







目录
1. RFM模型
在零售及电商领域,RFM(Recency, Frequency, Monetary)模型是一种基于顾客交易行为的经典价值评估与分群方法。它通过计算“最近一次购买时间(R)”、“购买频率(F)”和“累计消费金额(M)”三大指标,对顾客进行量化打分与分层,帮助企业识别高价值用户、潜在流失用户及低价值用户,从而制定精准的营销和客户维护策略。以下内容将依次介绍模型概念、客户划分思路、核心作用,并结合 Python 示例演示从数据准备到 RFM 得分、分层的完整实现流程。
1.1 RFM模型概念
RFM 模型是一种根据顾客历史交易行为进行量化分析和分群的经典客户价值管理工具,最早由美国数据库营销研究所提出,用于识别企业核心客户及关键细分人群。RFM 模型是用来衡量客户价值的重要模型。
- R——Recency(最近一次购买):距今最近一次消费的时间间隔,间隔越短,得分越高,反映用户活跃度。
- 客户对商家的记忆程度
- 活跃用户
- 沉睡用户
- 流失用户
- 对用户的接触机会
- 客户对商家的记忆程度
- F——Frequency(购买频率):在一定时间窗口内的消费次数,次数越多,得分越高,体现用户黏性程度。
- 客户忠诚度
- 新用户
- 老用户
- 忠诚用户
- 客户对商家的熟悉度
- 客户忠诚度
- M——Monetary(消费金额):在同一时间窗口内的累计消费总额,金额越大,得分越高,反映用户价值贡献。
- 客户的消费能力
- 客户的贡献程度
- 低价值客户
- 中价值客户
- 高价值客户
1.2 客户划分方法
根据客户3个维度(R、F、M)值的差异,可以对客户进行划分。划分规则需要根据具体业务需求而定,业务内没有什么统一标准。通常情况下,我们可以将每个维度分为高与低两个类别,因此,3个维度共用8个类别。
| R | F | M | 客户类型 |
|---|---|---|---|
| 高 | 高 | 高 | 重要价值客户 |
| 低 | 高 | 高 | 重要保持客户 |
| 高 | 低 | 高 | 重要发展客户 |
| 低 | 低 | 高 | 重要挽留客户 |
| 高 | 高 | 低 | 一般价值客户 |
| 低 | 高 | 低 | 一般保持客户 |
| 高 | 低 | 低 | 一般发展客户 |
| 低 | 低 | 低 | 一般挽留客户 |
说明:这里的高与低,指对企业价值的高与低,而非维度数值上的大与小。例如:R越小价值越高。F和M越大价值越高。M越大,客户越重要。
1.3 模型作用
通过RFM模型,就可以将用户实现等级划分,从而能够对不同类别的客户,采取不同的方案与策略。进而,企业就可以做好产品运营,来提升企业的利润。
- 重要价值客户(高高高)
- 长期联络,定期回访
- 一对一服务
- 生日、节假日等问候,赠送礼品
- 重要保持客户(低高高)
- 赠送优惠券
- 发送打折信息
- 重要发展客户(高低高)
- 办理会员卡
- 赠送免费送货券
- 购买n次返红包
- 重要挽留客户(低低高)
- 定时定期发送促销活动信息
2. K-Means聚类
2.1 概念
K-Means 聚类是一种基于质心(centroid)的无监督学习方法,用于将 n 个样本划分到 K 个簇(cluster)中,使得同一簇内的样本彼此相似度高,不同簇间的样本差异大。该方法将每个聚类的中心定义为簇中样本的平均值(质心),并通过迭代不断调整质心位置和样本归属,从而优化簇划分效果。
具体来说,K-Means 算法的目标是最小化样本到其所属簇质心的欧氏距离平方和(Within-Cluster Sum of Squares,WCSS),体现了簇内紧密度的最优性要求。由于不需要标签信息,K-Means 常用于探索性数据分析,帮助发现数据内部的潜在结构。
2.2 应用场景
K-Means 聚类在工业界和学术界均有广泛应用,主要包括:
- 客户分群(Customer Segmentation):根据客户行为或属性,将客户划分为不同群体,便于实施差异化营销和推荐策略。
- 文档聚类(Document Clustering):将文本表示为向量后,利用K-Means发现主题相似的文档集合,常用于新闻分类、话题建模或识别在同一个圈子的朋友,判断哪些人可能互相认识等场景。
- 图像分割(Image Segmentation):以像素或超像素为数据点,通过K-Means将相似颜色/纹理区域分割出来,用于医学影像处理、物体检测等。
- 配送中心选址与路线优化:结合K-Means和其他优化算法,确定最佳仓库或投放点位置,并解决配送路径问题,以降低成本和时效。
- 异常检测(Anomaly Detection):在金融、电信等领域,通过识别与大部分数据聚类中心距离异常的点,来检测欺诈或故障情况。
除上述典型场景外,K-Means 还可用于市场细分、社交网络分析、基因表达数据聚类等众多领域。
2.3 算法步骤
K-Means算法,即K均值算法,是最常见的一种聚类算法。顾名思义,该算法会将数据集划分为K个簇,每个簇使用簇内所有样本的均值来表示,我们将该均值称为“质心”。具体步骤如下:
- 选择簇数 K:从训练样本中选择K个样本作为初始质心。由用户指定,或通过肘部法则(Elbow Method)等启发式方法确定。
- 初始化质心:在数据空间内随机选择 K 个点,或使用 k-means++ 等改进策略提高收敛速度和稳定性。
- 分配样本:计算每个样本到各个质心的距离,将样本划分到距离最近的质心所对应的簇中。(最小化欧氏距离或其他度量)。
- 更新质心:对于每个簇,重新计算簇内所有样本的平均值,作为新的质心。
- 迭代直到收敛:重复“分配—更新”步骤,直到质心位置不再发生显著变化(质心的位置变化小于指定的阈值)或达到最大迭代次数。
2.4 优化目标
K-Means 聚类的目标就是选择合适的质心,使得每个簇内,样本距离质心的距离尽可能的小。这样就可以保证簇内样本具有较高的相似性。我们可以使用最小化簇内误差平方和(Within-Cluster Sum of Squares,SSE)来作为优化算法的量化目标(目标函数),簇内误差平方和也称为簇惯性(inertia)。
S
S
E
=
∑
i
=
1
K
∑
j
=
1
m
i
∥
x
j
−
μ
i
∥
2
SSE = \sum_{i=1}^{K} \sum_{j=1}^{m_i} \| x_j - \mu_i \|^2
SSE=i=1∑Kj=1∑mi∥xj−μi∥2
- k k k:簇的数量
- m i m_i mi:第 i i i个簇含有的样本数量
- μ i \mu_i μi:第 i i i个簇的质心
- ∥ x j − μ i ∥ \| x_j - \mu_i \| ∥xj−μi∥:第 i i i个簇中,每个样本 x j x_j xj与质心 μ i \mu_i μi的距离
算法通过交替最小化样本分配和质心位置,使 S S E SSE SSE单调下降,直至局部最优收敛。
注意:由于目标函数非凸(non-convex),K-Means 容易陷入局部最优解,初始化策略(如 k-means++)和多次随机重启能够显著提升聚类效果和鲁棒性。
2.5 程序实现
1. 数据标准化
在实现聚类之前,我们需要对数据进行标准化处理,以消除不同量纲对距离计算的影响。
# 获取Recency,Frequency,Monetary数据
X = rfm.iloc[:,1:] # 取所有行,第2列到最后一列。这里的rfm是RFM模型的结果,包含了R,F,M三个特征。
X.head()
# 标准化
from sklearn.preprocessing import StandardScaler
s = StandardScaler()
X_scale = s.fit_transform(X)
X_scale = pd.DataFrame(X_scale, columns=X.columns, index = X.index)
X_scale.head()
2. 确定簇数量
可以根据最小的SSE原则,选择最佳的K值,即客户的类别数量。
from sklearn.cluster import KMeans
# 定义候选的K值范围
scope = range(1, 11) # 假设K的范围是1到10
# 定义SSE列表,用于存储每个K值对应的SSE
sse = []
# 遍历每个K值,计算对应的SSE
for k in scope:
# 创建KMeans模型,设置n_clusters为当前K值
kmeans = KMeans(n_clusters=k, random_state=42) # 设置random_state为42以确保结果的可重复性
# 训练模型
kmeans.fit(X_scale)
# 获取每个样本到其所属簇中心的距离平方和(SSE)
sse.append(kmeans.inertia_) # inertia_属性保存了SSE值
# 绘制K值与SSE的折线图
plt.plot(scope, sse, marker='o')
plt.xlabel('Number of Clusters (K)')

选择折线图的拐点变缓处(降低的幅度变小的)作为最佳K值(详细如何选择可查看下文的“2.6 肘部法”,这里查看上图可选择3或4),这里可以根据SSE的变化趋势选择拐点,也可以根据其他评估指标选择最佳K值。
3. 执行聚类
根据上述的图,选择效果较好的k值,上图为3或4
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(X_scale)
# 获取聚类厚的质心
print("质心:",kmeans.cluster_centers_)
# 获取每个样本所属的簇。标签的数值对应所属簇的索引
print("标签",kmeans.labels_)
# 获取SSE(簇惯性)
print("SSE",kmeans.inertia_)
# 获取迭代次数
print("迭代次数",kmeans.n_iter_)
# 聚类的分值,分值越大,效果越好。直接读SSE的相反数
print("分值",kmeans.score(X_scale))
4. 数量分析
统计每个类别群体的数量
v = pd.Series(kmeans.labels_).value_counts() #统计各个类别的数目
ax = sns.countplot(x=kmeans.labels_,order=v.index) #绘制条形图
# 在图像上绘制数值
for x, y in enumerate(v):
text = ax.text(x, y, y)
# 文本数值居中对齐
text.set_ha('center')
5. 客户群体分析
对聚类算法来说,只能帮助我们划分出客户的群体,但是,对于具体的某个群体,属于什么类型的客户,需自行分析。
fig, ax = plt.subplots(3,3)
fig, set_size_inches(18,15)
for i in range(3):
# 获取第i个客户群的数据
d = X[kmeans.labels_ == i]
sns.boxplot(y = "Recency", data = d, ax = ax[i,0])
sns.boxplot(y = "Frequency", data = d, ax = ax[i,1])
sns.boxplot(y = "Monetary", data = d, ax = ax[i,2])
- 对应R、F、M价值都较低的客户群体,属于一般挽留用户,该客户群体可以不用耗费过多的投入,在促销活动发送通知,给予一定的优惠券激活。
- 对应R价值较高,F与M较低的群体,属于最近消费的用户(很可能是新用户),该客户群体中可能包含很多潜能用户,需要频繁发送活动消息,增加其消费频率与消费金额。
- 对与R、F与M都较高的客户群体,属于重要价值客户,需要重点关注,给予特别VIP服务。
6. 绘制客户群体散点图
from mpl_toolkits.mplot3d import Axes3D #主要用于绘制3D坐标的类
fig = plt.figure() #创建一个绘图对象
fig.set_size_inches(12, 8) #设定绘图对象的大小
ax = Axes3D(fig) #用这个绘图对象创建一个Axes对象(有3D坐标)
color = ['r', 'g', 'b'] #颜色列表
for i in range(3): #循环绘制3个散点
d = X[kmeans.labels_ == i] #取出第i类数据
ax.scatter(d["Recency"], d["Frequency"], d["Monetory"], c=color[i], label = f"客户群{i}") #绘制散点图,颜色用color列表里的颜色
ax.set_xlabel("Recency") #设置x轴标题
ax.set_ylabel("Frequency") #设置y轴标题
ax.set_zlabel("Monetory") #设置z轴标题
ax.legend() #显示图例
2.6 肘部法(Elbow Method)
1. 原理
肘部法通过计算不同 K K K 值下的簇内误差平方和(Within-Cluster Sum of Squares, SSE),观察其随 K K K 的变化趋势。随着 K K K 的增加,SSE 通常会下降,但下降的幅度会在某个点后变得平缓。这个“肘部”点即为最佳的 K K K 值。
SSE(误差平方和):各簇内的样本点到所在簇质心
2. 实施步骤
- 选择一个 K K K 值的范围,例如从 1 到 10。
- 对每个 K K K 值,执行 K-Means 聚类,并计算对应的 SSE。
- 绘制 K K K 值与 SSE 的关系图。
- 观察图形,找到 SSE 明显下降后趋于平缓的“肘部”点,对应的 K K K 值即为最佳簇数。
# 肘部法 畸变函数(代价函数)
import matplotlib.pyplot as plt # 导入绘图工具
from sklearn.cluster import KMeans # 导入KMeans聚类算法
from sklearn.datasets import make_blobs # 生成聚类数据
X = info_scaled # 假设这是你的数据
distortions = [] # 存储每个K值对应的畸变函数值
for i in range(1,15): # 尝试不同的K值,从1到14,range(1,15)表示从1到14,不包括15
# 初始化KMeans模型,n_clusters表示生成的聚类数k,init表示优化质心初始化,n_init表示用不同质心初始值运算法的次数,max_iter表示每次迭代的最大次数,random_state表示随机种子
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0)
km.fit(X) # 训练模型
distortions.append(km.inertia_) # 计算畸变函数值并添加到列表中(所有样本到其最近质心距离的平方和)
plt.figure(dpi=150) # 设置图像分辨率为150
plt.plot(range(1,15), distortions, marker='o') # 绘制畸变函数值随K值变化的曲线
plt.xlabel('Number of clusters') # 设置x轴标签
plt.ylabel('Distortion') # 设置y轴标签
3. 示例图示



图中,肘部出现在 K = 2 K = 2 K=2 处,表示最佳簇数为 2。
2.7 轮廓系数法(Silhouette Coefficient)
簇内和簇间不相似度的概念
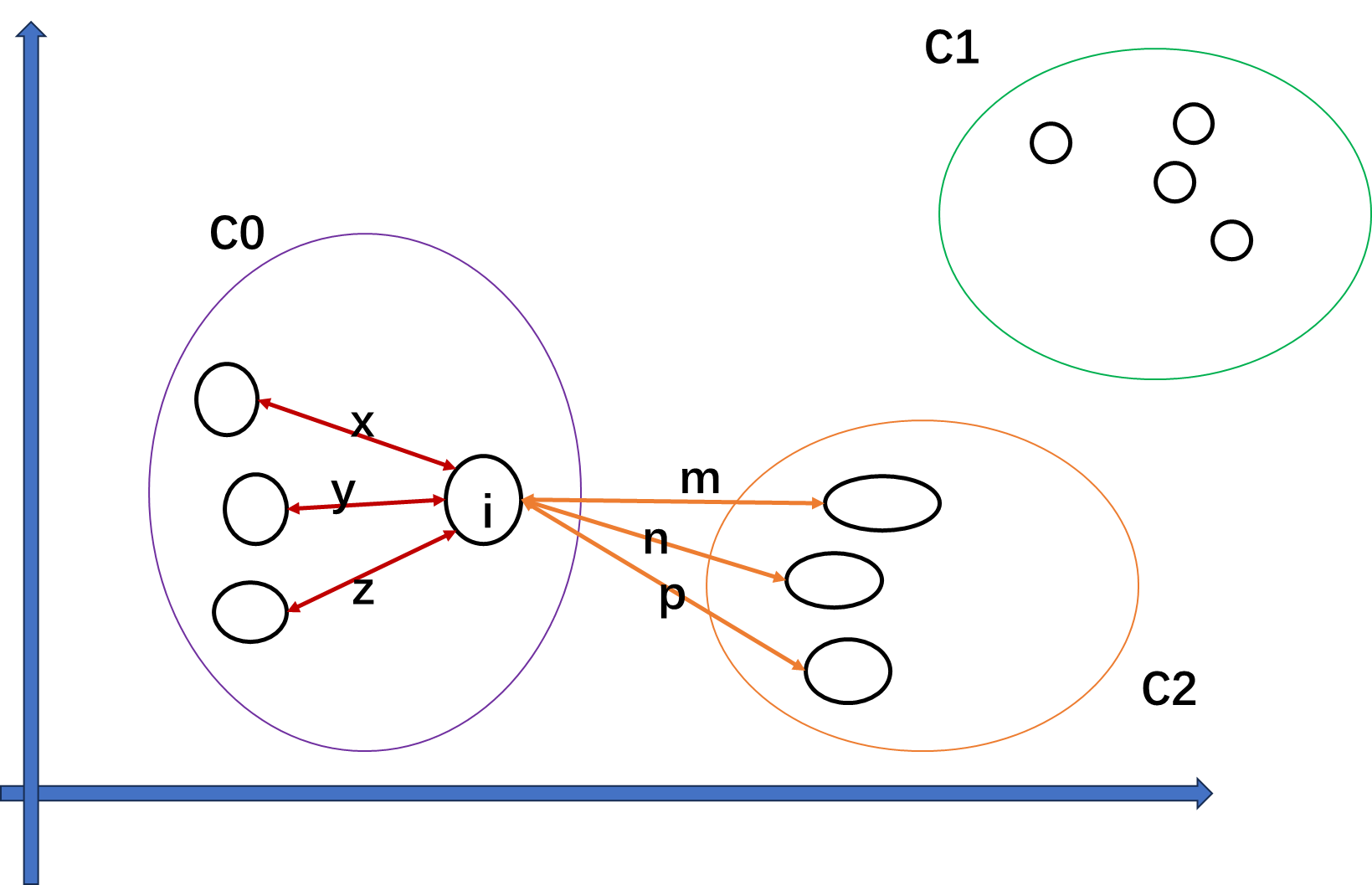
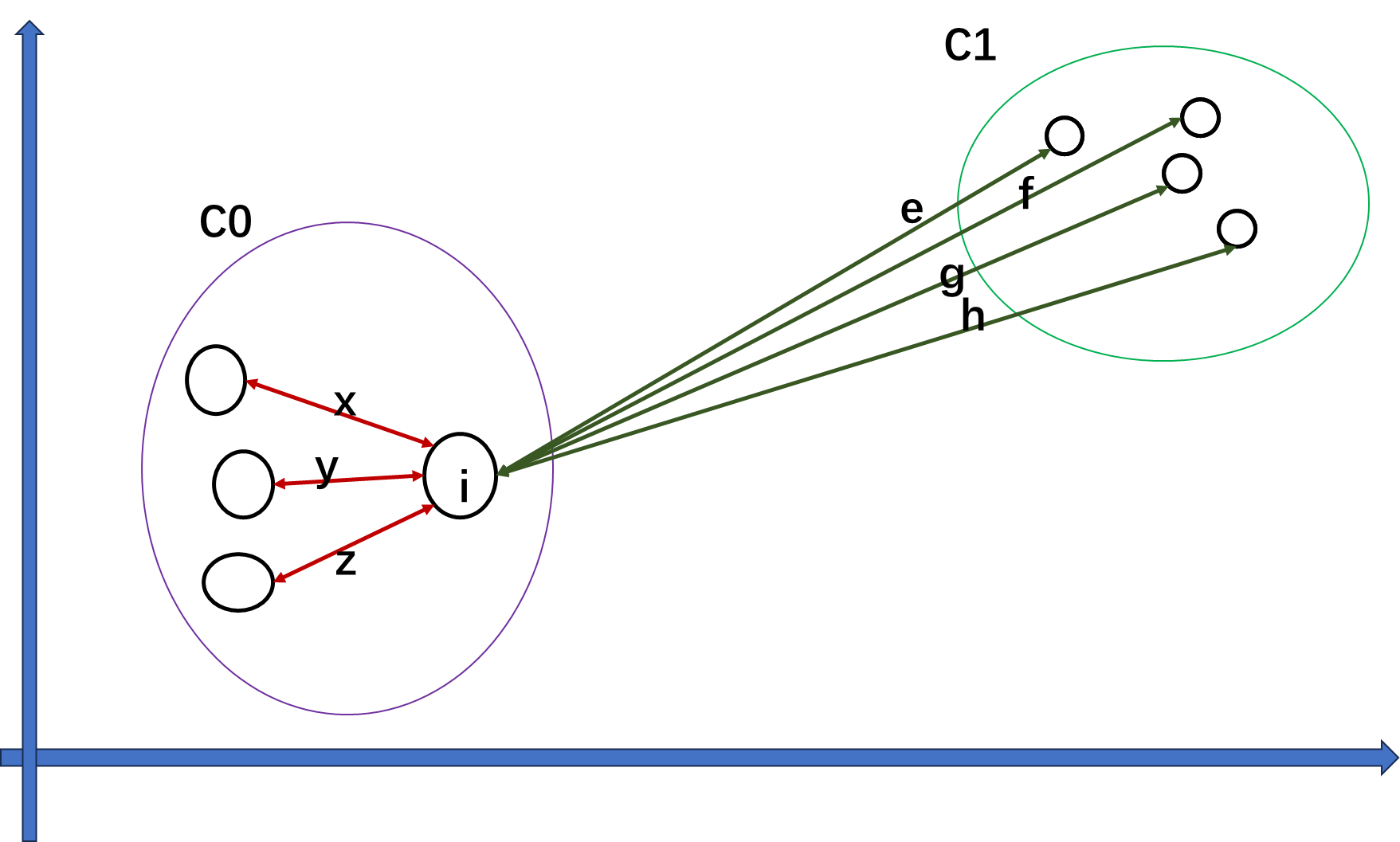
(1)Kmeans-轮廓系数-簇内不相似度
样本
i
i
i到同簇其他样本的平均距离
a
i
a_i
ai 为样本点
i
i
i的簇内不相似度。
a
(
i
)
=
x
+
y
+
z
3
a(i) = \frac{x+y+z}{3}
a(i)=3x+y+z

(2)Kmeans-轮廓系数-簇间不相似度
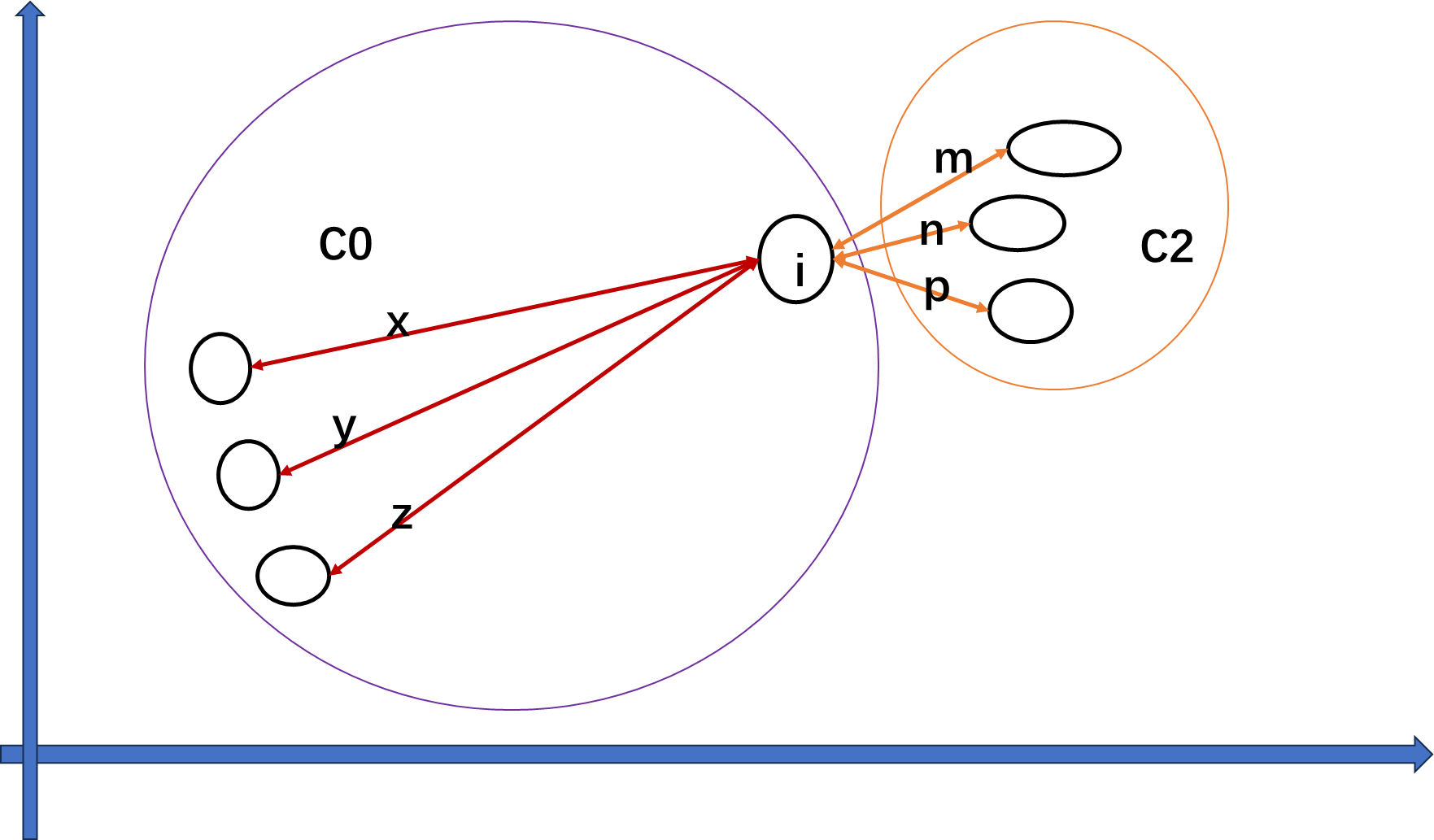
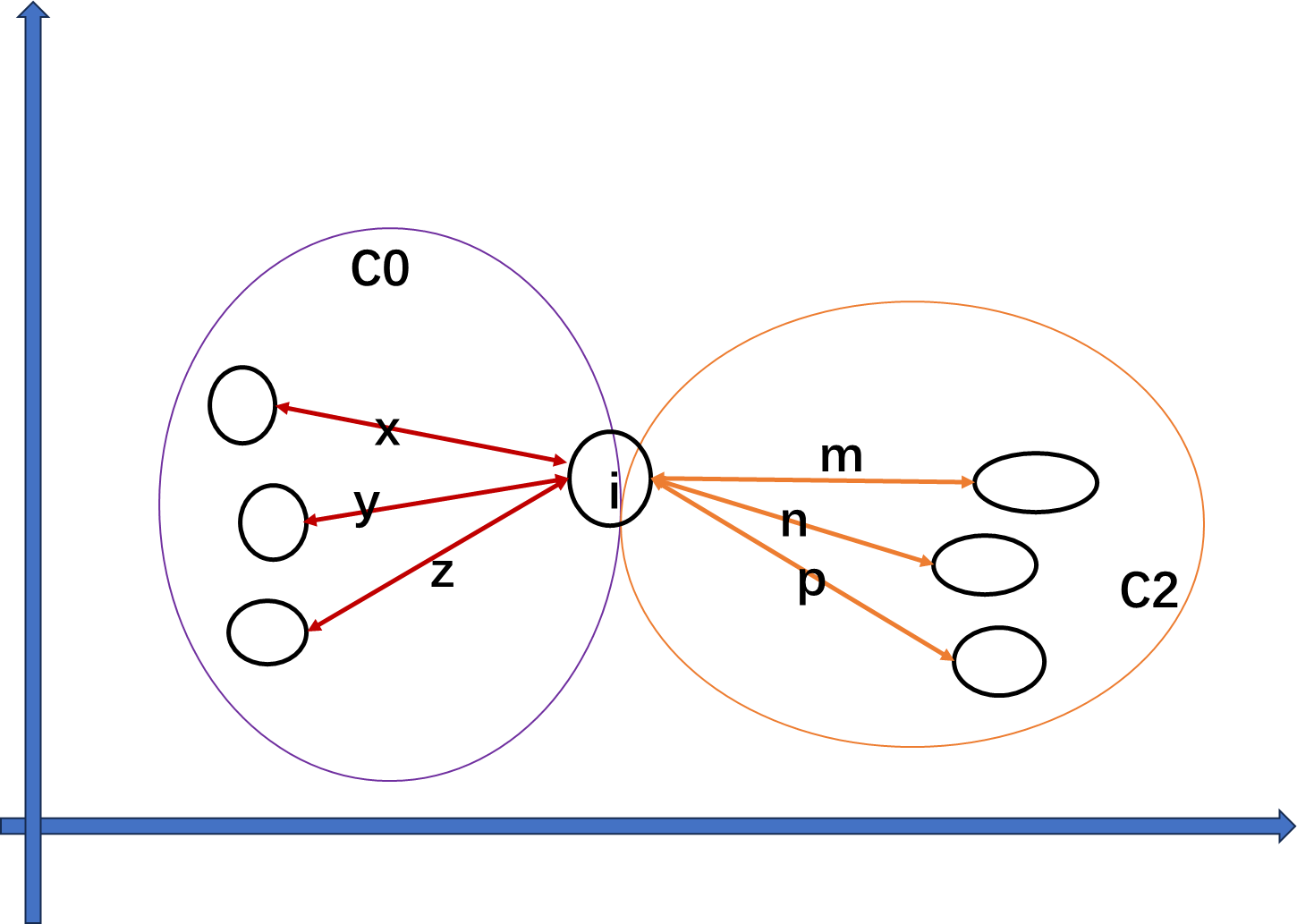
样本 i i i到其他某簇所有样本的平均距离 b i 1 = e + f + g + h 4 b_{i1} = \frac{e+f+g+h}{4} bi1=4e+f+g+h , b i 2 = m + n + p 3 b_{i2} = \frac{m+n+p}{3} bi2=3m+n+p 。 b i = min { b i 1 , b i 1 . . . . . b i n } ( n = K − 1 ) b_i={\min\{b_{i1}, b_{i1}.....b_{in}\}}(n=K-1) bi=min{bi1,bi1.....bin}(n=K−1) 样本点i的簇间不相似度为 b i b_i bi
b
i
1
>
b
i
2
b_{i1}>b_{i2}
bi1>bi2,
b
i
2
b_{i2}
bi2为
i
i
i点的簇间不相似度
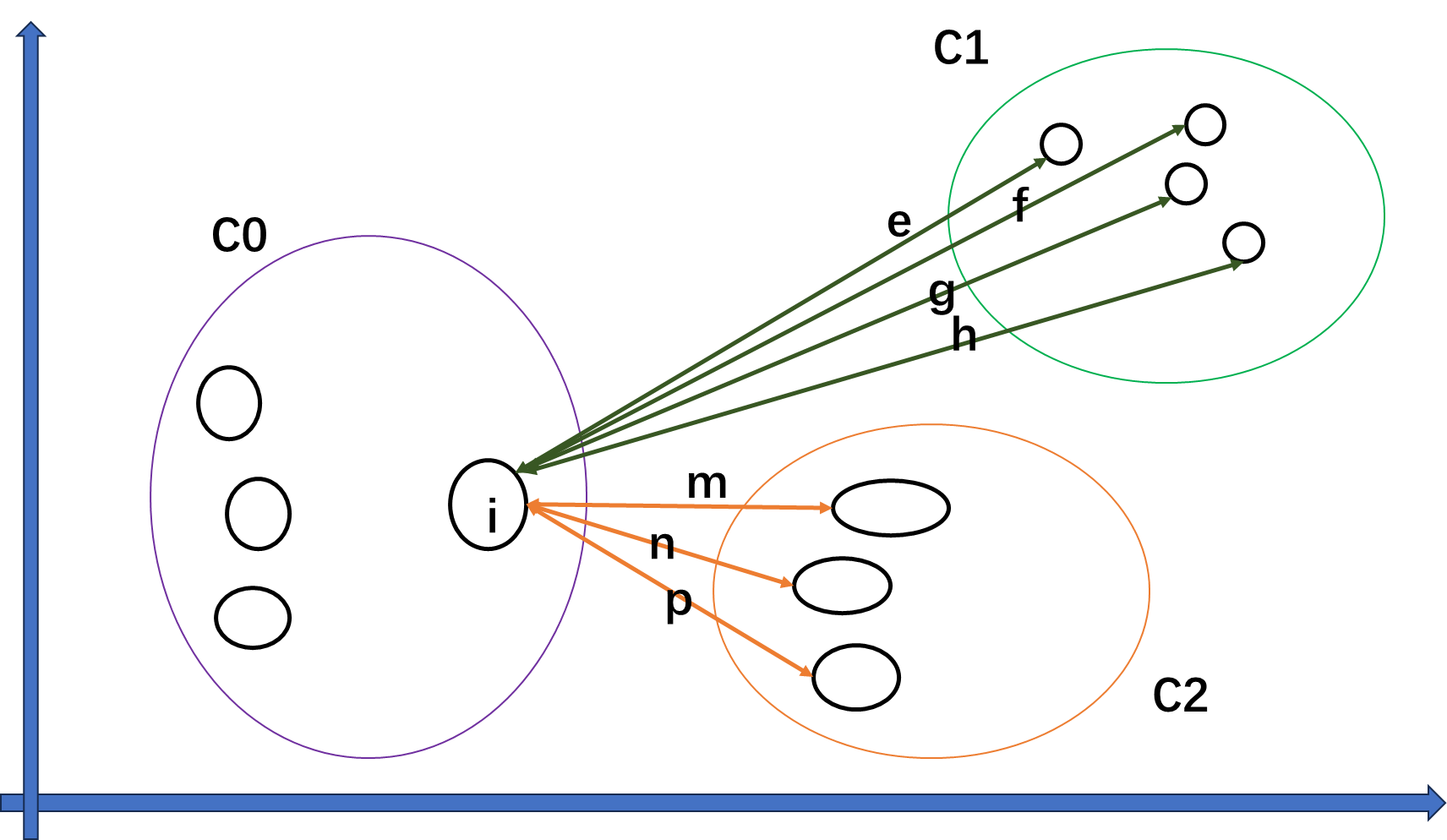
为什么簇间不相似度 b i = min { b i 1 , b i 1 . . . . . b i n } b_i={\min\{b_{i1}, b_{i1}.....b_{in}\}} bi=min{bi1,bi1.....bin} ?
计算样本点
i
i
i的
b
i
b_i
bi是为了与
a
i
a_i
ai进行比较,判断
i
i
i点属于哪一簇才更加合理。因此选择距离
i
i
i点最近的簇算得的
b
i
b_i
bi作为
i
i
i点的簇间不相似度。
1. 原理
轮廓系数衡量每个数据点与其所在簇内其他点的相似度(紧密度)与与最近邻簇中点的相似度(分离度)之间的差异。轮廓系数
s
(
i
)
s(i)
s(i)的计算公式为:
S
(
i
)
=
b
(
i
)
−
a
(
i
)
max
{
a
(
i
)
,
b
(
i
)
}
,
(
a
i
>
0
,
b
i
>
0
)
S(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}},(a_i>0,b_i>0)
S(i)=max{a(i),b(i)}b(i)−a(i),(ai>0,bi>0)
其中:
- a ( i ) a(i) a(i):样本 i i i 与同簇内其他样本的平均距离。
- b ( i ) b(i) b(i):样本 i i i 与最近邻簇中所有样本的平均距离。

轮廓系数的特点:
-
轮廓系数的取值范围为 [-1, 1],值越大表示聚类效果越好。
-
当 a i > b i a_i>b_i ai>bi,时: S ( i ) = b ( i ) − a ( i ) a ( i ) S(i) = \frac{b(i) - a(i)}{a(i)} S(i)=a(i)b(i)−a(i), S i ∈ [ − 1 , 0 ) S_i\in{[-1, 0)} Si∈[−1,0)
- 当
a
i
>
b
i
a_i>b_i
ai>bi且
b
i
b_i
bi趋近于0时
S
i
S_i
Si趋近于-1,表示
i
i
i点与簇内点分散,而与最近的另一簇样本点相聚较近。说明样本
i
i
i更应被分类到另外的簇。
- 当
a
i
>
b
i
a_i>b_i
ai>bi且
b
i
b_i
bi趋近于0时
S
i
S_i
Si趋近于-1,表示
i
i
i点与簇内点分散,而与最近的另一簇样本点相聚较近。说明样本
i
i
i更应被分类到另外的簇。
-
当 a i = b i a_i=b_i ai=bi,时:$S(i) = 0 $ ,表示 i i i点与簇内点和最近的另一簇样本点距离相等,说明样本 i i i在两簇的边界上。
-
当 a i < b i a_i<b_i ai<bi,时:$S(i) = \frac{b(i) - a(i)}{b(i)} $ S i ∈ ( 0 , 1 ] S_i\in{(0, 1]} Si∈(0,1]
- 当
a
i
<
b
i
a_i<b_i
ai<bi且
a
i
a_i
ai趋近于0时
S
i
S_i
Si趋近于1,表示
i
i
i点与簇内点紧凑,而与最近的另一簇样本点相聚较远。说明样本
i
i
i聚类合理。
- 当
a
i
<
b
i
a_i<b_i
ai<bi且
a
i
a_i
ai趋近于0时
S
i
S_i
Si趋近于1,表示
i
i
i点与簇内点紧凑,而与最近的另一簇样本点相聚较远。说明样本
i
i
i聚类合理。
2. 实施步骤
- 选择一个 k k k 值的范围,例如从 2 到 10。
- 对每个 k k k 值,执行 K-Means 聚类。
- 计算所有样本的轮廓系数,并求其平均值。
- 绘制 k k k 值与平均轮廓系数的关系图。
- 选择平均轮廓系数最大的 k k k 值作为最佳簇数。
# 轮廓系数
from sklearn import metrics
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
X = info_scaled # 标准化后的数据
scores = [] # 存储轮廓系数
for i in range(2, 11): # 从2到10个簇
#n_clusters: 生成的聚类数k, init: 优化质心初始化, n_init: 用不同的质心初始值运行算法的次数, max_iter: 每次迭代的最大次数, random_state: 确定随机数生成种子
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0) # 初始化KMeans
km.fit(X) # 训练模型
# metrics.silhouette_score(X, km.labels_, metric='euclidean'): 计算轮廓系数
# X: 数据集, km.labels_: 每个样本的簇标签, metric: 距离度量方式, 默认为'euclidean', 即欧氏距离
scores.append(metrics.silhouette_score(X, km.labels_, metric='euclidean')) # 计算轮廓系数
plt.figure(dpi = 150) # 设置分辨率
plt.plot(range(2, 11), scores, marker='o') # 绘制轮廓系数
plt.xlabel('Number of clusters') # 设置x轴标签
plt.ylabel('Silhouette-score') # 设置y轴标签
plt.show() # 显示图形
3. 示例图示


图中,平均轮廓系数在 k = 2 k = 2 k=2时达到最大,表示最佳簇数为 2。
2.8 对比与建议
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 肘部法 | 简单直观,易于实现 | 对于某些数据集,肘部不明显,判断主观 | 初步探索数据结构 |
| 轮廓系数法 | 提供定量指标,适用于评估聚类质量 | 计算复杂度较高,尤其在大数据集上 | 需要精确评估聚类效果的场景 |
在实际应用中,建议结合两种方法使用,先通过肘部法确定一个大致的 k k k 值范围,再利用轮廓系数法精细调整,以获得最佳的聚类结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









