









一、初始化云盘FAQ
出现位置:运行【align-check optimal 1】,报错【1 not aligned】
问题:在创建GPT分区时,分区显示未对齐
1.运行命令,查看云盘参数
【cat /sys/block/vdb/queue/optimal_io_size】
【cat /sys/block/vdb/queue/minimum_io_size】
【cat /sys/block/vdb/alignment_offset】
【cat /sys/block/vdb/queue/physical_block_size】
2.运行【mkpart primary <推荐扇区值>s 100%】重新划分一个主分区
推荐扇区值=(optimal_io_size + minimum_io_size)/ physical_block_size
说明:里面的数据是第1步中云盘参数,这个公式常见于磁盘驱动器的优化配置场景,特别是用于Linux系统下进行IO调度优化时。而这个公式是基于对特定硬件特性的理解使用的
【optimal_io_size】:指磁盘驱动器建议的最佳I/O传输大小
【minimum_io_size】:指驱动器能够接受的最小I/O操作大小
【physical_block_size】:指磁盘上实际数据存储的最小单位
二、升级e2fsprogs工具包
出现位置:运行【sudo mkfs -t ext4 /dev/vdb1】,报错【mkfs.ext4: size of device /dev/vdb too big to be expressed in 32 bits using a blocksize of 4096】
问题:当数据盘容量为16TB,在创建ext4文件系统报错,e2fsprogs版本过低
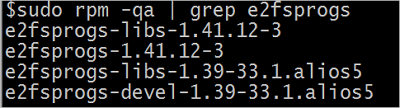
1.运行【rpm -qa | grep e2fsprogs】,检查e2fsprogs当前的版本
2.运行【wget https: / /ww.kernel.org/pub/linux/kernel/people/tytso/e2fsprogs/v1.42.8/e2fsprogs-1.42.8.tar-gz --no-check-certificate】下载1.42.8版本e2fsprogs
3.运行【tar xvzf e2fsprogs-1.42.8.tar.gz】解压软件包
4.运行【cd e2fsprogs-1.42.8】进入软件包目录
5.运行【./configure】生成Makefile文件
6.运行【make】编译e2fsprogs
7.运行【make install】安装e2fsprogs
8.运行【rpm -qa | grep e2fsprogs】检查是否成功更新版本
三、关闭lazy init功能
在创建ext4文件系统后,默认开启lazy init功能。实例会发起一个线程持续地初始化ext4文件系统的metadata,从而延迟metadata初始化。所以在格式化数据盘后的近期时间内,云盘的IOPS性能会受到影响,IOPS性能测试的数据会明显偏低
运行【sudo mke2fs -o 64bit,has_journal,extents,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize -E lazy_itable_init=e,lazy_journal_init=e /dev/vdb1】关闭lazy_init功能
注:关闭lazy init功能后,格式化的时间会延长,格式化32 TiB的数据盘可能需要10分钟~30分钟

















 2521
2521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









