






## 面积图
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
# 创建数据
x = range(1, 6, 1)
y = [1, 4, 6, 8, 4]
# 绘制面积图
# plt.fill_between()函数用于绘制面积图
# 参数x和y分别表示x轴和y轴的数据
# 该函数会在x轴和y轴之间填充颜色,形成一个面积图
plt.fill_between(x, y)
# 显示图形
plt.show()
## 堆叠面积图
# 导入所需的库
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.ticker as mticker
# 数据来源:联合国世界人口展望(2019年修订版)
# 数据来源网址:https://population.un.org/wpp/
# 定义数据
year = [1950, 1960, 1970, 1980, 1990, 2000, 2010, 2018]
population_by_continent = {
'Africa': [.228, .284, .365, .477, .631, .814, 1.044, 1.275],
'the Americas': [.340, .425, .519, .619, .727, .840, .943, 1.006],
'Asia': [1.394, 1.686, 2.120, 2.625, 3.202, 3.714, 4.169, 4.560],
'Europe': [.220, .253, .276, .295, .310, .303, .294, .293],
'Oceania': [.012, .015, .019, .022, .026, .031, .036, .039],
}
# 创建图形和坐标轴对象
fig, ax = plt.subplots()
# 绘制堆叠面积图
# ax.stackplot()函数用于绘制堆叠面积图
# 参数year表示x轴数据,population_by_continent.values()表示y轴数据
# labels参数设置每个大洲的标签
# alpha参数设置透明度,0.8表示半透明
ax.stackplot(year, population_by_continent.values(),
labels=population_by_continent.keys(), alpha=0.8,
colors=['#FFD8E4', '#B3E5FC', '#E8F5E9', '#FFF3E0', '#E0F2F1']) # 马卡龙色系
# 添加图例
# loc参数设置图例位置为左上角
# reverse参数设置为True,使图例顺序与堆叠顺序一致
ax.legend(loc='upper left')
# 设置图表标题
ax.set_title('World population')
# 设置x轴标签
ax.set_xlabel('Year')
# 设置y轴标签
ax.set_ylabel('Number of people (billions)')
# 在y轴上每隔2亿人添加一个次刻度
ax.yaxis.set_minor_locator(mticker.MultipleLocator(.2))
# 显示图形
plt.show()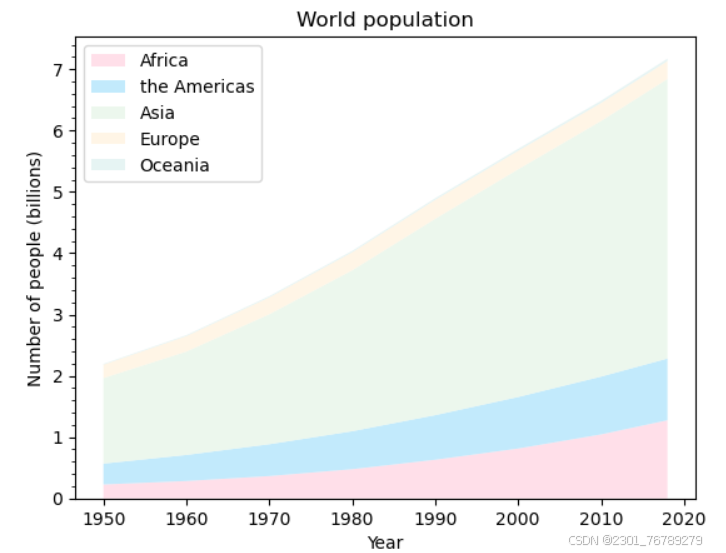
## 散点图
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
# 定义数据点的数量
N = 21
# 使用numpy的linspace函数生成x轴的数据点,从0到10,共11个点
x = np.linspace(0, 10, 11)
# 定义y轴的数据点,是一个包含11个值的列表
y = [3.9, 4.4, 10.8, 10.3, 11.2, 13.1, 14.1, 9.9, 13.9, 15.1, 12.5]
# 使用numpy的polyfit函数进行线性拟合
# deg=1表示拟合一个一次多项式(即线性拟合)
# 返回值a和b分别是拟合直线的斜率和截距
a, b = np.polyfit(x, y, deg=1)
# 根据拟合的参数计算每个x值对应的估计y值
# y_est = a * x + b
y_est = a * x + b
# 计算估计值的误差范围
# y_err表示每个点的误差估计值,基于x的标准差和样本大小
# 公式来源于线性回归的标准误差计算
y_err = x.std() * np.sqrt(1/len(x) +
(x - x.mean())**2 / np.sum((x - x.mean())**2))
# 创建图形和坐标轴对象
fig, ax = plt.subplots()
# 绘制拟合的直线
# 使用plot函数绘制拟合直线,'-'表示实线
ax.plot(x, y_est, '-')
# 使用fill_between函数绘制误差范围的填充区域
# alpha参数设置填充区域的透明度为0.2
ax.fill_between(x, y_est - y_err, y_est + y_err, alpha=0.2)
# 绘制原始数据点
# 使用plot函数绘制原始数据点,'o'表示圆点标记,颜色设置为棕色
ax.plot(x, y, 'o', color='tab:brown')
# 显示图形
plt.show()
## 气泡图
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
# 设置随机数据点的数量
N = 45
# 生成随机数据
# np.random.rand(2, N)生成两行N列的随机数,分别作为x和y坐标
x, y = np.random.rand(2, N)
# 生成随机颜色分类,范围从1到4,共N个
c = np.random.randint(1, 5, size=N)
# 生成随机大小,范围从10到220,共N个
s = np.random.randint(10, 220, size=N)
# 创建图形和坐标轴对象
fig, ax = plt.subplots()
# 绘制气泡图
# c参数设置颜色,根据分类c进行颜色映射
# s参数设置大小,根据大小s调整气泡的面积
scatter = ax.scatter(x, y, c=c, s=s)
# 为颜色分类生成图例
# scatter.legend_elements()返回用于图例的颜色和标签
# loc参数设置图例位置为左下角
# title参数设置图例标题为"Classes"
legend1 = ax.legend(*scatter.legend_elements(),
loc="lower left", title="Classes")
# 添加图例到坐标轴
ax.add_artist(legend1)
# 为大小生成图例
# scatter.legend_elements(prop="sizes")返回用于图例的大小和标签
# loc参数设置图例位置为右上角
# title参数设置图例标题为"Sizes"
handles, labels = scatter.legend_elements(prop="sizes", alpha=0.6)
legend2 = ax.legend(handles, labels, loc="upper right", title="Sizes")
# 显示图形
plt.show()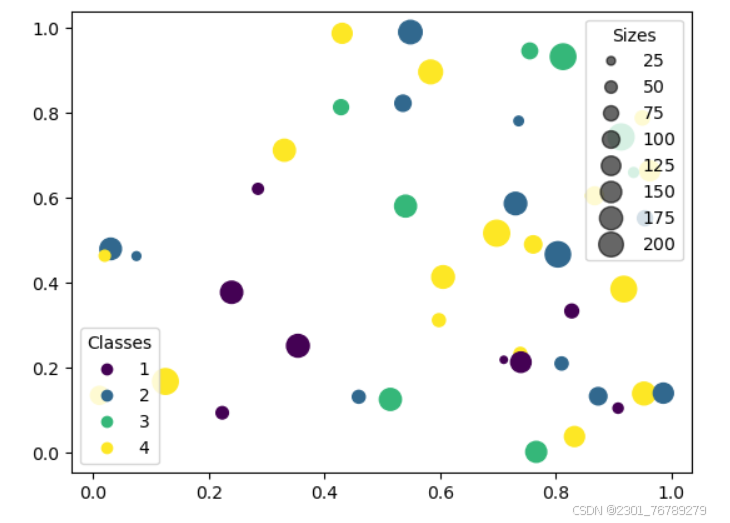
通过对面积图、堆叠面积图、散点图和气泡图的学习与实践,我深刻体会到了数据可视化在数据分析中的强大作用和独特魅力。每种图表类型都有其独特的应用场景和优势,能够以直观的方式呈现复杂数据的不同方面。
面积图和堆叠面积图通过填充颜色展示数据的范围和变化趋势,非常适合用于展示随时间或其他变量变化的数据量;堆叠面积图进一步通过堆叠的方式展示各部分对整体的贡献,帮助我们理解数据的结构和比例关系;散点图则通过点的位置展示两个变量之间的关系;而气泡图则在此基础上增加了第三个维度(大小)甚至第四个维度(颜色),能够更丰富地展示数据之间的复杂关系。这些图表不仅帮助我们快速识别数据中的模式、趋势和异常,还能通过颜色、大小等视觉元素增强信息的传达效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









