







首先明白一下为什么要引入映射,首先明白一点:因为内存的读取速度和cpu的速度差异过大,于是我们引入了cache机制,这样由于程序的局部性原理,我们把最常访问的一部分代码放到cache里面,这样cpu就可以直接从高速的cache里面直接取到代码,避免了与低速的主存交互。这从中就出现了一个问题:怎么把主存里面的内容放到cache里面?这就引出了我们的问题
直接映射:我们把主存分成若干个块(因为cache是以字块为单位的,这样便于映射)然后我们直接把内存的每一个块直接映射到cache里面,
公式:i = j mod C (其中,i为cache块号;j为主存块号;C为cache总块数)
例如:一个cache有64块,主存有若干块,我们以64为一个循环,将主存0-63编号放到cache里面0-63,主存63-127同样放到0-63块,以64为一个周期以此类推
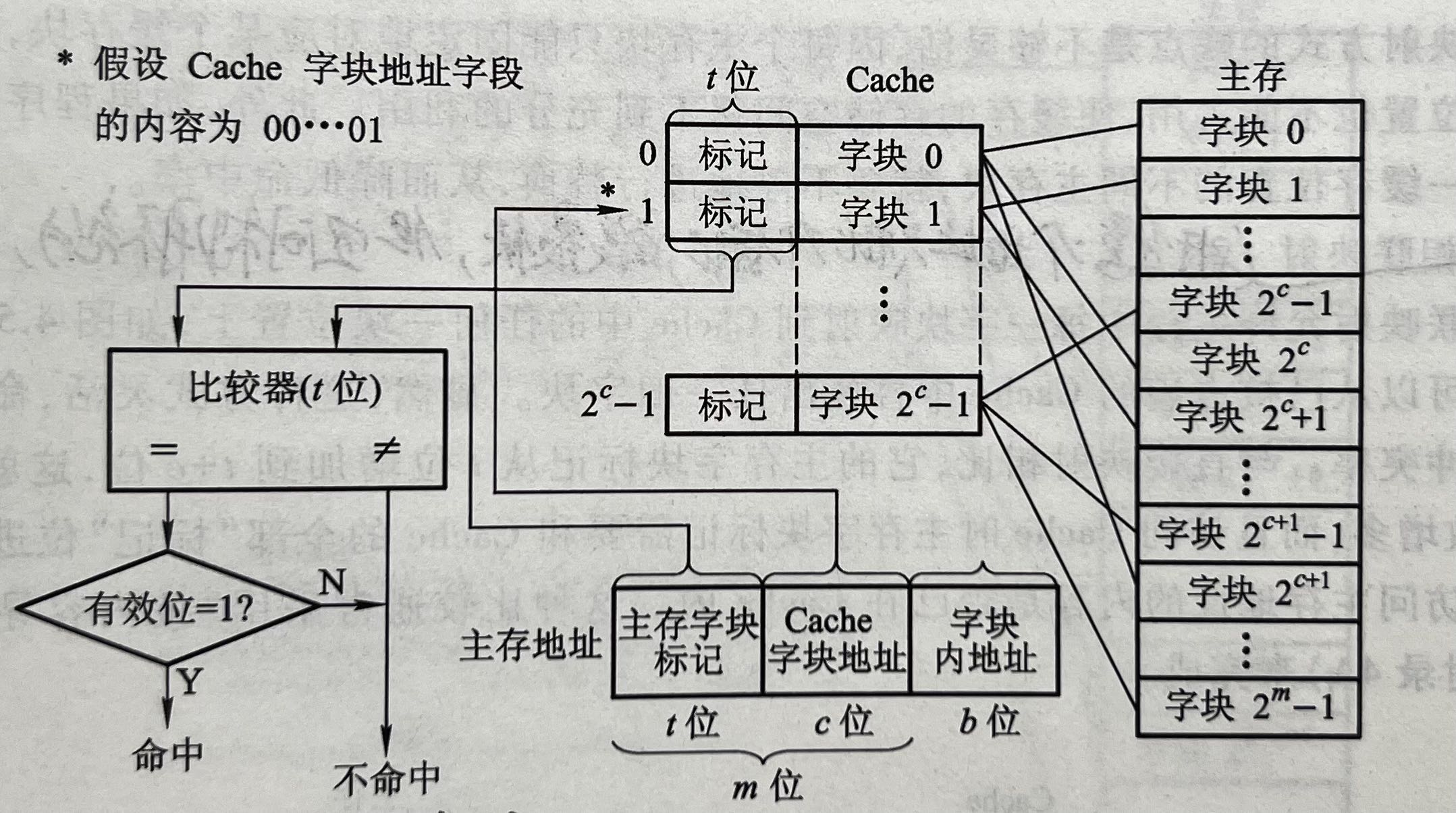
这么做当然没有问题,但是这样我们把主存每个地址都映射到了cache里面,这样在一个程序里面,我们并没有把访问最多的放到cache里面,这样cache的命中率变低了。没有体现程序的局部性原理。
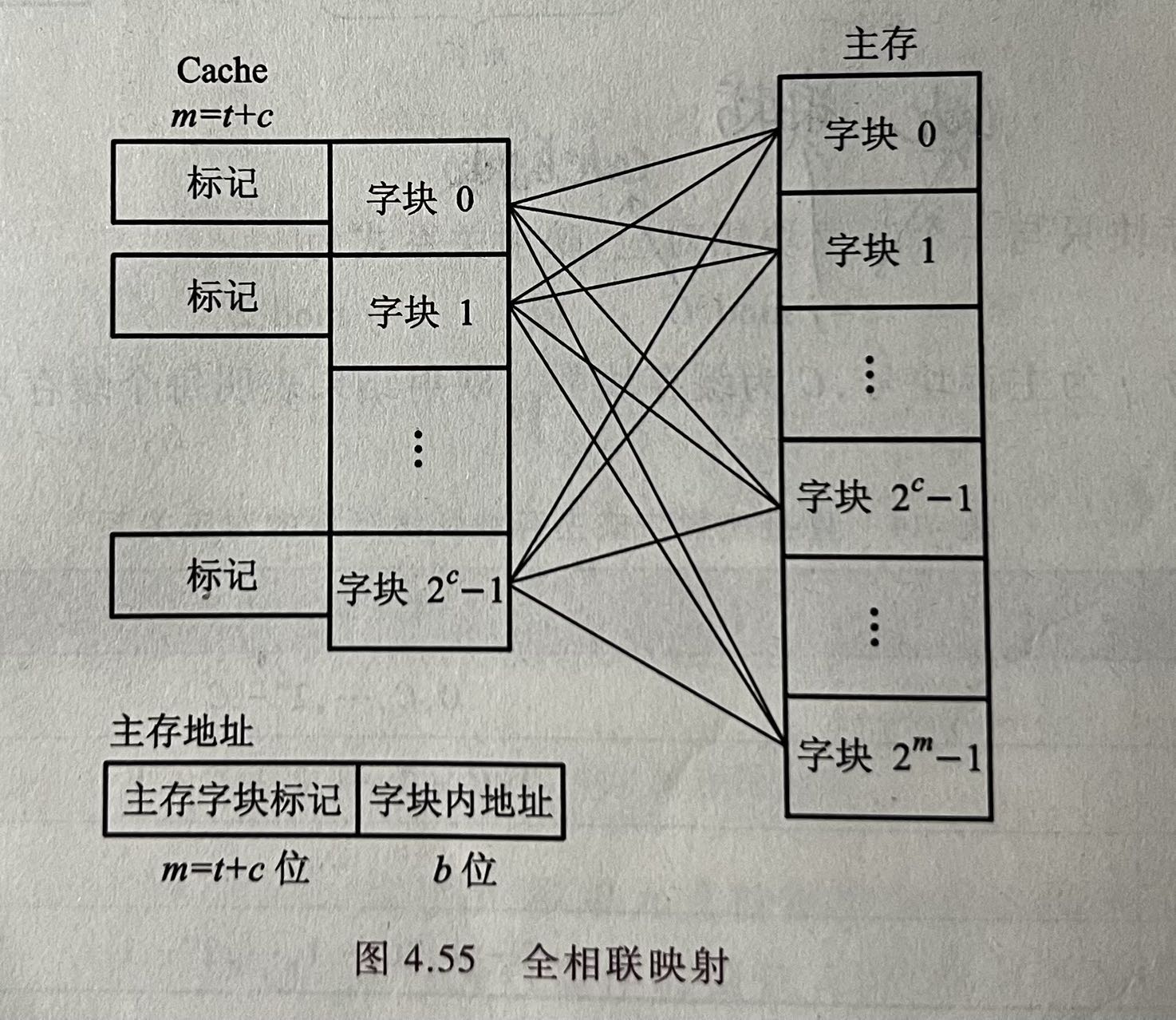
全相联映射:我们允许主存中的每一个字块映射到cache任意一个字块的位置上,而且可以替换任意一个旧的字块,这样对于一个程序我们最常访问的一块区域我们可以直接放到cache里面,不用担心会被替换(只要我们自己不替换就行),但是这种方式所需的逻辑电路多,成本较高。而且cache里面的主存字块标位数也变长了(因为存的是若干个主存地址,不像直接映射存的下标)
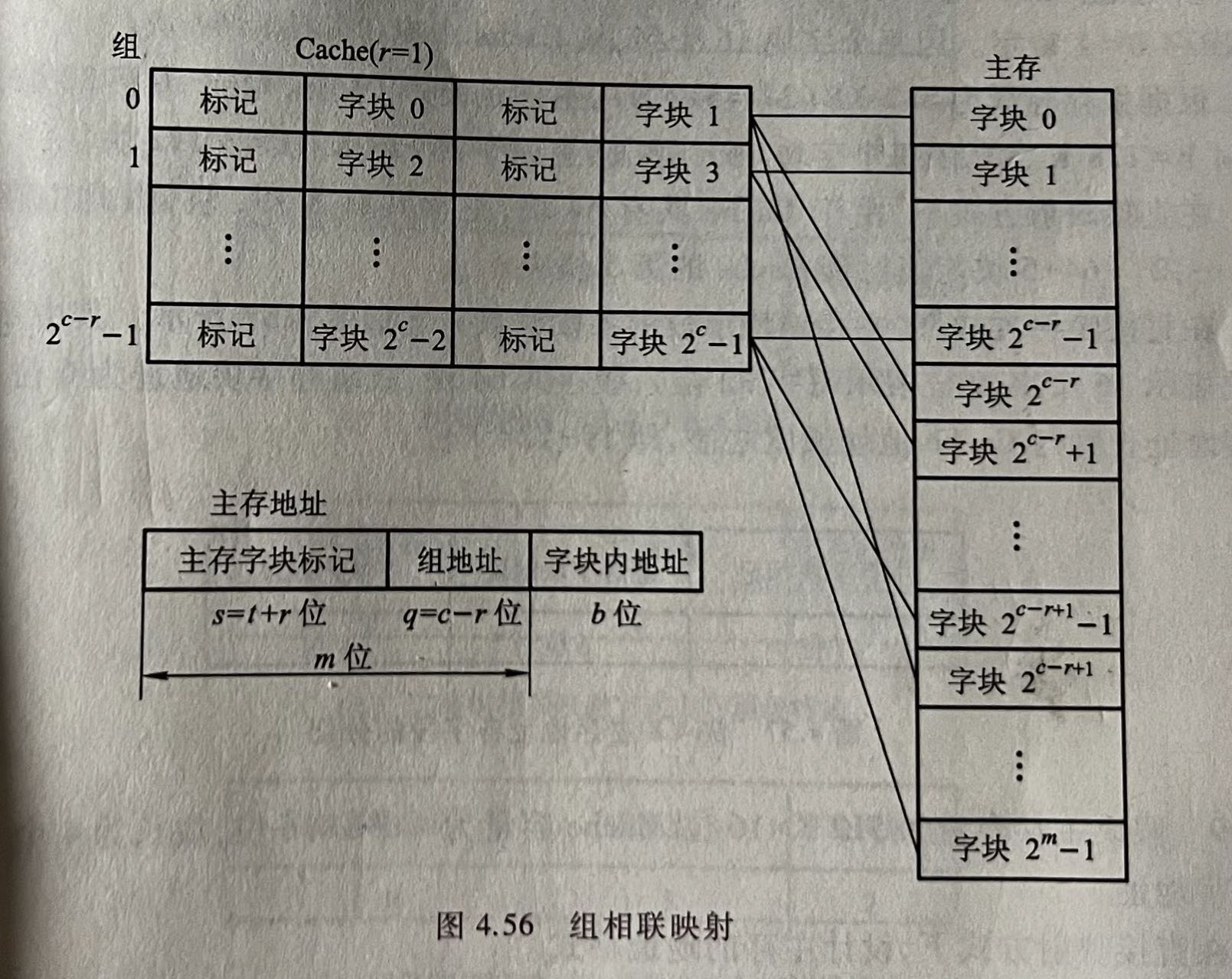
组相连映射:组相连映射巧妙地结合了二者的优点。它的核心思想是:将缓存分成若干组、每组包含若干路、主存块映射到特定组,但可以放在组内的任意路。
我们可以用商铺来比喻:
城市被划分为几个商业区(组)
每个商业区有若干店面(路)
商铺必须开在指定的商业区,但可以在区内自由选择店面
具体实现:
假设我们采用2路组相连映射:缓存分为32组(原64块,每组2路)主存块可以映射到:
- 块0和块32映射到组0
- 块1和块33映射到组1
- ...
- 块31和块63映射到组31
在每组内,块可以自由选择两个位置中的一个。
现代CPU缓存通常采用组相连映射:L1缓存:8路组相连;L2缓存:16路组相连


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









