响更严重一些,因为虽然VACUUM的成本主要与死行数量成正比(当表中死行很少时相当低,使不必要的清理变得便宜),但ANALYZE实际上必须在每次执行时重新构建统计信息(包括收集随机样本,这可能需要相当多的I/O)。另一方面,表中的膨胀可能会稍微降低查询速度,因为必须做更多的I/O。但是陈旧的统计数据意味着选择低效的查询计划和消耗大量资源(时间、CPU、I/O)的查询的风险很大。这种差异可能是指数级的。
在本博文的其余部分中,我将忽略此自动清理(autovacuum )任务 - 其配置与清理非常相似,并且遵循大致相同的原理。
监控
在开始调整之前,您需要能够收集相关数据。否则,您如何知道是否需要进行任何调整,或者评估更改的影响?换句话说,您需要进行一些基本的监控,定期从数据库收集重要指标。
如果您正在使用某些监控插件(绝对应该使用,有很多选择,既有免费的也有商业的),那么您可能已经拥有这些数据。但在这篇文章中,我将使用数据库中可用的统计数据来演示调整。
为了进行清理,您至少需要查看以下值:
1. pg_stat_all_tables.n_dead_tup- 每个表(用户表和系统目录)中的死行数
2. (n_dead_tup / n_live_tup)- 每个表中死行/活行的比率
3. (pg_class.relpages / pg_class.relrows)- “每行”空间
还有一个方便的pgstattuple扩展,允许您对表和索引执行分析,包括计算可用空间量、死行等。
调整目标
在查看实际的配置参数之前,我们先简单讨论一下高层的调优目标是什么,即改变参数时我们想要实现什么:
1. 清理死行- 保持磁盘空间量合理地较低,不要浪费不合理的磁盘空间,防止索引膨胀并保持查询快速。
2. 尽量减少清理影响- 不要过于频繁地进行清理,因为这会浪费资源(CPU、I/O 和 RAM)并可能严重损害性能。
也就是说,您需要找到正确的平衡点 - 过于频繁地运行清理可能与运行不够频繁一样糟糕。权衡主要取决于数据量、您处理的工作负载类型(尤其是DELETE/UPDATE的数量)。
大多数配置选项的默认值都非常保守。首先,默认值通常是多年前根据当时可用的资源(CPU、RAM 等)选择的。其次,我们希望默认配置可以在任何地方使用,包括 Raspberry Pi 等小型机器或小型 VPS 服务器。我们确实会不时调整默认值(正如将在本博文后面看到的那样),但即便如此,我们还是倾向于采取谨慎的小步骤。
对于较小的系统和/或处理主要读取工作负载的系统,默认配置参数工作正常,但对于大型系统,需要进行一些调整。随着数据库大小和/或写入量的增加,问题开始出现。
使用自动清理时,典型的问题是清理频率不够高,当清理终于发生时,它会严重影响查询的性能,因为它必须处理大量垃圾。在这些情况下,您应该遵循以下简单规则:
如果疼痛,那说明你锻炼的还不够频繁。(If it hurts, you're not doing it often enough.)
也就是说,您需要调整autovacuum配置,以便更频繁地进行清理,但每次执行时处理较少量的死行。
现在我们知道了我们想要实现的目标,接下来让我们看看配置参数...
注意:人们有时会遵循不同的规则 - 如果有害,就不要做 - 只需禁用autovacuum。请不要这样做,除非您真的(真的)知道自己在做什么,并且有定期执行的清理脚本(例如来自 cron)。否则,您就是在把自己逼入绝境,最终您将不得不处理严重下降的性能甚至中断,而不是性能有所下降。
阈值和比例因子
当然,您可能要调整的第一件事是清理的触发时间,它受两个参数的影响(具有以下默认值):
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
只要表的死行数(您可以看到pg_stat_all_tables.n_dead_tup)超过
threshold + pg_class.relrows * scale_factor
这个公式表明,在清理之前,一个表中最多有 20% 可能是死行(50 行的阈值是为了防止非常频繁地清理小表,但对于大表来说,与比例因子相比,这个数字就小得多了)。
那么,这些默认值有什么问题,特别是比例因子?这个值基本上决定了表中可以“浪费”的部分,对于中小型表来说,20% 非常合适 - 在 10GB 的表上,这最多允许 2GB 的死行。但对于 1TB 的表,这意味着我们可以积累多达 200GB 的死行,然后当最终进行清理时,它将不得不立即完成大量工作。
这是一个积累了大量死行并必须一次性全部清理的示例,这会造成麻烦 - 它会使用大量 I/O 和 CPU、生成 WAL 等等。这正是我们想要防止的对其他后端的破坏。
根据前面提到的规则,正确的解决方案是更频繁地触发清理。这可以通过显著降低比例因子来实现,例如:
autovacuum_vacuum_scale_factor = 0.01
这会将限制降低到表的 1%,即 1TB 表中的 ~10GB。
或者,您可以完全放弃比例因子,仅依赖阈值:
autovacuum_vacuum_scale_factor = 0
autovacuum_vacuum_threshold = 10000
这将在产生 10000 个死行后触发清理。
需要考虑的一点是,仅降低比例因子就可以更轻松地触发小型表上的清理 - 如果您的表有 1000 行,则比例因子 1% 意味着只需更新 10 行即可使该表符合清理条件。这似乎过于激进。
最简单的解决方案就是忽略它,认为它不是问题。清理小表的成本可能非常低,而大表的改进通常非常显著,即使更频繁地处理小表,总体效果仍然非常积极。
但如果你想防止这种情况发生,请稍微增加阈值。你可能会得到这样的结果:
autovacuum_vacuum_scale_factor = 0.01
autovacuum_vacuum_threshold = 1000
一旦表累积了 1000 + 1% 的死行,就会触发表的清理。对于小型表,1000 将占主导地位,对于大型表,1% 的比例因子将更重要。
还请考虑postgresql.conf中的参数会影响整个集群(所有数据库中的所有表)。如果您只有少数几个大表,您也可以考虑使用ALTER TABLE仅修改它们的参数:
ALTER TABLE large_table SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE large_table SET (autovacuum_vacuum_threshold = 10000);
我强烈建议只修改postgresql.conf参数,只有当修改不够时才诉诸ALTER TABLE。它使清理行为的调试和分析变得更加复杂。如果您最终要这样做,请确保记录每个表的原因。
注意:这些参数应该调到多低?为什么不调到 0.001,即对于 1TB 表,只调到 0.1%(1GB)?你可以试试,但我不推荐这么低的值。“浪费”的空间用作新数据的缓冲区,使系统有点松懈。从 200GB 调到 10GB 可以节省大量空间,同时仍为新行留下大量空间,而从 10GB 调到 1GB 的好处要小得多。不值得冒过早触发清理的风险(在实际清理行之前,强制再次尝试清理)。
节流
自动清理系统内置的一个重要功能是节流。清理旨在成为一项后台维护任务,对用户查询等的影响最小。我们当然不希望清理消耗太多资源(CPU 和磁盘 I/O)以影响常规用户活动(例如使查询速度变慢)。这需要限制清理随时间可以利用的资源量。
清理过程相当简单 - 它从数据文件中读取页面(8kB 数据块),并检查页面是否需要清理。如果没有死行,则直接丢弃该页面而不做任何更改。否则,页面将被清理(删除死行),标记为“脏”,并最终写出(写入缓存,最终写入磁盘)。
让我们将“成本”分配给基本案例,表示所需的资源数量(这些值在 PG 14 中发生了变化,除非另有明确说明,否则我将使用新值):
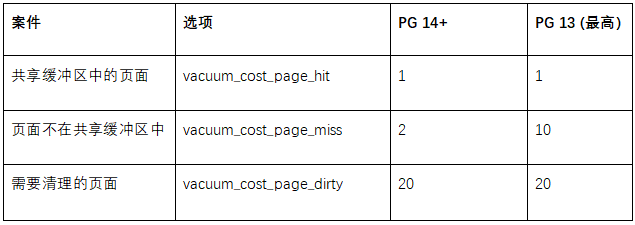
这表示如果在共享缓冲区中找到一个页面,则需要花费 1 个令牌。如果必须从操作系统(也可能从磁盘)读取,则成本会更高一些,需要花费 2 个令牌。最后,如果页面因清理而变脏并需要写出,则计为 20。这使我们能够计算自动清理随时间推移所做的工作。
然后通过限制一次性可以完成的工作量(默认设置为 200)来实现节流,每次清理工作完成这么多工作时,它都会休眠一小会儿。休眠时间以前是 20 毫秒,但在 PG 12 中减少到了 2 毫秒。
autovacuum_vacuum_cost_delay = 2ms
autovacuum_vacuum_cost_limit = 200
让我们计算一下实际允许的工作量。延迟在 PG 12 中发生了变化,这意味着我们有三组版本,具有不同的参数值。
延迟 2 毫秒,清理可以每秒运行 500 次,每轮 200 个令牌,这意味着每秒的预算为 100000 个令牌(在 PG 12 之前的旧版本中,限制为 10000)。考虑到前面讨论的清理操作的成本,这意味着:

考虑到当前硬件的功能(假设本地存储),PG 14 之前版本的默认限制可能太低。最好增加成本限制(可能增加到 1000-2000,将吞吐量提高 5-10 倍),或者以类似的方式降低成本延迟。当然,您可以调整其他参数(每页操作成本、睡眠延迟),但我们不经常这样做 - 更改成本限制就足够了。在 PG 14 中,限制明显更高,使得默认值更为合适。
注意:常规 VACUUM 具有相同的限制机制,但默认情况下禁用(vacuum_cost_delay设置为 0)。但如果您需要运行手动 VACUUM,则可以启用限制以限制对数据库其余部分(用户查询等)的影响。
工人数量
尚未提及的一个配置选项是autovacuum_max_workers,那么它是什么呢?清理不是由单个autovacuum进程执行的 - 相反,数据库启动执行实际清理的autovacuum_max_workers进程(每个工作进程一次处理一个表)。默认配置最多允许 3 个这样的工作进程。
这绝对很有用,因为例如,您不想停止清理小表,直到清理完一个大表(由于限制,这可能需要相当长的时间)。
问题是用户认为增加工作者的数量也会增加可能发生的清理量。如果你允许6个自动清理工作程序而不是默认的3个,它将做两倍的清理工作,对吧?
不幸的是,不行。前几段所述的成本限制是全局的,由所有运行中的自动清理工作进程共享。每个工作进程只获得全局成本限制的一小部分(大约为1/autovacuum_max_workers)。因此,增加工作线程的数量只会使它们运行得更慢,而不会增加清理吞吐量。
这有点像高速公路——汽车数量加倍但速度减半,每小时到达目的地的人数大致相同。
因此,如果数据库清理速度跟不上用户活动,增加工作进程数量也无济于事。您需要先调整其他参数。
每个表的限制
实际上,当我提到成本限制是全局的并由所有自动清理工作者共享时,这并不完全正确。与比例因子和阈值类似,成本限制和延迟可以使用每个表来定义:
ALTER TABLE t SET (autovacuum_vacuum_cost_limit = 1000);
ALTER TABLE t SET (autovacuum_vacuum_cost_delay = 10);
但是,处理具有自定义限制的此类表的工作者不包括在全局成本中,而是受到独立限制(即,限制适用于该单个工作者)。
实际上,我们几乎从不使用此功能,我们建议不要使用它。它使清理行为更难预测和推理 - 多个工作者有时一起被限制,有时独立被限制,这使得情况变得非常复杂。您可能希望对后台清理使用单个全局限制。
概括
如果我必须将其总结为几个基本规则,那就是以下五条:
1. 不要禁用自动清理功能,除非您真的知道自己在做什么。
2. 在繁忙的数据库(执行大量更新和删除)上,特别是大型数据库,您可能应该降低比例因子,以便更频繁地进行清理。
3. 在合理的硬件(良好的存储、多核)上,您可能需要增加节流参数,以便清理工作能够跟上。这尤其适用于 Postgres 14 之前的旧版本。
4. 在大多数情况下,单独增加 autovacuum_max_workers 不会有帮助,因为它不会增加清理吞吐量。您将得到更多运行速度较慢的进程。
5. 您可以使用 ALTER TABLE 设置每个表的参数,但如果真的需要这样做,请三思。这会使系统更加复杂,更难检查。
原文链接:https://www.enterprisedb.com/blog/autovacuum-tuning-basics















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









