







设计一个安卓端背单词应用:技术选型与设计思路
书接上回,在移动互联网时代,背单词应用已经成为语言学习者的必备工具。为了打造一款与众不同的背单词应用,我们团队决定开发一款结合 AI 生成单词故事 和 AI 生成漫画 的创新应用。
既然是设计背单词软件,那么选取合适的技术栈是最重要的。
显然,对于背单词来说,很多人更中意手机app而非网站
本文将详细阐述我们的设计思路和技术选型过程,分享从需求分析到技术实现的思考路径。
一、需求分析与功能设计(以下内容为暂定,可能根据实际情况有所调整)
1. 核心功能
单词学习:支持用户添加、删除、标记单词,提供单词释义、例句、发音等功能。
记忆:智能安排单词复习计划。
AI 生成单词故事:通过集成 DeepSeek API,为每个单词生成有趣的故事,帮助用户加深记忆。
AI 生成漫画:利用 Stable Diffusion API,为单词生成相关漫画,增强学习的趣味性。
用户数据同步:支持用户数据云端存储和跨设备同步。
2. 创新点
AI 故事与漫画:通过 AI 技术,将枯燥的单词学习转化为生动有趣的故事和视觉化内容。
个性化学习:根据用户的学习进度和偏好,动态调整学习内容和难度。
二、技术选型与设计思路(以下内容为暂定,可能根据实际情况有所调整)
1. 为什么选择 Android SDK 和 Kotlin?

在技术选型阶段,我们对比了多种开发方案,最终选择了 Android SDK + Kotlin 的组合,原因如下:
原生性能:Android SDK 提供了对系统底层功能的直接访问,能够实现高性能的应用体验。
开发效率:Kotlin 语法简洁,减少了大量样板代码,同时具备空安全特性,降低了 Bug 出现的概率。
生态支持:Kotlin 是 Android 官方推荐语言,拥有丰富的第三方库和工具支持。
未来扩展性:Kotlin 与 Java 完全兼容,便于团队逐步过渡到更现代的开发方式。
2. 前端技术栈
对于原生界面的开发,界面运用的xml的语言。我们对之前项目SSM架构中的sql语言设计也是xml,过度比较自然。
语言:Kotlin+xml
UI 框架:Jetpack Compose(声明式 UI 框架,代码简洁,开发效率高)
网络请求:Retrofit(用于调用 DeepSeek 或 Stable Diffusion 的 API)
数据存储:
目前我们小组有两个方案,目前还在讨论:
①本地存储:Room(SQLite 封装库,用于存储用户数据、单词记录等)
②第二个方案是服务器部署数据库,客户端通过网络请求,缓存等技术,读取到本地
3. 后端技术栈
语言:Kotlin/Java / Python(Flask/Django)/ XML
数据库:SQLite(快速搭建后端服务)或MySQL/PostgreSQL(传统关系型数据库)
API 集成:
DeepSeek API(生成单词故事)
Stable Diffusion API(生成漫画)
4. 其他工具
版本控制:Git进行版本控制
测试工具:
单元测试:JUnit
UI 测试:Espresso
性能测试:Android Profiler
三、设计思路与实现细节(以下内容为暂定,可能根据实际情况有所调整)
1. 用户界面设计
首页:展示用户的学习进度、每日任务和推荐单词。
单词详情页:显示单词的释义、例句、发音,以及 AI 生成的故事和漫画。
复习页面:根据记忆曲线,智能安排单词复习计划。
设置页面:支持用户调整学习偏好、同步数据等。
2. AI 功能集成
DeepSeek 故事生成:
用户点击单词后,应用通过 Retrofit 调用 DeepSeek API,获取生成的故事并展示。故事内容缓存到本地,减少重复请求。
Stable Diffusion 漫画生成:
根据单词的释义或故事内容,生成相关的漫画图片。使用 Glide 加载并显示漫画,确保图片加载流畅。
3. 性能优化
图片缓存:使用 Glide 的缓存机制,减少重复加载漫画图片的网络请求。
异步处理:通过 Kotlin 协程处理网络请求和数据库操作,避免阻塞主线程。
未完待续…
下一章我们会介绍原生Android开发的架构和效果,敬请期待
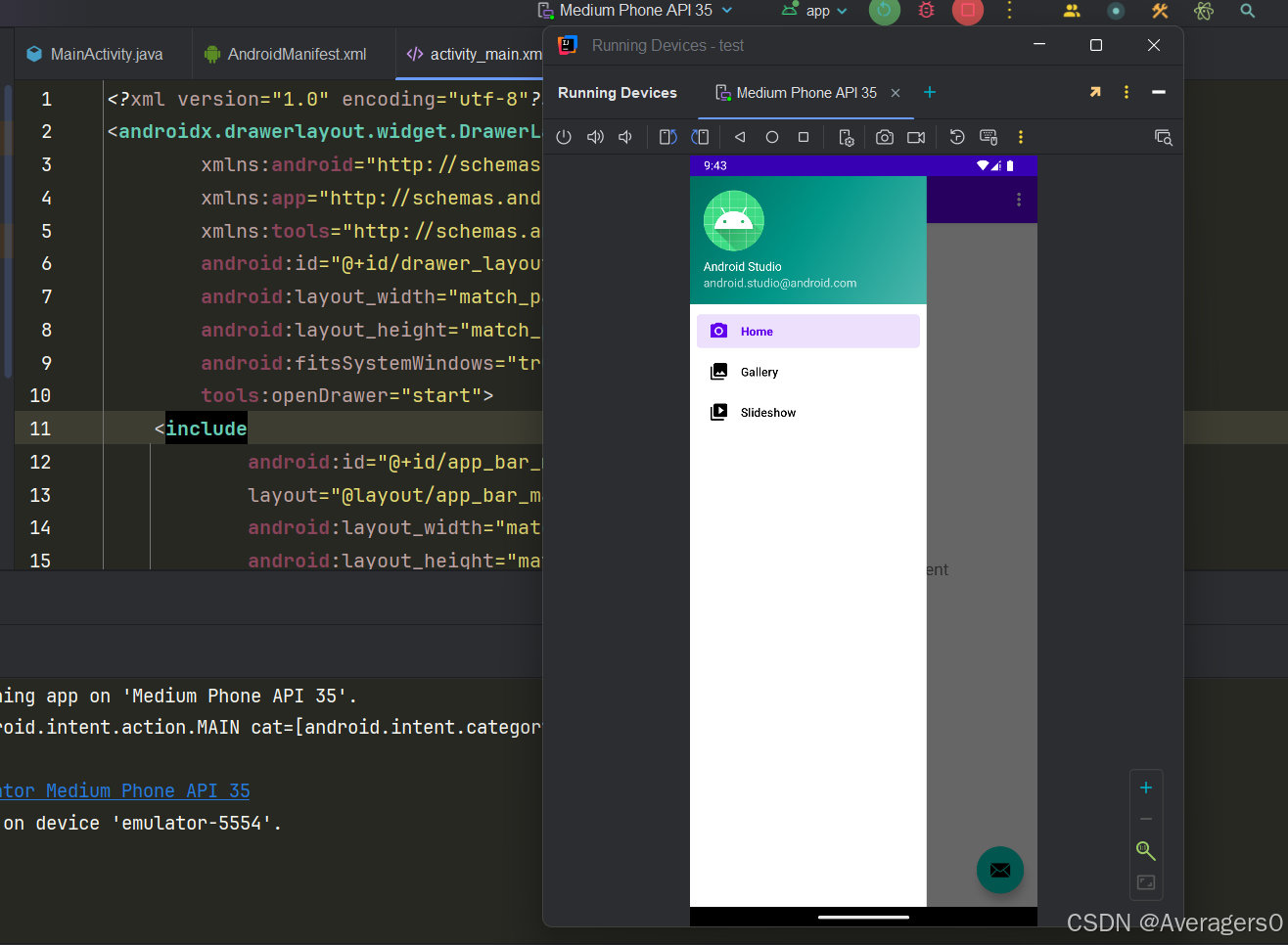
初步调试效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









