







1.问题的产生
今天在编译项目代码的时候,遇到了一个全局变量变量过大导致编译器在链接的时候出错。我们先来看一下,原本的项目代码出错的位置。
#include <errno.h>
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
#include <poll.h>
#include <sys/epoll.h>
#include <errno.h>
#include <sys/time.h>
#include "server.h"
#define CONNECTION_SIZE 1048576 // 1024 * 1024
#define MAX_PORTS 20
#define TIME_SUB_MS(tv1, tv2) ((tv1.tv_sec - tv2.tv_sec) * 1000 + (tv1.tv_usec - tv2.tv_usec) / 1000)
int accept_cb(int fd);
int recv_cb(int fd);
int send_cb(int fd);
int epfd = 0;
//static struct timeval begin;
int begin;
struct conn conn_list[CONNECTION_SIZE] = {0};
// fd
int set_event(int fd, int event, int flag) {
begin=10;
if (flag) { // non-zero add
struct epoll_event ev;
ev.events = event;
ev.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
} else { // zero mod
struct epoll_event ev;
ev.events = event;
ev.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_MOD, fd, &ev);
}
}
上面的是项目代码的原始的一个片段。当我编译这段代码的时候,gcc给我报错。显示内容如下。
[root@MiWiFi-RA80-srv 9.1-kvstore]# gcc kvs_reactor.c /tmp/ccZpgsv9.o: in function `set_event': kvs_reactor.c:(.text+0x13): relocation truncated to fit: R_X86_64_PC32 against symbol `begin' defined in COMMON section in /tmp/ccZpgsv9.o collect2: 错误:ld 返回 1
他说编译器在采用32位的符号链接的时候,引用“begin”这个全局变量的时候出错了。 这个问题很好解决,我们知道了问题的原因,就是链接器使用32位链接出错了,这是因为编译器在编译的时候 可能默认使用了某些优化选项,这些选项导致它选择了32位重定位。你可以尝试调整编译器的优化级别或者关闭某些优化选项。我们只需要关闭这个选项就可以了。关于gcc与此相关的命令选项主要有下面三个设置。
- small: 这是默认的内存模型。它假设所有的代码和数据段(包括全局和静态数据)的大小不会超过 2GB,并且它们的地址都可以用 32 位偏移量来表示(相对于某个基准点)。这种模型有利于生成更高效的代码,因为它允许使用 32 位相对地址,从而减少了指令大小和内存占用。但是,当数据或代码段的大小超过 2GB 时,这种模型就不再适用。
- kernel: 这种模型是为编写内核代码而设计的,它假设所有的符号都位于一个特定的段中,通常用于操作系统内核开发。
- medium: 这种模型放松了对数据和代码段大小的限制,但仍然假设它们的总大小不会超过物理内存的寻址范围。这个模型在某些情况下比 small 更灵活,但仍然有一定的限制。
- large: 使用这种模型时,编译器不会假设代码和数据段的大小有任何限制。这意味着它会生成更通用的代码,能够处理任意大小的代码和数据段。这种模型的缺点是生成的代码可能不如使用 small 或 medium 模型时那么优化,因为编译器不能使用 32 位相对地址来引用所有的符号,而可能需要使用 64 位绝对地址
我们应该使用large这个选项。好的,先试验一下,看看是否成功。
[root@MiWiFi-RA80-srv 9.1-kvstore]# gcc -mcmodel=large kvs_reactor.c
[root@MiWiFi-RA80-srv 9.1-kvstore]#
好的,从命令中看我们的编译是成功的。但解决这个问题,并不是今天我们要探究的主要内容,今天探究的主要是其底层的基本原理,也就是究竟是什么导致编译器在32位编译的时候报错,以及一些比较有趣的现象和其背后的原因。
2.试验过程
2.1 试验1
下面我们将项目代码进行简化一下,找到其根本的重点。
#define CONNECTION_SIZE (long)1024*1024*1024*2 // 2GB
char conn_list[CONNECTION_SIZE] = {0};//已初始化
int end;//未初始化
int main()
{
end = 10;//调用
}
上面的代码是在文件main.c的文件中。我们可以看到,我们定义了一个很大的全局变量,并且我们还对他进行了初始化。
conn_list 这个字符串数组的大小大概是2GB左右,后面我们还定义了一个变量 end,并且在main函数中使用了它。好的我们先编译一下看看会发生什么情况。
[root@localhost 9.1-kvstore]# gcc main.c
/tmp/ccNSjFxz.o: in function `main':
main.c:(.text+0x6): relocation truncated to fit: R_X86_64_PC32 against symbol `end' defined in COMMON section in /tmp/ccNSjFxz.o
collect2: 错误:ld 返回 1
ok,通过编译这个报错出现了。
2.2 试验2
那我们把全局变量大小设置小一点。我们看如下代码
#define CONNECTION_SIZE (long)1024*1024*2 // 2MB
char conn_list[CONNECTION_SIZE] = {0};
int end;
int main()
{
end = 10;
}
我们减小了一个1024倍数,全局变量变成了2MB左右,我们在编译一下。
[root@localhost 9.1-kvstore]# gcc main.c
[root@localhost 9.1-kvstore]#
编译成功了。
2.3试验3
好的,我们继续做一些试验,然后总结一些结论,供我们后续进行分析。我们把end这个变量进行初始化,然后再编译,也就是定义一下“int end=0;”,然后再把1024该回去变成2GB.
#define CONNECTION_SIZE (long)1024*1024*10244*2 // 2GB
char conn_list[CONNECTION_SIZE] = {0};
int end=0;//初始化,但位置在下面
int main()
{
end = 10;
}
好的我们编译一下试试。
[root@localhost 9.1-kvstore]# gcc main.c
/tmp/ccbb4iUF.o: in function `main':
main.c:(.text+0x6): relocati
同样的出错,
2.4试验4
接下来我们再调换一下end和conn_list这两个变量在代码中的位置。也就是下面的代码。
#define CONNECTION_SIZE (long)1024*1024*10244*2 // 2GB
int end=0;//初始化,并且位置在上面
char conn_list[CONNECTION_SIZE] = {0};
int main()
{
end = 10;
}
我们编译一下,看看能否成功。
[root@localhost 9.1-kvstore]# gcc main.c
[root@localhost 9.1-kvstore]#
既然成功了,的确是一个神奇的现象,我们调换一下前后顺序既然成功了。
2.5 试验5
那如果我们不对end进行初始化,但位置不变会是什么情况。就像下面代码一样。
#define CONNECTION_SIZE (long)1024*1024*10244*2 // 2GB
int end;
char conn_list[CONNECTION_SIZE] = {0};
int main()
{
end = 10;
}
编译一下。
root@localhost 9.1-kvstore]# gcc main.c
/tmp/cca8rxFd.o: in function `main':
main.c:(.text+0x6): relocation truncated to fit: R_X86_64_PC32 against symbol `end' defined in COMMON section in /tmp/cca8rxFd.o
collect2: 错误:ld 返回 1
又出错了,好了到此我们也做了几个试验了,我们先总结一下结论。
3.结论和假设
1.当一个特别大的全局变量,然后这个全局变量进行了初始化,并且位于end变量前面位置的时候,我们编译出现链接时候的地址引用错误。
2.当我们把这个全局变量的大小改成2MB的时候,编译正常。
3.当我们对end进行了初始化,但是代码位置位于2GB变量的后面,编译的时候出错。
4.当我们把end放到,特别大的变量前面的时候,并且对end进行初始化,编译正常没有报错。
5.当我们把end放到特别大的变量的前面,但不对end进行初始化,编译出现错误。
上述是我们得出的一些结论,我们接下来探究其原因。其实,其根本原因,与C程序在系统中的内存分布有关系,我们先来看一下它在linux系统中的内存分布图。
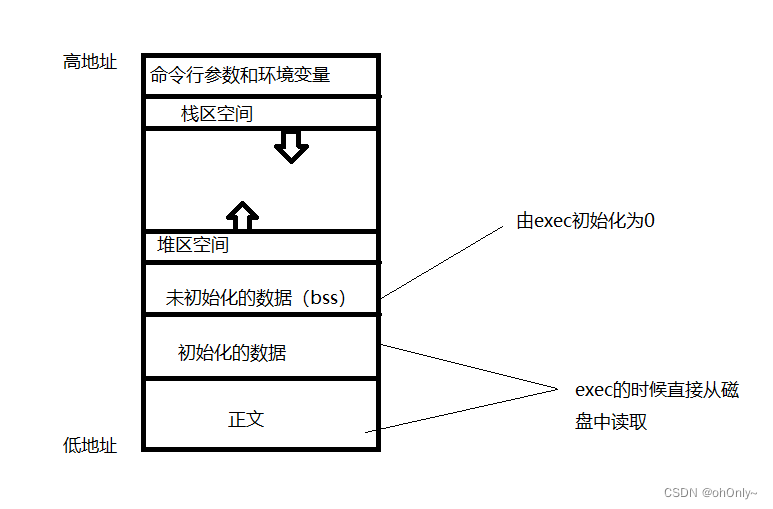
这个图是我手画的,有点丑,大家凑合着看吧哈哈。重点关注下面的三段。我们可以看到未初始化的数据(bss),在初始化数据之上。好了,我们根据上面的五个结论,和这个内存分布图,我们做出一个猜想,来解释上面的5个现象。在此先说一个知识点,就是编译器在编译代码的时候,会把全局变量存放在静态存储区,并且会把初始化过的全局变量和没有初始化的分开存储。对于初始化的全局变量,它的赋值是编译器在编译的时候赋值的。没有初始化过的全局变量,则是由链接器先链接程可以执行程序,然后在对其初始化为0.在这里,还需要补充一个点,就是c++和c的编译器的处理情况不一样,对于c++编译来说,如果gcc遇到的是.cpp文件,那么对于未初始化的全局变量编译器会直接将其初始化为0,不用等到链接阶段。我们后续可以顺便验证一下这个情况。
1.当一个全局变量特别大的时候,并且我们还对他进行了初始化,所以它在内存中的分布是在“初始化的数据”这个位置,因为end没有进行初始化,所以他在内存中的位置应该是在”bss“段内。因为内存地址从下到上是递增的,所以end的地址会很大,大概为2GB加上正文段,导致它的地址偏移超过了32位所能表示的最大值,而链接器又因为优化的原因,使用的32位的指针,所以导致编译除了问题。
2.当我们把conn_list变量从2GB变成2MB的时候,因为变小了,导致我们没有初始化的end变量在内存中的偏移也就没有那么大了,32位足够表示,所以编译成功。
3.当我们对end进行了初始化,但它在代码中的位置是位于2GB大小的变量的下面。所以即使他们都在初始化数据段,但end变量的地址是比conn_list高的。所以也就导致了它的地址偏移很大,最终编译错误。
4.当我们对end进行了初始化,并且位于conn_list变量的上面,这时候我们在编译就没有问题了。
5.如果把end放在了conn_list上面,但没有进行初始化,最终还会导致end存放在bss段,比conn_list的地址高,也就导致了地址偏移量过大,编译错误。
4.验证
4.1验证假设
上面是我们用假设对我们的5个结论做出的解释,我们要想验证一下我们这个假设是不是正确的,那我们就按照我们的逻辑看一下是不是得出我们想要的结论。按照我们的假设,是不是只要end变量比conn_list变量在内存分布中地址低就可以了。那我们就在第5个结论的代码上面进行一下改动。我们把conn_list不进行初始化了,是不是这样conn_list也就位于未初始化的段里了,并且end还在代码位置的上面,在内存中就会位于其下面。下面看一下代码。
#define CONNECTION_SIZE (long)1024*1024*10244*2 // 2GB
int end;//没有初始化,但位置在上面
char conn_list[CONNECTION_SIZE] ;//没有初始化
int main()
{
end = 10;
}
我们编译一下。
[root@localhost 9.1-kvstore]# gcc main.c
[root@localhost 9.1-kvstore]#
好的编译成功了,基本可以验证我们的猜想是正确的。大家后续可以按照这个理论再做一些其它试验,我们这里就不再继续啰嗦了。
4.2 验证C++编译器对全局变量编译阶段进行初始化
最后我们来验证一下c++编译是否会对没有初始化的全局变量,再编译阶段就初始化为0.我们看下面代码
#define CONNECTION_SIZE (long)1024*1024*10244*2 // 2GB
int end;
char conn_list[CONNECTION_SIZE]={0} ;
int main()
{
end = 10;
}
我们通过上面代码可以知道,如果编译阶段不对end进行初始化,那么链接器就会把end放到conn_list上面,也就会导致地址偏移过大,编译会出错。但如果编译阶段就初始化了,那么链接器就不会把end放在bss段里了,并且end在代码中还位于conn_list上面,编译就会正常通过。好的,我们接下来编译一下它。
[root@localhost 9.1-kvstore]# gcc main.cpp
[root@localhost 9.1-kvstore]#
编译成功了,看来没有问题。不过,c++编译的时候,要比c程序编译慢很多倍。
如果有说的不对的地方,或者我理解有问题的地方,希望各位大佬可以在评论区中指出来,谢谢。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









