






简单理解常用的匹配方式有四种
- (=)精确匹配
- (^~)不在向后匹配的前缀匹配
- ( )前缀匹配
- (~,~*)区分大小写的正则匹配和不区分大小写的正则匹配
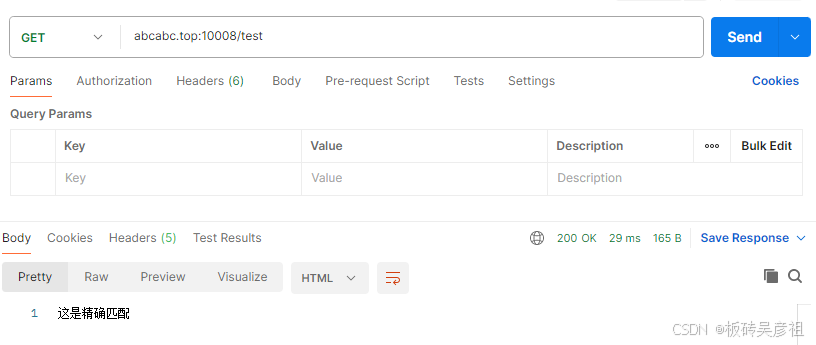
1.1= 等号开头的精确匹配
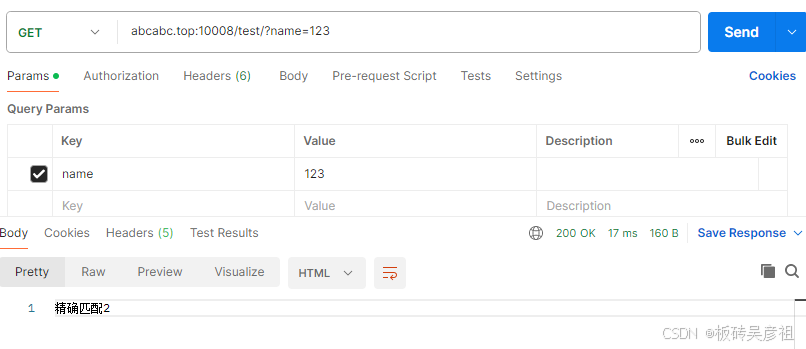
请求的url完全匹配该值时才生效,如有参数不影响匹配的路径
location = /test {
default_type text/html;
return 200 '这是精确匹配';
}
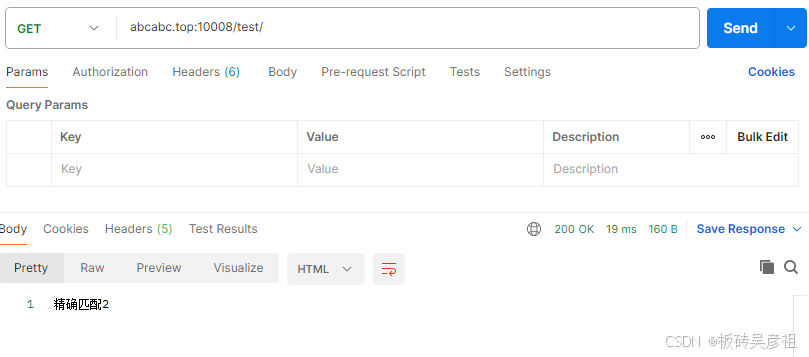
location = /test/ {
default_type text/html;
return 200 '精确匹配2';
}
1.2空格开头的前缀匹配
只要url路径和前缀匹配路径一致即可匹配,url的路径可以大于等于前缀匹配的路径。
如url满足多个前缀匹配会选择匹配路径最长的那个。
location = /test {
default_type text/html;
return 200 '这是精确匹配';
}
location = /test/ {
default_type text/html;
return 200 '精确匹配2';
}
location /test {
default_type text/html;
return 200 '前缀匹配1';
}
location /test/test2 {
default_type text/html;
return 200 '前缀匹配2';
}
location / {
default_type text/html;
return 200 '前缀匹配3';
}
可以看到/test/abc这个路径前缀满足精确匹配的前缀却不会匹配,只有完全一致才能精确匹配。匹配到了前缀匹配上
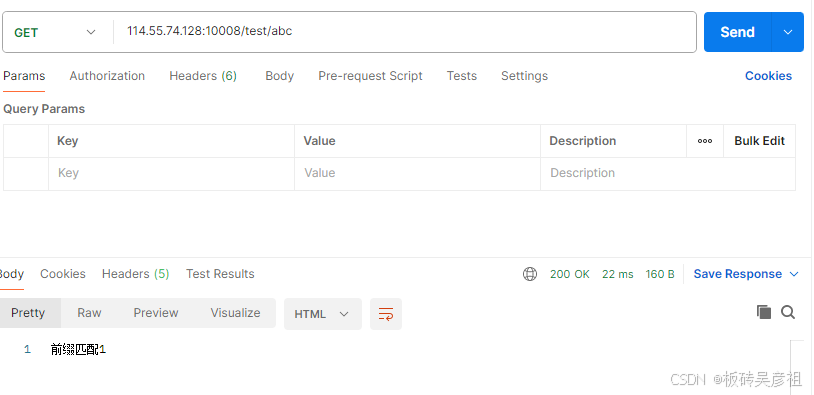
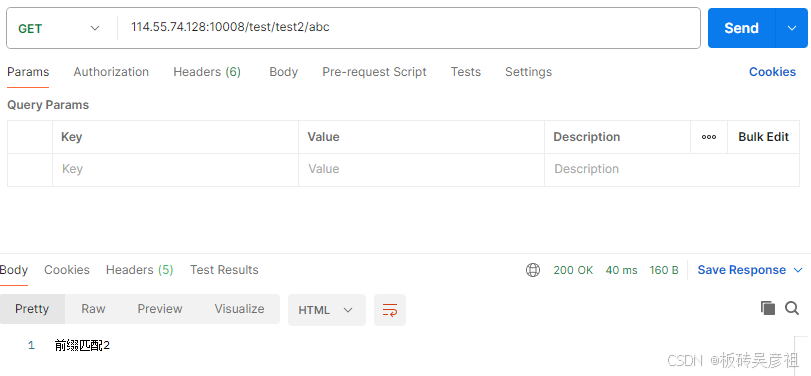
/test/test2/abc路径满足前缀匹配1和前缀匹配2,会选择匹配路径更长的前缀匹配2
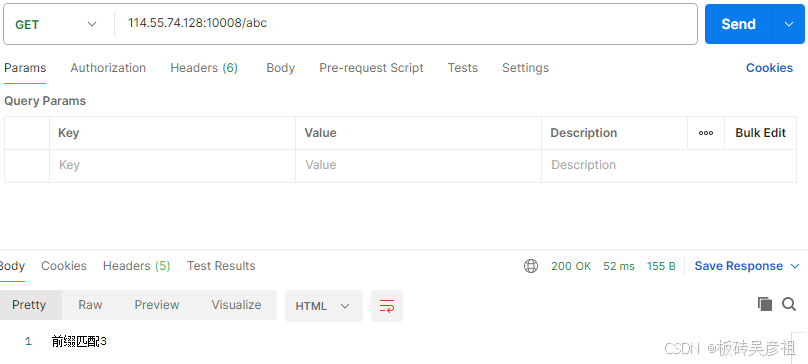
/可以匹配所有没有匹配到的路径因为所有路径都是/开头的
1.3^~ 开头不在向后匹配的前缀匹配
是前缀匹配的一种,不过匹配后会停止后续的正则匹配的查找。
location ^~ /test {
default_type text/html;
return 200 '不向后的前缀匹配1';
}
location ^~ /test/t1 {
default_type text/html;
return 200 '不向后的前缀匹配2';
}
location /test/t1/t2 {
default_type text/html;
return 200 '前缀匹配1';
}
location / {
default_type text/html;
return 200 '前缀匹配3';
}
location ~* bb$ {
default_type text/html;
return 200 '正则匹配1';
}
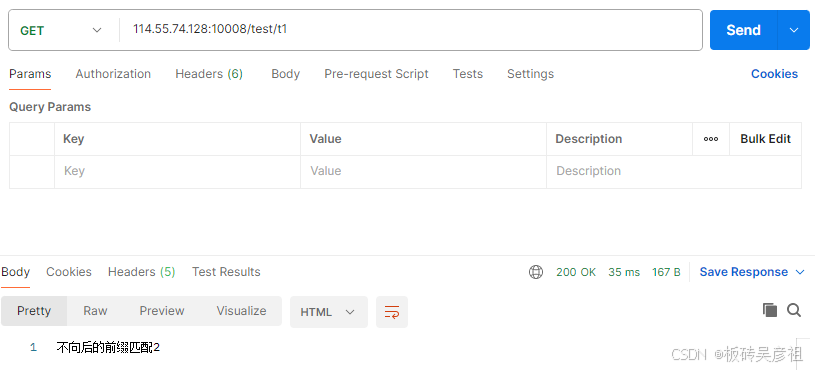
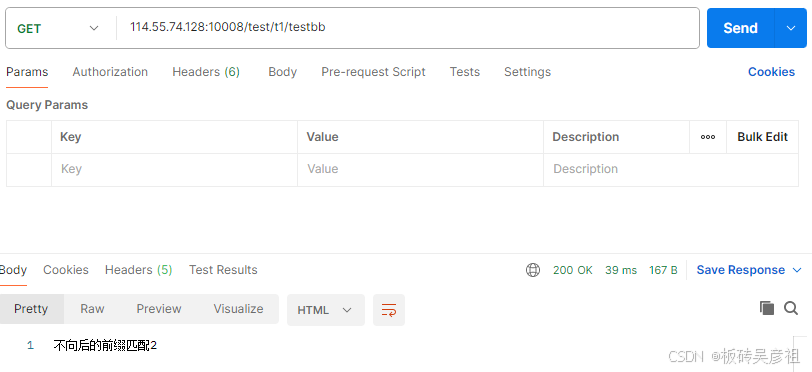
/test/t1满足不向后前缀匹配1,和不向后的前缀匹配2。会选择更长的不向后的前缀匹配2
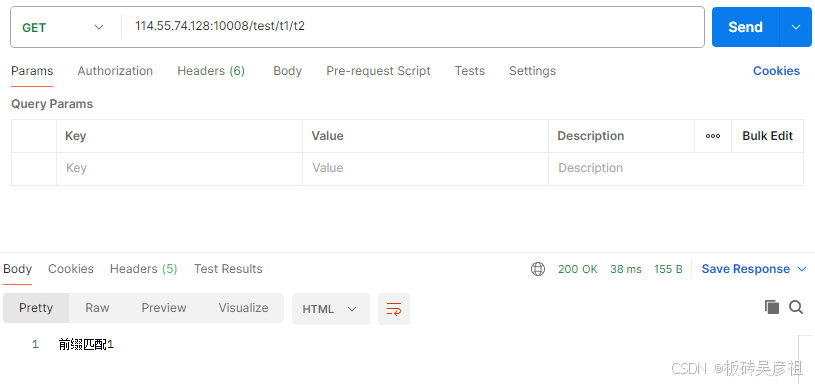
不向后的前缀匹配也是一种前缀匹配/test/t1/t2路径会匹配最长的前缀匹配1
有bb结尾的正则匹配,/test/t1/t2/testbb路径匹配前缀匹配后继续向下匹配到正则匹配1
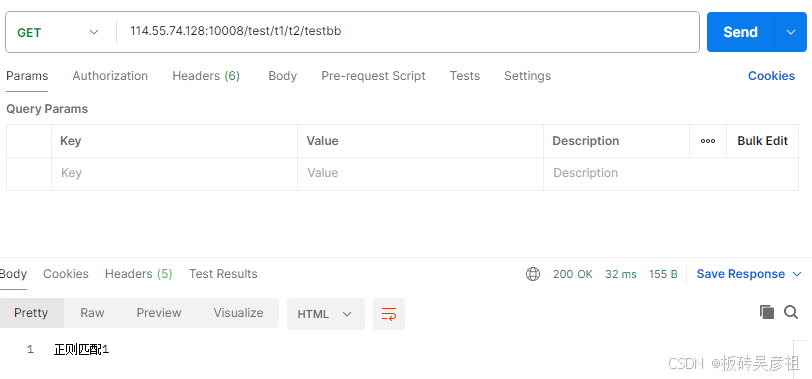
/test/t1/testbb路径匹配不向后的前缀匹配2跳过了bb结尾正则匹配
1.4~或~*开头的正则匹配
~区分大小写~*不区分大小写多用于对复杂的url匹配
location /test/t1/t2 {
default_type text/html;
return 200 '前缀匹配1';
}
location / {
default_type text/html;
return 200 '前缀匹配3';
}
location ~* bb$ {
default_type text/html;
return 200 '正则匹配1';
}
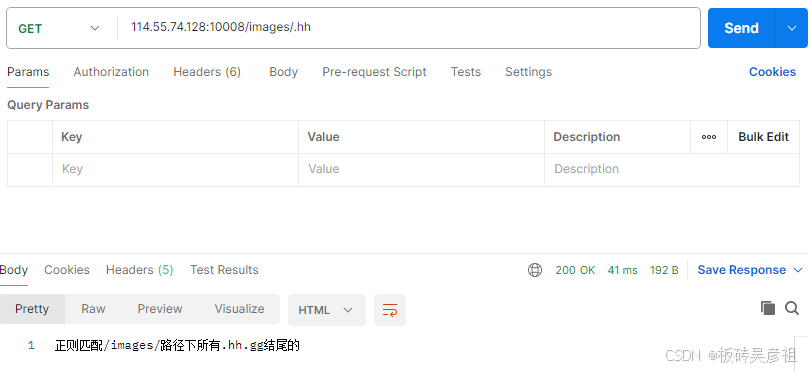
location ~ ^/images/.*\.(hh|gg)$ {
default_type text/html;
return 200 '正则匹配/images/路径下所有.hh.gg结尾的';
}
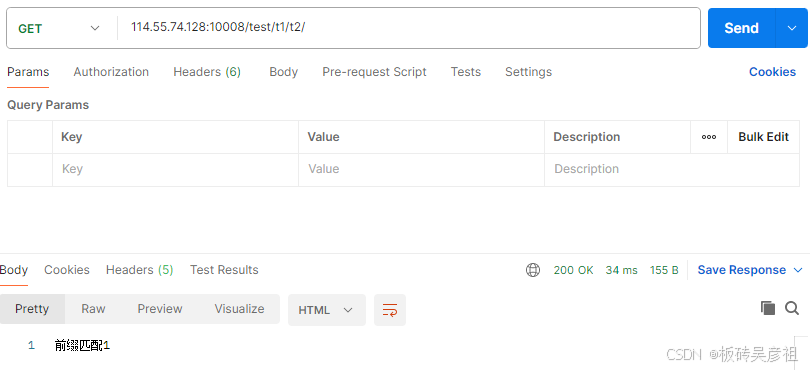
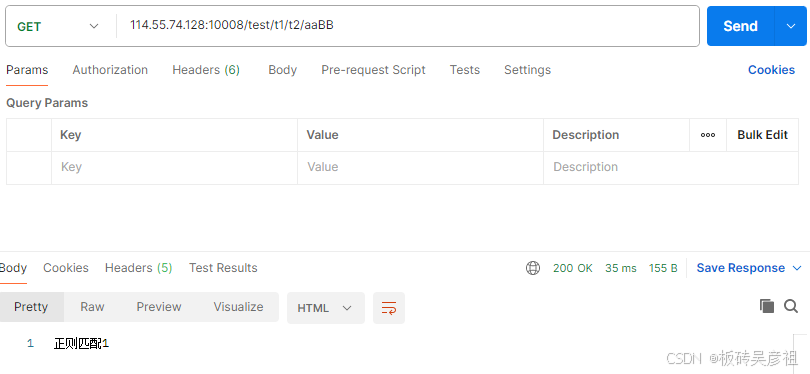
/test/t1/t2/aa满足前缀匹配
/test/t1/t2/aaBB满足前缀匹配后继续判断是否满足正则匹配,满足则用正则匹配
总结
匹配的优先顺序
- 先匹配精确匹配,如果匹配到直接使用。
- 匹配前缀匹配,若能匹配多个前缀匹配选最长匹配的
- 前缀匹配后若还有正则匹配则在看是否有可匹配的正则匹配,若有使用正则匹配
- 如果是不继续向后匹配的正则匹配,则不向后匹配正则匹配
- 都没匹配看是否有正则匹配可以匹配


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









