






随着网络的迅速发展,万维网成为大量信息的载体,我们如何有效地提取并利用这些信息呢?那么就不得不提到一个概念——“网络爬虫”
1.网络爬虫
1.1概念
网络爬虫(英文名叫 Web crawler 或 Spider)。
它是一种自动化抓取互联网信息的程序,也是搜索引擎的核心组成部分。网络爬虫可以根据指定的规则,从互联网上下载网页、图片、视频等内容,并抽取其中的有用信息进行处理。
网络爬虫的工作流程包括获取网页源代码、解析网页内容、存储数据等步骤。
简单来说,爬虫就是抓取目标网页信息的工具。
1.2原理

1.3基本流程

1.4爬虫语言
PHP,C++,JAVA,Python
[而这里使用的语言是Python]
使用python编写的爬虫脚本可以完成定时、定量、指定目标(Web站点)的数据爬取。主要使用多(单)线程/进程、网络请求库、数据解析、数据存储、任务调度等相关技术。
1.5实际应用
- 搜索引擎索引
- 数据采集和挖掘
- 网站更新检测
- 网络监控与安全
- 学术研究
既然我们刚刚提到了利用Python来完成我们的爬取数据,那么就要安装、配置以及使用Python了。
2.Python
2.1安装环境
附上大佬链接:http://t.csdn.cn/Fxdm7
2.2基础教程
在学习Python中,也不妨多练点手。
3.网页采集
3.1利用开发者模式获取信息
开发者模式打开的三种方法:
- Chrome菜单→更多工具→开发者着工具
- 快捷键F12(fn+F12) Ctrl+shifi+i
- 鼠标右击→检查
3.2举例:
(1)网页图片采集
首先进入开发者模式获取我们需要的信息(url地址、请求头、请求方式)
附图:

插个题外话,在运行我们的Python脚本时,结果会出现一个200的数据,这就是回馈给我们的状态代码。如果状态代码是200的话,代表成功状态响应码指示请求已成功。
我们平时常见的404也是状态代码,指客户端错误响应代码指示服务器找不到请求的资源。
附上状态代码方面的知识链接:
https://cloud.tencent.com/developer/section/1190192
关于请求头方面的知识链接:
HTTP请求头之User-Agent组成及常用例子_http_user_agent_东方虫的博客-CSDN博客
然后安装request库
request库是用Python语言编写,用于访问网络资源第三方库,基于urllib更加简单人性化
接着,我们导包,把所需要的图片的地址写入python里,用request包加载图片地址,设置好图片名字和写入格式,最后用字节的/二进制的方式写入图片
#导包
import requests
#图片地址
img_url='https://gss0.baidu.com/-4o3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/5fdf8db1cb134954adb02775544e9258d1094a71.jpg'
#使用requests的get请求加载图片
re = requests.get(img_url)
#设置图片名和写入格式
img_file=open('hhh.jpg','wb')
#以字节的/二进制的方式写入文件
img_file.write(re.content)
注意点:
问:为什么使用二进制和字节来读取图片?
答:这种方式可以大大降低读取文件时的IO操作,提高读取图片的速度,尤其在需要处理多张大型图片的情况下表现更加优秀。
点击运行就成功获取到我们所需要的图片了
最终结果:
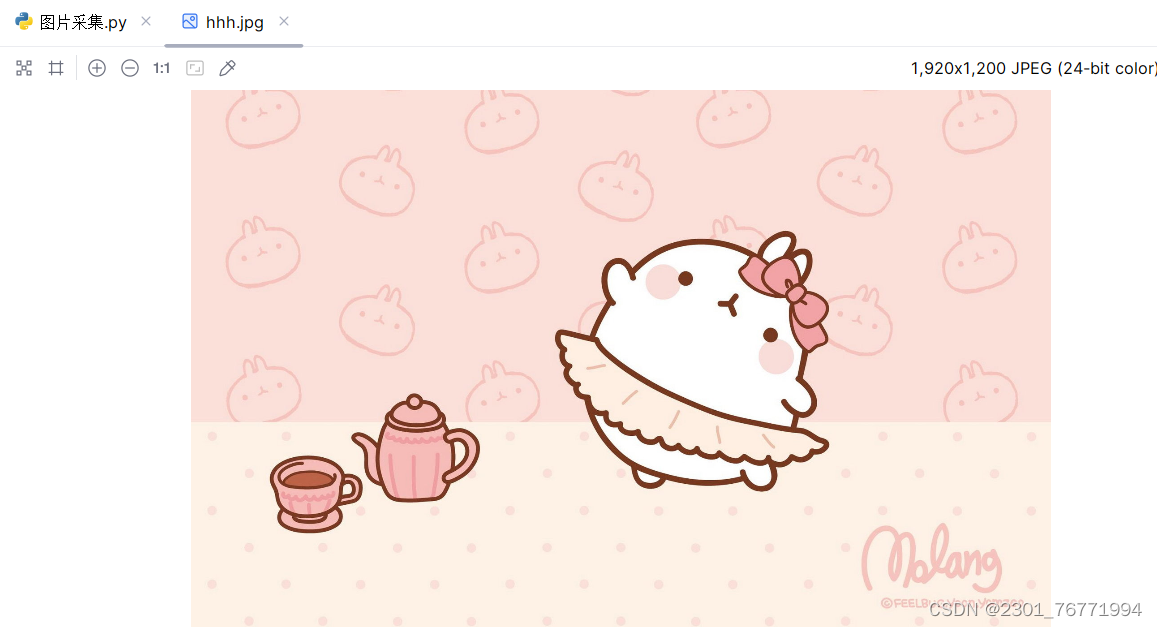
(2)豆瓣网的参数传递
与上步骤差不多,先进入开发者模式获取我们所需要的信息(找出url地址、请求头墩、请求方式),接着导包,输入我们获取的网址,然后拼接搜索功能,定义要传递的参数,设置请求头、请方式以及传递参数,最后打印获取我们所需要的网址
#--------百度-----------
#导包
import requests
#定制请求头
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.76'}
#豆瓣网网址
movie_url='https://www.baidu.com/'
#拼接搜索功能
url=movie_url+'s?'
#定义要传递的参数(单参数)
data ={'wd':'遂宁'}
#设置请求方式何请求头,以及传递参数
response=requests.get(url,headers=header,params=data)
#打印请求地址
print(response.url)
print(response.status_code)运行结果:

200就是之前我们提到的状态代码,说明运行OK。
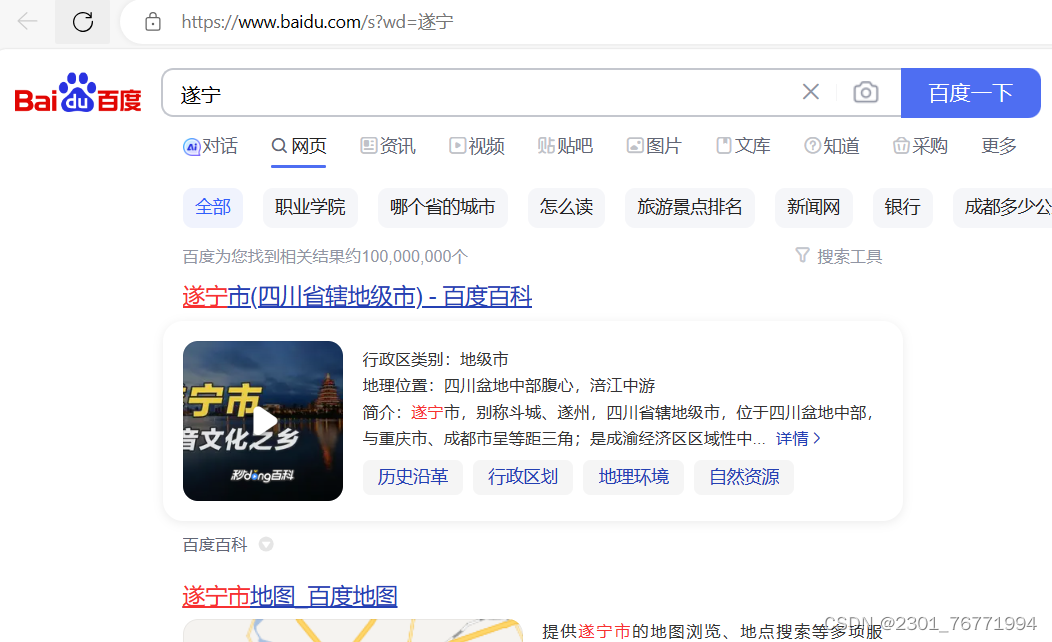
这个例子只是一个简单的单参数传递,既然有单参数那么也有多参数,区别也不大,定义多个参数就ok了,平时多加练习,找出网页中的规律,后续就简单多了。

3.3扩展:代理IP(略)
我们可以使用代理IP来多次访问网址获取相应信息。
目的:【为了防止访问网址次数过多导致自身IP被封禁】
分类:
-
透明IP
-
普匿代理IP
- 高匿代理IP
第一次写,还有很多不足,欢迎指出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









