







查询的过程
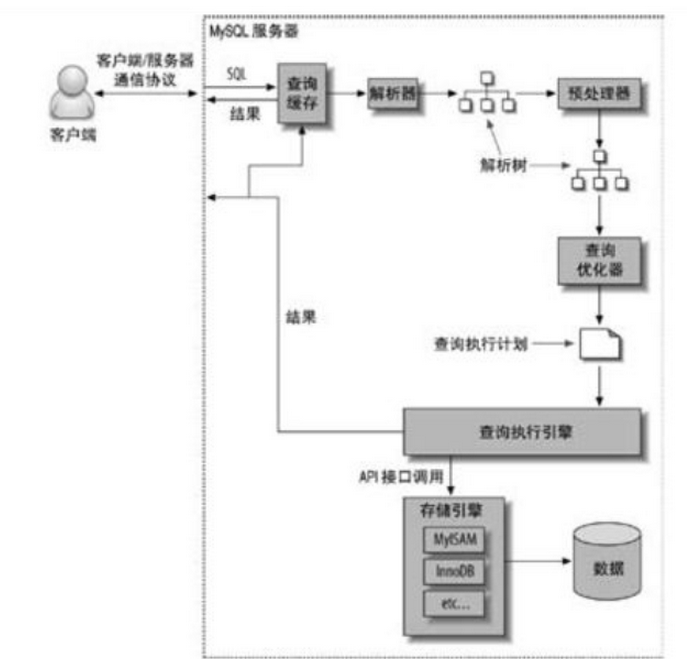
-
客户端先发送查询语句给服务器
-
服务器检查缓存,如果存在则返回
-
进行sql解析,生成解析树,再预处理,生成第二个解析树,最后再经过优化器,生成真正的执行计划
-
根据执行计划,调用存储引擎的API来执行查询
-
将结果返回给客户端。
# 以下面为例 select `name` ,`age` from `user` where `id`=1
建立链接
首先输入链接命令,输入用户名和密码,链接成功会查询响应的权限。可以看到,用户在建立链接之后就被赋予了权限,若中间进行更改,已经建立的链接权限不会改变。
若客户端长时间没有操作,服务端会在参数 wait_timeout 设置的时间后自动断开,默认时间是八小时
建立链接的过程是比较复杂的,若短时间内要做多次查询,可以在同一个链接下执行,但是有长时间不断开导致内存占用过多,因为链接临时使用的内存是被链接对象所有的,只用断开链接时才会释放内存。
可以采用一下两种方案:
1.定时断开长链接,若链接时间过长或者执行了一个占用内存较大的查询后,自动断开链接
2.在mysql5.7以及之后的版本中,可以使用 mysql_reset_connection来初始化链接对象,这个过程不会重新分配权限
查询缓存
mysql在接受到查询请求后,会先查询缓存。缓存是key-value对组成,key该是对象之前的查询语句的hash值,value是之前查询的结果
mysql在8.0版本将缓存功能删掉了
生成解析树
生产解析树的流程类似于编译原理的分析流程,也需要词法分析和语法分析
服务端接受的实际上是一个客户端传来的字符串,服务端首先会将字符串分割成几个字符串
select `name` ,`age` from `user` where `id`=1 #分解如下 "select","name","age","from","user","where","id","=","1"
然后分析 "select" 知道是执行查询语句,分析得到表名 "user" ,得到查询的列 "name" ," age" 等。然后生成一颗语法树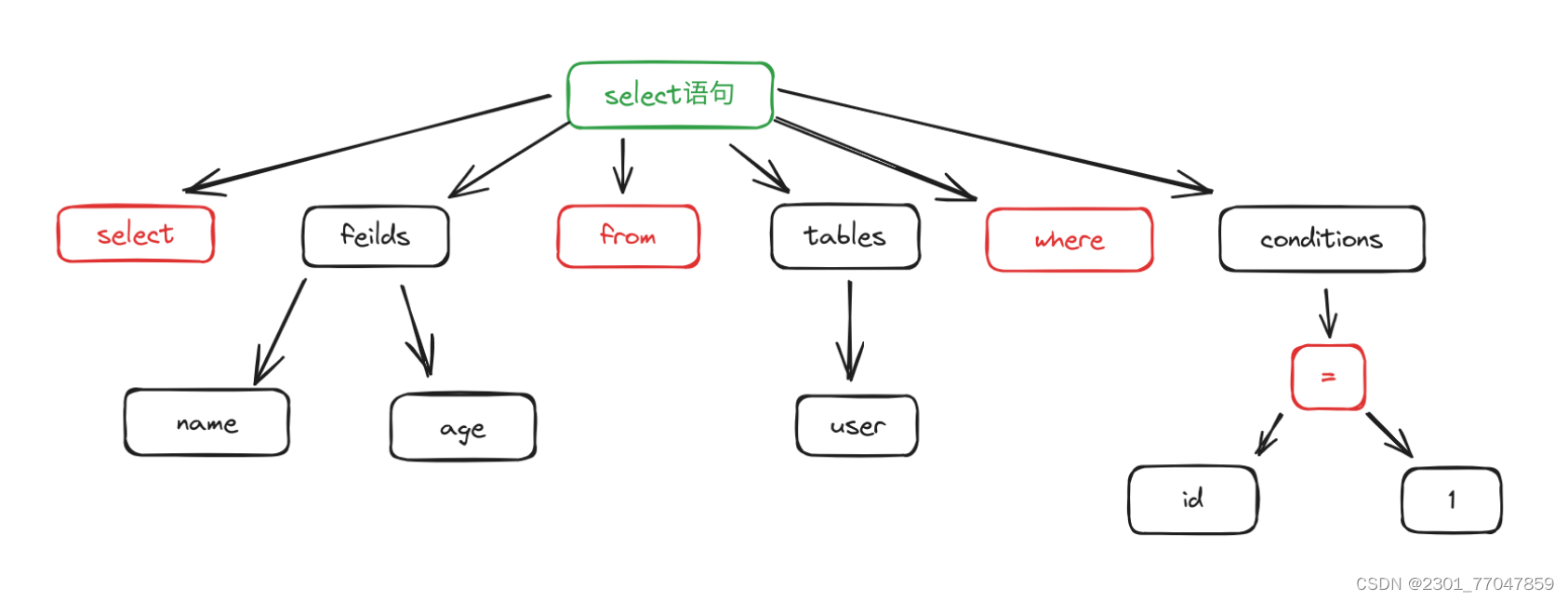
之后在进行语法分析,这个过程会验证表是否存在,表中列是否存在,语句是否有错误,检验用户是否有权限操作等,处理之后得到一个新的语法树。
查询优化器
当有多个索引时,决定使用那个索引
当有多个表做关联时,决定链接的顺序,以哪个表做基准表
MySQL版本之间的优化策略和技术可能会有所不同,因此建议查阅相应版本的MySQL文档以获取最准确的信息。
执行器
执行前也会判断有没有权限
首先执行器会调用存储引擎的的接口查询:,查询id=1
-
若id是主键索引,则从主键索引中查找id=1的记录,主键索引只会返回一条结果
-
若id不是索引,则进行全表查询,每次扫描一行,若满足id=1,则加入到结果集缓存中,直到遍历整个表
存储引擎分类
三类存储引擎
InnoDB:
支持十五,行锁,外键,MVCC,可以回滚,mysql5.5之后的默认引擎
MyISAM
高速引擎,拥有较高的插入和查询速度,不支持事务
Memory
内存存储引擎,拥有极高的插入、更新、查询功能。但是会占用和数据大小相等的内存















 3009
3009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









