







Guido在创建Python之前,是ABC语言的贡献者,ABC语言是一个为期10年的研究项目,旨在为初学者设计编程环境。ABC引入了许多我们现在认为很“Pythonic”的想法:对不同类型序列、内置的元组、映射类型设计统一的操作方式;缩进式代码写法、数据的强类型但无变量声明等。Python如此用户友好并非偶然。
Python继承了ABC对序列的统一处理。字符串、列表、字节序列、数组、XML元素和数据库结果集共享一组丰富的通用操作,包括迭代、切片、排序和连接。
了解Python中可用的各种序列使我们免于重新发明轮子,我们可以充分使用通用的API,在自定义的序列类型中遵循和发扬这些通用规则。
本章讨论的内容可适用于常规的序列类型,例如list、str、bytes。List、tuple、array、queue各自的特性也会介绍,但是Unicode字符串和byte序列在第4章介绍。本章先介绍可以直接使用的序列类型,自定义序列在12章介绍。
本章内容包括:
- 熟悉列表推导式和生成器
- 元组作为记录和作为不可变列表的对比
- 序列的拆包和模式
- 读取和编辑切片
- 特殊的序列类型,如array(阵列)和queue(队列)
内置序列概述
Python基础库提供了丰富的序列类型,其底层是用C语言实现的:
- 容器型序列:可以容纳不同类型的元素,可以多层嵌套。例如list、tuple、collections.deque。
- 扁平型序列:只能容纳同一类型的元素。例如str、bytes、array.array。
容器型序列存放元素的引用(也可以叫做句柄),所以不管元素本身的类型是什么都可以存。扁平型序列直接存储元素数据,所以元素不能是可变数据类型。如图2-1所示。
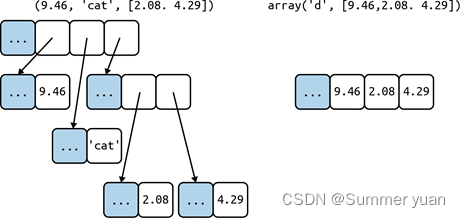
虽然扁平型序列更简洁,但是只能存储基础类型,如byte、interger、float型。
Python对象存储的内存区块内都有一个数据头,数据头包含一些元数据(即描述此对象特征的数据)。像float这样的简单类型,其内存空间内保存有值和两个元数据:
- ob_refcnt:对象的引用计数
- ob_type:指向该对象类型的指针,即指向float这个类的指针
- ob_fval:存储该float的本值,即C语言double值
64位Python解释器上,每个float占8个字节。所以一个存储float型元素的array比存储float类型的tuple简单的多。array型对象中存储的是其元素的原始值(即C语言double值),整个array是一个整体性的对象,tuple存储的是n+1个对象——包括tuple自身,和每个元素(每个元素都是对底层C语言double值的包装)
序列的另一种分类方式是根据其可变性:
- 可变序列:list、bytearray、array.array、collections.deque等
- 不可变序列:tuple、str、bytes等。
如图2-2,可变序列继承了不可变序列的所有方法,并增加了一些。内置的序列类型其实不是Sequence和MutableSequence这两个抽象基类的子类,但是它们是在这两个抽象基类上注册的虚拟子类——在13章中介绍这个概念。例如,tuple和list作为虚拟子类,可以这样测试:
>>> from collections import abc
>>> issubclass(tuple, abc.Sequence)
True
>>> issubclass(list, abc.MutableSequence)
True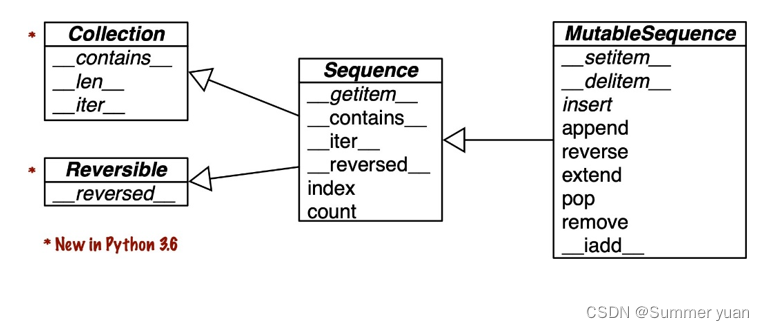
(父类在左,子类在右,箭头从子类指向父类,斜体表示的是抽象类和抽象方法)
记住这些常见概念:可变与不可变;容器型与扁平型。它们有助于根据熟悉的序列推演其他序列的特点。
最基本的序列类型是list —— 一个可变的、容器型序列。list的基础用法我们应当不陌生,下面介绍列表推导式。这是一种构建列表的强大方法,但是,初学者可能会觉得语法有点奇怪而很少使用。列表推导式可以帮助大家学习和使用生成器,而生成器可以生成元素来填充任何类型的序列。两者都是下一节的主题。
列表推导式和生成器
使用列表推导器或生成器可以快速构建list(生成器也可以构建其他序列类型)。了解他们的用法,能编写更具可读性且速度更快的代码。对于为什么“更具可读性”,下文会给出答案。
列表推导式和可读性
# 例2-1 从一段Unicode文本创建一个list
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
... codes.append(ord(symbol))
...
>>> codes
[36, 162, 163, 165, 8364, 164]
# 例2-2 从一段Unicode文本创建一个list(使用列表推导式)
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]
例2-1很易懂,但是了解列表推导式之后,将会发现示例 2-2 更具可读性,因为代码表现出来的目标意图很明确。
for 循环的功能很多:遍历序列以计数或操作元素、聚合计算(加和、平均值)或其他操作。例 2-1 中的代码用 for 构建了 list。相比之下,列表推导式的目的更明确,它就是为了建立一个新的列表而生的。
当然,滥用列表推导式可能导致写出难以理解的代码,例如只是为了重复执行一段代码(例如:[sleep(1) for i in range(10)] )。如果目标不是生成列表,就不应使用该语法。另外,尽量保持简短。如果列表推导式长度超过两行,最好将其分解或重写为普通的for 循环。使用的时候保持直觉,并没有规则说什么场合下必须用,或不能使用。
在 Python 代码中,[ ]、{ } 或 ( ) 内部的换行符将被忽略。因此,可以编写多行列表、列表推导式、元组、字典等代码,而无需使用“\”连续转义。此外,当这些括号内的元素用逗号分隔时,最后一个元素后面的逗号将被忽略(例如,[ 1, 2, 3, ] 中3后面有无逗号均可)。因此,在编写多行列表文字时,最好在最后一项后面放置一个逗号,这样下一次该列表末尾添加一项时不容易出错,读写都简便。
推导式和生成器的内部作用域
Python3中,列表推导式、生成器,以及类似的集合推导式和字典推导式中,使用for语句时,内部的变量都赋予了本地作用域。
然而,操作符“:=”(俗称海象操作符,因为旋转90度后看起来像海象的眼睛和牙齿)赋值的变量能保持到推导式和生成器之后。PEP572(赋值表达式)中定义了通过“:=”赋值的变量,作用域和封闭函数一样,除非此变量由global或非本地声明。
>>> x = 'ABC'
>>> codes = [ord(x) for x in x]
>>> x # x不会销毁,仍然等于’ABC’
'ABC'
>>> codes
[65, 66, 67]
>>> codes = [last := ord(c) for c in x]
>>> last # last仍然存活
67
>>> c # 变量c已经被销毁,它只存在与推导式内部
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'c' is not defined列表推导式可以从其他序列创建 list,并对其中的元素进行筛选和加工。Filter 和 map 两个内置函数也能实现这个功能,但是可读性很差。
列表推导式 VS map/filter
函数map和filter能做的事情,列表推导式都能做,即使前者用到了lambda。
>>> symbols = '$¢£¥€¤'
#if语句过滤掉了ascii码小于127的$字符
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
>>> beyond_ascii
[162, 163, 165, 8364, 164]性能方面,Alex Martelli 说列表推导式并不比map/filter差,最起码在上面这个例子里是这样的。本书所附代码库中的02-array-seq/listcomp_speed.py 脚本有速度测试代码(代码库下载地址:https://github.com/fluentpython/example-code-2e)。代码是:
import timeit
TIMES = 10000
SETUP = """
symbols = '$¢£¥€¤'
def non_ascii(c):
return c > 127
"""
def clock(label, cmd):
res = timeit.repeat(cmd, setup=SETUP, number=TIMES)
print(label, *(f'{x:.3f}' for x in res))
clock('listcomp :', '[ord(s) for s in symbols if ord(s) > 127]')
clock('listcomp + func :', '[ord(s) for s in symbols if non_ascii(ord(s))]')
clock('filter + lambda :', 'list(filter(lambda c: c > 127, map(ord, symbols)))')
clock('filter + func :', 'list(filter(non_ascii, map(ord, symbols)))')第7章会再次介绍 map 和 filter,下面用列表推导式获取笛卡尔积。
笛卡尔积
列表推导式可以根据两个或多个可迭代对象的笛卡尔积构建list。输入多个可迭代对象,每个可迭代对象都转换成一个元组,所有元组组合,构成笛卡尔积的元素。 生成的列表长度等于输入可迭代对象长度的乘积。 参见图 2-3。

如例2-4,一些T裇包含2种颜色和3种尺寸,代码使用列表推导式生成所有组合,共6种。
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for color in colors for size in sizes] # 生成先按颜色后按尺寸的元组排列组合的列表
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'), ('white', 'M'), ('white', 'L')]
>>> for color in colors: # 请注意嵌套的方式,在for循环和列表推导式中出现的顺序一样
... for size in sizes:
... print((color, size))
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
>>> tshirts = [(color, size) for size in sizes # 若要让元素先按尺寸排列,然后按颜色排列,只需调整for 子句即可。推导式中添加换行符可以更轻松地查看结果的排序方式。
... for color in colors]
>>> tshirts
[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'), ('black', 'L'), ('white', 'L')]第1章例1-1中,使用列表推导式生成了一副扑克牌,13个点数和4种花色生成了52张牌,顺序是先花色,后点数。
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]列表推导式唯一的功能是创建list。生成其他序列类型,就需要用到生成器。下节开始其用途。
生成器
构建tuple、array或其他序列,除了使用推导式,还可以用生成器。生成器是依据迭代协议一个元素接一个元素生成的,而不是一下创建出所有元素,所以更加节省资源。生成器和推导式的语法一致,但是使用小括号而不是中括号。
例2-5创建了一个tuple和array。
例2-5 生成器创建tuple和array
>>> symbols = '$¢£¥€¤'
>>> tuple(ord(symbol) for symbol in symbols) # 函数调用中,若生成器是唯一参数,没必要在外面再添加括号
(36, 162, 163, 165, 8364, 164)
>>> import array
>>> array.array('I', (ord(symbol) for symbol in symbols)) # 数组构造函数需要两个参数,因此生成器表达式外必须加括号。 数组构造函数的第一个参数定义了数组中数字的存储类型
array('I', [36, 162, 163, 165, 8364, 164])例2-6使用生成器由2种颜色和3种尺寸得出笛卡尔积的T裇规格。与示例 2-4 相比,这里生成的6项T裇不会在内存中构建:for语句每运行一次循环,生成器就提供一个元素。如果向笛卡尔积输入的两个list各有一千个项目,使用生成器表达式将节省构建包含一百万个元素列表的内存成本。
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> for tshirt in (f'{c} {s}' for c in colors for s in sizes): # 生成器一个接一个地生成元素,不会一下创建6个元素
... print(tshirt)
...
black S
black M
black L
white S
white M
white L此处只展示创建列表的生成器方式,及其节省内存的特性。17章阐述了生成器的原理。
现在,转而关注另一种序列——tuple。
tuple不仅仅是不可变的list
有的人把tuple解释为不可变的list,这可小看它了。tuple有两种功能:可用作不可变列表;可以作为无名记录集。第二个用途经常被忽略掉,在此介绍一下。
tuple作为记录集
tuple保存记录集时:每个tuple对象保存一条记录,对象内依靠各元素的顺序区分各字段。
当把tuple当作不可变列表时,各元素的顺序可能有用也可能没用。但是当把tuple当作记录集时,元素顺序则是重要的信息。
例2-7是tuple作为记录集使用的例子。注意对tuple元素重新排序将损毁数据信息,因为顺序是数据正确性的一部分。
>>> lax_coordinates = (33.9425, -118.408056) # 洛杉矶的经纬度
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32_450, 0.66, 8014) # 东京的名称、年份、人口/千人、人口增长率/%、面积/平方千米
>>> traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), # 元组(国代码,护照代码)的列表
... ('ESP', 'XDA205856')]
>>> for passport in sorted(traveler_ids): # list遍历,护照信息存入tuple
... print('%s/%s' % passport) # 操作符%参数传入tuple,将各元素插入对应位置
...
BRA/CE342567
ESP/XDA205856
USA/31195855
>>> for country, _ in traveler_ids: # for语句中解包tule,内部元素对应赋值给两个变量,第二个变量名是“_”,代表后面用不到这个数值
... print(country)
...
USA
BRA
ESP用“_”表示无用的变量是约定俗成的习惯,“_” 是个一般不会用到但合法的变量名。在Python控制台,上例中的“_”会被赋值。但是在match/case语句中,“_”是个通配符,可以匹配任何值,参考“序列的模式匹配”节。
有时候需要记录集数据携带字段名,第5章介绍了两种方法创建带字段名的tuple。
一般情况下,没必要为了带字段名创建类,尤其是可以通过元素索引位置来对应记录的字段。例2-7中元组 ('Tokyo', 2003, 32_450, 0.66, 8014) 对应赋值给了city、year、pop、chg、area字段。然后,操作符“%”将各元素一一对应地映射给字符串的对应位置。这是tuple解包两种用法的示例。
经常用到的是元组解包,但还会用到可迭代类型解包,如PEP3132的标题所称——扩展可迭代解包。
“解包序列和可迭代类型”一节介绍了tuple之外的序列类型和可迭代类型的解包。
tuple作为不可变的list
Python解释器和标准库的源代码中充分发挥了tuple作为不可变list的作用。它有两个关键优势:
- 代码清晰:当看到tuple时就知道长度不可变。
- 性能:tuple比list更节省内存,Python解释器还会专门优化。
但是,时刻注意tuple只保证存储的对象引用不可变。tuple内的引用不能删除或改变,但是如果引用所指向的实际对象是可变的,一旦目标对象改变时,tuple的值也变了。下段代码说明了这一点,a和b的初始值是相等的,图2-4描述了b的内存结构。
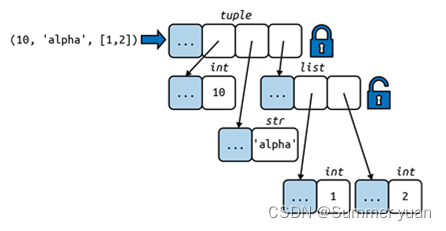
改变b最后一个元素后,就和a的值不同了。
>>> a = (10, 'alpha', [1, 2])
>>> b = (10, 'alpha', [1, 2])
>>> a == b
True
>>> b[-1].append(99)
>>> a == b
False
>>> b
(10, 'alpha', [1, 2, 99])tuple允许其元素可变就像个bug。参考 “什么是可哈希” 一节,只有值不可变的情况下才叫可哈希。只有可哈希的tuple(即不包含可变类型元素的tuple)才能作为dict的键或set的元素。
如果想要检测一个tuple或其他对象是否不可变,可以用内置的hash函数写一个fixed函数(对于可哈希对象,hash函数返回计算出的哈希值;对于不可哈希的对象,抛出TypeError异常):
>>> def fixed(o):
... try:
... hash(o)
... except TypeError:
... return False
... return True
...
>>> tf = (10, 'alpha', (1, 2))
>>> tm = (10, 'alpha', [1, 2])
>>> fixed(tf)
True
>>> fixed(tm)
False
在“tuple的相对不可变性” 一节中在讨论这个问题。
尽管有这个坑,但是tuple仍被广泛用作不可变列表。它们有性能优势,Python 核心开发人员 Raymond Hettinger 在 StackOverflow 回答“Python 中的元组比列表更高效吗?”问题时对此进行了解释:
- tuple转化为字面量时,Python 编译器把整体元组整体一次性生成字节码; 但对于list,将对每个元素生成字节码,写入到数据堆栈,然后构建列表。
- 给定一个元组t,tuple(t)返回对同一t 的引用。 无需复制本对象。相反,给定列表 l,list(l) 构造函数将创建 l 的新副本。
- 由于其固定长度,元组实例会被分配其所需的确切的内存空间。 另一方面,列表的实例分配有备用空间,以分摊未来追加元素的成本。
- tuple中,子元素的引用保存在tuple数据结构内的数组中,而list把元素的引用保存在其他内存空间的数组中,list的数据结构保存这个数组的指针。这样的间接存储是必要的,因为当列表增长超出当前分配的空间时,Python 需要重新分指针指向的数组以腾出空间。 额外的间接寻址会降低 CPU 缓存的效率。
tuple和list方法的对比
因为tuple多数时候可以当作不可变list,所以他们有一部分API很相似。如表2-1,tuple支持list类型中除了增删元素、反转顺序之外的所有方法。而且,tuple虽然没有反转方法__reversed__,但可以通过reversed(my_tuple)返回tuple的反转结果(实际上返回一个迭代器)。
| 方法 | list | tuple | 说明 |
|---|---|---|---|
| s.__add__(s2) | ● | ● | s + s2—>合并 |
| s.__iadd__(s2) | ● | s += s2—>复合合并,相当于s=s+s2 | |
| s.append(e) | ● | 在末尾追加元素 | |
| s.clear() | ● | 清空所有元素 | |
| s.__contains__(e) | ● | ● | s是否包含e |
| s.copy() | ● | 浅拷贝 | |
| s.count(e) | ● | ● | 计算e在s内出现的次数 |
| s.__delitem__(p) | ● | 删除位置在p的元素 | |
| s.extend(it) | ● | 将可迭代对象it的元素追加到s末尾 | |
| s.__getitem__(p) | ● | ● | s[p]—通过下标访问元素 |
| s.__getnewargs__() | ● | 对pickle 序列化提供支持 | |
| s.index(e) | ● | ● | 返回元素e在s中第一次出现的位置 |
| s.insert(p, e) | ● | 在位置p的元素前插入e | |
| s.__iter__() | ● | ● | 获取迭代器 |
| s.__len__() | ● | ● | len(s)—元素数量 |
| s.__mul__(n) | ● | ● | s * n—序列重复n次合并 |
| s.__imul__(n) | ● | s *= n—复合重复合并 | |
| s.__rmul__(n) | ● | ● | n * s—逆向运算的重复合并 |
| s.pop([p]) | ● | 删除并返回p位置的元素,不传入p时删除并返回最末尾元素 | |
| s.remove(e) | ● | 返回第一个等于e的元素 | |
| s.reverse() | ● | 反转元素顺序 | |
| s.__reversed__() | ● | 获取反转顺序的迭代器 | |
| s.__setitem__(p, e) | ● | s[p] = e—将p位置的元素赋值为e | |
| s.sort([key], [reverse]) | ● | 使用可选的参数key、reverse进行排序(key是排序规则函数,reverse控制是否倒序) |
下节讨论Python编程中的通常用法:tuple、list和可迭代对象的解包。
序列和可迭代对象的解包(unpacking)
解包很有用,它可以避免从序列中获取元素时搞错索引位置。 此外,解包可以使用任何可迭代对象作为数据源,包括不支持索引取值 ([ ]) 的迭代器。 唯一的要求是有足量的变量去接收和对应生成的元素,除非使用星号 (*) 捕获多余的项目,如下一节“使用 * 捕获多余的项目”中所述。
最容易看懂的解包形式是平替赋值(原文叫做并行赋值,意思是将一个序列的元素一一对应地赋值给另一个序列对象);也就是说,将可迭代项中的元素分配给变量元组,如本例所示:
>>> lax_coordinates = (33.9425, -118.408056)
>>> latitude, longitude = lax_coordinates # 解包
>>> latitude
33.9425
>>> longitude
-118.408056使用解包,可以优雅地交换两个变量值,而摒弃了中间变量的做法:
>>> b, a = a, b解包的另一个用法是调用函数时使用带 “*” 的变量将其子元素传递给多个形参:
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)
>>> quotient, remainder = divmod(*t)
>>> quotient, remainder
(2, 4)上面代码还演示了解包的另一个用处:函数可以一次性返回多个值。再比如,函数os.path.split()可以将一个表示文件路径的字符串拆分成一个元组(path, last_part):
>>> import os
>>> _, filename = os.path.split('/home/luciano/.ssh/id_rsa.pub')
>>> filename
'id_rsa.pub'如果只需要获取其中一部分元素,可以用 “*” 语法。
使用 “*” 符号获取多余元素
Python中编写函数的一个通常做法是使用 *args 接收任意个数的参数。
Python3中,这种做法也适用于平替赋值方式的解包:
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])平替赋值中,“*”只能加在其中一个变量前,但是对这个变量的位置没有要求:
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)在函数调用和序列字面量中使用 * 进行解包
PEP 448《解包的其他说明》中引入了更灵活的可迭代对象解包语法, “Python 3.5 的新增功能”中也介绍了它。
函数调用中可以使用多个 “*”:
>>> def fun(a, b, c, d, *rest):
... return a, b, c, d, rest
...
>>> fun(*[1, 2], 3, *range(4, 7))
(1, 2, 3, 4, (5, 6))
“Python 3.5 的新增功能”中举了一些例子,“*”可以用在list、tuple或set的字面量中:
>>> *range(4), 4
(0, 1, 2, 3, 4)
>>> [*range(4), 4]
[0, 1, 2, 3, 4]
>>> {*range(4), 4, *(5, 6, 7)}
{0, 1, 2, 3, 4, 5, 6, 7}PEP448还介绍了相似的 “**” 语法,将会在“解包映射类型”一节讨论。
解包的强大还在于可以递归式解包。
递归解包
被解包的序列可以嵌套,例如 (a, b, (c, d))。接收值的变量嵌套结构要和解包对象的嵌套结构一致。例2-8演示嵌套解包。
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
] # 每个元组有4个元素,其中最后一个包含一对经纬度值
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for name, _, _, (lat, lon) in metro_areas: # 为经纬度传递嵌套的元组,获取其值
if lon <= 0: # 只筛选出西半球的城市
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if name == ' main ':
main()
例2-8的输出是:
| latitude | longitude
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
São Paulo | -23.5478 | -46.6358
解包赋值语句的左值(即等号左边被赋值的部分)也可以是列表,但很少见。唯一一种情况是: 如果数据库查询只返回一条记录(例如,SQL语句中有 LIMIT 1 子句),那么就可以使用此代码解包这条唯一记录:
>>> [record] = query_returning_single_row()如果这条唯一记录只有一个字段,可以直接获取到这一字段的值,如下所示:
>>> [[field]] = query_returning_single_row_with_single_field()这两个语句的左值都可以用元组来写,但不要忘了一个语法问题,那就是单元素元组必须在元素后加逗号。因此,第一段代码左值是(record,),第二个段代码左值是((field,),)。如果不加逗号,就会出现bug,而代码并不会报错提醒你。
现在我们来研究模式匹配,它支持更强大的解包序列的方法。
序列模式匹配
Python 3.10 中最明显的新特性是使用 match/case 进行模式匹配,这是在PEP 634《结构模式匹配:规范》中提出的。
Python 核心开发者 Carol Willing 在 "Python 3.10 新特性 "的 " 结构模式匹配 "部分写了一篇关于模式匹配的精彩介绍,有兴趣可以阅读一下。在本书中,根据不同的模式类型, 将模式匹配分为不同的章节:映射类型的模式匹配和类实例的模式匹配。见 18章中"lis.py 中的模式匹配:案例研究 "的扩展示例。
下面是用match/case处理序列的例子。假设设计一个机器人,它可以接受以单词和数字组成的序列发送的指令,比如 “BEEPER 440 3”。将指令分割,会得到如下信息:[' BEEPER', 440, 3]。下列方法可以达到目的:
例 2-9 Robot类的一个方法
def handle_command(self, message):
match message: # match后是待比较的数据,将尝试与每个case子句的值进行对比
case ['BEEPER', frequency, times]: # 此模式是包含3个元素的序列,其中第一项必须是"BEEPER",
#后两项可以是任意值,且后两个值会赋值给两个变量:frequency, times
self.beep(times, frequency)
case ['NECK', angle]: # 匹配第一项是“NECK”的二元素序列
self.rotate_neck(angle)
case ['LED', ident, intensity]: # 匹配第一项是“LED”的三元素序列
self.leds[ident].set_brightness(ident, intensity)
case ['LED', ident, red, green, blue]: # 匹配第一项是“LED”的五元素序列
self.leds[ident].set_color(ident, red, green, blue)
case _: # 默认分支,用于以上条件都不匹配的情况。“_”是个特殊变量
raise InvalidCommand(message)
match/case 与 C 语言中的 switch/case 语句相似,但这只是表象。与 switch 相比,match 的一个关键改进是 解构赋值(destructuring,一种更高级的解包形式)。在 Python中," 解构赋值 "是一个新概念,但它在支持模式匹配的语言(如 Scala 和 Elixir)文档中很常用。
《流畅的Python》作者认为,if/elif/elif/.../else 语句可以很好地替代 switch/case。它不会出现多次匹配和匹配落空的问题,而这些问题是某些语言设计者从 C 语言中无脑搬运造成的。
例 2-10用 match/case 重写了例 2-8 的一部分代码。
例 2-10 嵌套元组的解构赋值(Python ≥ 3.10)
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record: # 待匹配数据record,是metro_areas内包含的每个元组
case [name, _, _, (lat, lon)] if lon <= 0: # case分支语句有两部分,模式匹配部分和if条件过滤部分
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')match/case语句的语法如下: match subject: ->subject是待比较的数据,为避免翻译误差,下文直接用英文subject case <pattern_1>: ->case后的表达式或值是匹配模式,下文称为模式或pattern <action_1> case <pattern_2>: <action_2> …… case _: <action_wildcard>
一般来说,如果同时出现以下情况,序列pattern会与subject相匹配:
- subject是一个序列,并且:
- subject和pattern的元素数相同;
- 每个相应位置的元素都匹配,包括嵌套在内部的元素。
例 2-10 中的pattern: [name, _, _, (lat, lon)] 能够匹配包含四个元素的序列,且最后一个元素是包含两个元素的序列。
序列pattern可以写成元组或列表,也可以写成嵌套元组和列表的任意组合,两种语法并无区别,所以说,在序列pattern中,方括号和括号的含义是一样的。在例 2-10中,为了避免重复使用方括号或圆括号,将pattern写成了列表内部嵌套元组的形式。
序列pattern可以匹配 collections.abc.Sequence 的大多数抽象或非抽象子类的实例,但str、bytes 和 bytearray 除外。
提醒:在 match/case 中,str、bytes 和 bytearray 的实例不会作为序列处理。这些类型的待匹配subject被视为 "原子 "值,而不是字母/字节序列。如果要将这些类型的对象作为序列subject,请在match语句中进行转换。例如,请参阅下面的 tuple(phone):
match tuple(phone):
case ['1', *rest]: # 北美、拉美区号
...
case ['2', *rest]: # 非洲、加拿大区号
...
case ['3' | '4', *rest]: # 欧洲区号
...在标准库中,这些类型可用作序列pattern:列表、内存视图、array.array、tupler、ange、collections.deque
与拆包不同,pattern不会对可迭代对象进行解构赋值(如迭代器,即不会遍历迭代器)。
符号“_”在pattern中比较特殊:它可以匹配该位置上的任何一个元素,但永远不会与匹配项的值绑定(即_不会被赋值)。此外,_在pattern中可以出现多次,也是唯一一个可以在同一个pattern表达式中出现多次的变量。
可以使用 as 关键字将pattern的任何部分起一个别名变量,例如:
case [name, _, _, (lat, lon) as coord]:对于数据 ['Shanghai', 'CN', 24.9, (31.1, 121.3)],可以与上述pattern匹配成功,并设置以下变量:
name -> 'Shanghai'
lat -> 31.1
lon ->121.3
coord->(31.1, 121.3)
我们可以通过添加类型信息使pattern更加具体。例如,下面这个pattern匹配的序列嵌套结构与上一个例子相同,但第一个项必须是 str 类型,而最后的元组中的两个元素都必须是 float 类型:
case [str(name), _, _, (float(lat), float(lon))]:表达式 str(name) 和 float(lat) 看起来像是构造函数调用,将 name 和 lat 转换为 str 和 float。但在模式匹配的上下文中,该语法执行运行时类型检查:前面的pattern将匹配一个四元素序列,其中第一个元素必须是 str,第四个元素必须是一对浮点数。此外,第一个元素的值将赋给 name 变量,第四个元素的2个浮点数将分别赋值给 lat 和 lon。因此,虽然 str(name) 与构造函数调用的写法雷同,但其语义在pattern中却完全不同。第5章的"模式匹配类实例 "一节将介绍如何在pattern中使用任意类。
再者,如果要匹配以 str 开始、以两个浮点数嵌套序列结束的任何序列(不限制中间其他元素的数量),我们可以这样写 :
case [str(name), *_, (float(lat), float(lon))]:*_ 可以匹配任意数量的元素,而无需将它们赋值给变量。如果使用*extra 替换 *_ ,会将中间的所有元素归集给 extra ,使其成为一个有 0 个或多个元素的列表。
以 if 开头的过滤子句只有在模式匹配时才会运算,并且可以引用pattern表达式中已赋值的变量,如例 2-10 所示:
match record:
case [name, _, _, (lat, lon)] if lon <= 0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')只有当模式匹配且过滤子句为真值时,才会运行打印代码块。
使用模式匹配进行解构赋值的功能强大,有时只用一个case分支条件就能完成功能,代码看起来很简洁。Guido van Rossum 收集了一些match/case用法示例,其中包括一个名为 "非常深的可迭代对象和类型的匹配提取 "的示例。
例 2-10 并不是对例 2-8 的改进。它只是用来对比做同一件事的两种方法。下一个示例展示了模式匹配如何有助于编写清晰、简洁和有效的代码。
解释器中的模式匹配序列
斯坦福大学的 Peter Norvig 用 132 行漂亮易读的 Python 代码写了 lis.py:一个 Lisp 编程语言子集的解释器。作者采用了 Norvig 的 MIT 许可下的源代码,并将其更新到 Python 3.10 版本,以展示模式匹配。本节将比较Norvig 代码的一个关键部分:使用if/elif 和解包,与使用 match/case 重写的代码。
lis.py 的两个主要函数是 parse和evaluate(在 Norvig 的代码中名为 eval;为了避免与 Python 的内置 eval 混淆,重新命名了它)。parse传入带有括号格式的表达式,返回list类型。下面是两个例子:
>>> parse('(gcd 18 45)')
['gcd', 18, 45]
>>> parse(''' (define double (lambda (n) (* n 2))) ''')
['define', 'double', ['lambda', ['n'], ['*', 'n', 2]]]evaluate函数传入上述list结果,并执行它们。第一个例子是调用一个以 18 和 45 为参数的 gcd 函数,evaluate会计算出2个参数的最大公约数:9。第二个例子是定义一个名为 double 的函数,参数为 n,函数体是 (* n 2)。按照Lisp语法,调用此函数的结果是返回函数体中最后一个表达式的值。
这里的重点是序列的解构赋值,此处不解释evaluate的操作。请参阅 "lis.py 中的模式匹配:案例研究",了解有关 lis.py 的更多信息。
例2-11显示了对Norvig的代码稍作修改后的evaluate,只显示序列模式匹配,略去了其他代码。
例 2-11.不使用 match/case 的匹配模式
def evaluate(exp: Expression, env: Environment) -> Any:
"Evaluate an expression in an environment."
if isinstance(exp, Symbol): # 符号变量
return env[exp]
# ... 省略部分行
elif exp[0] == 'quote': # (quote 语句)
(_, x) = exp
return x
elif exp[0] == 'if': # (if 语句后跟断言对象和两个选项值)
(_, test, consequence, alternative) = exp
if evaluate(test, env):
return evaluate(consequence, env)
else:
return evaluate(alternative, env)
elif exp[0] == 'lambda': # (lambda (parm…) body…)
(_, parms, *body) = exp
return Procedure(parms, body, env)
elif exp[0] == 'define':
(_, name, value_exp) = exp
env[name] = evaluate(value_exp, env)
# ... 更多行省略请注意每个 elif 子句的操作:检查列表的第一个元素,然后解包列表,并忽略第一个元素。大量使用解包表明Norvig 很喜欢用模式匹配,代码最初是为 Python 2 编写这段代码的(现在经过改写可以在 Python 3 上运行)。
使用 Python ≥ 3.10 中的 match/case,我们可以重构evaluate,如例2-12所示。
例 2-12.使用 match/case 进行模式匹配( Python ≥ 3.10)
def evaluate(exp: Expression, env: Environment) -> Any:
"Evaluate an expression in an environment."
match exp:
# ... 省略部分行
case ['quote', x]: # 如果exp含2个元素,第一个元素是'quote'
return x
case ['if', test, consequence, alternative]: # 如果exp含4个元素,第一个元素是'if'
if evaluate(test, env):
return evaluate(consequence, env)
else:
return evaluate(alternative, env)
case ['lambda', [*parms], *body] if body: # 如果exp含3个或3个以上元素,第一个元素是lambda',
# if条件语句确保body不能为假值
return Procedure(parms, body, env)
case ['define', Symbol() as name, value_exp]: # 如果exp含3个元素,第一个元素是'define',第二个元素是Symbol对象
env[name] = evaluate(value_exp, env)
# ...省略部分行
case _: # 书写兜底情况的分支语句是个好习惯。以上条件都不匹配时执行此分支,此处手动抛出SyntaxError
raise SyntaxError(lispstr(exp))
如果没有最后的兜底条件分支,当subject不匹配任何pattern时,整个match语句就什么也不做——这可能是一个不期望的结果,但不会报错引起你的注意。
Norvig 在 lis.py 中省略了错误检查,以保持代码易于理解。有了模式匹配, 我们可以添加更多检查,并保持代码的可读性。例如,在 "define "模式中,原始代码并没检查 name 是否 Symbol 的实例,这就需要用if、isinstance和更多代码来判断。例2-12比2-11更简短、更安全。
模式匹配替代lambda
在Lisp的lambda语法中,后缀“...”意味着该元素可能出现零次或多次:
(lambda (parms…) body1 body2…)如果把分支'lambda'语句简写成下面这样,就会出现问题:
case ['lambda', parms, *body] if body: # 有bug的简写它的问题在于parms 位置可以匹配任何值,包括下面这个有问题的语句中的第一个 "x":
['lambda'、'x'、['*'、'x'、2]]按照Lisp语法规范,lambda 关键字后的 list 保存了函数的形参名称,即使只有一个元素,也是一个 list。如果函数不带参数,它也可以是一个空list,例如 Python 的 random.random()。
在例2-12中,使用嵌套list模式使 "lambda "模式更加安全:
case ['lambda', [*parms], *body] if body:
return Procedure(parms, body, env)在序列pattern中,每个序列只能出现一次 *。这里我们有两个序列:外部序列(包含'lambda'、[*parms]、 *body三个元素的list)和内部序列(包含 *parms 元素数量不定的list)。
在 parms 前添加*并使用“[ ]”包裹起来,使pattern语句更符合Lisp语法规范,并为我们提供了额外的结构检查。
函数定义的快捷语法
Lisp语法规范有另一种语法,使用define关键字可以在不使用lambda 的情况下创建命名函数。语法如下:
(define (name parm...) body1 body2...)
define关键字后是一个包含函数名称和形参列表的list(形参可以是0个或多个)。再之后是包含若干表达式的函数体。
将这两行添加到match代码段中就可以实现了:
case ['define', [Symbol() as name, *parms], *body] if body:
env[name] = Procedure(parms, body, env)
在例2-12 中把这个case语句放在了另一个”define“分支之后。在本例中,各分支语句的顺序无关紧要,因为一个subject不会同时匹配这两种pattern:另一个”define“分支,define后的元素必须是一个Symbol对象,但在此处改写后的define分支中,是一个以Symbol对象开头的序列。
现在考虑一下,如果例2-11中不使用模式匹配,添加第二个define需要费不少周章。match语句的功能比在类 C 语言中的switch语句强大得多。
模式匹配是声明式编程的一个例子:代码表达的是你想匹配 "什么",而不是 "如何 "匹配。如表2-2 所示,代码的结构根据数据的结构而定。
| 语法形式 | 序列模式 |
| (quote exp) | ['quote', exp] |
| (if test conseq alt) | ['if', test, conseq, alt] |
| (lambda (parms…) body1 body2…) | ['lambda', [*parms], *body] if body |
| (define name exp) | ['define', Symbol() as name, exp] |
| (define (name parms…) body1 body2…) | ['define', [Symbol() as name, *parms], *body] if body |
希望通过对Norvig 代码的重构,能让你相信match/case更可读、更安全。
我们将在"lis.py 中的模式匹配案例研究 "中进一步了解 lis.py,通过evaluate的代码完整展示match/case。如果想更多地了解 Norvig 的 lis.py,请阅读他的精彩博文"(如何用 Python 写一个Lisp解释器)"。
至此,序列的拆包、解构赋值和模式匹配的首次学习就告一段落了。在以后的章节中将会介绍其他类型的模式。
每个 Python 程序员都知道序列的 s[a:b]切片,现在来谈谈关于切片的一些不太为人所知的事实。
切片
在 Python 中,list、tuple、str 和所有序列类型的一个共同特征是支持切片操作,而切片操作比你想象中要强大得多。
在本节中,我们将介绍高级切片的使用。第 12 章将介绍如何在用户定义的类中实现这些功能,因为本书的这一部分介绍内置类,而第三部分介绍自定义类。
为什么切片和range不包括最后一个元素
例如,s[1:3]不包含索引为3的元素,range(1,3)不包含3这个值。
切片和range不包含最后一个元素,是为了配合索引从0开始的机制, Python、C 和许多其他语言都如此。该约定的一些便利性如下:
- 当只给出终点位置时,很容易看出切片或range的长度:range(3) 和 my_list[:3] 都包含三个元素。
- 如果给定了起点和终点,切片或range的长度很容易计算:只需终点 - 起点即可。
- 很容易在任意索引 x 处将序列分成两部分,且不会重叠:直接划分成my_list[:x]和 my_list[x:]。例如:
>>> lst = [10, 20, 30, 40, 50, 60]
>>> lst [:2] # 在 2 处分割
[10, 20]
>>> lst [2:]
[30, 40, 50, 60]
>>> lst [:3] # 在 3 处分割
[10, 20, 30]
>>> lst [3:]
[40, 50, 60]荷兰计算机科学家 Edsger W. Dijkstra为这一约定提出了最好的论据。
Edsger W. Dijkstra在题为 "为什么索引应该从0开始 "的备忘录,解释为什么Python有在切片和range中排除最后一项的习惯。备忘录标题是“从0开始索引”,但备忘录实际上是关于说明为什么用'ABCDE'[1:3]表示'BC'而不是'BCD',以及为什么将 range(2, 13)产生 2、3、4......12 是完全合理的。顺便说一句,备忘录是手写的但它非常漂亮,完全可以阅读。Dijkstra 的字迹非常清晰,以至于有人用他的笔记创建了一种字体。
现在让我们仔细看看 Python 是如何规定切片操作的。
切片对象
关于切片,再说明一下:s[a:b:c]指定了步长c,使生成的切片跳过部分元素。步长也可以是负数,即以相反的方向切出元素。有三个例子可以说明这一点:
>>> s = 'bicycle'
>>> s[::3]
'bye'
>>> s[::-1]
elcycib
>>> s[::-2]
eccb另一个例子见第 1 章,当时我们用deck[12::13]得到了牌垛中的所有" A":
>>> deck[12::13]
[Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'),
Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]a:b:c 的写法只有在 [ ] 中用作索引或下标操作符时才是合法的,它产生一个slice 对象:slice(a, b, c)。正如我们将在后文"切片是如何工作的 "中看到的, Python解析表达式 seq[start:stop:step] 时,调用 seq. getitem (slice(start,stop,step))。了解切片对象是很有用的,它可以为切片命名,就像一个班级内可以为一个兴趣小组命名一样。
假设您需要解析扁平结构文件的数据,如例2-13中所示的发票。与其在代码中硬编码切片,不如为它们命名。这让代码末尾的 for 循环变得非常易读。
>>> invoice = """
... 0.....6...........................40.......52..55.......
... 1909 Pimoroni PiBrella $17.50 3 $52.50
... 1489 6mm Tactile Switch x20 $4.95 2 $9.90
... 1510 Panavise Jr. - PV-201 $28.00 1 $28.00
... 1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
... """
>>> SKU = slice(0, 6)
>>> DESCRIPTION = slice(6, 40)
>>> UNIT_PRICE = slice(40, 52)
>>> QUANTITY = slice(52, 55)
>>> ITEM_TOTAL = slice(55, None)
>>> line_items = invoice.split('\n')[2:]
>>> for item in line_items:
... print(item[UNIT_PRICE], item[DESCRIPTION])
...
$17.50 Pimoroni PiBrella
$4.95 6mm Tactile Switch x20
$28.00 Panavise Jr. - PV-201
$34.95 PiTFT Mini Kit 320x240当我们在第12章"Vector Take #2:可切分的序列 "一节中讨论自定义集合时, 将再次讨论切片对象。同时,从用户角度来看,切片还包括其他功能,如多维切片和省略号(...)符号。
多维切片和省略号对象
[ ]操作符内也可以使用逗号分隔的多个索引值或切片。[ ] 操作符在后台调用 __getitem__ 和 __setitem__ 魔术方法,从而将多个参数打包成元组作为参数传入。换句话说,Python把a[i,j]表达式转为调用 a.__getitem__((i, j))。
例如,在NumPy 软件包中,可以使用语法 a[i, j] 获取二维numpy.ndarray 中的项,并通过表达式 a[m:n, k:l] 获得二维切片。本章后面的例2-22 展示了这种使用方法。
除了memoryview,Python 的内置序列类型都是一维的,因此它们只支持一个索引或切片参数,而不支持上文所说的元组参数。
a[i,j](相当于a[(i,j)])其实是在二维数组中取了第i行、第j列的一个元素,因此不要混淆了a[i,j]和a[i:j]的区别,前者取的是一个元素,后者是对一维序列的切片。
省略号是用三个英文的句号 (...)而不是中文的半个省略号…(Unicode U+2026)写成的(其实中文的省略号也是合法的Python标记符,可以作为变量名)。它是 Ellipsis 对象的别名,是 ellipsis 类的唯一实例(ellipsis是类,Ellipsis是这个类的实例对象,首字母大小写的区别不要搞混)。因此, 它可以作为参数传递给函数,也可以作为切片的一部分, 如f(a, ..., z) 或 a[i:...]。在对多维数组进行切片时,NumPy 使用...作为快捷方式,例如,如果 x 是四维数组,x[i, ...] 是 x[i, :, :, :,] 的快捷方式。请参阅 "NumPy快速入门 "了解更多相关信息。
在撰写本文时, Python 标准库中的数据类型还没有 Ellipsis 或多维索引和切片的使用。如果您发现了,请告诉我。这些语法特性的存在是为了支持用户定义的类型和扩展,例如 NumPy。
切片不仅能从序列中提取数据,还能用于可变序列的就地更改,无需创建新对象。
为切片赋值
切片放在赋值语句的左侧或作为 del 语句的操作数,可以对可变序列进行就地修改、切除或其他编辑。接下来的几个示例让我们观察其强大功能:
>>> lst = list(range(10))
>>> lst
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst[2:5] = [20, 30] # 删除索引2、3、4的三个元素,替换为20、30两个元素
>>> lst
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del lst[5:7]
>>> lst
[0, 1, 20, 30, 5, 8, 9]
>>> lst[3::2] = [11, 22]
>>> lst
[0, 1, 20, 11, 5, 22, 9]
>>> lst[2:5] = 100 # 赋值的目标是切片时,右侧必须是迭代对象,即使它只有一个元素
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> lst[2:5] = [100]
>>> lst
[0, 1, 100, 22, 9]本篇到此为止吧,这一章的内容太多,分两次发文。















 2634
2634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









