






自从上次学完java基础做了个贪吃蛇之后,又花了两周时间去学了java的一些框架,如maven,mybaits,jsp,vue,虽然说不上熟练,只能说能用,不过现在能够看懂这些框架的一些术语了,于是为了使自己的学习留下些痕迹,又花了五天时间使用java做了个爬虫出来,该爬虫可以爬取b站视频,小说,漫画。有需要的同学可以进来看看。有基础的可以直接看后面,没头绪的建议从头看到尾。
视频用到的依赖:htmlunit,fastjson,ioutils
小说用到的依赖:jsoup
漫画用到的依赖:selenium,jsoup,htmlunit,ioutils
maven参数在后面
一.写在前面的话(关于爬虫)
大家不要以为爬虫是什么高大上的东西,这玩意说白了就是模拟浏览器把网络上的资源下载到本地,那么我们用浏览器打不开的页面,换爬虫来一样会失败,体现为报错,也就是说,爬虫只是方便我们进行大批量下载时节约时间用的。
那么说到这里,先来介绍一下爬虫的原理
有些人可能会好奇,有些页面并没有提供下载按钮,为什么用爬虫就能爬出来下载,其实你只要学了html网页的一些相关知识,就知道网页上的资源如图片,视频这些并不是凭空冒出来的,他是有人做好然后通过网页的一些方法展示到页面上,然后他去建了个服务器,让大家都能够访问这个页面,服务器再把资源给展示出来,那么服务器怎么知道是哪个资源呢?其实所谓服务器就是一台大型的联网硬盘,就跟我们的c盘d盘一样,那么他只要把路径标明就行了,这个最初的路径我们称之为src,即source,我们在自己的电脑上点路径只会跳转到对应文件,但在别人的服务器里点src就会直接开始下载,那么爬虫说白了他的技术核心,就是找我们想要的src,然后让java去”点“那么一下就行了,由于电脑的检索速度比人快的多,它看到的是二进制的母语,那么爬虫建好了是极具效率的。
那么我们从哪里去找src呢?这页面上也妹有一条代码啊,大家在浏览器中按f12就能打开开发者软件,打开元素那一栏,仔细观察,你其实就能看到src了,然后元素他是给我们人直接看的(元素本来在html中,只是浏览器开发者为了方便人看才造出来的),java他找不到元素这栏,他只能找到源代码的这条html(大家打开源代码,默认停留的就是当前页面的html)那么爬虫的核心代码就是把整个html页面的源码复制粘贴下来,通过一些手段把src筛出来。
二.爬取b站视频
为什么我要把爬视频放到前面呢,因为爬视频反而是三个里面最容易进行,最大概率成功的。我后面会写猜测。爬取b站用到的maven为htmlunit,fastjson,IOutils
先来介绍一下:
htmlunit:无头浏览器,由java模拟浏览器打开网站,为什么叫无头呢?因为它不会打开浏览器窗口
fastjson:json是网页返回的数据,这个包可以把从网页获得到的json以便捷的语法展示成字符串,下载链接就算一个json,靠这个就能把b站视频的下载链接提出来
IOutils:可以把他看成一个便捷的io流工具包,就是方便我们下载的
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(false);
是否加载jsp
webClient.getOptions().setCssEnabled(false);
是否加载css
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
抛出异常的设置
上方是设置无头浏览器的参数
webClient.addRequestHeader("referer", "https://www.bilibili.com/");
webClient.addRequestHeader("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) A" +
"ppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0");
请求头的设置这里就是设置浏览器的参数,关闭jsp和css加载能够提高效率
下方请求头的设置很重要,b站根据这个判断你能否进行访问,不写这个你拿java都进不去网站,大家在f12的网络那一栏那里随便点开一个,就能看到自己的请求头,由于我们的请求,服务器的servlet返回了一些东西
WebRequest webRequest=new WebRequest(new URL("https://www.bilibili.com/video/BV1F5fMYkE7U/"),HttpMethod.GET);
这里进行你要下载的视频的访问,后面输入对应网址
Page p=webClient.getPage(webRequest);
WebResponse webResponse=p.getWebResponse();
String c = webResponse.getContentAsString();
这三行代码就是把那个网址的html页面里的源码整个扒出来那么到这里,爬虫就已经成功一半了,我们可以通过正则表达式把源码里的下载链接扒出来
那么我们先去源码里观察一下下载链接长什么样
虽然b站把自己的源码页面隐藏了,但是我们可以在控制台网络栏刷新一下网页,最先响应的资源就是它的html文件
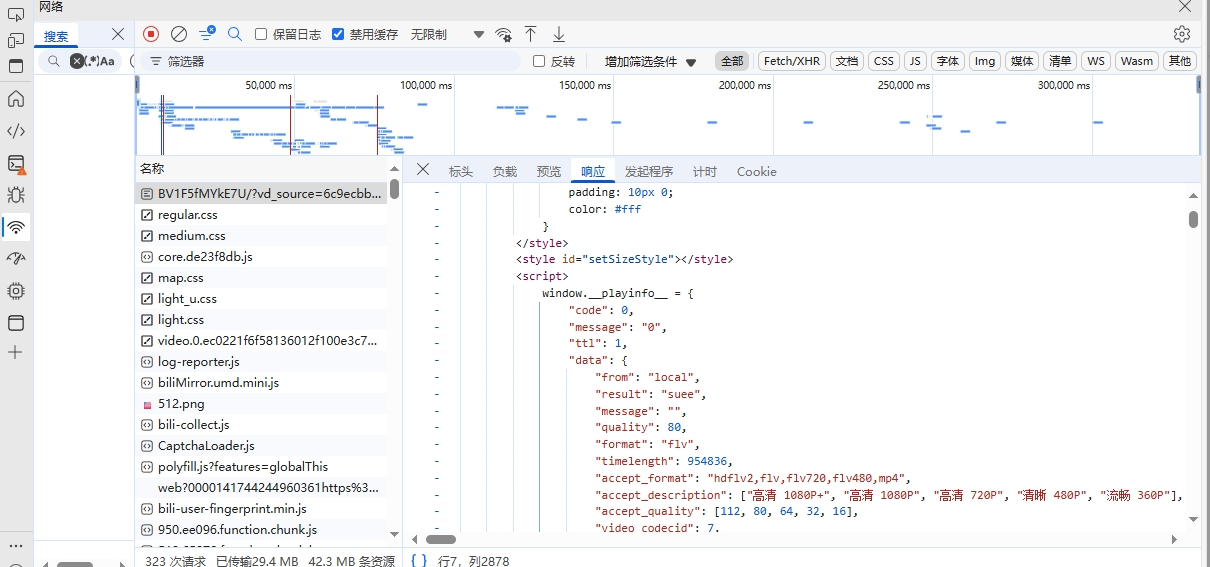
那么我们可以观察到b站视频的html是以视频的bv号进行命名的,关于视频的信息在旁边的
window.__playinfo__中,我们为了方便观察,可以将这段json复制下来,到一个json解析器中打开,我用的是jsonview
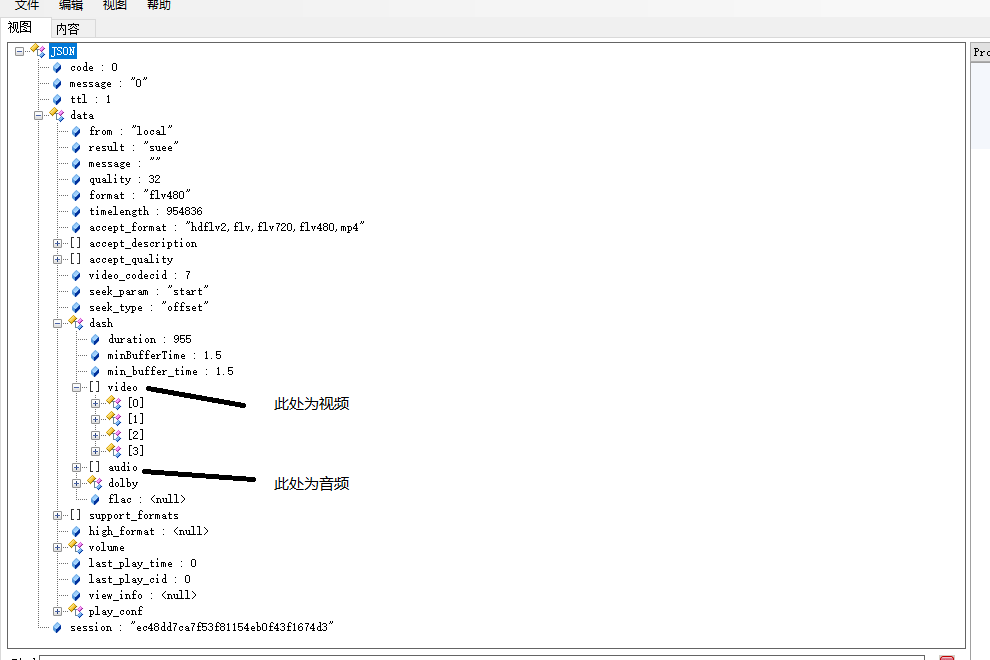
可以看到它有video和audio两个数组json,里面代表的不同元素就是不同的清晰度和音质好坏,越往前面的质量就越好,打开video【0】,里面有一个baseurl属性,这个就是它的src了,我们如果把这段src放到浏览器里打开,浏览器就会直接开始下载
现在看在java中如何实现
Pattern pattern=
Pattern.compile("<script>window.__playinfo__=(.*?)</script>");
Matcher matcher=pattern.matcher(c);
String js=null;
if(matcher.find()) {
js=matcher.group(1);
System.out.println(js);
}使用正则表达式爬出整个json
String jsonObject = JSON.parseObject(js).getJSONObject("data").getJSONObject("dash").getJSONArray("video").getJSONObject(3).getString("baseUrl");
fastjson的语法,快速得到我们想要的baseurl
//得到下载网址
System.out.println(jsonObject);
webRequest =new WebRequest(new URL(jsonObject),HttpMethod.GET);
继续模拟浏览器进行访问
Page p1=webClient.getPage(webRequest);
webResponse=p1.getWebResponse();
InputStream contentAsStream = webResponse.getContentAsStream();
IOUtils.copy(contentAsStream, new FileOutputStream("D:\\T.MP4"));设置好下载路径
IOUtils的语法,进行下载
System.out.println("下载完成");这里有一个细节,我们用(.*?)去匹配playinfo的整个json,.*?为任意的意思,拿括号括起来就是说只要括号里的内容,然后js=matcher.group(1),注意这个1,如果你不写,他不会给你返回括号里的,依然是整段。
那么到这里,b站的视频就下载好了,但仅仅是视频,我们可以按照同样的方法把audio中的音频下载下来,但是两段内容是分开的,我在b站上看up主是用一个额外的音频合成软件合成的,那么有没有别的方法呢,在这里我也要说,有的有的
打开浏览器里一个在线b站视频下载网页,可以观察到,他的底层逻辑和我们是一样的,那么它是如何将音视频在线合并的呢,看到源码
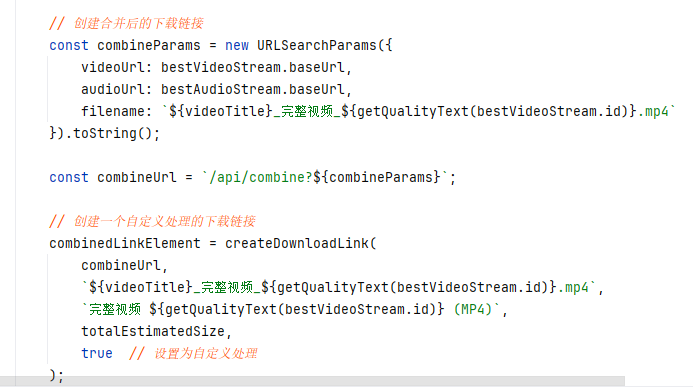
他把视频和音频的链接合成一个同时下载,再把保存路径设置成同一个,这样就实现了直接拼接成视频,至于这个拼接路径的api是人家写的接口,里面实现的功能应该就是怎么同时下载
BiBiDOWN - 哔哩哔哩视频下载工具大家可以去看看源码学习一下,也用用它支持一下这个网站的开发人员。
至于jsonview在浏览器里直接搜就能搜到
关于视频爬取的一些心得
请求头部分一定要写对,不然就会报一个zipexception,其他的部分没什么好说的
三.爬取小说
这个其实逻辑上比较简单,就是靠java把每一章的html复制下来,靠着正则表达式把小说部分扒出来,最后写到txt文件中,不过由于复制来的是网页源代码,对于字符串格式的处理有点繁琐
我选择的是母猪的产后护理(鲜虾蟹黄焗饭)全文免费阅读-BL文库
这里用到的maven依赖为jsoup
先来说明一下jsoup的功能,我们随便观察html的一个页面,就能发现它是有各种各样的标签写成的,什么class了,什么id了,什么img了

我们获取到html页面后,jsoup可以根据我们输入的class,id,tag(标签类型,如img为图片),获取到它后面标签里的内容,有的人可能会疑惑,就像我们爬视频时那样直接使用正则表达式不好吗?其实不然,视频他的相关data只有一个,而当我们爬取小说时,肯定不是只爬一章,如果不用jsoup先筛一遍,把存放章节链接的部分先抓出来,那么到时候正则表达式匹配到的可能不止我们想要的的链接,与其费时费力去思考如何修改正则表达式,不如直接用jsoup先过一遍,锁定范围
不要认为这是在偷懒,我自己写到这里的时候,可以说正则写得完全匹配小说章节链接,但是依然出现了其他我不想要的
String Url = "https://www.blwenku123.cc/15/15578/";
上面是我要爬取的小说目录
String host="https://www.blwenku123.cc";
上面是小说主页
Connection accept = Jsoup.connect(Url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
.header("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
.timeout(10000);
jsuop的连接方法,可以设置各种各样的连接参数
Document catalog=accept.get();
get()为核心,即获取到整个页面的内容
Elements mlList = catalog.getElementsByClass("ml_list");
观察发现所有章节的链接都放在一个class名为ml_list的标签中,进行初筛
//获取每一章的链接
//System.out.println(mlList);
Pattern pattern=Pattern.compile("\\/15\\/15578\\/1588\\d{3}\\.html");
Matcher matcher=pattern.matcher(mlList.toString());
完全筛出
不要以为链接就两章,这个标签它是横着排的,下方有一个很长的滚动条。
那么筛选完成,我们拿到这个href后面的链接去打开网址显示错误,为什么呢?因为这是人家服务器里的相对路径,我们需要把网站主页的链接复制下来,将获取到的链接拼在主址后面。
关于pattern和matcher的使用,它在正则匹配的时候是一个一个找的,所以我们不用担心多个链接会混合起来,也不用担心获取到的章节会乱位,保证每一章都查到是通过matcher.find()来实现的,通过while直到它找不到了
while (matcher.find()) {
chapter++;
这个是我设定的章节数,方便后面命名
//获取到每一章的链接
//第一面
String page1=host+matcher.group();
将完整链接拼起来
System.out.println(host+matcher.group());
//第二面
StringBuilder page2 = new StringBuilder(page1);
page2.insert(42, "_2");
在第42位插入
System.out.println(page2);
关于页面一和页面二,这是因为我爬的那本小说它每一章是有两面的,观察他的链接变化发现只是在.html的前面加了个_2,那么我们拿StringBuilder给他插一下就行了。
那么至此,我们得到了一章小说的完整链接,接下来去爬
try {
Document document =texttool.link(page1);
第一面
Element articlecontent = document.getElementById("articlecontent");
String text=articlecontent.toString();
text = texttool.suittext(text);//对小说格式进行修改
//第二节
第二面
Document document1 =texttool.link(page2.toString());
Element articlecontent1 = document1.getElementById("articlecontent");
String text1=articlecontent1.toString();
text1 = texttool.suittext(text1);
text="第一节\n"+text+"\n"+"第二节\n"+text1;
//制造文件夹
File des=new File("D:\\小说1");
if(!des.exists()){des.mkdirs();
System.out.println("小说文件夹已经建立");}
// System.out.println(text);
texttool.copy(text, "D:\\小说1\\"+chapter+".text");
System.out.println("章节"+chapter+"已经下载好了");
} catch (Exception e) {
System.out.println("章节\"+chapter+\"下载失败");
}
}那么我们在真正爬取小说内容时,jsoup的强大之处就体现出来了,直接锁定小说主体部分,不然我真的不知道正则要怎么筛选一堆标签里的中文
写到这里我才意识到我把txt写成text了,不过不影响,上面代码中的texttool是我造的一个存爬取小说方法的类,link为连接,suittext为修改小说字符串,在这里我意识到了java面向对象的意思就是说我们需要干什么,就专门造一个类里的方法,后面直接放参数就行了,不然用一次就得cv个5,6行代码

public String suittext(String text) throws IOException {
text = text.replace("<br>", "");
text = text.replace(" ", "");
text = text.replaceAll(" (.*?) ","$1");
text=text.replaceAll(" (.*?)</p>", "$1");
text=text.replaceAll("<p.*?“", "");
text=text.replaceAll("</p>", "");
return text;
}这是爬来的原文,里面有大量的换行,分句标签,我们拿出replace,replaceall方法即可解决,replaceall可以使用正则表达式,这里有一个重点,看到上方代码中的$1,这个意思是保留括号中的,.*?为任意的非贪婪匹配(只匹配到屁股符合条件的第一处停止,不写这个写.的话全文都会被换掉),为什么我要这么写呢,因为小说中有一些敏感字被换成了拼音,这么写就把拼音留下来了
try {
Document document =texttool.link(page1);
第一面
Element articlecontent = document.getElementById("articlecontent");
String text=articlecontent.toString();
text = texttool.suittext(text);//对小说格式进行修改
//第二节
第二面
Document document1 =texttool.link(page2.toString());
Element articlecontent1 = document1.getElementById("articlecontent");
String text1=articlecontent1.toString();
text1 = texttool.suittext(text1);
text="第一节\n"+text+"\n"+"第二节\n"+text1;
文本文档也能识别这个\n
合并两段文字
//制造文件夹
File des=new File("D:\\小说");
只写到目录不写到文件
if(!des.exists()){des.mkdirs();
System.out.println("小说文件夹已经建立");}
// System.out.println(text);
texttool.copy(text, "D:\\小说\\"+chapter+".text");
System.out.println("章节"+chapter+"已经下载好了");
} catch (Exception e) {
System.out.println("章节"+chapter+"下载失败");
}
}那么我们已经得到一个章节的全部内容了,现在可以直接写到指定路径了吗?还不行。我们得先把文件夹造出来,这里需要注意的是这里file只写到目录不写到文件,文件的最终写入是靠io流完成的,这个copy方法就是我造的一个io流方法

那么到这里,小说的爬虫基本上完成了,但大家看上面,出现了失败的情况,这里有两个可能的原因。我这里后面又多运行了几次,在失败中陆陆续续的下完了
1.对方的服务器很烂,现在访问的人又太多,响应即response会很慢,java它等不及就会报timeout超时,这个在请求头里设置timeout就行了,设的长一点就能解决
2.现在还不会解决的一点,由于我们在访问前面章节的时候java速度极快,被网站开发人员设置的反爬虫监听到了,拒绝我们进行访问,在这里教大家如何看这个网站适不适合爬,打开f12的网络栏,刷新一下看到响应html的请求标头
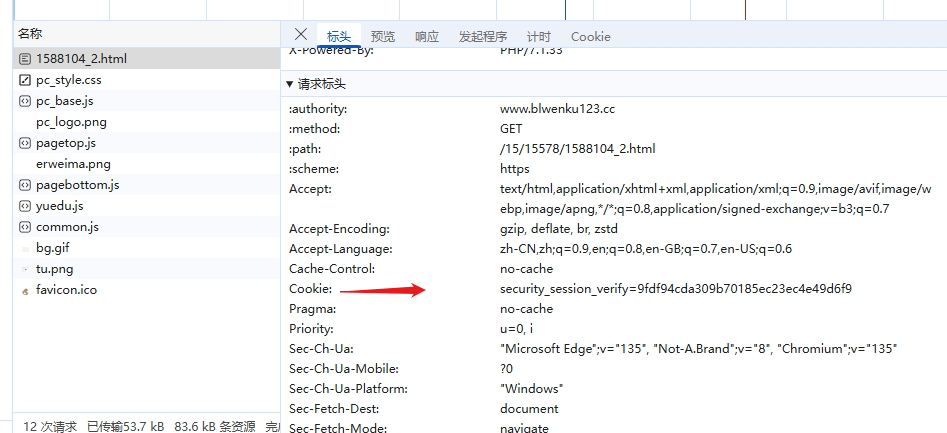
看到这个cookie,越难爬的网站后面参数越多,给大家看一个多的,这是一个我本来想爬但是后面放弃了的漫画网站
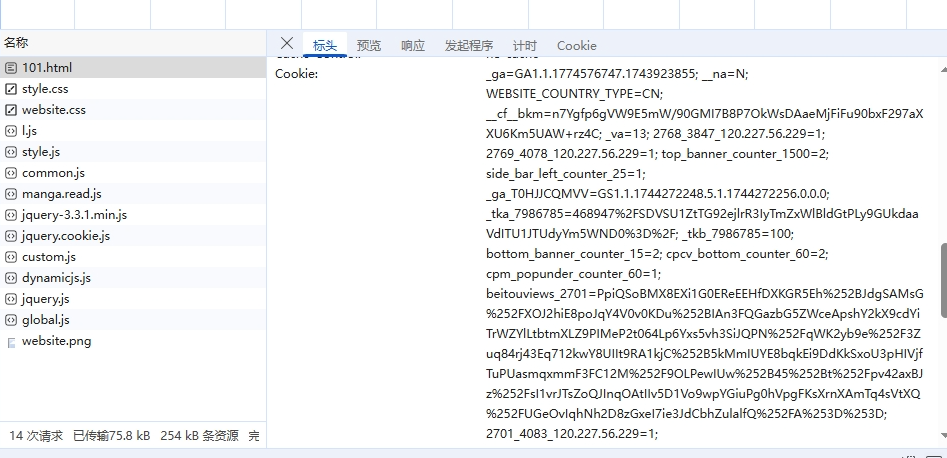
cookie是身份验证的一种,它是由服务器给你发放的,你看到的这一大串cookie后面的每一条a=b都是由脚本生成的,没有cookie就不予访问,服务器不会给java这种发放cookie,所以那些高级爬虫就是反向破解cookie,再在自己的代码里加cookie达到破解的效果(语法同我们前面加请求头)
四.爬取漫画
漫画我认为它是这三个里面最难爬的,因为它是动态加载的
你可能会问,动态加载是啥?我们打开随便一个漫画
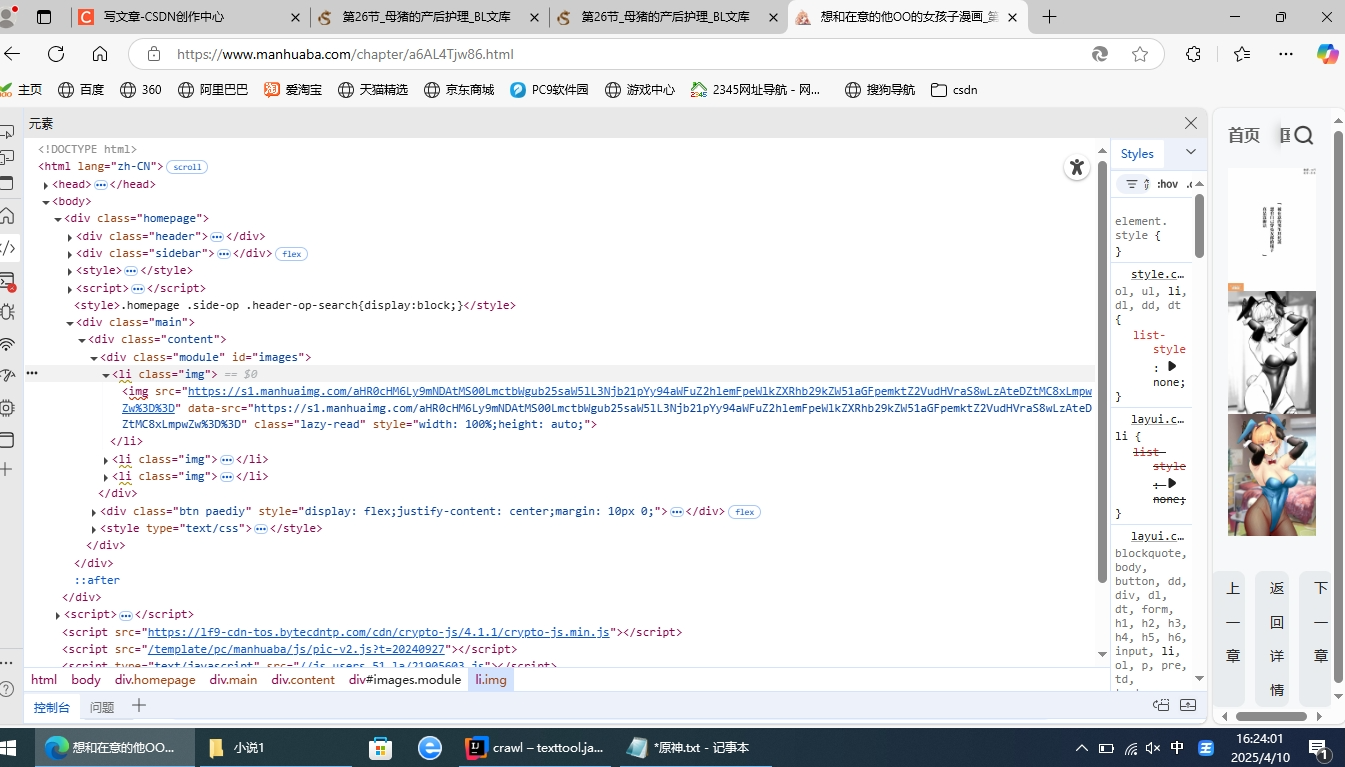
你可以看到img的src好好的在元素栏里躺着呢,但java说:我不道啊
再看html的源代码,使用ctrl+f搜索id快速定位
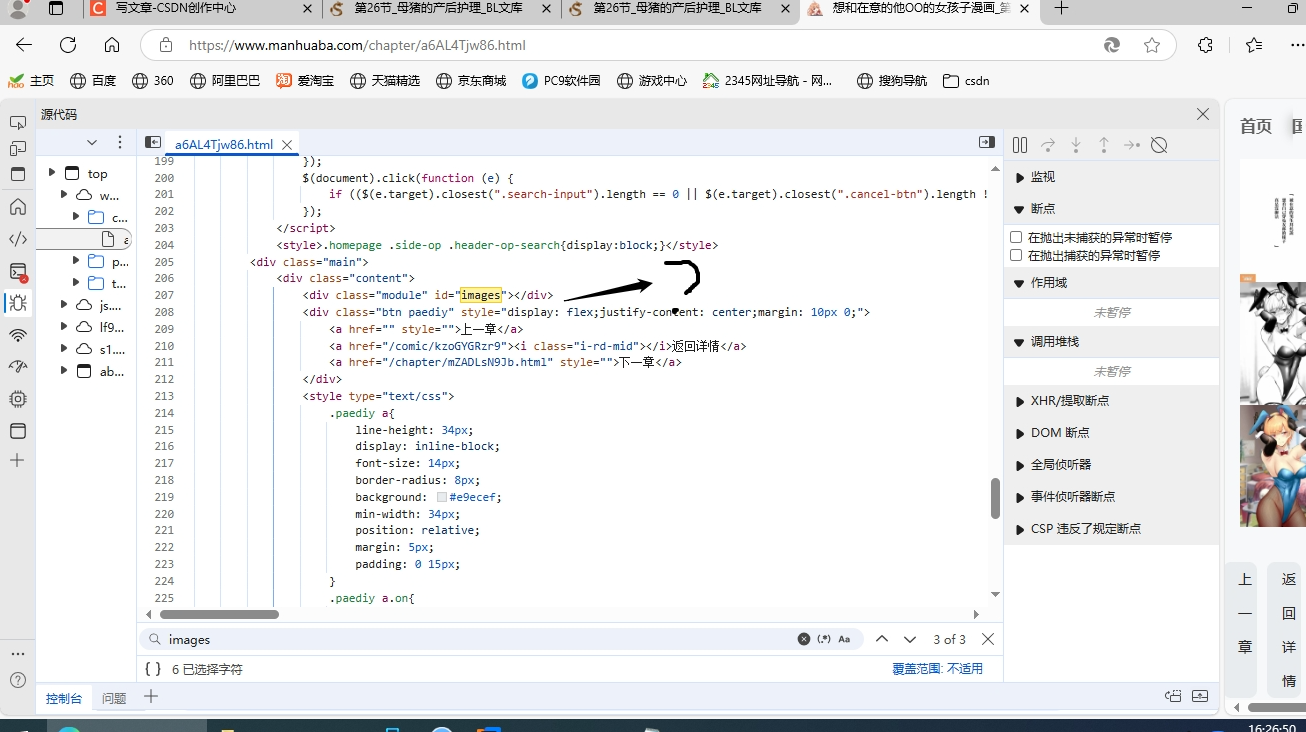
这里面是空的,前面也说过,java找不到元素栏,它只能去看源代码,也就是说,如果我们按前面获取小说和视频的方法来做是行不通的,源代码里压根没有,java也巧妇难为无米之炊。
那么动态加载就是不把路径写死了,有人来访问时就把这一章的内容再贴上去。
关于只有漫画动态加载的猜测
因为它的图片性质不同于视频和小说,这些漫画图片每一张几百kb,比小说字符串大得多,却又比视频小的多,小说动态加载浪费资源,视频动态加载响应时间长,影响用户体验,所以只有漫画是动态加载的,当然也有一些网站为了反爬也会搞动态加载
解决方法:我翻阅了各种各样的帖子,有人说可以用htmlunit模拟浏览器进行动态加载,获取到拥有src的html,但我去试了不知道为什么行不通,有人说可以用到另一个maven依赖模拟浏览器动态加载——selenium,本人亲测试验成功,可行
想用selenium,首先得下一个浏览器的驱动器,它是根据这个来模拟浏览器的,我最熟悉edge,用的是它的Microsoft Edge WebDriver |Microsoft Edge 开发人员
首先选择你要爬取的漫画,获取到所有的章节链接
String mangaUrl = "https://www.manhuaba.com/comic/kzoGYGRzr9";
这是目录链接
设置selenium
System.setProperty("webdriver.edge.driver", "D:\\tool\\MicrosoftWebDriver.exe");
EdgeOptions options=new EdgeOptions();
options.addArguments("--remote-allow-origins=*");
这一句很重要,似乎是允许访问外网
WebDriver driver = new EdgeDriver(options);
设置完成
设置全局变量漫画章数,后面方便命名
int page=0; Connection accept = Jsoup.connect(mangaUrl).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
.header("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
.timeout(10000);
//伪造请求头
Document doc = accept.get();
Element elements = doc.getElementById("panel1");
Pattern pattern=Pattern.compile("href=\"(.*?)\"");
Matcher matcher=pattern.matcher(elements.toString());上面这一段使用jsoup先把静态加载的章节链接先扒了,不知道jsoup的请去小说开头部分看下介绍
然后是重头戏,使用我们造出来的driver去爬动态页面
while(matcher.find()) {
page++;
int chapterpage=0;//设置这一章节的面数
File dir=new File("D:\\漫画\\"+page);
if(!dir.exists()){dir.mkdirs();
System.out.println("已经创建一层目录");
}造目录
String host = "http://www.manhuaba.com";
host+=matcher.group(1);
拼接成浏览器可以访问的路径
使用selenium来访问动态网站
System.out.println(host);
driver.get(host);//开始爬取每一章
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);防止超时
String pageSource = driver.getPageSource();
Document parse = Jsoup.parse(pageSource);
Elements img = parse.getElementsByTag("img");
Pattern p = Pattern.compile("<img src=\"(.*?)\"");
Matcher m = p.matcher(img.toString());把src爬出来这里把host放在while()循环里面,防止乱加
你可以看到document是由jsoup的prase得到的,parse字如其名--解析嘛
看到这里你可能想看看我是否真的成功了,当然我以图片为证
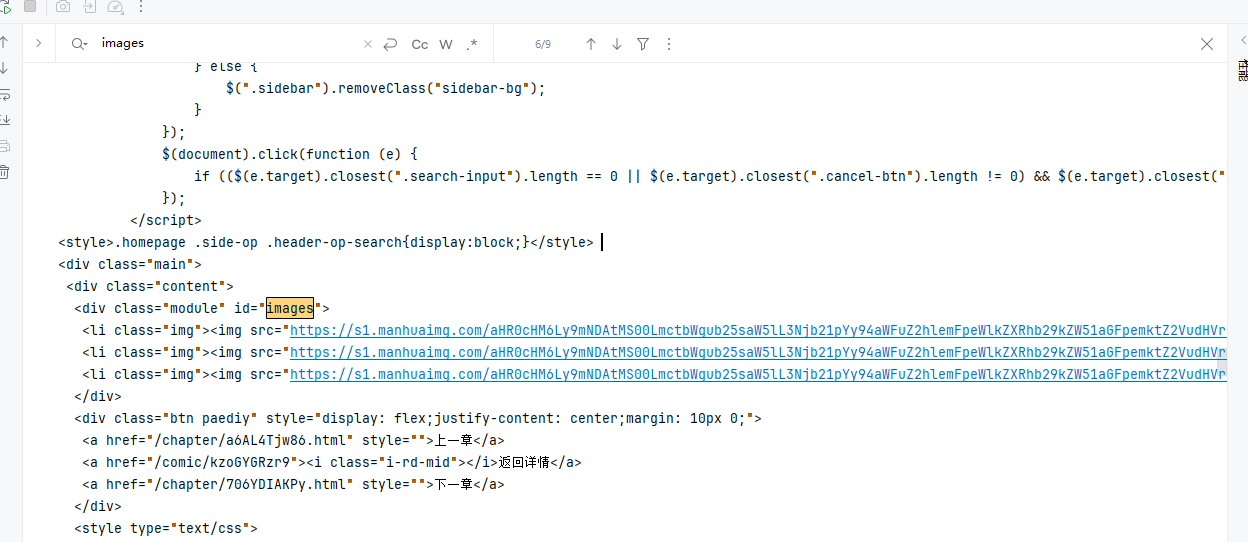
在打印出的pagesource中成功得到了我们想要的src,接下来就是下载了
while (m.find()) {chapterpage++;这个是漫画的张数,一面漫画有多张图嘛
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
WebRequest webRequest = new WebRequest( new URL(m.group(1)), HttpMethod.GET);
Page p1 = webClient.getPage(webRequest);
WebResponse webResponse;
webResponse = p1.getWebResponse();
InputStream contentAsStream = webResponse.getContentAsStream();
IOUtils.copy(contentAsStream, new FileOutputStream("D:\\漫画\\"+page+"\\T"+chapterpage+".jpg"));
System.out.println(page+"."+chapterpage+"下载完成");
} catch (Exception e) {
System.out.println(page+"."+chapterpage+"爬取失败");
}
}这里的下载用的是htmlunit加IOutils,是纯粹从视频下载那里cv过来的,我发现这样的下载速度极快,明明是下大资源,速度却比我自己用io流下小说还快,果然别人造的轮子就是好用
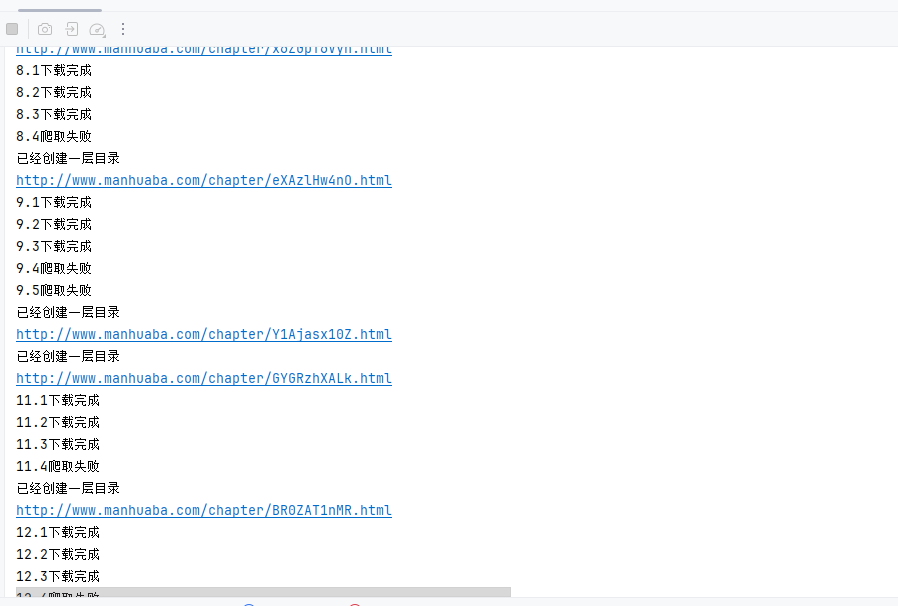
大家可以看到这里出现了两个问题
1.9后面的10没有进行下载,也就是说selenium由于加载得太快没有等src出来就到下一章去了,这个设置个等待时间就行,Thread.sleep(2000)解决
2.可以看到每章漫画里3以后全都爬取失败,这是因为jsp的动态加载里面设置了只响应某个区域内的内容,需要selenium模拟一下向下滑动,selenium中有与键盘绑定的方法,直接让他到底就行
while(matcher.find()) {
page++;
int chapterpage=0;//设置这一章节的面数
File dir=new File("D:\\漫画\\"+page);
if(!dir.exists()){dir.mkdirs();
System.out.println("已经创建一层目录");
}造目录
String host = "http://www.manhuaba.com";
host+=matcher.group(1);
拼接成浏览器可以访问的路径
使用selenium来访问动态网站
System.out.println(host);
driver.get(host);//开始爬取每一章
WebElement webElement =driver.findElement(By.cssSelector("body"));
webElement.click(); 点击一下聚焦页面
webElement.sendKeys(Keys.END);滑到底
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);防止超时
Thread.sleep(2000);这句很重要,让浏览器加载一会,别让selenium跳走了
String pageSource = driver.getPageSource();
Document parse = Jsoup.parse(pageSource);
Elements img = parse.getElementsByTag("img");
Pattern p = Pattern.compile("<img src=\"(.*?)\"");
Matcher m = p.matcher(img.toString());把src爬出来
完美解决
maven依赖

总结
1.爬虫不是万能的,能否成功主要取决于对方愿不愿意你爬,当然可以去学高级爬虫,但是面向监狱编程我们也不希望看到,大家爬了自己看看就行了,千万别拿去卖
2.爬虫需要一定的硬件支持,网速不好爬取大概率失败
3.maven依赖项一定要找对版本,例如selenium中2.x中有一些方法根本没有,最好都去下载最新版本的
4.知道爬虫的原理后我也试着去爬了vip资源,发现根本爬不了,你不开vip服务器压根不给你返回相应的src,给你展示的都是“假资源”,视频前三分钟预览,后面是拼接的黑屏,图片用的是黑图加文本代替,文字用的是统一替换的“请开通vip”
5.一个爬虫只能针对一个网站,需要观察网站原代码进行爬取代码的修改
6.不怕贼偷就怕贼惦记,我搞出这堆代码真的是天天对着网页源码在看,虽然我最近不太打算继续深入爬虫了,但是我知道这东西肯定有学得很深的人,他们盯上了的网站估计是不爬到不罢休的
如果这篇文章对你有帮助的话,麻烦点个赞支持一下,有问题可以直接问我,看到了就会回复


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









